
Résumé
Les tarifs de l'API Groq commencent à 0,05 $ par 1M tokens en entrée pour Llama 3.1 8B - l'un des prix d'inférence LLM les moins chers disponibles. Le niveau gratuit (sans carte bancaire, 30 RPM) est véritablement utilisable pour le prototypage. L'API payante fait tourner des modèles open source à 280–1 000 tokens par seconde sur du matériel LPU personnalisé, généralement 10 à 20 fois moins cher que les modèles OpenAI équivalents. Le bémol : le catalogue de Groq est entièrement open source - pas de GPT-4o, pas de Claude, pas de Gemini. Si votre infrastructure peut fonctionner avec Llama, Qwen ou Whisper, Groq est souvent la solution à la fois la plus rapide et la moins chère. Deux remises sont faciles à manquer : l'API batch réduit les coûts de 50 % pour les charges asynchrones, et le cache de prompt divise automatiquement par deux le coût des préfixes d'entrée répétés.
Si vous créez une IA orientée client, eesel déploie des agents support autonomes par-dessus une inférence rapide - utile à savoir si vous évaluez Groq pour un cas d'usage helpdesk.
Qu'est-ce que Groq (et pourquoi la tarification fonctionne-t-elle différemment ici) ?
Groq ne crée pas de modèles - ils font tourner les modèles des autres (Llama, Qwen, Mistral, Whisper, modèles open-weight d'OpenAI) sur leur propre silicium personnalisé : le Language Processing Unit, ou LPU. Fondé en 2016 par d'anciens ingénieurs de Google TPU, ils ont levé 750 M$ à une valorisation de 6,9 Md$ en septembre 2025 et servent désormais plus de 2 millions de développeurs. L'équipe McLaren F1 utilise Groq pour l'analyse de course en temps réel - un cas d'usage où « généralement rapide » n'est pas acceptable.
Le modèle de tarification est simple : facturer par token, sans frais d'infrastructure inactive, sans pics de tarification élastique. La déclaration officielle de Groq à ce sujet : « D'autres fournisseurs d'inférence font monter les coûts sans prévenir. Certains se cachent derrière une tarification élastique. La tarification de Groq est linéaire et prévisible, sans coûts cachés ni infrastructure inactive. »

