Kurz und knapp
Eine KI-Agenten-Schleife ist der sich wiederholende Zyklus, der ein Sprachmodell in einen Agenten verwandelt: Es nimmt eine Eingabe wahr, überlegt, was zu tun ist, handelt, indem es ein Tool aufruft, beobachtet das Ergebnis und kehrt dann zurück, immer und immer wieder, bis die Aufgabe abgeschlossen ist oder eine Abbruchregel greift. Diese eine architektonische Idee ist der gesamte Unterschied zwischen einem Agenten und einem Chatbot. Ein Chatbot antwortet in einem Durchlauf; ein Agent macht weiter, verkettet Schritte und kann sich erholen, wenn etwas schiefgeht.
Deshalb nennen Leute einen Agenten nur halb im Scherz „ein LLM in einer While-Schleife mit Tools". Die Schleife ist auch genau der Grund, warum Agenten für den Kundensupport funktionieren: Ein Ticket ist eine mehrstufige Aufgabe (das Problem herausfinden, Dinge nachschlagen, eine Aktion ausführen, prüfen, ob sie geklappt hat, lösen oder eskalieren), und das ist eine Schleife, keine gerade Linie. Wenn Sie diese Schleife in Ihrem Helpdesk laufen lassen wollen, ohne die Infrastruktur selbst zu bauen und zu betreuen, ist genau das, was eesel leistet.
Die Definition in einem Satz
Eine KI-Agenten-Schleife (Sie werden auch die Bezeichnung agentische Schleife finden) ist der iterative Ausführungszyklus im Kern jedes agentischen Systems. Ein Modell nimmt wiederholt eine Eingabe wahr, überlegt, was als Nächstes zu tun ist, handelt, indem es ein Tool aufruft, beobachtet dann das Ergebnis und speist es in die nächste Runde ein, und wiederholt das, bis die Aufgabe abgeschlossen ist oder eine Abbruchbedingung erreicht wird.
Das Entwicklerteam von Oracle bringt den Unterschied unverblümt auf den Punkt: „Der architektonische Unterschied zwischen einem Chatbot und einem KI-Agenten ist ein einziges Muster: die Agenten-Schleife". Die Version des Praktikers Simon Willison ist noch kürzer. Ein Agent, schreibt er, ist etwas, das „Tools in einer Schleife ausführt, um ein Ziel zu erreichen."
Das ist tatsächlich der größte Teil des Konzepts. Der interessante Teil ist, was jede Phase der Schleife tatsächlich tut, warum die Schleife Dinge ermöglicht, die ein einzelner Modellaufruf nicht kann, und wo sie ihren Nutzen entfaltet.
Die vier Phasen: wahrnehmen, denken, handeln, beobachten
