Resumo
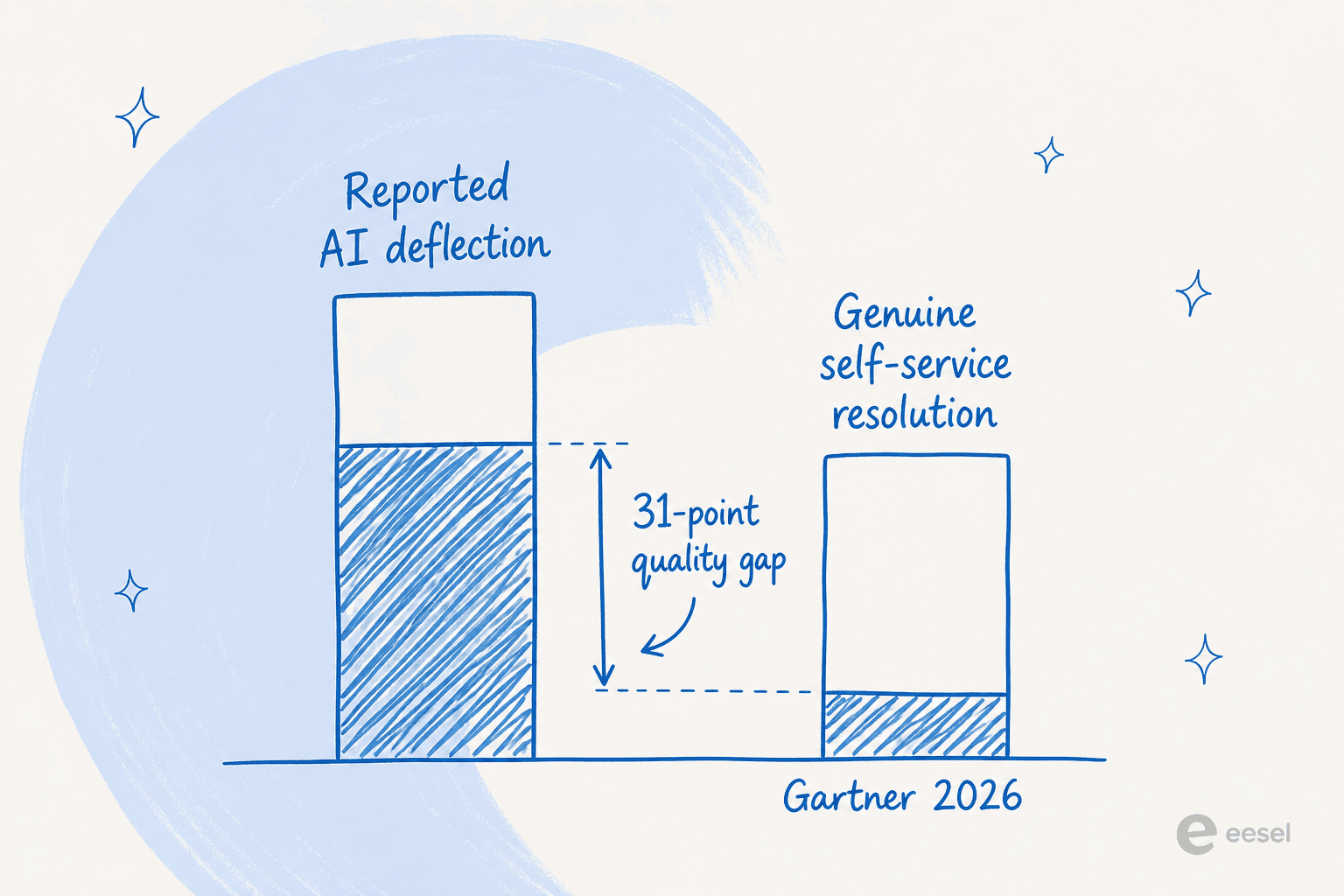
A maioria das equipes que reportam 40-60% de deflexão de tickets com IA está medindo a coisa errada. A pesquisa do Gartner de 2026 mostra que a IA deflecte mais de 45% das consultas dos clientes - mas apenas cerca de 14% chegam a uma resolução genuína de autoatendimento. A lacuna de ~31 pontos entre esses dois números é o que a maioria dos dashboards esconde silenciosamente.