Pourquoi le LPU change la donne en matière de coûts
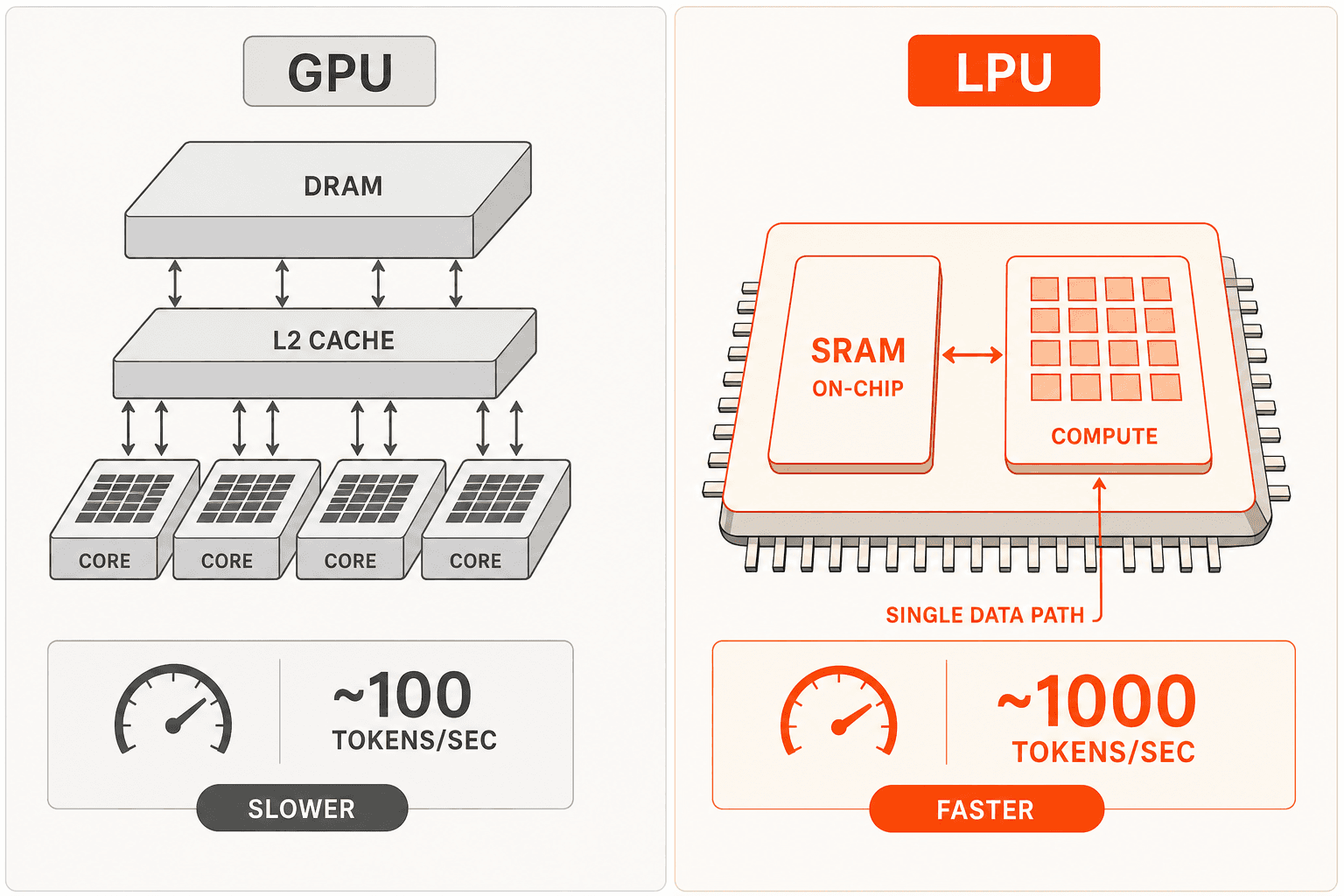
Les GPU ont été conçus pour l'entraînement : de grandes hiérarchies mémoire DRAM/HBM externes, une ordonnancement dynamique, des protocoles de cohérence de cache. Ce sont de bonnes propriétés pour paralléliser des opérations matricielles sur des milliers de cœurs lors de l'entraînement. Elles sont mal adaptées à l'inférence, où l'exécution séquentielle des couches a une faible intensité arithmétique et où les accès mémoire dominent la latence.
L'architecture LPU adopte une approche différente. La SRAM sur puce sert de stockage principal des poids - pas un cache, mais la mémoire principale. Le compilateur dédié de Groq préordonnance chaque opération jusqu'aux cycles d'horloge individuels avant le démarrage de l'exécution, éliminant entièrement la surcharge d'ordonnancement dynamique. Le protocole RealScale chip-à-chip permet à des centaines de LPU de se comporter comme un seul cœur pour le parallélisme tensoriel. Parce que chaque opération est ordonnancée statiquement, Groq peut faire tourner le parallélisme de pipeline par-dessus le parallélisme tensoriel : la couche N+1 commence à traiter pendant que la couche N se termine - quelque chose que l'ordonnancement dynamique des GPU ne peut pas faire de manière fiable.
Le résultat pratique : GPT OSS 20B à 1 000 tokens par seconde. Llama 3.1 8B à 560–840 TPS. Llama 3.3 70B à 280–394 TPS. Les API cloud basées sur GPU typiques tournent à 50–100 TPS sur des modèles équivalents. Quand le même matériel traite plus de requêtes par seconde, les coûts fixes se répartissent sur plus de tokens - c'est ainsi que 0,05 $ par 1M tokens en entrée devient commercialement viable.

