
Ce qu'est Qwen (et pourquoi il est différent)
Qwen (通义千问) est la famille de modèles de langage d'Alibaba Cloud - un catalogue vaste de plus de 145 identifiants de modèles couvrant le texte, la vision, l'audio, le code, la traduction, la génération de vidéo et les embeddings, tous accessibles sous une seule clé API via Qwen Cloud / Alibaba Cloud Model Studio.
Trois éléments le rendent inhabituel sur le marché des LLM :
- Modèles à poids ouverts aux côtés de modèles propriétaires. Toute la série Qwen3 (de 0,6B à 235B-A22B) est sous licence Apache 2.0 et disponible sur Hugging Face. Vous pouvez exécuter localement et gratuitement le même modèle que celui que vous paieriez via l'API.
- L'architecture MoE domine le milieu de gamme. La majeure partie de la tarification compétitive de Qwen provient de sa conception Mixture-of-Experts - le modèle 235B-A22B n'active que 22B de paramètres par token, ce qui rend son coût d'inférence similaire à celui d'un modèle dense de 22B malgré une échelle totale de 235B.
- Un volume à une échelle que peu de fournisseurs égalent. Qwen3.6-Plus a été le premier modèle sur OpenRouter à traiter plus d'un billion de tokens en une seule journée, signe de l'adoption massive de la famille Qwen par les développeurs.
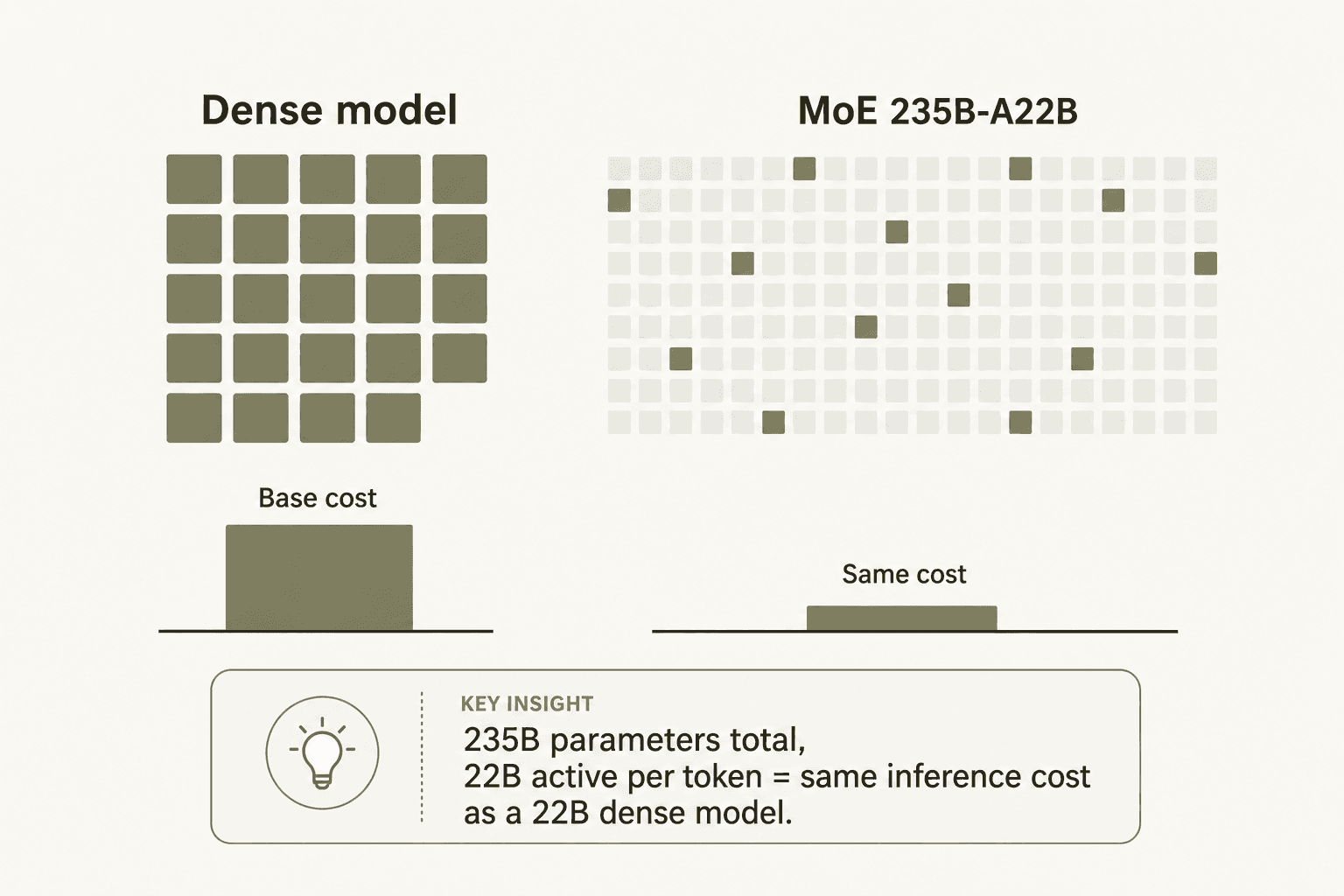
"Le design MoE : La plupart des modèles MoE semblent être des ajouts de dernière minute. L'activation clairsemée de Qwen 3.5 est native : seuls 4,3 % des paramètres s'activent par token. C'est ainsi que l'on obtient des performances de classe 'trillion de paramètres' sans les coûts d'inférence correspondants. Le prix de 0,8 RMB par million de tokens n'est pas subventionné ; il est structurellement mérité."