Equipes que atingem deflexão real acima de 70% compartilham três características: uma base de conhecimento construída a partir de tickets reais encerrados e atualizada semanalmente, integrações profundas com CRM e sistemas de pedidos, e roteamento por confiança que sabe quando não tocar em um ticket. O eesel AI foi construído em torno desse framework - e os resultados tendem a aparecer rapidamente. O cliente eesel Gridwise resolveu 73% das solicitações de nível 1 no primeiro mês após um teste de 7 dias.
Este guia cobre como é a deflexão real, os quatro alavancas que a movem, uma sequência de configuração em seis etapas e o que faz a maioria das implantações parar em 20-30%.
O número de deflexão que seu dashboard mostra pode não significar o que você pensa
Aqui está um padrão que se repete em muitas equipes de suporte: elas implantam um chatbot de IA, observam a métrica principal de deflexão subir para 55% e consideram uma vitória. Então o CSAT deriva. As taxas de recontato dos clientes sobem. As notas de churn começam a citar "não conseguiu obter ajuda."
O que aconteceu é o que o Gartner chama de lacuna de qualidade: a IA suprimiu o ticket, não o problema do cliente. O cliente não escalou formalmente - desistiu do bot e voltou por e-mail na manhã seguinte. Isso conta como "deflectido" na maioria dos dashboards.
Profissionais de automação de tickets de suporte com experiência no assunto tratam a taxa de deflexão como um indicador defasado, não como uma métrica de sucesso. O sinal antecipado é a taxa de recontato em 48 horas: se o mesmo cliente entrar em contato novamente por qualquer canal dentro de dois dias de uma interação "deflectida", a deflexão foi falsa.
"Otimizar para deflexão de tickets com IA quase arruinou nossa taxa de churn. Pare de usar bots como porteiros."
Quando as equipes tratam a taxa de deflexão como o KPI principal, os incentivos se invertem. Tornar o bot mais difícil de escapar - menos opções de "falar com um humano", mais etapas em loop - aumenta o número enquanto afasta os clientes. As equipes que atingem deflexão real acima de 70% quase nunca são as que manipulam a métrica principal; são as que constroem para resolução genuína.
O risco em termos diretos: um estudo de 100.050 interações descobriu que sistemas de IA operando em bases de conhecimento inadequadas tinham 37% mais probabilidade de afastar os problemas da resolução do que agentes humanos. Confiante e errado é pior do que escalonar.
O que é deflexão de tickets com IA de verdade
Em sua essência, a deflexão de tickets com IA é o processo de resolver consultas de clientes antes que se tornem tickets formais exigindo um agente humano. O cliente recebe uma resposta precisa imediatamente - e nunca entra na fila de ninguém.
A deflexão moderna é categoricamente diferente dos bots baseados em regras de cinco anos atrás. Os sistemas atuais usam:
- Grandes modelos de linguagem para entender linguagem natural, incluindo consultas vagas ou com erros de digitação
- Geração aumentada por recuperação (RAG) para basear as respostas na base de conhecimento específica da sua empresa, não nos dados de treinamento geral do modelo
- Pontuação de confiança para decidir em tempo real se deve resolver automaticamente, rascunhar para revisão ou escalonar imediatamente
- Integrações com CRM e backend para responder perguntas específicas da conta ("onde está meu pedido?", "por que fui cobrado?") com dados reais
- Ações agênticas para executar tarefas diretamente - não apenas responder, mas iniciar um reembolso, redefinir uma senha ou atualizar uma assinatura
Três padrões de implantação parecem diferentes na prática:
- Widget de chat / chatbot - uma bolha voltada para o cliente que responde perguntas antes que um ticket seja enviado. Chatbots de suporte ao cliente com IA são a superfície de deflexão mais comum.
