Como saber se meu suporte de IA está funcionando?
Alicia Kirana Utomo
Katelin Teen
Última edição June 17, 2026

Resumo
"Meu suporte de IA está funcionando?" se resume a cinco números lidos juntos, não um só: taxa de resolução, taxa de desvio, qualidade das respostas, precisão de escalonamento e taxa de erros factuais. Se a resolução e o desvio estão aumentando enquanto a qualidade e o CSAT se mantêm, está funcionando. Se o volume aumenta mas a satisfação está caindo, ou o bot responde com confiança sem citar nada, não está, não importa o quão ocupado pareça.
A armadilha é julgar um agente de IA pela atividade ("ele respondeu a 4.000 tickets!") em vez de pelos resultados. Um bot pode estar enormemente ocupado e silenciosamente errado. A solução é monitorar o pequeno conjunto de métricas descritas abaixo, aprender a identificar os sinais positivos e de alerta, e idealmente simular com seus tickets reais do passado antes de confiar nele ao vivo.
Passei os últimos três anos e mais implantando agentes de IA em filas de suporte ao vivo na eesel, então este é o scorecard que eu realmente usaria.
Por que "está funcionando?" é mais difícil do que parece
Aqui está o que a maioria dos painéis não vai te dizer. O modo de falha assustador para o suporte de IA não é o bot ficando em silêncio, é o bot soando muito bem enquanto está errado.
Já vi um agente de tom confiante dizer a um cliente "sim, suportamos o modelo do seu carro" para marcas que não estavam na base de conhecimento, simplesmente porque alguém escreveu "suportamos todos os modelos" em um documento de ajuda. O bot não estava quebrado. Estava fazendo exatamente o que foi dito, e parecia perfeitamente fluente fazendo isso. Essa é a razão pela qual agora simulamos cada implantação contra tickets históricos primeiro, em vez de acionar um interruptor e esperar.
Antes de chegar aos números: "funcionar" significa que a IA está resolvendo os tickets certos corretamente, transferindo o restante de forma limpa, e não inventando nada no meio. Contagens de atividade são vaidade. Os resultados são a verdade. Se você levar apenas uma ideia deste artigo, que seja essa.