Tableau complet des tarifs de l'API Qwen (2026)
Tous les prix sont en USD, paiement à l'usage sur le point de terminaison international (Alibaba Cloud Model Studio, ap-southeast-1). Prix provenant des pages de détails des modèles Qwen Cloud et de PricePerToken.com (vérifiés le 3 juin 2026).
Modèles de génération de texte
| Modèle | Entrée $/1M | Sortie $/1M | Contexte | Notes |
|---|---|---|---|---|
| Qwen3.7-Max | 1,25 $ | 3,75 $ | 1M tokens | Promo -50 % sur 2,50 $/7,50 $ ; texte uniquement ; lancé le 21/05/2026 |
| Qwen3.7-Plus | 0,32 $–0,96 $ | 1,28 $–3,84 $ | 1M tokens | Multimodal natif ; par paliers de contexte ; lancé le 01/06/2026 |
| Qwen3-Max | 1,20 $ | 6,00 $ | 262K tokens | Optimisé pour les agents ; lecture cache 0,12 $/1M |
| Qwen3.6-Plus | 0,50 $–2,00 $ | 3,00 $–6,00 $ | 1M tokens | Multimodal natif ; codage agentique ; visuel + texte |
| Qwen3.6-Flash | 0,25 $–1,00 $ | 1,50 $–4,00 $ | 1M tokens | Vision-langage optimisé pour les coûts |
| Qwen3-235B-A22B | 0,70 $ | 2,80 $ / 8,40 $* | 131K tokens | Flagship MoE à poids ouverts ; *mode réflexion |
| Qwen3-30B-A3B | 0,20 $ | 0,80 $ / 2,40 $* | 131K tokens | MoE équilibré ; *mode réflexion |
| Qwen3-8B | 0,18 $ | 0,70 $ / 2,10 $* | 131K tokens | Dense petit ; *mode réflexion |
| Qwen-Max | 1,60 $ | 6,40 $ | 32K tokens | Alias de production stable |
| Qwen-Plus | 0,40 $ | 1,20 $ / 4,00 $* | 1M tokens | Alias stable ; *mode réflexion |
| Qwen-Turbo | 0,05 $ | 0,20 $ / 0,50 $* | 131K tokens | Niveau texte le moins cher ; débit 5M TPM ; *mode réflexion |
| Qwen3.5-0.8B | 0,01 $ | 0,05 $ | - | Plancher absolu ; micro-tâches d'automatisation |
*Sortie en mode réflexion facturée au tarif supérieur lorsque enable_thinking: true
Modèles vision-langage et multimodaux
| Modèle | Entrée $/1M | Sortie $/1M | Contexte |
|---|---|---|---|
| Qwen3-VL-Plus | 0,20 $ | 1,60 $ | 262K tokens |
Modèles d'embedding
| Modèle | Prix |
|---|---|
| text-embedding-v3 / text-embedding-v4 | 0,07 $/1M tokens ; 0,035 $/1M par lots |
Modèles de génération de vidéo
| Modèle | Prix |
|---|---|
| HappyHorse-1.0 series (T2V, I2V, R2V, edit) | 0,112 $/seconde |
| Wan2.7-T2V | 0,10 $/seconde |
Les fourchettes de prix sur Qwen3.7-Plus et la série Qwen3.6 reflètent des paliers d'entrée : le coût par million de tokens augmente à mesure que la longueur de l'entrée croît au sein d'une seule requête (usage non cumulatif). Le tarif de 0,32 $ s'applique aux entrées courtes ; celui de 0,96 $ s'active pour les requêtes à long contexte sur Qwen3.7-Plus.
