
En résumé
AA-Briefcase est un nouveau benchmark d'Artificial Analysis qui évalue les modèles d'IA sur un vrai travail de connaissance s'étalant sur plusieurs semaines (modèles financiers, présentations au conseil, spécifications produit) plutôt que sur des questions ponctuelles. Chaque modèle reçoit des milliers de fichiers désordonnés (e-mails, fils Slack, feuilles de calcul) et doit produire de véritables livrables, qui sont notés sur la correction, la qualité analytique et la présentation.
Le constat principal est édifiant : même le meilleur modèle satisfait à tous les critères du barème sur seulement 3 % des tâches, et sur 31 des 91 tâches aucun modèle ne dépasse 50 %. Claude Fable 5 est en tête du classement, avec le GLM-5.2 open-weight bien au-delà de son prix.
Voici ce que la plupart des analyses omettent : un score élevé au benchmark indique qu'un modèle est capable en général, pas qu'il est sûr sur vos données. Cet écart est exactement la raison pour laquelle je pense que quiconque cherche un service client IA devrait tester sur ses propres données historiques avant de passer en production, plutôt que de faire confiance à un classement.
Je développe des agents IA à titre professionnel chez eesel, donc un benchmark qui mesure enfin le vrai travail désordonné plutôt que des questions triviales est le genre de chose qui m'arrête tout. Voici ce qu'AA-Briefcase mesure réellement, comment il note, qui gagne, et la seule leçon que j'en tirerais pour tout déploiement d'agent IA.
Ce qu'AA-Briefcase mesure réellement
La plupart des benchmarks IA posent des questions courtes et indépendantes : un problème de mathématiques, un puzzle de codage, un quiz à choix multiple. C'est utile pour mesurer le raisonnement brut, mais cela ne ressemble pas à la façon dont les gens utilisent réellement ces modèles au travail. Le vrai travail de connaissance est long, ambigu et noyé dans le désordre.
AA-Briefcase a été conçu pour combler cet écart. Au lieu d'un prompt, chaque modèle est plongé dans un projet d'entreprise de plusieurs semaines avec de nombreuses tâches liées et des milliers de fichiers sources, et on lui demande de produire le type de livrables qu'un vrai analyste ou PM ferait : modèles financiers, présentations au conseil, maquettes de conception, mémos de stratégie. Les scénarios ont été développés pendant des mois par des experts du secteur d'entreprises comme Google, McKinsey et Boston Consulting Group, de sorte que le travail ressemble à ce que ces entreprises font réellement.
Les chiffres donnent une idée de l'ampleur. Il y a quatre scénarios de projets réservés et 91 tâches au total, tirées de la science des données, de la gestion de produit et de la stratégie d'entreprise. À travers eux se trouvent près de 2 000 fichiers sources, dont plus de 3 500 e-mails et 25 000 messages Slack, délibérément fragmentés et remplis de contradictions réalistes. Les quatre scénarios de notation sont un projet de Science des données, un projet de Gestion de produit, une transformation des Opérations bancaires et une construction de Stratégie d'industrie lourde ; un cinquième scénario de Due Diligence est public et ne compte pas dans les scores.
Ce cadrage compte parce qu'il reflète le mode d'échec de chaque agent IA que j'ai jamais déployé : le modèle lutte rarement avec l'idée, il lutte pour trouver l'exigence cachée dans le fichier 1 400 sans contredire l'e-mail qui l'avait silencieusement remplacée.
Comment AA-Briefcase évalue un modèle
C'est là qu'AA-Briefcase devient malin. Un seul score cacherait la chose la plus intéressante dans la production IA, à savoir que paraître professionnel et être correct sont deux compétences totalement différentes. Chaque tâche est donc notée selon trois dimensions séparées.