Os cinco números que realmente informam
Quando as equipes me perguntam como interpretar seu agente de IA, eu os direciono para as mesmas cinco métricas de suporte ao cliente. Lidas juntas, elas capturam quase todos os modos de falha.
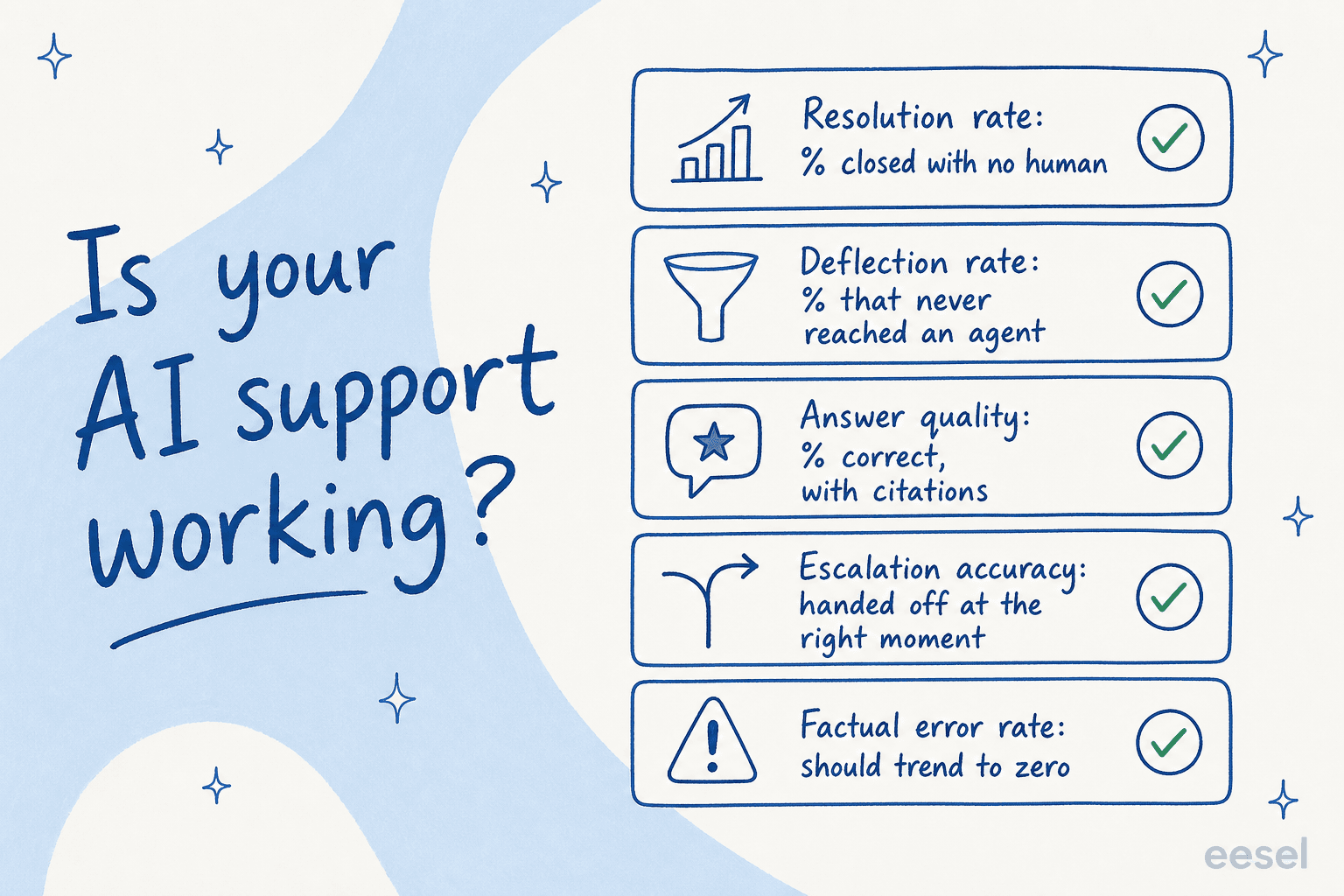
1. Taxa de resolução
O número principal: qual percentual de tickets a IA fechou de ponta a ponta sem um humano tocá-los. Este está diretamente ligado ao custo, porque cada ticket resolvido é um que um agente não teve que abrir.
O que é "bom"? Depende completamente do seu mix de tickets, mas o nível 1 é onde a IA ganha seu valor primeiro. Um aplicativo de análise de motoristas da economia gig no Zendesk nos disse, em uma avaliação pública no G2, que o eesel estava resolvendo 73% das solicitações de nível 1 no primeiro mês, com resultados visíveis em um período de teste de 7 dias. Na outra extremidade, um helpdesk interno de TI rodando no Jira começou com 15% de desvio e definiu uma meta de 55%. Ambos estão "funcionando". O ponto não é um benchmark universal, é a tendência: a taxa de resolução está aumentando à medida que você fornece mais conhecimento ao agente?
2. Taxa de desvio
Desvio e resolução são usados de forma intercambiável, e não deveriam ser. Resolução é um ticket fechado sem um humano. Desvio é um cliente que obteve sua resposta e nunca abriu um ticket, geralmente através de um widget de chat ou autoatendimento antes que a conversa se tornasse um caso de suporte.
Vale a pena rastrear separadamente, porque uma alta taxa de desvio é o que silenciosamente reduz sua fila. Se você quiser a definição precisa e a fórmula, escrevemos sobre o que é taxa de desvio e como melhorá-la, e um artigo separado sobre como medir o desvio de IA versus o desvio humano para que você não faça dupla contagem.
3. Qualidade das respostas
Volume sem qualidade é a armadilha. Então a verdadeira pergunta por trás da resolução é: quando a IA respondeu, ela estava certa, e mostrou seu trabalho?