Comment fonctionne réellement la facturation
Comprendre la grille tarifaire est la première étape. Comprendre comment ces tarifs se combinent dans une charge de travail réelle est l'étape où les gens sont surpris.
Mode réflexion (Thinking mode)
Plusieurs modèles de génération Qwen3 prennent en charge un paramètre optionnel enable_thinking: true qui déclenche un raisonnement par chaîne de pensée avant la réponse finale. Les tokens de réflexion sont générés en interne puis facturés à des tarifs généralement 3 à 10 fois supérieurs à la sortie standard. Sur Qwen-Plus, par exemple, la sortie standard coûte 1,20 $/1M mais la sortie de réflexion coûte 4,00 $/1M. Sur Qwen3-235B-A22B, la sortie de réflexion passe de 2,80 $ à 8,40 $/1M.
Pour la plupart des charges de travail en production (classification, résumé, extraction structurée), le mode réflexion est excessif. Activez-le uniquement pour les tâches nécessitant un raisonnement complexe (revue de code complexe, planification multi-étapes, mathématiques) et prévoyez votre budget en conséquence.
Mise en cache des invites (Prompt caching)
Le caching d'invite implicite est automatique sur la plupart des modèles Qwen : les préfixes de contexte répétés sont mis en cache, et les succès de cache sont facturés à environ 20 % du tarif d'entrée standard. Pour Qwen-Plus, cela représente 0,08 $/1M au lieu de 0,40 $/1M sur les parties en cache.
Une gestion explicite du cache est également disponible sur Qwen3-Max et Qwen-Plus :
- Création du cache : ~0,50 $/1M (125 % du tarif d'entrée)
- Lecture du cache : ~0,04 $/1M (10 % du tarif d'entrée)
Le bémol soulevé régulièrement par la communauté : le caching de Qwen semble moins fiable que celui de ses concurrents. Un utilisateur de Reddit a testé la même tâche de revue de code sur quatre CLI d'IA et a constaté que Qwen avait consommé 23 % de son quota mensuel de 30 $ sur une seule tâche, alors que la même tâche consommait moins de 1 % des forfaits équivalents de 100 $ chez Claude et OpenAI. Le diagnostic explicite : "Ils ne semblent pas mettre en cache aussi bien que les autres fournisseurs de modèles."
Traitement par lots (Batch processing)
L'API batch asynchrone offre environ 50 % de réduction sur les tarifs standard pour les charges de travail non temps réel. Sur Qwen3-Max, l'entrée par lots passe de 1,20 $ à 0,60 $/1M ; la sortie par lots de 6,00 $ à 3,00 $/1M. Pour les pipelines ETL, les tâches de classification massive ou la génération de rapports nocturnes, le mode batch est le choix par défaut.