- Deflexão pré-envio - o portal sugere artigos relevantes da KB e respostas de IA ao cliente antes de ele terminar de enviar um ticket. Se a resposta estiver lá, ele nunca clica em enviar.
- Resolução automática na fila - a IA processa tickets já na fila, resolve os que consegue tratar com confiança e encaminha o restante para humanos. É para isso que as ferramentas de triagem de tickets com IA e classificação de tickets com IA foram criadas.
O cálculo de custos funciona rapidamente em escala. Tickets tratados por IA custam em média US$ 0,50-1,05 cada; tickets tratados por humanos custam em média US$ 8-12 - um diferencial de custo de 12x a 24x por interação (Gartner 2025, Forrester 2025). A IA da Klarna agora cuida de dois terços de todo o atendimento ao cliente, equivalente a 700 agentes em tempo integral. A Bilt Rewards trata 70% de seus 60.000 tickets mensais com agentes de IA. É assim que se parece a automação de suporte ao cliente com IA bem implementada quando os pilares certos estão em funcionamento.
Como a deflexão por IA funciona por baixo dos panos
O loop de decisão dentro de um sistema de deflexão moderno funciona aproximadamente nesta ordem:
- Análise de intenção - o LLM lê a consulta e identifica o que o cliente quer, quem é ele e a urgência e tom da mensagem
- Recuperação de conhecimento - o sistema pesquisa as fontes de KB conectadas (artigos da central de ajuda, tickets resolvidos anteriormente, documentos, páginas do Confluence) por conteúdo semanticamente correspondente
- Síntese da resposta - o LLM elabora uma resposta baseada no conteúdo recuperado, não em seus dados de treinamento gerais
- Pontuação de confiança - o sistema avalia a qualidade de sua própria resposta e decide o que fazer a seguir
- Ação ou roteamento - com base na confiança, ele resolve o ticket, rascunha para revisão humana ou escala imediatamente
- Chamada de backend se necessário - para consultas específicas da conta, o sistema busca dados de pedido, histórico de cobrança ou status da conta nos sistemas conectados
- Transferência com contexto completo se escalonando - ao escalonar, tudo acompanha o ticket: a consulta, o que a IA tentou, quais fontes pesquisou e qual pontuação de confiança retornou
O roteamento por confiança é a decisão mais importante no loop - e a mais frequentemente mal configurada. O limite entre "resolver automaticamente" e "rascunhar para revisão humana" não é um número fixo; é calibrado por equipe e por tipo de ticket, e muda conforme a KB evolui.
Um líder de CX de uma marca de suplementos DTC que gerencia cerca de 7.000 tickets do Gorgias por mês fez a declaração mais clara possível de por que o roteamento por confiança é determinante:
"A IA nunca será capaz de responder 100% das perguntas, mas se ela tentar e apenas responder 'desculpe, não sei isso', não posso verificar todos os meus 7.000 tickets para ver se a IA realmente deu uma boa resposta - então o ponto se perde um pouco. Preciso de uma IA que cuide apenas dos tickets que tem confiança em tratar e todos os outros, que os deixe em paz."
Esse é o requisito de controle destilado em uma frase. É também o que separa agentes de suporte ao cliente com IA úteis de bloqueadores de tickets com aparência sofisticada - e o que faz com que IA e suporte humano ao cliente funcionem como um complemento genuíno em vez de uma substituição desajeitada.
As quatro alavancas que movem a taxa de deflexão real
A lacuna entre 20% de deflexão e 70% de deflexão quase nunca é o modelo de IA. São essas quatro variáveis - e como cada uma está configurada de forma precisa.