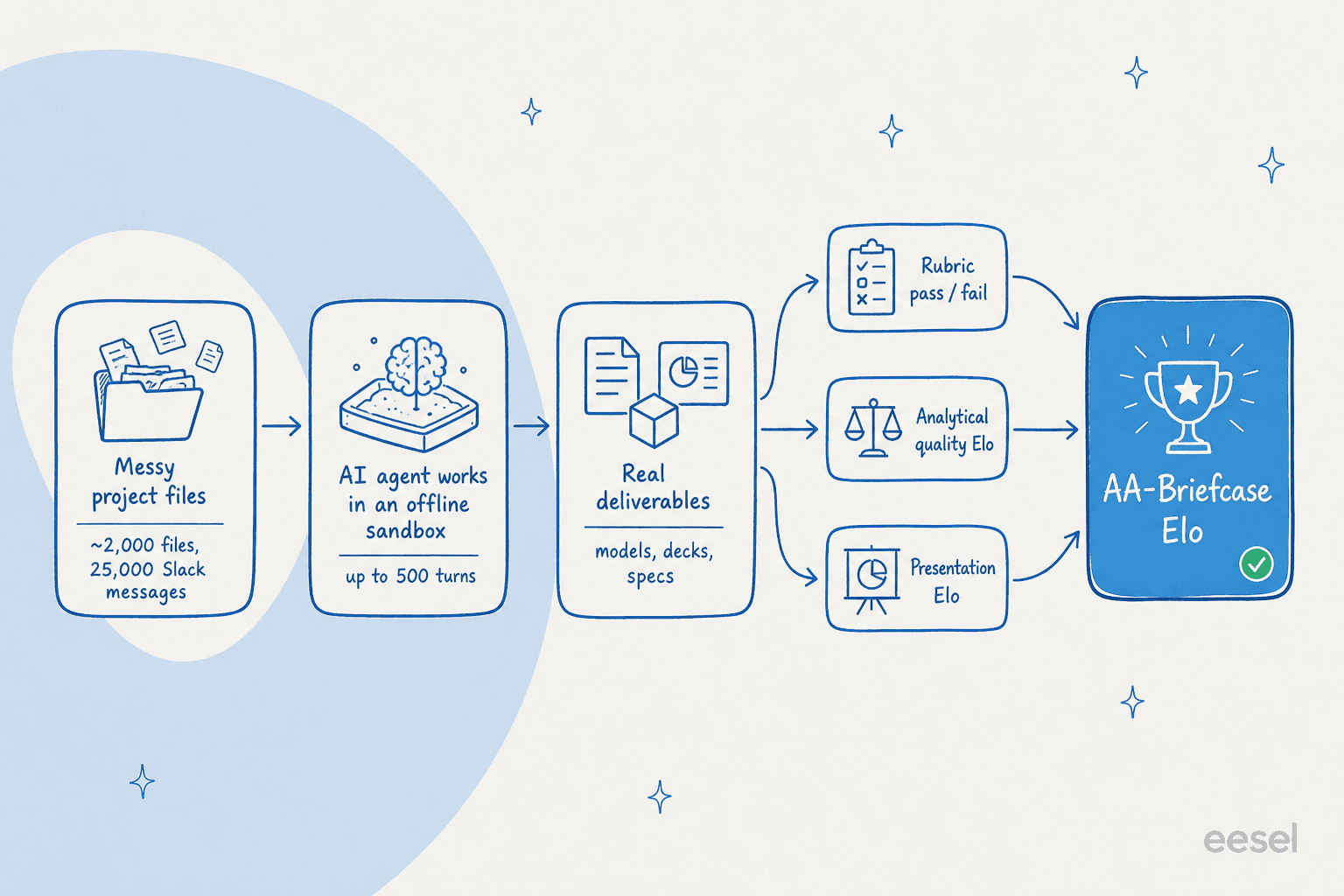
La première est un barème binaire : réussi ou échoué pour chaque vérification, sans crédit partiel. Le modèle a-t-il suivi les instructions, trouvé les exigences dispersées dans les fichiers, utilisé les bonnes preuves et atteint la bonne conclusion ? La deuxième est la qualité analytique, jugée par comparaison par paires avec la soumission d'un autre modèle : quel livrable est plus complet et mieux étayé ? La troisième est la présentation, également par paires : quel résultat est présenté de façon plus professionnelle ?
Ces trois éléments se combinent en un seul chiffre principal, l'Elo AA-Briefcase, qui mélange l'Elo de qualité analytique, l'Elo de présentation et le taux de réussite au barème par agrégation Elo à maximum de vraisemblance. Pour éviter qu'une famille de modèles se note favorablement, chaque comparaison est décidée par un jury de trois juges : Claude Opus 4.8, GPT-5.5 et Gemini 3.1 Pro Preview.
L'infrastructure est aussi ouverte. Les modèles tournent sur Stirrup, le harness d'agent open-source d'Artificial Analysis, dans un sandbox hors ligne sans internet, pour jusqu'à 500 tours par tâche. C'est une configuration véritablement exigeante, et c'est beaucoup plus proche d'un vrai workflow agentique qu'une fenêtre de chat.