Die meisten Beschreibungen fassen die Schleife in vier sich wiederholende Phasen zusammen. Oracle verwendet eine Variante mit fünf Phasen (es trennt das Planen vom Denken ab), aber die Mechanik ist in beiden Fällen dieselbe.
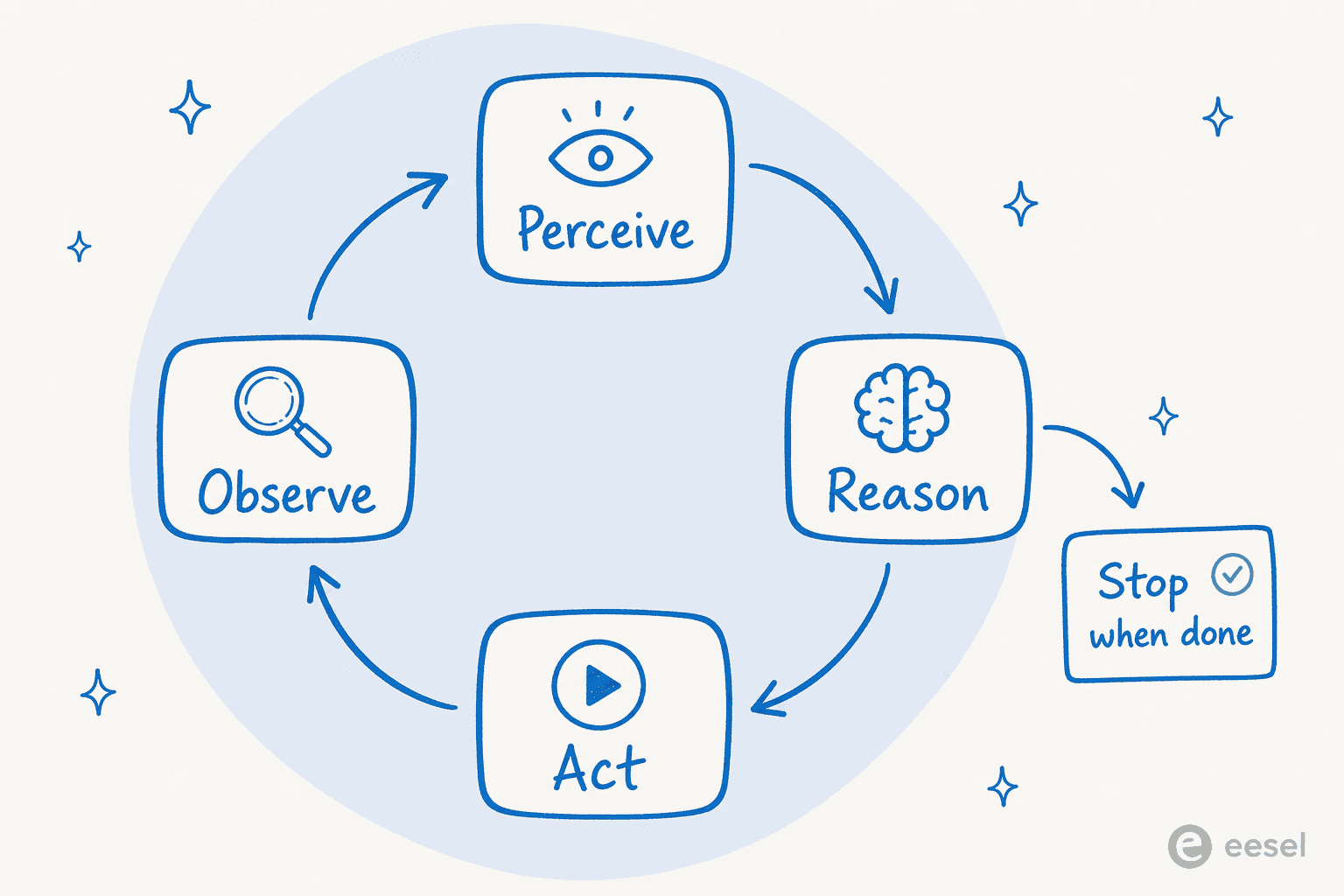
- Wahrnehmen. Der Agent nimmt eine Eingabe auf: eine Nutzernachricht, eine API-Antwort, einen Fehler oder das Ergebnis seiner eigenen letzten Aktion.
- Denken. Das Modell betrachtet alles in seinem Kontext und entscheidet, was als Nächstes zu tun ist. Bei schwierigeren Aufgaben plant es hier auch, indem es das Ziel vor dem Handeln in kleinere Schritte zerlegt.
- Handeln. Der Agent tut etwas in der Welt: einen Tool-Aufruf, eine API-Anfrage, eine Datenbankabfrage, eine Codeausführung.
- Beobachten. Der Agent prüft das Ergebnis. Hat es funktioniert? Ist die Aufgabe erledigt? Muss der Plan geändert werden?
Dann kehrt er zurück. Das Ganze lässt sich auf eine Handvoll Zeilen Pseudocode reduzieren, weshalb sich die Formulierung „es ist nur eine While-Schleife" durchgesetzt hat:
while not done:
response = call_llm(messages)
if response has tool_calls:
results = execute_tools(response.tool_calls)
messages.append(results)
else:
done = True
return response
Die großen Labore sind alle unabhängig voneinander hier gelandet. Anthropic beschreibt Agenten als „typischerweise einfach LLMs, die in einer Schleife Tools auf Basis von Umgebungsfeedback nutzen". Das Agents SDK von OpenAI dokumentiert seinen Runner als buchstäbliche Schleife: das Modell aufrufen, und wenn es eine endgültige Antwort ohne Tool-Aufrufe zurückgibt, stoppen; andernfalls die Tools ausführen, die Ergebnisse anhängen und erneut laufen lassen. Eine praktische Einzeiler-Zusammenfassung, ursprünglich von Lilian Weng, lautet Agent = LLM + Speicher + Planung + Tool-Nutzung. Die Schleife ist die Laufzeitumgebung, die diese vier zusammenführt.
Ein durchgespieltes Beispiel
Um es konkret zu machen, hier ein echter Durchlauf über drei Iterationen für die Aufgabe „Identifiziere die meistzitierte Arbeit über Agenten-Speicher, die 2026 veröffentlicht wurde, und fasse ihre wichtigsten Erkenntnisse zusammen", aus Oracles Artikel:
- Iteration 1. Denken: Es muss suchen. Handeln: eine Such-API aufrufen. Beobachten: 15 Arbeiten mit Zitationszahlen kommen zurück.