1. Qualidade da base de conhecimento
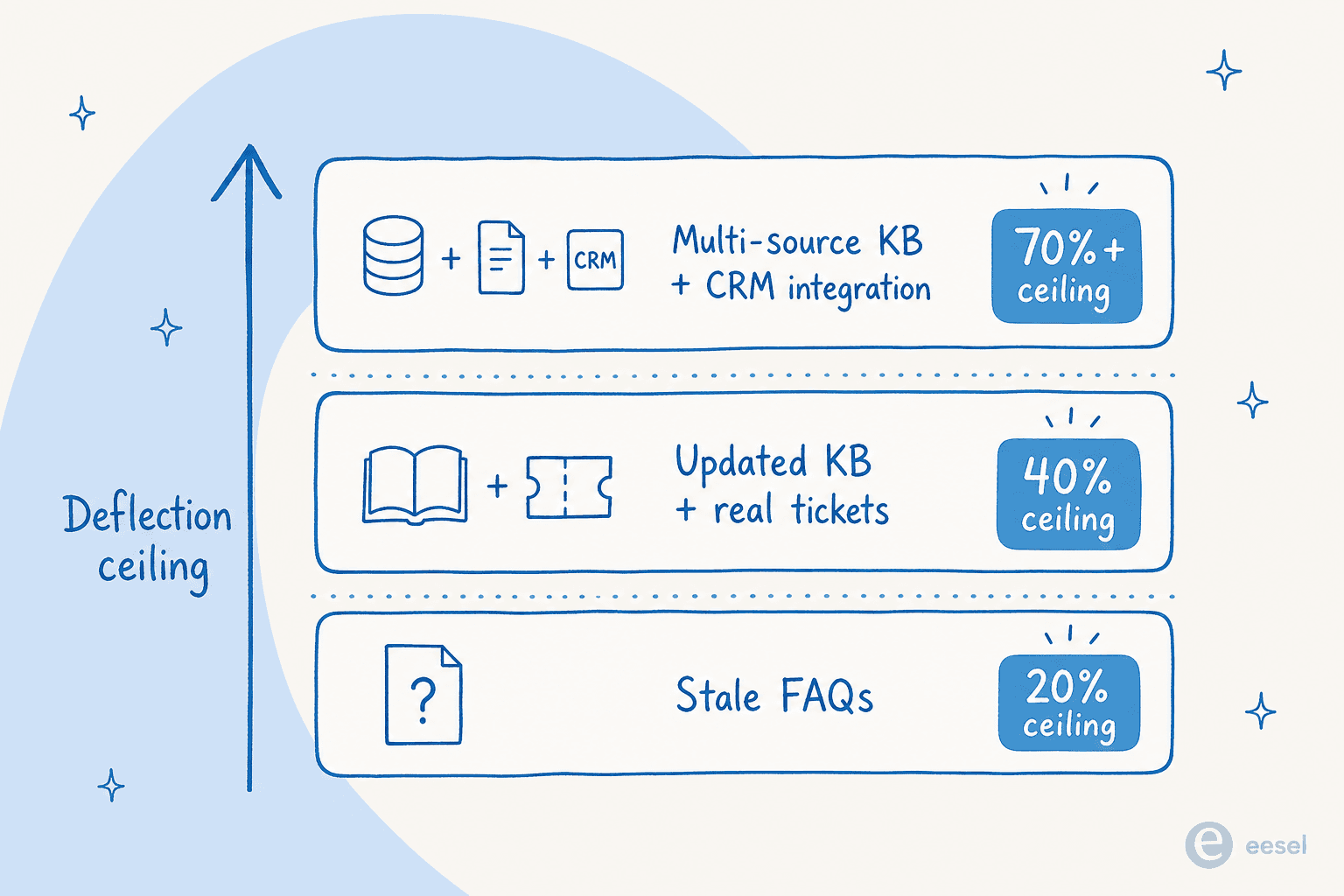
O teto da sua taxa de deflexão é definido pela sua base de conhecimento, não pelo seu modelo de IA. Um sistema de recuperação só consegue apresentar o que existe e está atualizado. Se seus documentos estão desatualizados, fragmentados, escritos para equipes internas em vez de clientes, ou sem cobertura dos seus principais tipos de consulta - a IA vai alucinar ou reconhecer corretamente que não consegue responder e escalonar.