Niveau gratuit de Groq : ce que vous obtenez vraiment
Le niveau gratuit ne nécessite pas de carte bancaire et est régi par des limites de débit, et non par un budget mensuel de tokens. Voici exactement ce que chaque modèle fournit sur le plan gratuit :
| Modèle | RPM | TPM | Requêtes/jour |
|---|---|---|---|
llama-3.1-8b-instant | 30 | 6 000 | 14 400 |
llama-3.3-70b-versatile | 30 | 12 000 | 1 000 |
meta-llama/llama-4-scout-17b-16e-instruct | 30 | 30 000 | 1 000 |
openai/gpt-oss-20b | 30 | 8 000 | 1 000 |
openai/gpt-oss-120b | 30 | 8 000 | 1 000 |
qwen/qwen3-32b | 60 | 6 000 | 1 000 |
groq/compound | 30 | 70 000 | 250 |
whisper-large-v3 | 20 | - | 2 000 req. audio |
whisper-large-v3-turbo | 20 | - | 2 000 req. audio |
(RPM = requêtes par minute, TPM = tokens par minute. Source : documentation des limites de débit Groq)
Deux choses surprennent les développeurs ici. Premièrement, les limites de débit s'appliquent au niveau de l'organisation, pas par clé API. Créer cinq clés ne vous donne pas 150 RPM - il reste 30 RPM partagés sur l'ensemble de votre compte. Deuxièmement, les tokens de cache de prompt ne comptent pas dans les limites de débit, ce qui est un avantage significatif si vous avez de longs prompts système qui se répètent entre les appels.
Les limites TPM par minute sont généralement la vraie contrainte, pas les plafonds de requêtes quotidiennes. Un prompt de 2 000 tokens consomme un tiers du budget TPM de Llama 8B en un seul appel.
« J'utilise l'API Groq sans arrêt, en me disant constamment 'comment je n'ai toujours pas atteint une quelconque limite du niveau gratuit' » - @ctatedev, mai 2024
Le niveau gratuit Whisper est la vraie perle. Artificial Analysis a confirmé que Groq est l'un des fournisseurs Whisper Large v3 les moins chers. Sur le plan gratuit, vous obtenez 2 000 requêtes de transcription audio par jour - environ 2 heures d'audio par heure d'horloge en regroupant au minimum de 10 secondes par requête. OpenAI facture 0,36 $/heure pour l'accès à Whisper ; le niveau payant de Groq facture 0,04 à 0,111 $/heure, donc le niveau gratuit est un point de départ généreux.
« Leur API gratuite pour la transcription vocale est incroyable, très généreuse, je la recommande vivement. »
Avis Trustpilot, recherche dérivée

Tarifs de l'API payante Groq : chaque modèle
Tous les prix sont en USD par 1M tokens (entrée / sortie) sauf indication contraire. Source : page de tarification Groq.