- Iteration 2. Denken: das Top-Ergebnis mit 340 Zitationen wählen. Handeln: ein Tool zum Abruf von Dokumenten aufrufen. Beobachten: Abstract und Schlüsselabschnitte zurückgegeben.
- Iteration 3. Denken: genug gesammelt. Handeln: die Zusammenfassung schreiben. Beobachten: Aufgabe abgeschlossen, Schleife verlassen.
Wie Oracle es formuliert: „Drei Iterationen. Drei Tool-Aufrufe. Eine vollständige Antwort, die kein Chatbot mit nur einem Durchlauf hätte produzieren können." Genau dieser letzte Satz ist der springende Punkt.
Woher die Idee kam: ReAct
Die Schleife ist keine Erfindung von 2026. Ihr akademisches Rückgrat ist das ReAct-Paper (Yao et al., 2022), kurz für „reasoning and acting" (Denken und Handeln). Seine Erkenntnis war, Denkspuren mit Aktionen zu verschränken: einen Thought (Gedanke) darüber, was zu tun ist, dann eine Action (Aktion), dann eine Observation (Beobachtung), dann einen weiteren Gedanken und so weiter. Das Denken, so argumentiert das Paper, „hilft dem Modell, Aktionspläne zu erstellen, zu verfolgen und zu aktualisieren sowie Ausnahmen zu behandeln, während Aktionen es ihm ermöglichen, mit externen Quellen zu interagieren".
Der gemessene Nutzen war real, nicht vage: eine absolute Verbesserung der Erfolgsrate von 34 % beim ALFWorld-Benchmark und 10 % bei WebShop gegenüber den stärksten Baselines (arXiv:2210.03629). Ein Modell, das nur denkt, „leidet unter Fehlinformationen, da es nicht in externen Umgebungen verankert ist", und ein Modell, das nur handelt, „leidet unter mangelndem Denken". Beides in der Schleife zu kombinieren, behebt beide Probleme. Wenn Abruf Teil Ihres Bildes ist, lohnt es sich zu verstehen, wie das mit einfachem Retrieval-Augmented Generation zusammenhängt, worauf wir gleich kommen.
Agenten-Schleife versus Chatbot: die eine While-Schleife
Hier ist der Vergleich, auf den es ankommt, denn das ist die Frage, mit der die meisten Leute tatsächlich kommen.
| Dimension | Klassischer Chatbot / Single-Turn-RAG | Agenten-Schleife |
|---|---|---|
| Modelldurchläufe pro Anfrage | Einer | Viele (einer pro Iteration) |
| Zustand über Schritte hinweg | Zustandslos und isoliert | Persistenter Kontext, der weitergetragen wird |
| Tool-Nutzung | Keine oder ein einzelner Aufruf | Wiederholte, verkettete Tool-Aufrufe |
| Fehlererholung | Keine | Beobachtet Fehler und plant neu |
| Mehrstufige Aufgaben | Kann nicht zerlegen | Zerlegt und verkettet |
| Führt echte Aktionen aus | Liest und antwortet nur | Handelt (Rückerstattungen, Buchungen, Schreibvorgänge) |
| Ablaufsteuerung entschieden durch | Fest codierte Pfade | Das Modell, zur Laufzeit |
| Endet, wenn | Eine Antwort erzeugt ist | Aufgabe abgeschlossen oder Abbruchbedingung |
Das entscheidende Detail, das die Leute übersehen, ist, dass dies keine Lücke in der Modellfähigkeit ist. Dieselben zugrunde liegenden Modelle (Claude, GPT, Gemini) treiben beide an. Oracle stellt klar, dass ChatGPT, Claude und Gemini „alle in der Lage sind, sich durch mehrstufige Probleme zu denken. Die Einschränkung ist architektonisch." Eine reine Chatbot-Interaktion ist zustandslos: Jeder Prompt wird isoliert behandelt, ohne Erinnerung an Zwischenergebnisse und ohne Möglichkeit, Entscheidungen zu verketten. Die Schleife ist das, was diese Decke entfernt.