Isso é mensurável. Em uma amostra de uma semana de 581 chats, avaliamos a qualidade dos chats em 96%. Em outra amostra de 434 chats, a distribuição foi 86% boa, 7% parcial, 6% desviada e 1% totalmente falha, e em tickets reais acionados por webhook (o teste mais difícil) foi 79% bom. O método exato importa menos do que ter um: avalie uma amostra de respostas quanto à exatidão e se elas carregavam uma citação. Uma resposta sem fonte anexada é uma resposta em que você não pode confiar. Um fundador de legal-tech com quem trabalhamos expressou bem: com o eesel eles podiam "definir limites exatos sobre as fontes e sempre fornece citações transparentes", o que em seu mundo é a diferença entre útil e uma ação judicial.
4. Precisão de escalonamento
Um bom agente de IA sabe o que não sabe. Portanto, a precisão de escalonamento é realmente uma medida de julgamento: quando a IA estava incerta, ela transferiu para um humano em vez de adivinhar?
Este é o número mais subestimado da lista. Você quer um agente que resolva com confiança e escale honestamente, não um que responda tudo. Um líder de suporte de uma plataforma de SMS capturou o ideal em uma avaliação do G2: a IA "responde com confiança, mas não com muita confiança." Essa segunda parte é todo o jogo. Acompanhe sua taxa de escalonamento e, mais importante, se os escalonamentos acontecem no momento certo.
5. Taxa de erros factuais
Por fim, o número que deve tender a zero: com que frequência a IA diz algo falso. Isso é diferente de respostas "parciais". Um erro factual é o bot afirmando um fato errado como se fosse certo.
Em um teste no tráfego real do Zendesk de um varejista alemão de joias (cerca de 1.000 tickets por mês), medimos 93% de precisão de triagem e 100% de detecção de spam sem falsos positivos, mas também uma taxa de erros factuais de 7% que nos disse exatamente onde a base de conhecimento tinha lacunas. Esses 7% não foram motivo para abandonar a implantação. Era um mapa. Cada erro factual aponta para um documento ausente ou contraditório, que geralmente é corrigível, e é o cerne do que nosso guia sobre como prevenir alucinações de IA no suporte aborda.