Modèles texte/LLM
| Modèle | ID du modèle | Vitesse (TPS) | Contexte | Entrée $/1M | Sortie $/1M | Statut |
|---|---|---|---|---|---|---|
| Llama 3.1 8B Instant | llama-3.1-8b-instant | 560–840 | 128k | 0,05 $ | 0,08 $ | Production |
| GPT OSS 20B | openai/gpt-oss-20b | 1 000 | 128k | 0,075 $ | 0,30 $ | Production |
| Llama 4 Scout (17Bx16E) | meta-llama/llama-4-scout-17b-16e-instruct | 594–750 | 128k | 0,11 $ | 0,34 $ | Aperçu |
| GPT OSS 120B | openai/gpt-oss-120b | 500 | 128k | 0,15 $ | 0,60 $ | Production |
| Qwen3 32B | qwen/qwen3-32b | 400–662 | 131k | 0,29 $ | 0,59 $ | Aperçu |
| Llama 3.3 70B Versatile | llama-3.3-70b-versatile | 280–394 | 128k | 0,59 $ | 0,79 $ | Production |
| Kimi K2 Instruct | moonshotai/kimi-k2-instruct-0905 | - | - | 1,00 $ (0,50 $ en cache) | 3,00 $ | - |
| Llama Prompt Guard 2 22M | meta-llama/llama-prompt-guard-2-22m | - | 512 | 0,03 $ | 0,03 $ | Aperçu |
| Llama Prompt Guard 2 86M | meta-llama/llama-prompt-guard-2-86m | - | 512 | 0,04 $ | 0,04 $ | Aperçu |
Quelques remarques sur les modèles à mettre en avant. GPT OSS 20B - le modèle open-weight d'OpenAI, pas GPT-4 - tourne à 1 000 tokens par seconde à 0,075 $ en entrée / 0,30 $ en sortie. C'est simultanément le modèle le plus rapide de la plateforme et l'un des moins chers par token en sortie. Llama 4 Scout supporte les entrées visuelles (fichiers jusqu'à 20 Mo) mais reste en aperçu - ne le mettez pas encore en production. Kimi K2 est le seul modèle où le cache de prompt est explicitement intégré dans la ligne de tarification : 0,50 $ par 1M tokens d'entrée en cache contre 1,00 $ sans cache.
Les modèles Prompt Guard (0,03–0,04 $ par 1M tokens) sont des classificateurs de sécurité conçus pour détecter les tentatives d'injection de prompt et de contournement des restrictions - utiles si vous construisez une IA orientée client et que vous avez besoin d'une couche de filtre légère avant votre modèle principal.
Limites de débit du plan développeur
Le passage du niveau gratuit au plan développeur est substantiel :
| Modèle | TPM développeur | RPM développeur |
|---|---|---|
llama-3.1-8b-instant | 250 000 | 1 000 |
llama-3.3-70b-versatile | 300 000 | 1 000 |