Es lohnt sich, Single-Turn-RAG ausdrücklich zu benennen, weil es dazwischen liegt und die Leute verwirrt. Ein RAG-Chatbot ruft tatsächlich externes Wissen ab, bevor er antwortet, was sich agentenartig anfühlt. Aber er läuft trotzdem nur einmal: abrufen, dann antworten. Er kann nicht entscheiden, dass er eine zweite Suche braucht, basierend auf dem, was die erste ergeben hat, kann keine Aktion mit Nebenwirkungen ausführen und kann sich nicht erholen, wenn der erste Abruf danebenging. Eine Agenten-Schleife verwandelt diesen einen Abruf in eine einzelne Aktion, die sie wiederholen und mit anderen verketten kann. Wenn Sie sich jemals gefragt haben, warum ein KI-Chatbot ständig falsch antwortet, ist das Fehlen dieser Schleife oft der Grund: Er bekommt einen Versuch und keine Chance, sich selbst zu überprüfen.
Noch eine Einordnung, die man im Kopf behalten sollte: „agentisch" ist ein Spektrum, kein Ja-oder-Nein. Harrison Chase von LangChain argumentiert, ein System ist „umso agentischer, je mehr ein LLM entscheidet, wie sich das System verhalten kann", reichend von einem einfachen Router über einen Zustandsautomaten, der bis zum Abschluss in einer Schleife läuft, bis hin zu einem vollständig autonomen Agenten, der seine eigenen Tools baut und wiederverwendet. Die nützlichste Support-Automatisierung lebt in der Mitte dieses Bereichs, nicht am wilden Ende.
Die Schleife hat Varianten
Die grundlegende ReAct-Schleife deckt die meisten Fälle ab, aber ein paar Erweiterungen tauchen oft genug auf, um sie beim Namen zu kennen. Andrew Ng gruppierte die Kernideen in vier agentische Design-Muster: Reflexion, Tool-Nutzung, Planung und Multi-Agenten-Zusammenarbeit. In Schleifenbegriffen:
- Plan-and-Execute. Trenne Planung vom Handeln. Ein Planer schreibt die vollständige Aufgabenzerlegung im Voraus, ein Executor arbeitet sie ab, und ein Re-Planner passt an, wenn die Realität abweicht. Das reduziert Modellaufrufe im Vergleich zum Denken bei jedem einzelnen Schritt; LangChains LLMCompiler meldete eine 3,6-fache Beschleunigung gegenüber sequenzieller Ausführung im ReAct-Stil.
- Reflexion. Ein Modellaufruf erzeugt ein Ergebnis, während ein anderer es kritisiert und Rückmeldung gibt, in einer Schleife, bis die Ausgabe die Messlatte erreicht. Ng beschreibt dies als das LLM, das „seine eigene Arbeit kritisiert und überarbeitet".
- Multi-Agent. Ein leitender Agent erzeugt Sub-Agenten, die Stränge parallel bearbeiten. Anthropic berichtete, dass sein Multi-Agenten-Recherchesystem „ein Single-Agenten-Setup bei internen Recherche-Evaluationen um 90,2 % übertraf".
Der einheitliche Rat aus jeder Quelle, und der Teil, der am häufigsten ignoriert wird: Beginne mit der einfachsten Schleife, die funktioniert, und füge nur dann Komplexität hinzu, wenn du messen kannst, dass sie tatsächlich geholfen hat.
Schutzmechanismen: warum die Schleife eine Bremse braucht
Eine Schleife, die sich selbst ausführen kann, ist auch eine Schleife, die davonlaufen kann. Abbruchbedingungen sind nicht optional. Ohne sie kann ein Agent endlos drehen und „Tokens verbrennen und zunehmend inkohärente Ergebnisse produzieren".
Die üblichen Bremsen:
- Maximale Iterationen. Eine harte Obergrenze für Schleifendurchläufe. OpenAI löst eine
MaxTurnsExceeded-Ausnahme aus, sobald man das konfigurierte Limit überschreitet, und Anthropic empfiehlt eine maximale Anzahl von Iterationen, „um die Kontrolle zu behalten". - Token- und Kostenbudgets. Schleifen sind nicht billig. Agenten verbrauchen laut Oracle etwa 4-mal mehr Tokens als ein Standard-Chat-Aufruf, und Multi-Agenten-Setups bis zu 15-mal so viele. Diese Kosten sind der Hauptgrund, warum Produktionsteams jeden Schritt instrumentieren.
- Erkennung ausbleibenden Fortschritts. Beende, wenn wiederholte Iterationen nichts Neues mehr produzieren.
- Human-in-the-Loop-Kontrollpunkte. Agenten können bei einem Hindernis für einen Menschen pausieren, was im Support sehr wichtig ist.