Plans d'économie (Savings plans)
Alibaba Cloud propose des AI Savings Plans avec jusqu'à 47 % de réduction des coûts via un engagement d'utilisation. Il existe également un AI Token Plan (crédits d'abonnement fixes pour tous les modèles), mais l'expérience de la communauté à ce sujet est mitigée (voir Ce que vous payez réellement, ci-dessous).
Ce que vous payez réellement en pratique
Les prix affichés et les factures réelles divergent. Voici trois exemples basés sur des données du monde réel.
Exemple 1 : un pipeline de contenu à 10 000 tâches/jour
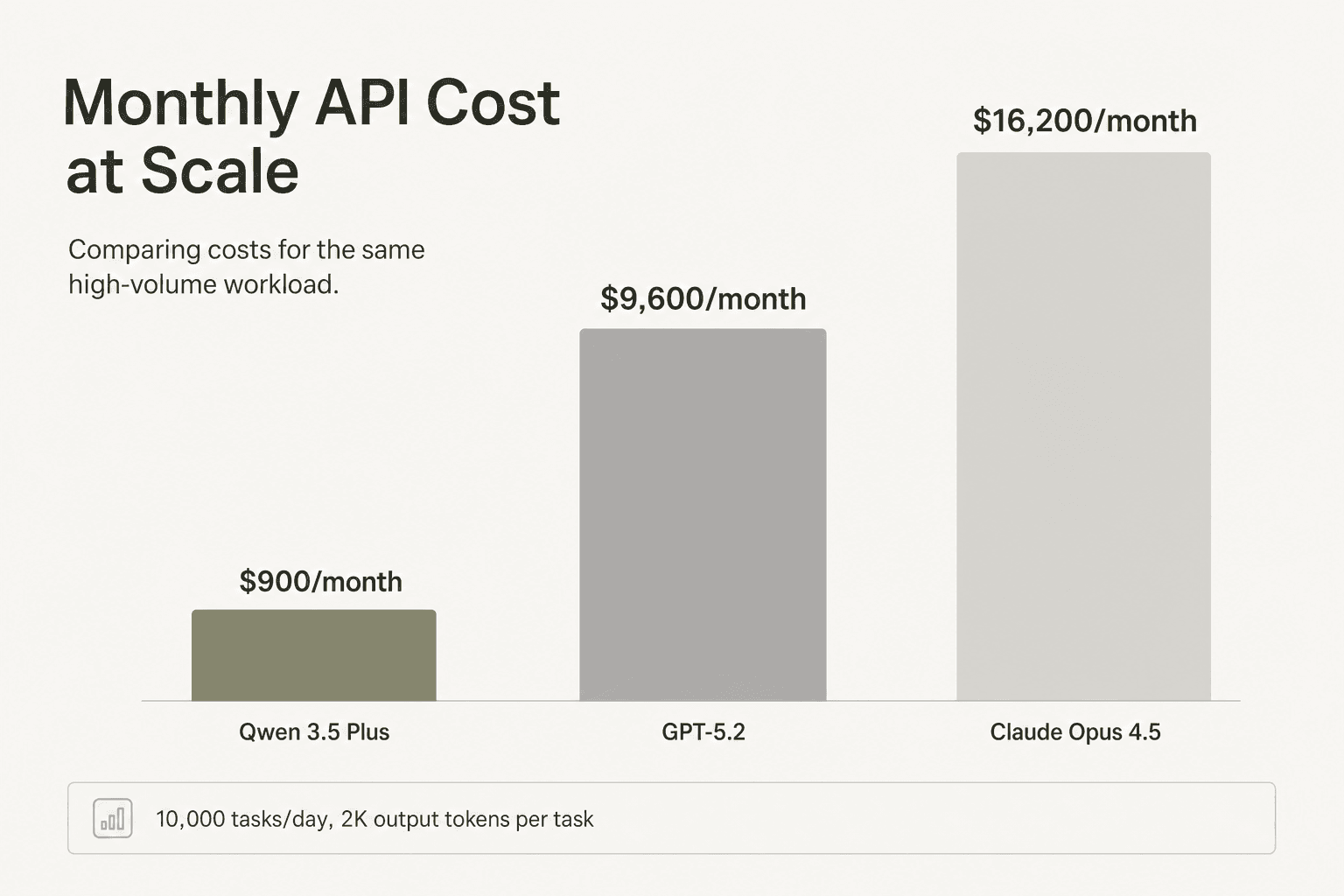
ChartGen AI a comparé Qwen 3.5, GPT-5.2 et Claude Opus 4.5 sur 20 tâches de visualisation de données, chacune nécessitant environ 2K tokens de sortie. L'économie pour 10K tâches/jour :
| Modèle | Coût par tâche | Coût quotidien | Coût mensuel |
|---|---|---|---|
| Qwen 3.5-35B-A3B | ~0,003 $ | ~30 $ | ~900 $ |
| GPT-5.2 | ~0,032 $ | ~320 $ | ~9 600 $ |
| Claude Opus 4.5 | ~0,054 $ | ~540 $ | ~16 200 $ |
Qwen a obtenu un score de 163/200 lors du test contre 178/200 pour GPT-5.2, soit un écart de qualité de 9 % pour une réduction de coût de 10x.
L'équipe de ChartGen a également souligné le multiplicateur multi-agent :
"Dans le pipeline de ChartGen AI, une seule génération de tableau de bord invoque le modèle 5 à 8 fois... À cette échelle, vous pouvez faire fonctionner 10 agents Qwen 3.5 pour le prix d'un seul appel GPT-5.2, et utiliser un vote d'ensemble pour dépasser la précision de n'importe quel modèle unique."
Steven Cen, ChartGen AI [Source]
Exemple 2 : le test d'infrastructure de l'Intelligence Index
Artificial Analysis a fait passer l'intégralité de son test Intelligence Index à Qwen3.6 Plus. Coût total :
- Qwen3.6 Plus : 483 $ (~100M de tokens de sortie à 0,50 $/3,00 $)
- Claude Opus 4.6 (effort max) : 4 970 $
Cela représente une différence de coût de 10x pour un écart de score d'intelligence de 2 points (Qwen3.6 Plus a obtenu 51 contre 53 pour Claude Opus 4.6 sur leur index). Le bémol : Qwen a généré nettement plus de tokens de sortie par tâche que ses pairs, ce qui a gonflé les coûts par rapport à un modèle moins verbeux au même tarif par token.