openai/gpt-oss-20b | 250 000 | 1 000 |
openai/gpt-oss-120b | 250 000 | 1 000 |
meta-llama/llama-4-scout-17b-16e-instruct | 300 000 | 1 000 |
qwen/qwen3-32b | 300 000 | 1 000 |
whisper-large-v3-turbo | 400 000 ASH | 400 |
groq/compound | 200 000 | 200 |
(Source : console.groq.com/docs/models)
Comment les tarifs Groq se comparent à OpenAI et aux autres fournisseurs
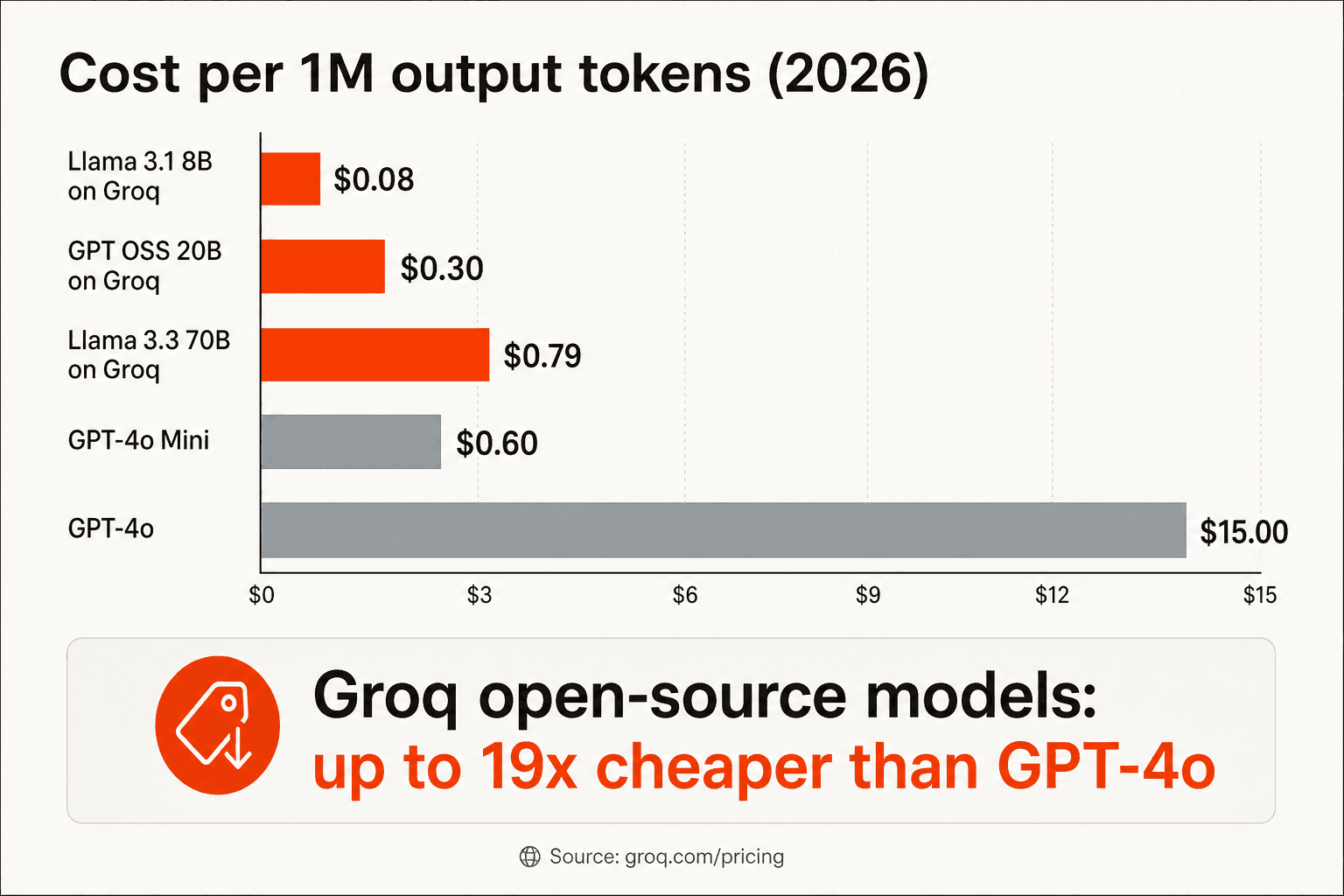
Le chiffre le plus souvent cité dans les communautés de développeurs est « 10 à 20 fois moins cher qu'OpenAI pour des modèles open source comparables. » C'est à peu près exact, avec la nuance nécessaire que vous ne comparez pas des modèles identiques.
« L'inférence LLM sur Groq coûte environ 10 fois moins par rapport aux tarifs d'OpenAI pour GPT-4o. Groq est 10 à 20 fois moins cher, mais pour un modèle un peu moins capable - Llama 3-70B vs GPT-4o. » - Balazs Kocsis, Medium, août 2024
La comparaison la plus honnête n'est pas Groq contre les modèles propriétaires d'OpenAI - c'est Groq contre d'autres fournisseurs d'hébergement open source comme Together AI ou Fireworks AI faisant tourner les mêmes modèles. Là, selon l'examen de production sur 8 semaines d'Awesome Agents, Groq est 20 à 50 % moins cher aux niveaux de modèles équivalents avec une latence de queue déterministe où p99 reste dans les 15 % de la médiane - un avantage significatif par rapport aux charges GPU où les pics de latence de queue sont courants.
« Adieu l'API OpenAI. Aujourd'hui, vous pouvez obtenir la même intelligence sous-jacente - Llama-3 ou ses concurrents open source - à des tarifs qui s'effondrent vers le plancher, souvent en dessous de 0,20 $ par million de tokens. C'est une réduction de prix de 99 % en dix-huit mois. » - Aparna Pradhan, GoPenAI, décembre 2025
Le modèle mental du praticien qui a émergé dans la communauté des développeurs - résumé par Jolly Gupta sur LinkedIn (114 likes, septembre 2025) : utiliser Groq pour les charges open source critiques en vitesse et en coût, utiliser OpenAI quand vous avez besoin des capacités de GPT-4o ou de sa profondeur multimodale. La plupart des stacks en production font les deux.