Ce que les résultats disent vraiment
Le classement en haut raconte la belle histoire (Claude Fable 5 en tête, niveaux de capacité proprement empilés). L'histoire plus difficile se trouve dans les taux de réussite.
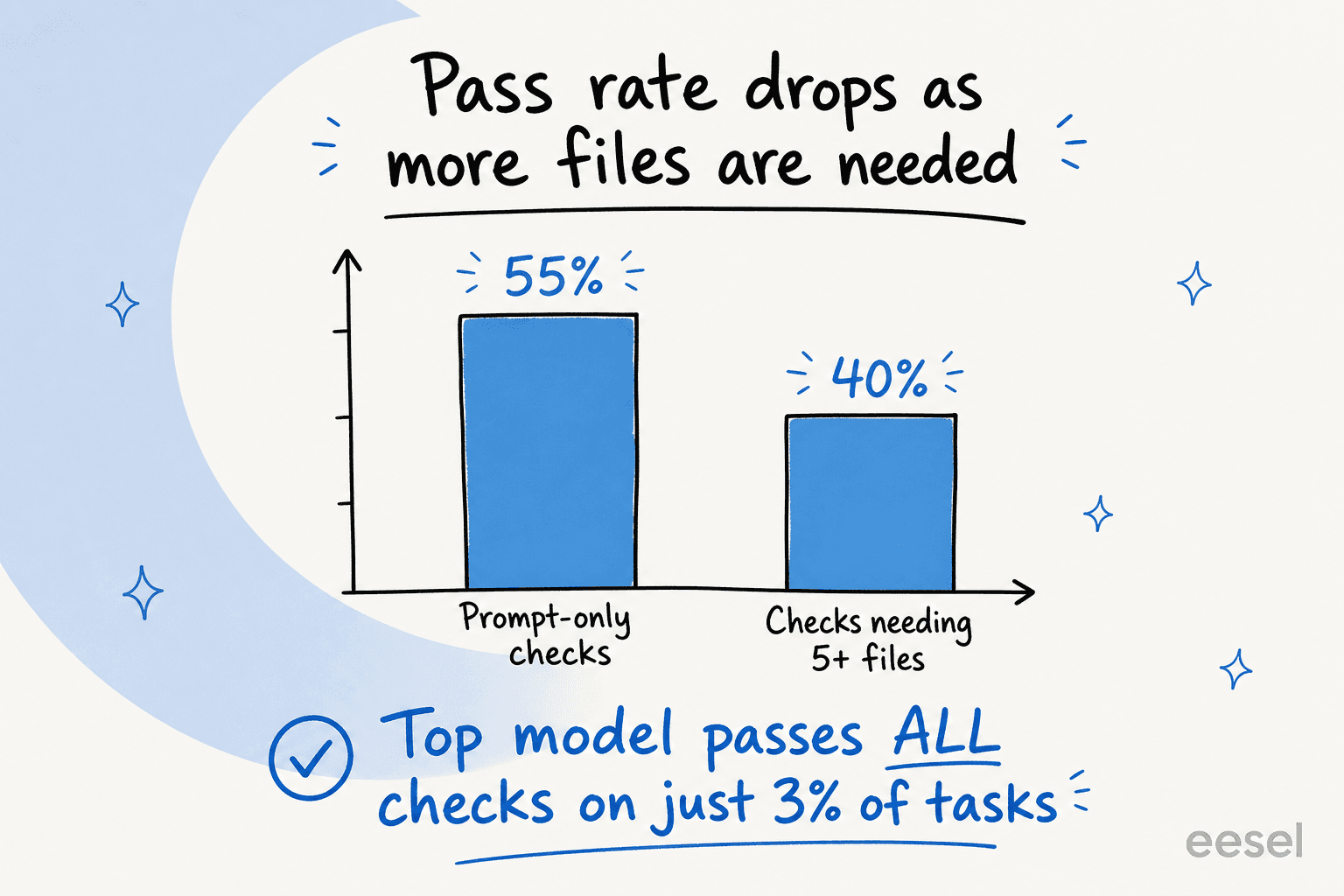
Même le modèle leader satisfait tous les critères du barème sur seulement 3 % des tâches, et sur 31 des 91 tâches aucun modèle ne dépasse 50 %. La difficulté augmente également avec le nombre de fichiers requis : les modèles à haute intelligence tombent d'environ 55 % sur les vérifications prompt-only à environ 40 % dès qu'une tâche en nécessite cinq ou plus. Plus une tâche ressemble à du vrai travail, moins tout le monde s'en sort.