Documentação bem estruturada com atualizações semanais a partir de tickets encerrados aumenta as taxas de resolução genuína em 15-25% segundo os benchmarks de produção de 2026 da ClarityArc. Os formatos de KB mais prontos para deflexão: pares de perguntas e respostas em linguagem natural derivados de tickets reais, artigos curtos respondendo cada um a uma pergunta claramente e conteúdo atualizado sempre que um novo padrão de consulta surge nos logs de escalonamento.
O eesel AI extrai conhecimento de onde ele realmente vive - Confluence, Notion, Google Drive, tickets anteriores do Zendesk ou Freshdesk, SharePoint, PDFs enviados - e os combina em uma camada pesquisável. A IA voltada para o cliente utiliza todos eles em tempo real, portanto a qualidade da deflexão é atualizada quando seus documentos são atualizados. Veja como treinar IA em sua base de conhecimento para a configuração de indexação e ferramentas de base de conhecimento com IA para uma comparação mais ampla.
2. Profundidade de integração
A maioria das consultas de suporte reais não é respondida apenas pelo conteúdo da KB - elas precisam de dados específicos da conta. "Onde está meu pedido?" precisa do seu sistema de pedidos. "Por que fui cobrado duas vezes?" precisa dos seus registros de cobrança. "Posso fazer upgrade?" precisa da sua camada de assinatura.
Uma IA que só consegue recuperar artigos da KB mas não consegue chamar sistemas de backend vai falhar em uma parcela significativa das consultas recebidas em qualquer empresa de e-commerce, SaaS ou fintech. Adicionar integrações de CRM e gestão de pedidos geralmente adiciona 20-30 pontos percentuais à qualidade da deflexão (ClarityArc). É por isso que a automação de roteamento de tickets do Zendesk, a automação de tickets do HubSpot e as alternativas de IA para Freshdesk têm desempenho materialmente melhor assim que a IA é conectada à camada de dados, não apenas à camada de KB.
O catálogo de integrações do eesel cobre Zendesk, Freshdesk, Gorgias, Shopify, HubSpot, Salesforce e mais de 100 outros sistemas, para que a IA possa responder consultas específicas da conta com dados reais em vez de uma resposta genérica.