Exemple 3 : le choc du Token Plan
La nouvelle offre d'abonnement de Qwen, l'AI Token Plan, convertit les dollars en crédits de manière à désorienter de nombreux utilisateurs précoces. Extrait d'un fil Reddit de mai 2026 :
"Je me suis inscrit au forfait de 30 $ (qui offre 25 000 crédits)... en seulement 4 heures d'utilisation [avec Qwen 3.6 Plus], [j'ai consommé] environ 8 000 crédits (sur un total de 25 000 crédits dans le forfait de 30 $)."
La comparaison directe par l'utilisateur qu1etus est accablante pour le Token Plan spécifiquement :
"qwen3.7-max (via qwen cli - forfait 30 $) : a utilisé 23 % de mon quota mensuel. gpt-5.5 xhigh (via codex cli - forfait 100 $) : a utilisé <1 % du quota mensuel. opus 4.7 (via claude code - forfait 100 $) : a utilisé <1 % du quota mensuel. Vu le coût, j'arrête. Ils ne semblent pas mettre en cache aussi bien que les autres fournisseurs de modèles et leur modèle de tarification est défaillant."
Le tarif brut de l'API en paiement à l'usage est plus avantageux que ce que suggère le calcul du Token Plan. Si vous comparez Qwen à Claude ou OpenAI, tenez-vous-en à la tarification de l'API par token plutôt qu'aux niveaux d'abonnement.
Niveaux de prix Qwen : choisir le bon modèle
Toutes les charges de travail n'ont pas besoin du niveau Max. La décision d'architecture compte souvent plus que la génération du modèle.

Qwen-Turbo (0,05 $/0,20 $) : le bon choix pour la classification, le routage, l'extraction et toute charge de travail nécessitant un débit élevé à bas coût. Avec une limite de débit de 5M de tokens par minute, il gère les pipelines batch agressifs sans atteindre les plafonds. Un utilisateur de Reddit l'a formulé ainsi : "À sept centimes par million de tokens, on a l'impression de tricher."
Qwen3-30B-A3B (0,20 $/0,80 $) : le choix MoE équilibré. Le 30B-A3B n'active que 3B de paramètres lors de l'inférence, fonctionne à ~137 tokens/seconde sur un seul GPU H20, et couvre la vaste majorité des tâches de codage et de raisonnement qui n'ont pas besoin des capacités du niveau Max. Consensus de la communauté sur r/LocalLLaMA : la variante MoE 35B-A3B fonctionne 15 fois plus vite que le modèle dense 27B pour une fraction du coût ; choisissez toujours le MoE s'il y en a un à votre taille cible.
Qwen-Plus (0,40 $/1,20 $) : l'alias stable pour la production avec un contexte de 1M. Si vous avez besoin d'un identifiant API prévisible qui ne changera pas entre les mises à jour de modèles, c'est celui-ci. Mode réflexion disponible à 4,00 $/1M de sortie.
Qwen3.7-Plus (0,32 $–0,96 $/1,28 $–3,84 $) : l'option multimodale native avec un contexte de 1M et des capacités de codage agentique. Convient bien aux pipelines mélangeant texte, image et appels d'outils dans le même appel.
Qwen3-Max / Qwen3.7-Max (1,20 $–1,25 $ / 6,00 $–3,75 $) : on approche des tarifs des modèles de pointe. La communauté a constaté que la variante 480B MoE Coder est souvent plus pertinente que le Max pour le codage intensif à 1,50 $/7,50 $, sauf si vous avez spécifiquement besoin de l'optimisation des pipelines d'agents de l'architecture Max. À 1,25 $ (tarif réduit) pour Qwen3.7-Max, il est compétitif avec les tarifs de milieu de gamme de GPT-5, mais la remise est indiquée comme promotionnelle.
La situation de l'offre gratuite en 2026
C'est la partie qui induit le plus les gens en erreur.
Ce qui est gratuit : L'application de chat grand public Qwen Studio - aucune inscription requise, aucune limite de débit communiquée, disponible sur iOS, Android, macOS et le Web. Cela ne va pas disparaître. Alibaba a de forts intérêts commerciaux à maintenir le produit grand public gratuit.
Ce qui était gratuit et ne l'est plus : L'offre gratuite de l'API OAuth pour les développeurs, qui permettait 1 000 (puis 100) requêtes/jour via l'API, a été interrompue le 15 avril 2026. Le niveau gratuit de 2 000 requêtes/jour de la CLI Qwen Code a également été supprimé à peu près au même moment. La réaction de la communauté a été immédiate :
"Sérieux, je viens de m'abonner à Claude. J'ai demandé à Qwen de faire des fichiers .md de tout pour que Claude puisse reprendre de là."
u/ihateroomba, 3 upvotes
Un commentaire Reddit très pertinent a bien expliqué la distinction :
"Il est important de distinguer deux mondes distincts qui coexistent chez Alibaba : Le monde du 'Produit Grand Public' (Qwen Studio) : L'application que vous utilisez sur votre téléphone est un produit fini. Alibaba a tout intérêt à ce qu'elle reste gratuite... Le monde 'Développeur / API' : C'est là que la politique a changé... C'est une stratégie classique : attirer les utilisateurs avec la version gratuite, puis les faire payer quand ils passent à l'échelle."