Oracle erzählt hier eine großartige Warngeschichte: Ein Scraping-Agent, dessen Zielseite stillschweigend ihre Struktur änderte, begann leere Ergebnisse zurückzugeben, und mit einem „Versuche es erneut, bis du Daten bekommst"-Prompt und ohne harten Stopp „rief er das defekte Tool 400 Mal in fünf Minuten auf", bevor ein Rate-Limit ihn rettete. Die Lösung war fast beleidigend einfach: „Ein maximales Iterationslimit von drei Zyklen hätte den Fehler vollständig verhindert." Wenn Sie aus diesem ganzen Beitrag eine betriebliche Lektion mitnehmen, dann diese.
Wie sich die Schleife auf ein Support-Ticket abbilden lässt
Hier wird das abstrakte Muster zum Produkt. Anthropic hebt den Kundensupport als „eine natürliche Passform für offenere Agenten" hervor, weil die Arbeit sowohl Konversation als auch Aktion erfordert. Ein Support-Ticket ist eine Musterschleife wie aus dem Lehrbuch:
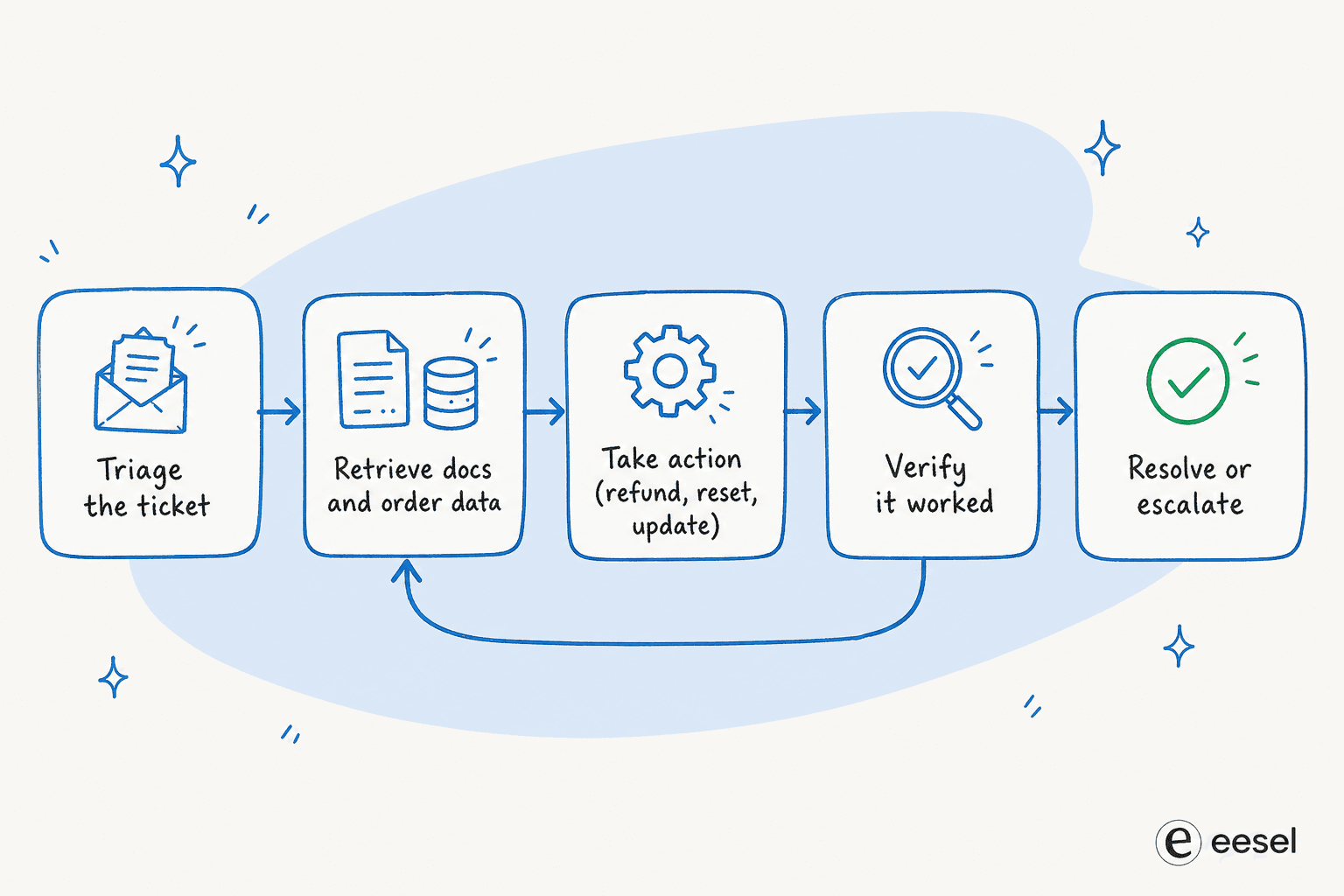
- Triagieren. Die Schleife nimmt das eingehende Ticket wahr, und das Modell überlegt sich die Absicht: Abrechnung, Rückerstattung, Passwort-Zurücksetzung, ein technischer Fehler. Das ist der klassische Schritt der Ticket-Triage.