Le classement comporte quelques points à retenir. GLM-5.2 est le clair leader open-weight et la référence prix/performance, se situant environ 90 Elo sous Claude Opus 4.8 pour moins d'un quart du coût. MiniMax-M3 et GLM-5.2 surpassent tous deux leurs scores d'intelligence générale, tandis que les modèles Gemini de Google sous-performent sur AA-Briefcase par rapport à leur position dans les classements d'intelligence générale. Et comme le montre la vue coût dans le widget, l'écart entre le modèle le plus cher et le moins cher dépasse 800×, ce qui est un rappel utile quand on pèse le vrai coût d'un agent IA contre les métriques qui comptent vraiment.
Le problème de « semble juste mais est faux »
Ma découverte préférée de toute la publication est comportementale, et elle explique beaucoup de choses sur la raison pour laquelle le travail IA peut sembler peu fiable.
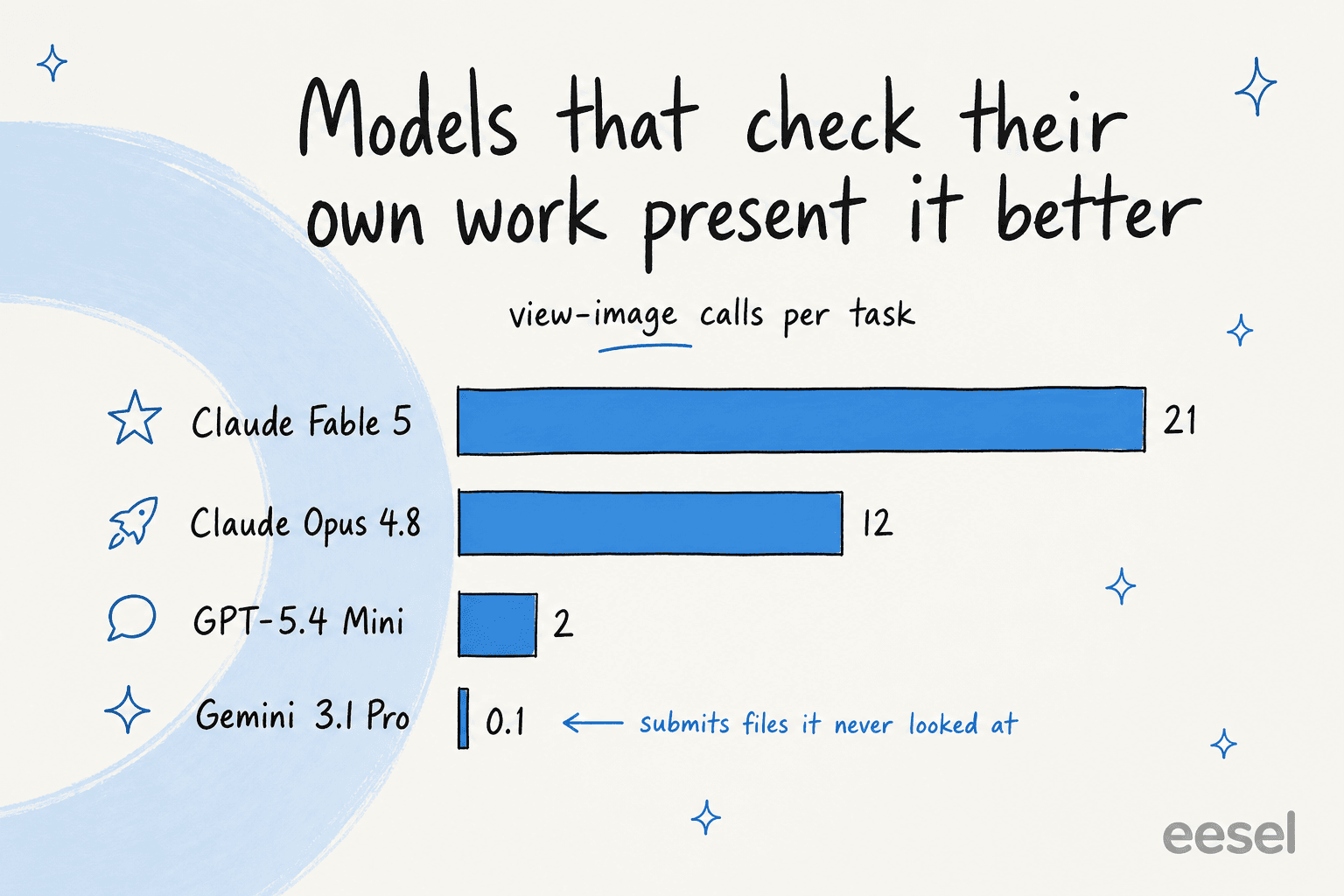
Les modèles qui obtiennent les meilleurs scores en présentation sont ceux qui regardent réellement leur propre résultat rendu. Claude Fable 5 a effectué environ 21 appels view-image par tâche et Opus 4.8 environ 12, tandis que certains modèles soumettaient des fichiers qu'ils avaient à peine examinés (Gemini 3.1 Pro Preview avec une moyenne d'environ 0,1 appel view-image). Il s'avère que « vérifie ton travail avant de le remettre » est un aussi bon conseil pour une IA que pour une personne.