Os sinais positivos (e os sinais de alerta)
Os números mostram a tendência. Mas há sinais qualitativos que você pode identificar em uma única tarde percorrendo transcrições, e muitas vezes são mais rápidos do que esperar um mês de dados.
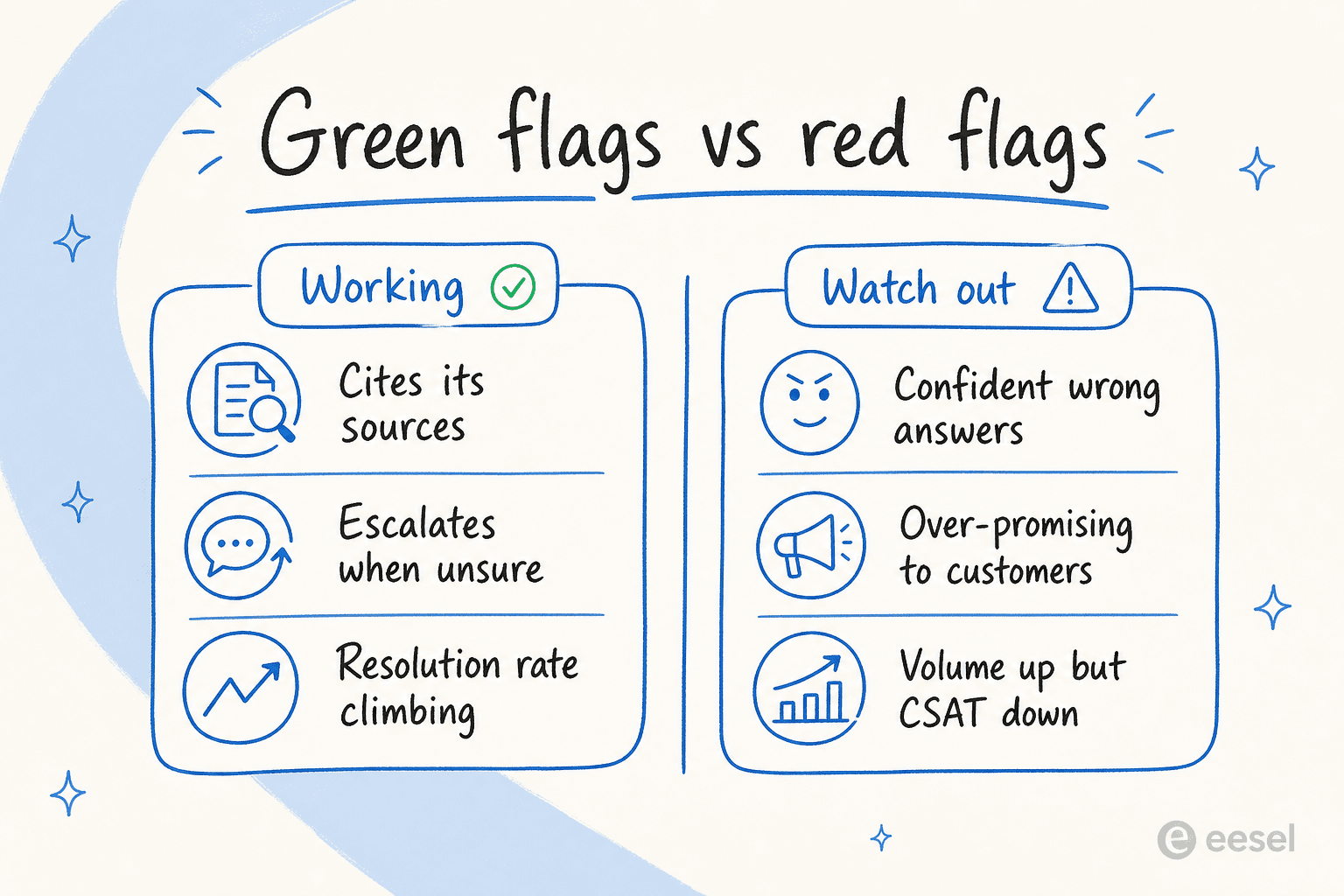
Os sinais positivos são os mais fáceis. A IA cita suas fontes em cada resposta. Ela escala quando está realmente insegura em vez de blefar. Sua taxa de resolução está tendendo para cima semana após semana, não estagnada. E, o sinal mais simples de todos, seus agentes param de reclamar de tickets repetitivos.
Os sinais de alerta são onde eu colocaria sua atenção, porque se escondem atrás de painéis que parecem bons:
- Respostas erradas dadas com confiança. O exemplo do modelo de carro mencionado antes. O bot é fluente, certo e incorreto. Este é o padrão mais prejudicial de todos, porque os clientes acreditam nele.
- Promessas excessivas. Já vi agentes tranquilizando clientes de maneiras que o negócio não pode sustentar. Um gerente de suporte sinalizou isso diretamente para nós, dizendo à IA para "parar de dizer aos clientes que vamos resolver o problema deles. Você não sabe disso," e "parar de prometer aos clientes coisas que não podemos fazer." Se seu bot está fazendo compromissos sobre datas de entrega ou resultados, isso é um problema de controle, não de conhecimento.
- Volume crescendo, CSAT caindo. O agente está lidando com mais, e os clientes estão menos satisfeitos. Essa divergência é o sinal mais claro de que "ocupado" e "funcionando" se separaram.
- Sem citações. Se você não pode ver de onde veio uma resposta, o cliente também não pode, e você também não quando estiver auditando mais tarde.
A maioria desses problemas tem origem em lacunas de conhecimento ou proteções ausentes, o que é uma boa notícia, porque ambos são corrigíveis sem desmontar nada. O artigo sobre problemas comuns de chatbots de IA aprofunda os culpados habituais.
Onde realmente procurar
Tudo isso pressupõe que você pode ver o que seu agente de IA está fazendo. Se sua ferramenta mostra apenas uma contagem total, esse é o primeiro passo a corrigir, porque você não pode gerenciar o que não consegue ler.