3. Limites de confiança
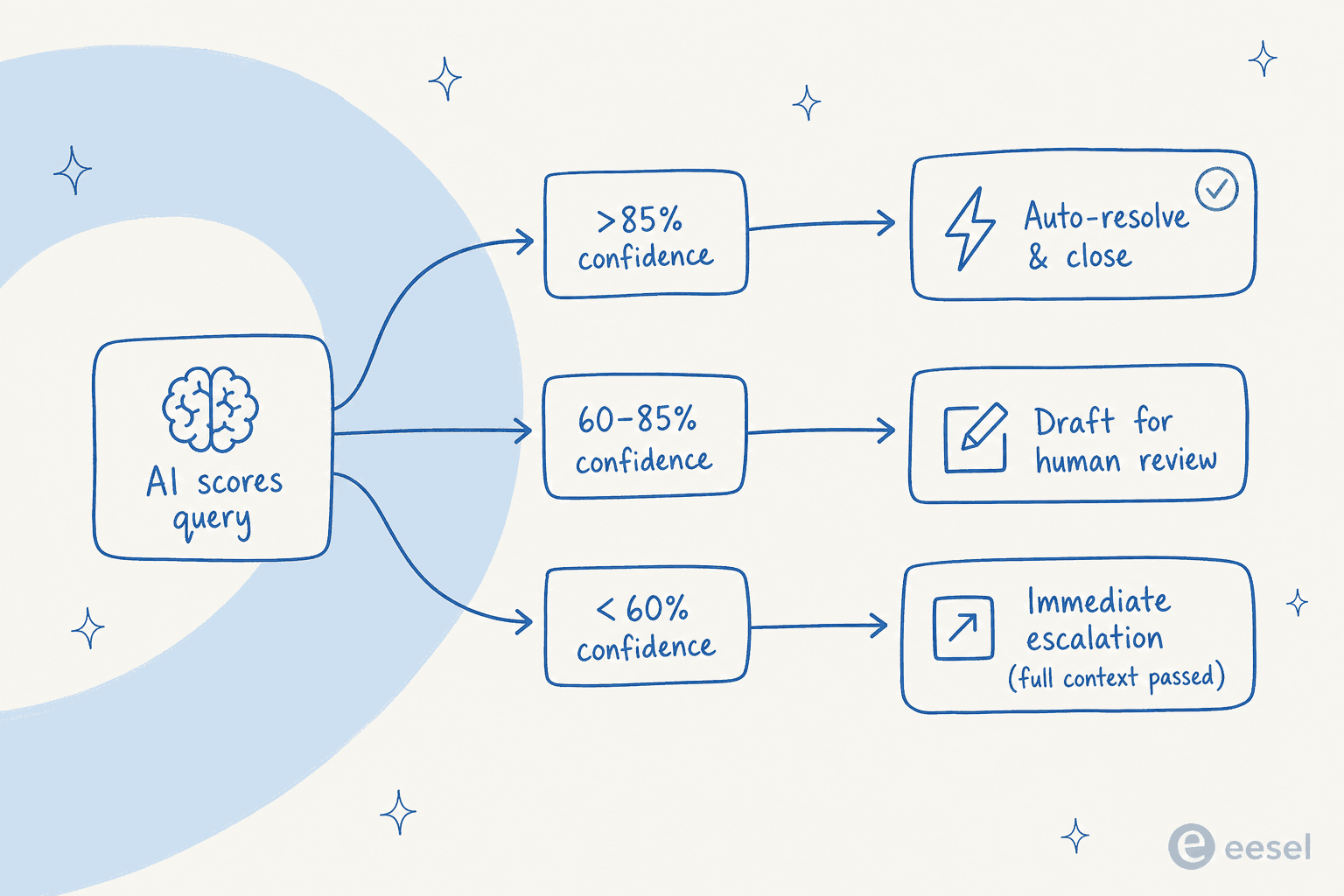
O roteamento por confiança é o mecanismo de controle que torna a IA implantável em escala sem supervisão constante. Três níveis funcionam confiavelmente em produção:
- Alta confiança (normalmente >85%) - resolver automaticamente e fechar. São suas consultas mais limpas e mais repetidas, com boa cobertura da KB e sem ambiguidade.
- Confiança média (60-85%) - rascunhar uma resposta para revisão humana antes de enviar. A IA faz ~80% do trabalho; o humano aprova. Com o tempo, você verá quais tipos de intenção consistentemente chegam aqui e decidirá se os promove para resolução automática.
- Baixa confiança (<60%) - escalonamento imediato, com contexto completo passado para o agente. Sem becos sem saída.
A maioria das equipes começa muito conservadora (tudo passa pela revisão humana) ou muito agressiva (limite tão alto que a IA resolve automaticamente coisas que erra). A calibração leva 2-4 semanas de tráfego real. Os guias de configuração de resposta de IA do Zendesk explicam a configuração de limite para implantações no Zendesk.
4. Design de escalonamento
Nenhum sistema de deflexão trata toda a gama de intenção do cliente. Os clientes que ele não consegue ajudar precisam de um caminho rápido e claro para um humano - e esse humano precisa de contexto completo.
Um escalonamento bem projetado: acessível em 1-2 interações (sem loops de bot), passa o contexto completo da conversa em vez de apenas a mensagem final, nunca faz o cliente reexplicar sua situação e roteia para o tipo certo de agente em vez da fila geral.
O design de escalonamento ruim é o motivo número 1 pelo qual as equipes recebem reclamações de chatbot de IA não respondendo corretamente mesmo quando a IA em si está funcionando corretamente. O bot estava bem; o beco sem saída era o problema. Para ferramentas de chatbot de IA sem código, o design de escalonamento é frequentemente onde as opções prontas ficam aquém - vale a pena testar sob pressão antes de se comprometer com uma plataforma.