Il y a un point plus profond en dessous. AA-Briefcase sépare le polissage de la correction précisément parce qu'une réponse confiante, bien formatée et discrètement fausse est plus dangereuse qu'une réponse évidemment incomplète. C'est le risque exact qui apparaît quand un chatbot IA répond à un client, et c'est pourquoi prévenir les hallucinations est l'essentiel en support, pas un bonus agréable.
Pourquoi un score dans le classement n'est pas un plan de déploiement
Donc un modèle frontière peut faire un vrai travail de connaissance, parfois brillamment, et rater quand même la plupart du temps sur les tâches les plus difficiles et les plus chargées en fichiers. Si vous ne retenez qu'une chose d'AA-Briefcase, retenez ceci : un rang dans un benchmark est un signal de capacité générale, pas une promesse sur la façon dont un modèle se comporte sur vos données désordonnées spécifiques.
J'ai vu cela se produire en direct. Nous avons passé des années à mettre des agents IA sur des files d'attente de support en production, et ce qui fait trébucher les équipes n'est pas si le modèle sous-jacent est assez intelligent dans l'abstrait, c'est s'il reste précis sur leurs tickets spécifiques, les particularités de leur produit et leurs cas limites. Un modèle qui domine tous les classements publics peut quand même citer avec confiance votre politique de remboursement de façon incorrecte dès le premier jour, bien avant d'atteindre la résolution automatisée des tickets. Ce n'est pas une critique du modèle ; c'est la différence entre un benchmark et la production.
La solution repose sur le même instinct qu'AA-Briefcase : évaluer le travail par rapport à la réalité avant de lui faire confiance. Pour un helpdesk, cela signifie faire tourner l'IA sur vos propres tickets historiques et voir exactement ce qu'elle aurait répondu, plutôt que de lire une fiche technique en espérant le meilleur. Imaginez que vous exécutez votre propre AA-Briefcase privé, où l'ensemble de test est votre vrai historique de support.
Essayez eesel pour un support IA en qui vous pouvez vraiment avoir confiance
Si AA-Briefcase vous a convaincu que capacité et fiabilité ne sont pas la même chose, c'est exactement le problème autour duquel eesel AI a été conçu. eesel fonctionne comme un nouveau membre de l'équipe de support qui se branche sur votre helpdesk et votre base de connaissances existants en quelques minutes, puis vous permet de le simuler sur des milliers de vos tickets passés avant qu'il ne parle jamais à un client, pour que vous voyiez son vrai taux de résolution et ses réponses exactes à l'avance plutôt que de les deviner dans un classement.

Vous gardez le contrôle de ce à quoi il est autorisé à répondre et quand il escalade, et c'est gratuit pour essayer sur vos propres données. Si vous évaluez l'IA pour le service client, cette approche simuler-d'abord est ce qui se rapproche le plus d'apporter la rigueur « prouve-le sur du vrai travail » d'AA-Briefcase à votre propre file d'attente.
Questions fréquemment posées
Qu'est-ce que le benchmark AA-Briefcase ?
Quel modèle d'IA est le meilleur sur AA-Briefcase ?
Pourquoi les modèles d'IA obtiennent-ils des scores si faibles sur AA-Briefcase ?
Un score élevé sur AA-Briefcase signifie-t-il que le modèle est sûr à déployer ?
En quoi AA-Briefcase est-il différent des autres benchmarks IA ?
Puis-je utiliser AA-Briefcase pour choisir un outil IA pour le support client ?

Article by
Alicia Kirana Utomo
Kira is a writer at eesel AI with a Computer Science background and over a year of hands-on experience evaluating AI-powered customer service tools. She focuses on breaking down how helpdesk platforms and AI agents actually work so that support teams can make better buying decisions.









Comment est calculé le score d'AA-Briefcase ?