Ce qui est encore disponible en essai gratuit : Les nouveaux comptes Alibaba Cloud Model Studio reçoivent plus de 70 millions de tokens gratuits sur les modèles Qwen (1 million de tokens par modèle), ainsi que 1 650 secondes de crédit de génération de vidéo. Valable 90 jours, point de terminaison de Singapour uniquement. Le point de terminaison US Virginia ne dispose d'aucun quota gratuit.
Le prix plancher de l'auto-hébergement
Il existe un chiffre que les tableaux de prix des API ne montrent pas : 0,00 $ par token, accessible à quiconque est prêt à exécuter sa propre inférence.
Tous les modèles Qwen3 (de 0,6B à 235B-A22B) sont à poids ouverts sous licence Apache 2.0 et disponibles sur Hugging Face. @WolframRvnwlf a testé la version quantifiée Unsloth du Qwen3-30B-A3B sur un MacBook Pro M4 :
"Le quantifié 30B-A3B Unsloth a affiché 82,20 % en tournant localement à ~45 tok/s et avec une dépense d'API nulle... Les modèles 30B quantifiés vous offrent désormais ~98 % de la précision de la classe frontier, à une fraction de la latence, du coût et de l'énergie."
vLLM et SGLang sont les frameworks d'auto-hébergement recommandés ; la documentation de Qwen3 inclut les commandes de déploiement complètes. Pour les équipes traitant des données sensibles ou opérant dans des juridictions où la conformité des clouds d'origine chinoise pose question, l'auto-hébergement résout également entièrement la question de la résidence des données.
Le revers de la médaille : le coût du matériel est réel. Un nœud GPU H20 unique coûte environ 3 à 5 $/heure chez les fournisseurs de cloud. Pour des charges de travail modérées (moins de quelques millions de tokens/jour), l'API est probablement moins chère que du calcul dédié. Mais à grande échelle, ou avec un GPU que vous possédez déjà, l'auto-hébergement l'emporte souvent.
Qwen vs Claude vs GPT : la comparaison honnête
L'argument "Qwen est 9 fois moins cher que Claude" est vrai, mais incomplet.
"La comparaison des prix des API raconte clairement l'histoire. Claude Opus 4.6 coûte 5 $ en entrée et 25 $ en sortie par million de tokens. GPT-5.3 Codex coûte 1,75 $ et 14 $. Qwen 3.5 Plus coûte 0,40 $ et 2,40 $. Ce n'est pas une différence marginale. C'est un changement structurel dans la capacité financière à construire avec une IA de pointe."
La nuance apportée par Artificial Analysis : les modèles Qwen génèrent plus de tokens de sortie par tâche que leurs pairs. Qwen3.5-27B a utilisé 98 millions de tokens de sortie pour terminer son test Intelligence Index, un chiffre nettement plus élevé que MiniMax-M2.5 (56M) ou DeepSeek V3.2 (61M). Si votre charge de travail génère des sorties longues, la verbosité des tokens compense partiellement la remise sur le prix par token.
L'analyse sur LinkedIn de Rishabh Choudhary concernant Qwen3.6-Plus pose la question centrale :
"Il a obtenu 78,8 sur SWE-bench Verified... Claude Opus 4.5 a obtenu 80,9. C'est un écart de 2 points. L'écart de prix ? Pas 2 points. Plutôt 17x... La question n'est pas de savoir si les modèles chinois rattrapent leur retard. Ils le font clairement. La question est de savoir si les écarts de qualité restants sont assez importants pour justifier de payer 17 fois plus. Pour beaucoup de cas d'utilisation, je pense que la réponse honnête devient non."
Les bémols des praticiens ayant utilisé Qwen en production méritent également d'être pris au sérieux. Dans les commentaires de ce même post LinkedIn : une latence de 11 secondes pour le premier token sur le niveau d'aperçu gratuit (un problème pour les boucles d'agents multi-étapes où le temps d'attente s'accumule), et un taux d'hallucination de raisonnement de code rapporté de 26 % lors de tests en production qui "nécessite une couche de vérification qui annule une partie des économies réalisées sur les tokens".