As duas visualizações que verifico com mais frequência são o painel de relatórios e o log de atividades bruto. A visualização de relatórios é onde vive a tendência: volume de tarefas ao longo do tempo, como as tarefas foram acionadas (chat, e-mail, nota interna) e quantas ações de IA foram aprovadas, rejeitadas ou ainda aguardam uma decisão humana. Essa proporção de aprovação versus rejeição é um indicador rápido de confiança.

O log de atividades é onde você lê o trabalho real. Cada conversa, seu canal, o ticket vinculado e se terminou resolvida ou pendente. É aqui que você vai para verificar amostras da qualidade das respostas e detectar os casos confiantes-errados que os números agregados suavizam. Eu revisaria dez destes por semana, no mínimo.

Se seu helpdesk já executa pesquisas de CSAT em conversas fechadas, vincule essas pontuações especificamente aos tickets tratados pela IA. Essa única análise — CSAT em tickets resolvidos pela IA versus os resolvidos por humanos — resolve a maioria dos debates "é realmente bom?" mais rápido do que qualquer outra coisa.
Não espere até estar ao vivo para descobrir
Aqui está a parte que a maioria das equipes pula, e a que eu mais enfatizaria: você não precisa descobrir se sua IA funciona testando-a em clientes reais.
O erro é tratar o lançamento como um interruptor liga/desliga. O modelo melhor é uma rampa. Você gradua a IA através de estágios de autonomia à medida que os números a justificam, não antes.
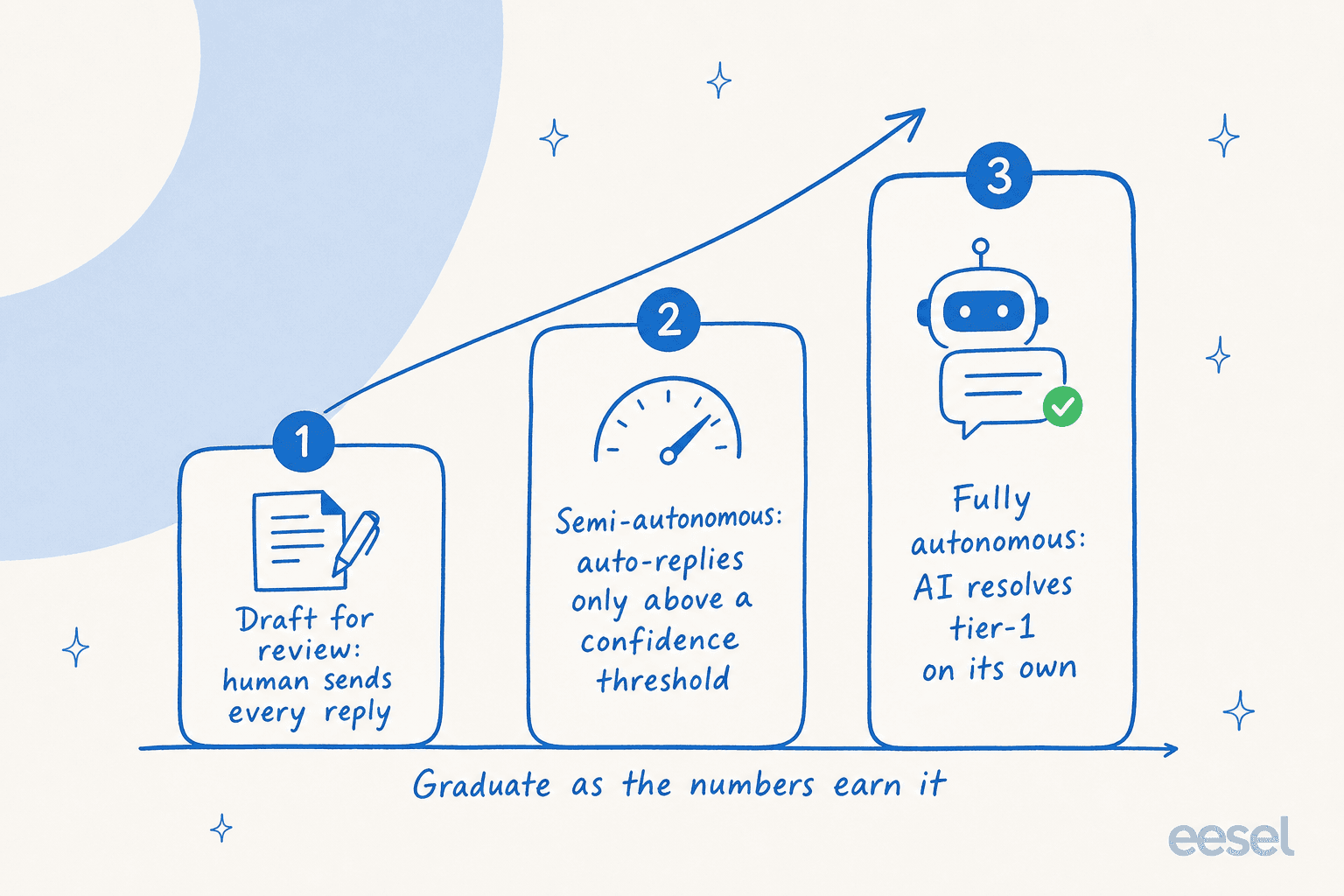
Você começa no modo rascunho, onde a IA escreve respostas mas um humano envia cada uma, então você está avaliando a qualidade sem nenhum risco para o cliente. À medida que as respostas se comprovam, você vai para semi-autônomo, deixando a IA responder automaticamente apenas acima de um limite de confiança e roteando o restante para uma pessoa. Uma vez que os números se sustentam, você a deixa funcionar totalmente de forma autônoma nos casos de nível 1 que ela conquistou.