Groq est également apparu dans l'enquête Artificial Analysis comme l'un des 5 principaux fournisseurs d'inférence par adoption des développeurs - aux côtés d'OpenAI, Google, Anthropic et Microsoft.
Tarifs audio : Whisper et TTS
Reconnaissance vocale
Groq fait tourner les deux variantes de Whisper Large v3 sur du matériel LPU, livrant la transcription à une vitesse de 217 à 228x le temps réel. Une heure d'audio est traitée en environ 15 secondes.
| Modèle | Facteur de vitesse | Prix | Fichier max |
|---|---|---|---|
whisper-large-v3 | 217x temps réel | 0,111 $ / heure | 100 Mo |
whisper-large-v3-turbo | 228x temps réel | 0,04 $ / heure | - |
Pour la plupart des charges de travail, Turbo à 0,04 $/heure est le choix évident - plus rapide et 2,8x moins cher que le modèle complet, avec seulement des différences de qualité marginales sur la plupart des audios. L'audio est facturé avec un minimum de 10 secondes par requête quelle que soit la durée réelle, donc regrouper les clips courts ensemble vaut l'effort d'implémentation.
OpenAI facture 0,36 $/heure pour Whisper ; Groq à 0,04 $/heure est 9x moins cher sur le modèle Turbo. Levels.io a noté que Whisper + TTS sur Groq était « très bon marché » dès 2024 ; la tarification est restée stable depuis.
Synthèse vocale (Aperçu)
Groq a récemment lancé le TTS via les modèles Orpheus de Canopy Labs :
| Modèle | Prix | Notes |
|---|---|---|
canopylabs/orpheus-v1-english | 22,00 $ / 1M caractères | Anglais, ~100 caractères/sec |
canopylabs/orpheus-arabic-saudi | 40,00 $ / 1M caractères | Arabe (dialecte saoudien) |
Ces modèles sont encore en statut d'aperçu. L'avantage de vitesse du LPU est également visible ici - Orpheus génère à 100 caractères par seconde sur Groq, ce qui permet des applications vocales quasi temps réel.

Systèmes d'IA composés : quand les outils coûtent en supplément
Les systèmes composés de GroqCloud - groq/compound et groq/compound-mini - sont des wrappers agentiques qui donnent à un modèle de langage une recherche web et une exécution de code intégrées. La tarification correspond aux coûts de tokens du modèle plus l'utilisation des outils :
| Outil | Prix |
|---|---|
| Recherche web basique | 5 $ / 1 000 requêtes |
| Recherche web avancée | 8 $ / 1 000 requêtes |
| Visite de site web | 1 $ / 1 000 requêtes |
| Exécution de code | 0,18 $ / heure |
| Automatisation de navigateur | 0,08 $ / heure |
Le système Compound tourne à ~450 TPS avec un contexte de 131k. C'est un point de départ pratique pour les charges de travail d'IA agentique où vous souhaitez déléguer l'orchestration de l'utilisation des outils à la plateforme plutôt que de la construire vous-même.

Deux remises cachées à connaître
API batch : 50 % de réduction pour les charges asynchrones
L'API batch divise par deux le coût de n'importe quel modèle en exécutant les tâches de manière asynchrone. Vous soumettez un fichier JSONL (jusqu'à 50 000 lignes, 200 Mo), le traitement se termine dans les 24 heures à 7 jours, et vous payez 50 % du tarif standard par token. Aucun impact sur vos limites de débit standard.
C'est le bon choix pour : les pipelines de classification de documents, la génération de contenu en masse, l'enrichissement de données nocturne, la modération de contenu à grande échelle - tout ce où la tolérance à la latence vous rapporte une remise significative. L'utilisation des outils dans les systèmes Compound est toujours facturée aux tarifs standard.