Configurando para deflexão real: seis etapas
Etapa 1: Audite sua KB antes de comprar qualquer coisa
Antes de avaliar qualquer fornecedor, responda honestamente: Quão atualizada está sua documentação? Quando foi a última vez que foi atualizada com tickets reais encerrados? Ela cobre seus 30 principais tipos de consulta com respostas curtas e claras? Se as respostas forem "misto" ou "não temos certeza", comece aí. Nenhuma IA corrige uma KB fraca - ela apenas revela as lacunas mais rapidamente e de forma menos gentil do que um humano faria.
Etapa 2: Comece com 2-3 tipos de intenção de alto volume e alta cobertura
Não tente cobrir tudo no lançamento. Escolha os 2-3 tipos de ticket que são: alto volume, claramente respondíveis a partir da sua KB existente e de baixa complexidade - redefinições de senha, status de pedido, FAQ de cobrança, status de reembolso. Essas são suas intenções com maior potencial de deflexão e onde a equipe ganha confiança mais rapidamente.
Ser muito abrangente no lançamento é o erro de configuração mais consistente. Ferramentas de triagem de tickets com IA podem ajudá-lo a mapear a distribuição real das intenções recebidas antes de definir o escopo.
Etapa 3: Conecte CRM e dados de pedidos antes de entrar em produção
Se seus clientes frequentemente perguntam "onde está meu pedido?" e sua IA não consegue consultar dados reais de pedidos - você cobriu as intenções erradas primeiro. Mapeie quais dos seus tipos-alvo precisam de chamadas de dados de backend e certifique-se de que essas integrações estejam ativas antes do lançamento. Para equipes de e-commerce e assinatura, isso não é opcional - IA para suporte ao cliente do Shopify e software de helpdesk para e-commerce cobrem os padrões de integração que funcionam.
Etapa 4: Defina limites de confiança conservadores e depois relaxe-os
Comece com um limite que encaminhe aproximadamente 80% das respostas pela revisão humana. Isso parece lento, mas gera dados rapidamente: você verá rapidamente quais tipos de intenção a IA trata consistentemente e poderá promover para resolução automática. Em 2-3 semanas você terá tráfego real suficiente para tomar decisões de limite empiricamente em vez de intuitivamente.
Etapa 5: Trate cada escalonamento como um sinal para a KB
Incorpore uma revisão semanal ao fluxo de trabalho. Qual foi a razão de escalonamento mais comum esta semana? Lacuna de KB (conteúdo não existe)? Lacuna de escopo (tipo de intenção não coberto)? Descalibração de confiança (conteúdo existe mas a recuperação não o está encontrando)? Cada categoria tem uma correção diferente. As equipes que fazem essa revisão semanal são as que chegam a 70%+ em 60 dias.
Etapa 6: Meça a taxa de recontato, não apenas a deflexão principal
Configure um relatório que verifique: para cada ticket marcado como "deflectido", o mesmo cliente entrou em contato com o suporte novamente dentro de 48 horas por qualquer canal? Esse número é sua taxa de deflexão falsa. Subtraia-o do número principal para obter o real - aquele que seus dados de CSAT e churn acabarão validando de qualquer maneira.
Três padrões onde a deflexão estagna (e a correção para cada um)
Padrão 1: IA confiante, KB desatualizada
Uma IA operando em documentação com seis ou mais meses de desatualização vai responder com confiança e incorretamente. A correção: um processo semanal de atualização da KB impulsionado por análise de tickets encerrados, onde cada ticket resolvido que revela uma lacuna de documentação aciona uma atualização de artigo. Construindo uma base de conhecimento para ChatGPT e o guia de base de conhecimento do Gorgias cobrem o fluxo de trabalho de atualização para stacks de helpdesk comuns.