Mesmo antes do modo rascunho, você pode executar uma simulação em milhares de seus tickets reais passados para ver exatamente como a IA teria respondido a cada um, com uma taxa de resolução prevista, antes que uma única resposta ao vivo seja enviada. Esse teste com a joalheria alemã que mencionei executou uma validação cruzada de 100 tickets precisamente dessa forma. Simular primeiro é a forma de responder "está funcionando?" antes de ter arriscado um único cliente. É também, honestamente, a parte que eu gostaria que mais equipes fizessem, porque transforma um salto de fé em uma medição.
Uma observação justa, já que trabalho nisso: o eesel se integra profundamente com helpdesks como Zendesk, Freshdesk e Help Scout, portanto não sou um observador neutro da categoria. Mas a abordagem de rampa e simulação se aplica independentemente da ferramenta que você usa. Se seu fornecedor de IA não consegue mostrar um teste com seus próprios tickets, isso em si é um sinal amarelo que vale a pena questionar.
Experimente o eesel
Se você quiser responder "meu suporte de IA está funcionando?" com números em vez de intuições, esse é o problema que o eesel foi criado para resolver. Você conecta seu helpdesk e fontes de conhecimento, instrui o agente em linguagem clara e executa uma simulação nos seus tickets passados para obter uma taxa de resolução prevista antes de entrar em produção, depois aumenta do modo rascunho para autonomia com os relatórios para apoiar cada etapa.

Funciona com preços baseados em uso sem taxas por assento, e há um nível gratuito para testá-lo na sua própria fila. Você pode ver como outras equipes mediram suas implantações na página de histórias de clientes, ou leia nosso guia prático de IA no suporte ao cliente para o manual completo. Experimente o eesel e descubra qual seria sua taxa de resolução real.
Perguntas frequentes
Como saber se meu suporte de IA está funcionando?
Qual é uma boa taxa de resolução para um agente de suporte de IA?
Como o desvio de IA difere da resolução de IA?
Quais são os sinais de alerta de que meu agente de suporte de IA está falhando?
Posso testar meu suporte de IA antes de deixá-lo responder aos clientes?

Article by
Alicia Kirana Utomo
Kira is a writer at eesel AI with a Computer Science background and over a year of hands-on experience evaluating AI-powered customer service tools. She focuses on breaking down how helpdesk platforms and AI agents actually work so that support teams can make better buying decisions.