Cache de prompt : 50 % de réduction sur les préfixes répétés
Le cache de prompt est automatique - pas de modifications de code, pas de frais supplémentaires. Lorsque le même préfixe (un long prompt système, un document de référence) se répète entre les appels, Groq le met en cache jusqu'à 2 heures. Les accès au cache coûtent 50 % du prix d'entrée normal.
Modèles supportant le cache de prompt et leurs tarifs en cache :
| Modèle | Entrée standard | Entrée en cache |
|---|---|---|
openai/gpt-oss-20b | 0,075 $ / 1M | 0,0375 $ / 1M |
openai/gpt-oss-120b | 0,15 $ / 1M | 0,075 $ / 1M |
moonshotai/kimi-k2-instruct-0905 | 1,00 $ / 1M | 0,50 $ / 1M |
Le double avantage : les tokens en cache coûtent deux fois moins cher et ne comptent pas dans les limites de débit. Pour les charges de travail avec de longs prompts système - pipelines RAG, questions-réponses sur documents, agents de support client IA avec de larges contextes de connaissances - cela étend de manière significative votre débit effectif sans upgrader votre niveau de limite de débit.
Limites de débit : que se passe-t-il quand vous les atteignez
Lorsqu'une limite de débit est dépassée, Groq retourne HTTP 429 avec un header retry-after indiquant combien de secondes attendre. Le corps de l'erreur est précis :
« Limite de débit atteinte pour le modèle
openai/gpt-oss-20b… niveau de service : on_demand … Limite 200 000 · Utilisé 199 336 · Demandé 1 524 · Veuillez réessayer dans 6m 11,52s. » - Documentation de l'outil de gestion de projet Standard Time, avril 2026
Les headers de réponse incluent également x-ratelimit-limit-requests, x-ratelimit-remaining-tokens, et x-ratelimit-reset-requests - suffisamment pour implémenter un backoff exponentiel précis sans essais et erreurs.
La considération opérationnelle clé : les limites de débit sont par organisation, et par modèle. Si vous exécutez plusieurs services ou membres d'équipe depuis le même compte Groq, ils partagent le même pool de limites. Utilisez des comptes d'organisation séparés pour les environnements de production et de développement, ou contactez Groq au sujet de limites plus élevées pour des charges de travail spécifiques via console.groq.com/settings/limits.
Tarification entreprise
Il n'y a pas de grille tarifaire entreprise publique. Pour accéder aux éléments suivants, contactez groq.com/enterprise-access :
- Limites de débit plus élevées pour des charges de travail spécifiques
- Déploiement sur site GroqRack
- Modèles fine-tunés avec LoRA
- Modèles réservés aux entreprises (Minimax M2.5, Qwen3-VL 32B avec vision)
- Options de déploiement régional et de résidence des données
- Documentation de conformité SOC 2, RGPD et HIPAA
Concernant la disponibilité : l'examen de production d'Awesome Agents a mesuré 99,94 % de disponibilité sur 8 semaines avec une latence p99 dans les 15 % de la médiane - meilleure comportement de queue que les concurrents basés sur GPU car l'ordonnancement LPU est déterministe. Les garanties SLA entreprise nécessitent un accord formel.
La question de la pérennité
La plupart des guides de tarification Groq passent cela sous silence. Pas nous.
En septembre 2024, Kyle Corbitt a posté sur X qu'il avait entendu un employé de Groq affirmer que leurs coûts par token sont « 1 à 2 ordres de grandeur plus élevés que ce qu'ils facturent. » Le post a atteint 271 000 vues. Plus tôt en 2024, @swyx a fait le calcul et a constaté que la tarification ne fonctionne qu'avec une taille de lot d'environ 512 - inouï en inférence normale - et tombe à ~1,84 $ par million de tokens à un lot normal de 64.