Pour une comparaison directe avec les alternatives les plus populaires, consultez les tarifs de Claude, les tarifs de Gemini et les tarifs de Mistral AI.
Contexte des benchmarks
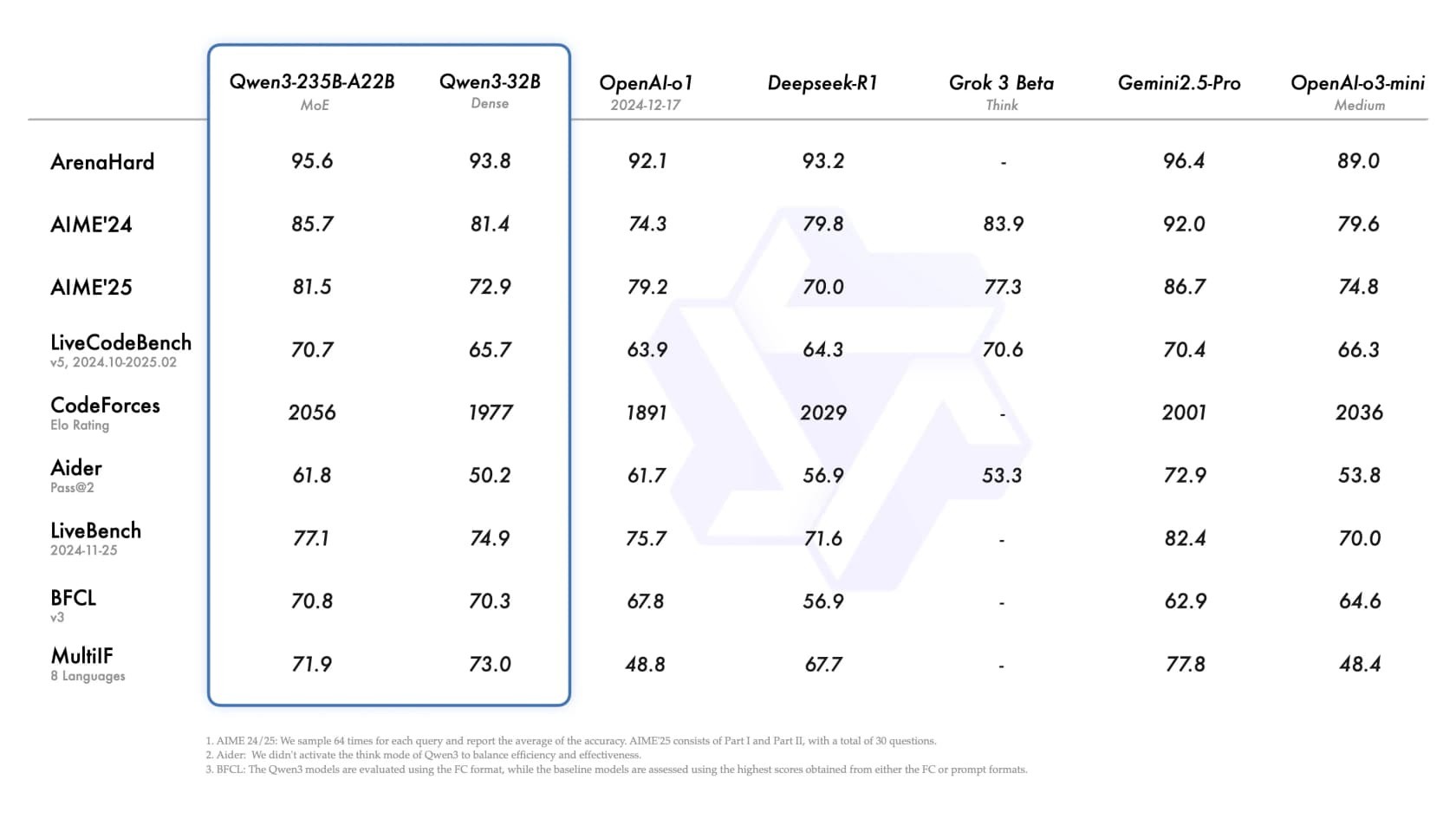
Le fleuron Qwen3-235B-A22B MoE rivalise directement avec OpenAI o1, DeepSeek-R1 et Gemini 2.5 Pro sur les benchmarks publics : ArenaHard 95.6, AIME'24 85.7, LiveCodeBench 70.7, BFCL 70.8. À 0,70 $/2,80 $ pour 1M de tokens (standard), il est moins cher que la plupart de ces modèles tout en égalant leurs scores. La disponibilité en poids ouverts signifie que vous pouvez également le télécharger et l'exécuter vous-même sans aucune dépendance à une API.