- Abrufen. Datentools aufrufen: Wissensdatenbank-Suche, Bestellhistorie, Konto-Abfragen.
- Handeln. Aktionstools mit echten Nebenwirkungen aufrufen: eine Rückerstattung auslösen, ein Abonnement ändern, eine Lieferadresse aktualisieren, ein Passwort zurücksetzen, das Ticket aktualisieren.
- Beobachten und verifizieren. Prüfen, ob die Aktion tatsächlich funktioniert hat. Wenn eine Abfrage leer zurückkam oder eine API einen Fehler warf, plant die Schleife neu, was die Erholung ist, die ein Bot mit nur einem Durchlauf schlicht nicht leisten kann.
- Lösen oder eskalieren. Wenn es erledigt ist, schließe es. Wenn der Agent eine Konfidenzgrenze erreicht, übergib es sauber an einen Menschen.
Das ist auch der Grund, warum Agenten-Schleifen so viel mehr lösen als ältere Bots. Laut Notchs Benchmark-Bericht 2026 lösen Legacy-Chatbots nur 10 bis 25 % der Anliegen (sie wurden zum Weiterleiten gebaut, nicht zum Lösen), während agentische Plattformen, die sich „direkt mit CRM-, Abrechnungs- und Schadensystemen verbinden und ausführen", bei 70 bis 85 % durchgängiger Lösung landen.
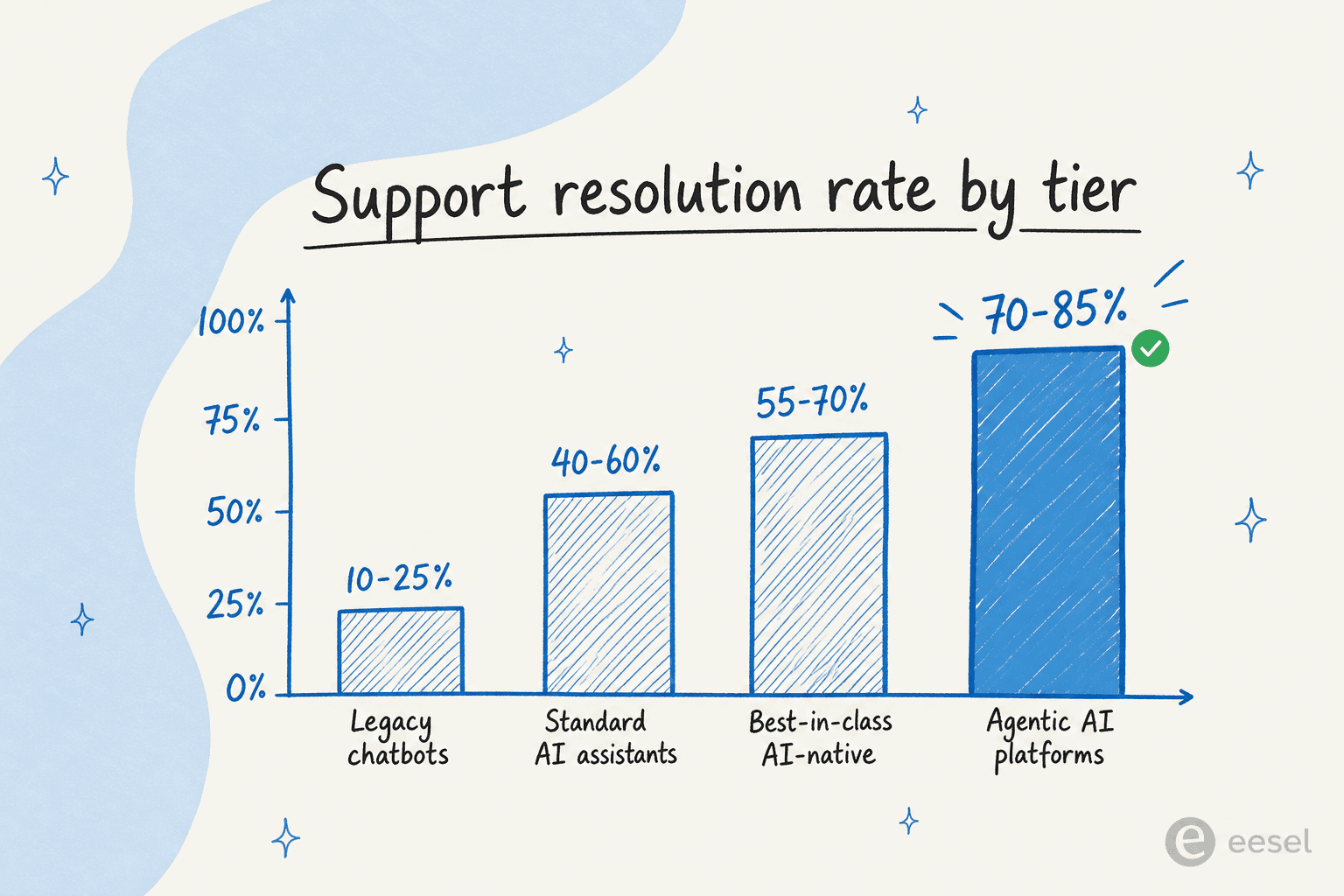
Eine Warnung aus demselben Bericht, die man in jedes Gespräch mit einem Anbieter mitnehmen sollte: Lösung ist nicht dasselbe wie Deflection oder Containment. Deflection bedeutet nur, dass die KI eine Antwort produziert hat und der Kunde verschwunden ist; das zugrunde liegende Problem ist möglicherweise immer noch ungelöst. Containment (keine Eskalation) ist, in Notchs Worten, „wohl das irreführendste". Die ehrliche Frage an einen Anbieter ist „nicht, wie hoch seine Lösungsrate ist, sondern was er als gelöst zählt." Das ist die Art von Nuance, die eine echte Schleife mit echten Aktionen tatsächlich untermauern kann und ein reiner Deflection-Bot nicht. Wenn Sie Tools auswählen, gehen unsere Übersichten zu den besten KI für Ticket-Automatisierung und der besten Kundenservice-KI tiefer darauf ein, welche Plattformen wirklich lösen statt nur abzuwehren.