Le contre-argument : Groq a levé 750 M$ auprès de BlackRock, Samsung, Cisco et Disruptive AI précisément parce que la thèse du volume et des nouvelles puces est crédible. Leurs études de cas clients montrent GPTZero à 7x plus rapide et 50 % de coûts en moins, ReBlink à 14x moins par partie, Recall à 10x moins de coûts. Les données de notoriété PeerSpot montrent un léger déclin en glissement annuel (13,7 % à 9,8 %) parmi les évaluateurs d'infrastructure IA entreprise, ce qui peut refléter l'incertitude autour des accords NVIDIA - à surveiller.
Notre avis : nous ne savons pas si la tarification actuelle est structurellement pérenne ou une stratégie délibérée d'acquisition avant les puces de deuxième génération. Ce que nous savons, c'est que la tarification a été stable tout au long de 2025–2026 et que les 750 M$ levés achètent du temps. Utilisez-le là où le rapport prix-performance a du sens ; ne vous enfermez pas dans une dépendance à un seul fournisseur que vous ne pouvez pas remplacer.
Qui devrait (et ne devrait pas) utiliser Groq
Utilisez Groq quand :
- Vous créez des interfaces vocales ou de chat en temps réel où 280–1 000 TPS compte pour l'expérience utilisateur
- Votre stack de modèles tourne sur Llama, Qwen, Whisper ou les modèles open-weight d'OpenAI
- Vous avez besoin de transcription bon marché à grande échelle - Whisper Turbo à 0,04 $/heure est difficile à battre
- Vous prototypez - le niveau gratuit couvre la plupart des charges de développement sans carte bancaire
- Vous avez des charges batch asynchrones - la remise de 50 % de l'API batch change significativement l'économie
Regardez ailleurs quand :
- Vous avez besoin de GPT-4o, Claude ou Gemini - non disponibles sur GroqCloud
- Vous avez besoin d'un support multimodal robuste - Llama 4 Scout est en aperçu uniquement
- Vous avez besoin d'un déploiement sur site avec des conditions de support standard - GroqRack nécessite des négociations entreprise
- Vous avez besoin de modèles propriétaires fine-tunés - le fine-tuning LoRA nécessite un accès entreprise
Pour une comparaison plus complète des fonctionnalités, notre avis sur Groq couvre le produit complet en profondeur. Si vous pesez encore les fournisseurs, les alternatives à Groq compare Together AI, Fireworks, Cerebras et d'autres sur les mêmes dimensions de rapport prix-performance.
Essayez eesel pour le support client propulsé par l'IA
Si vous évaluez Groq pour le support client ou l'automatisation du helpdesk, eesel s'y associe bien. eesel déploie des agents IA autonomes directement dans vos outils existants - Zendesk, Freshdesk, Slack, email - et oriente les tickets de support vers le bon modèle selon leur complexité. Les requêtes simples à fort volume vont vers un niveau de modèle rapide et bon marché (exactement ce pour quoi Llama 8B et GPT OSS 20B de Groq sont conçus) ; les escalades complexes vont vers un modèle à plus haute capacité.
Les équipes gérant plus de 100 000 tickets par mois utilisent des agents eesel qui résolvent réellement les problèmes plutôt que de simplement les détourner - pas de nouvelle interface à apprendre, pas d'ingénierie de prompt requise. Vous briefez l'agent comme vous intégreriez un nouvel employé, et il s'occupe du reste.

Questions fréquemment posées
Quel est le coût de l'API Groq par 1M de tokens ?
Groq propose-t-il un niveau gratuit ?
Quelles sont les limites de débit de Groq sur le niveau développeur payant ?
Les tarifs Groq offrent-ils un bon rapport qualité-prix pour les charges de travail en production ?

Article by
Rama Adi Nugraha
Rama is a software engineer at eesel AI with two years of experience writing about B2B SaaS, AI tools, and customer support technology. Based in Bali, Indonesia, he brings a developer's perspective to product comparisons — cutting through marketing copy to what the integrations and APIs actually do.








Comment les tarifs Groq se comparent-ils à OpenAI ?