Le signal des téléchargements open-source est révélateur : Qwen occupe 7 des 10 premières places dans le classement des téléchargements de modèles ouverts sur Hugging Face, selon Nathan Lambert (chercheur en ML), avec Qwen2.5-7B-Instruct à 52,4 millions de téléchargements et plusieurs variantes de Qwen3 dans le top 5. Ce niveau d'adoption crée des outils communautaires, des versions quantifiées et des intégrations d'écosystème qui rendent l'auto-hébergement de plus en plus accessible.
Accès à l'API : comment commencer
L'API internationale fonctionne sur Alibaba Cloud Model Studio. Elle est compatible avec OpenAI, ce qui signifie que passer du SDK d'OpenAI à Qwen se résume généralement à un changement de deux lignes : l'URL de base et la clé API.
from openai import OpenAI
client = OpenAI(
base_url="https://[workspace-id].ap-southeast-1.maas.aliyuncs.com/compatible-mode/v1",
api_key="votre-clé-api-dashscope"
)
Régions disponibles : Asie du Sud-Est (principale), Francfort (depuis le 20/03/2026) et Hong Kong (depuis le 17/03/2026). Le point de terminaison US Virginia est disponible mais ne comporte aucun quota d'essai gratuit.
Les limites de débit sont de 600 RPM / 1M TPM pour la plupart des modèles ; Qwen-Turbo monte plus haut à 5M TPM, ce qui en fait le bon choix pour les pipelines à gros volume et par rafales. Les comptes entreprise peuvent demander des augmentations de quota via un ticket de support.
Qui adopte réellement Qwen, et qui attend
L'adoption par les développeurs est forte : la dominance des téléchargements sur Hugging Face et le volume de tokens sur OpenRouter le prouvent. NVIDIA a officiellement soutenu Qwen 3.5 le jour de son lancement, orientant les développeurs vers la voie NeMo.
L'adoption par les entreprises est une autre histoire. Comme l'a noté un intervenant sur LinkedIn :
"Pour nos clients Fortune 500 / grandes entreprises, les modèles les plus utilisés sont : 1. Gemma 2. Mistral 3. GPT-OSS 4. Llama... Certains de nos clients entreprises avant-gardistes commencent à utiliser Qwen, mais ce n'est pas encore la majorité."
Andrew Jardine, IA d'entreprise [Source]
Les freins identifiés : les examens de conformité liés à l'origine chinoise dans les secteurs réglementés (services financiers, santé, gouvernement) et la latence sur les points de terminaison d'aperçu gratuit. La série Qwen3 détient la certification ISO 27001 sur l'API payante, mais de nombreux examens de sécurité en entreprise exigent des garanties supplémentaires sur la résidence des données et la journalisation des accès aux modèles avant que l'achat ne soit validé. L'auto-hébergement permet de contourner la plupart de ces problèmes.
Pour les équipes non soumises à ces contraintes de conformité, en particulier les startups, les créateurs de SaaS de milieu de gamme et les opérateurs de pipelines d'agents sensibles aux coûts, les arguments économiques sont difficiles à réfuter.
Essayez eesel
Si vous exécutez des flux de travail alimentés par l'IA à grande échelle et que les coûts des tokens comptent pour vous, eesel mérite votre attention. Il déploie des agents d'IA autonomes directement dans les outils que votre équipe utilise déjà (Zendesk, Slack, Freshdesk, email, Shopify) sans nécessiter de nouvelle interface ni d'abonnement par siège. Vous payez par tâche (0,40 $ par ticket résolu, 4,00 $ par article de blog rédigé), et les agents s'arrêtent automatiquement lorsque vous atteignez votre plafond de dépense. Ce modèle de tarification élimine totalement la gestion fastidieuse du comptage des tokens. Commencez avec 50 $ de crédit gratuit, aucune carte requise.

Questions fréquemment posées
Combien coûte Qwen par million de tokens ?
Qwen est-il toujours gratuit en 2026 ?
Qu'est-ce que le mode réflexion de Qwen et comment est-il facturé ?
enable_thinking: true qui active le raisonnement par chaîne de pensée. Les tokens de sortie de réflexion sont facturés à un tarif plus élevé que la sortie standard, généralement de 3 à 10 fois plus cher. Par exemple, Qwen-Plus facture 1,20 $/1M pour la sortie standard mais 4,00 $/1M pour la sortie de réflexion. Les tokens d'entrée standard sont facturés au même tarif, que la réflexion soit activée ou non.







Comment les tarifs de Qwen se comparent-ils à ceux de ChatGPT et Claude ?