So sieht eine Agenten-Schleife aus, wenn sie live in einem echten Helpdesk läuft und Aktionen auf Tickets ausführt, anstatt sie nur vorzuschlagen:
Die konfidenzbasierte Übergabe ist der saubere Ausstieg der Schleife
Die am häufigsten gewünschte Steuerung, die wir von Support-Teams hören, ist nicht „bring die KI dazu, alles zu beantworten". Es ist das Gegenteil: Lass die KI nur das bearbeiten, bei dem sie zuversichtlich ist, und lass den Rest in Ruhe. Eine CX-Leiterin bei einer Direct-to-Consumer-Nahrungsergänzungsmarke mit etwa 7.000 Tickets im Monat hat es perfekt ausgedrückt:
„Die KI wird niemals in der Lage sein, 100 % der Fragen zu beantworten... Ich brauche eine KI, die nur die Tickets bearbeitet, die sie zuversichtlich bearbeiten kann, und alle anderen in Ruhe lässt."
Das ist die Abbruchbedingung, angewendet auf den Support. Eine Konfidenzschwelle entscheidet, ob die Schleife löst oder übergibt, und eine saubere Übergabe an einen Menschen kümmert sich um den Rest. Deshalb sind auch die Eskalationsrate und die 48- bis 72-Stunden-Wiederkontaktrate die Metriken, die es zu beobachten lohnt, mehr als eine schlagzeilenträchtige Lösungszahl: Sie sagen Ihnen, ob die Schleife tatsächlich Probleme löst oder nur Tickets schließt.
Was Praktiker tatsächlich über die Schleife sagen
Die Entwicklergemeinschaft hat starke, witzige und leicht widersprüchliche Meinungen über Agenten-Schleifen, was das beste Zeichen dafür ist, dass die Idee real ist.
Zur Einfachheit ist diese vielgeteilte Einschätzung repräsentativ:
„Es ist tatsächlich erstaunlich, wie gut eine Schleife mit einem LLM, das Tools aufrufen kann, inzwischen für alle möglichen Aufgaben funktioniert."
libraryofbabel, auf Hacker News
Zur Gefahr, die Schleife uneingeschränkt laufen zu lassen, hat Docker-Gründer Solomon Hykes den Satz, den alle zitieren:
„Ein KI-Agent ist ein LLM, das seine Umgebung in einer Schleife zerstört."