Padrão 2: Escopo muito amplo desde o primeiro dia
Um gerente de suporte de um serviço de rastreamento de ônibus (200-250 tickets do Zendesk por mês) resumiu o briefing correto: eles queriam que a IA "tratasse 60% dos tickets recebidos do Zendesk e soubesse quando envolver uma pessoa real para melhor análise e resolução." Escopo definido, específico, realista. Equipes que tentam resolver automaticamente todos os tipos de intenção desde o lançamento consistentemente têm desempenho inferior às equipes que acertam em 3 tipos de intenção primeiro e expandem a partir daí.
Padrão 3: Sem profundidade de integração para consultas de conta
Uma equipe de operações de e-commerce que gerencia cerca de 7.000 tickets do Gorgias por mês encontrou seu problema rapidamente: WISMO, mudanças de assinatura e perguntas básicas sobre produtos dominavam a fila - todos exigindo acesso real ao sistema de pedidos. Uma IA com apenas acesso à KB não conseguia responder nenhum deles com precisão, independentemente de quão bem a KB estava escrita. É por isso que chatbots superficiais atingem um platô rapidamente para empresas de e-commerce e assinatura sem a camada de integração. Principais ferramentas de IA para automatizar o suporte ao cliente e ferramentas de IA para equipes de suporte ao cliente cobrem o que avaliar em profundidade de integração antes de se comprometer.
Uma pequena equipe de suporte de e-commerce no Zendesk descreveu como foi acertar nisso: "Realmente alivia nossa pequena equipe de suporte de ser sobrecarregada por perguntas que podem ser facilmente respondidas por uma IA simples." A diferença entre sobrecarregado e aliviado quase sempre se resume a se a IA consegue recuperar as informações certas e agir sobre elas.
Experimente o eesel
O eesel AI foi criado para o caso de uso de deflexão de tickets: lê de onde o conhecimento da sua equipe realmente vive (Confluence, Notion, Google Drive, Zendesk, Freshdesk, Gorgias, tickets anteriores, SharePoint, PDFs), opera nativamente dentro do seu helpdesk sem exigir uma troca de plataforma, e começa no modo rascunho-para-revisão para que sua equipe calibre os limites de confiança no tráfego real antes de ir totalmente autônomo.

A configuração é rápida. O Gridwise - um aplicativo de análise para motoristas de gig economy no Zendesk - implementou o eesel e viu resultados em um teste de 7 dias. 73% das solicitações de nível 1 foram resolvidas no primeiro mês, sem transferência humana nesses tickets.
O preço é baseado em tarefas a US$ 0,40/ticket sem taxa de plataforma - uma equipe executando 500 deflexões por semana paga US$ 200/semana, versus US$ 4.000-6.000 para o mesmo volume tratado por agentes humanos. O eesel se conecta ao Slack, mais de 100 helpdesks e ferramentas de conhecimento, e suporta mais de 80 idiomas nativamente. Comece com US$ 50 em uso gratuito - sem necessidade de cartão de crédito - e veja as taxas de deflexão reais nos seus próprios dados de tickets antes de se comprometer.
Para guias específicos de stack: Zendesk AI para suporte ao cliente, software de helpdesk para pequenas empresas e principais ferramentas de suporte ao cliente são pontos de referência úteis. Para uma comparação mais ampla do mercado: os aplicativos de IA mais baratos para helpdesk e deflexão de tickets do Decagon valem a leitura antes de se comprometer.
Perguntas Frequentes
O que é deflexão de tickets com IA?
Qual é uma boa taxa de deflexão de tickets com IA?
Por que meu chatbot de IA não está deflectindo tickets suficientes?
Qual é a diferença entre deflexão de tickets com IA e triagem de tickets?
Quanto tempo leva para ver resultados da deflexão de tickets com IA?
Quanto custa a deflexão de tickets com IA por ticket?

Article by
Riellvriany Indriawan
Riell is a designer and writer at eesel AI with about two years of experience researching CX platforms, AI chatbots, and helpdesk software. She combines her design background with a sharp eye for how these tools actually look and feel in practice — making her comparisons unusually visual and user-focused.