Beides ist gleichzeitig wahr, und diese Spannung ist das eigentliche technische Problem. Die Schleife ist erschreckend leistungsfähig und wirklich riskant, was genau der Grund ist, warum der Abschnitt über Schutzmechanismen oben kein optionales Standard-Beiwerk ist. Simon Willison argumentiert sogar, dass „das Entwerfen agentischer Schleifen" zu einer eigenen Disziplin wird: Die Kunst, sagt er, „besteht darin, die Tools und die Schleife für ihre Nutzung sorgfältig zu gestalten."
Selbst bauen oder kaufen?
Weil die Schleife so einfach zu beschreiben ist, kommen viele technische Teams zu dem naheliegenden Schluss: Wir bauen einfach unsere eigene auf der Claude- oder OpenAI-API. Und ehrlich gesagt können Sie einen funktionierenden Prototyp an einem Nachmittag aufsetzen. Die While-Schleife sind die einfachen 20 %.
Die schwierigen 80 % sind alles drum herum: persistenter Speicher, Observability über jeden Tool-Aufruf hinweg, die Schutzmechanismen, die eine außer Kontrolle geratene Schleife stoppen, die Helpdesk- und Wissensdatenbank-Integrationen und die laufende Wartung, während sich Modelle und APIs unter Ihnen verändern. Das ist der Teil, den Teams unterschätzen. Wir haben zugesehen, wie viele technisch starke Kunden eine Demo bauten und sich dann für den Kauf entschieden, um das nicht langfristig betreiben zu müssen. Wie ein Engineering-Leiter bei einem Hersteller von Bitcoin-Automaten, der sich für Kaufen statt Bauen entschied, uns sagte:
„Wir hätten versuchen können, unsere eigene LLM-Anwendung zu schreiben, aber wir wollten unsere Zeit nicht darin investieren. Wir wollten etwas, das wir nicht warten müssen."
Wenn der Vorsprung Ihres Teams in Ihrem Produkt liegt und nicht im Betrieb einer Agenten-Laufzeitumgebung, spricht diese Rechnung meist für das Kaufen. Wir sind auf den Kompromiss ausführlicher in unserem Blick auf das Erstellen eines benutzerdefinierten GPT für den Kundenservice eingegangen, und Sie können sehen, wie ausgereifte Schleifen in freier Wildbahn aussehen, bei Unternehmen, die KI bereits für den Kundenservice nutzen.
eesel ausprobieren
eesel ist die Agenten-Schleife, als Produkt für Support-, IT- und Ops-Teams aufbereitet, ohne den Eigenbau. Sein KI-Helpdesk-Agent führt den vollständigen Zyklus aus Wahrnehmen, Denken, Handeln und Beobachten direkt in dem Helpdesk aus, den Sie bereits nutzen (Zendesk, Freshdesk, HubSpot, Gorgias, Front, Slack und über 100 Integrationen), sodass er Antworten nicht nur entwirft, sondern Aktionen auf Tickets ausführt und sie löst.

Das Unterscheidungsmerkmal, das genau auf alles oben abbildet, ist sein Simulationsmodus: Sie können den Agenten gegen Tausende Ihrer vergangenen Tickets laufen lassen, um genau zu sehen, was er gelöst hätte, Thema für Thema, bevor eine einzige Live-Antwort herausgeht. Das ist die schutzmechanismus-zuerst, konfidenzbasierte Version der Schleife, die Support-Teams tatsächlich verlangen. Er lernt vom ersten Tag an aus Ihren gelösten Tickets und Hilfedokumenten, läuft in über 80 Sprachen und rechnet pro Lösung statt pro Platz ab. Sie können eesel ausprobieren mit 50 $ kostenloser Nutzung, ohne Kreditkarte, und Ihre eigene Lösungszahl sehen, bevor Sie sich festlegen.
Häufig gestellte Fragen
Was ist eine KI-Agenten-Schleife einfach erklärt?
Was ist der Unterschied zwischen einem KI-Agenten und einem Chatbot?
Wie lässt sich die KI-Agenten-Schleife auf den Kundensupport anwenden?
Kann eine KI-Agenten-Schleife ewig laufen, und wie wird das verhindert?
Sollte ich meine eigene KI-Agenten-Schleife bauen oder eine kaufen?

Article by
Alicia Kirana Utomo
Kira is a writer at eesel AI with a Computer Science background and over a year of hands-on experience evaluating AI-powered customer service tools. She focuses on breaking down how helpdesk platforms and AI agents actually work so that support teams can make better buying decisions.







