AIチケット削減がすべてのCXアジェンダのトップに戻ってきた理由
サポートリーダーは予算を増やしていません。しかし、キューははるかに大きくなっています。Freshworksのカスタマーベンチマークレポート2025によると、2025年には**カスタマーサービス担当者の53%**が「ヘッドカウントを増やさずにチケット量を管理すること」を最大の課題として挙げており、ビジネスサービスのエージェントの90%が繰り返し作業により高価値のチケットに取り組む時間が妨げられていると述べています。
経済的な根拠は、2つの数字を並べれば明らかになります。人間が処理するチケットの平均コストは業界全体で8〜12ドルで、Forresterによると、B2B SaaSでは25〜35ドルに達します。AIが処理するチケットは、AIがアカウントデータを調べてアクションを実行する場合でも、平均0.50〜1.05ドルです。これはインタラクションあたり12〜24倍のコスト差であり、削減するチケットごとに複利で増加します。
これが、カスタマーサービスにおけるAIが2024年の120億6千万ドルから2030年までに478億2千万ドルに成長すると予測されている理由であり、25.8%のCAGRで成長しています。また、Gartnerによると 2027年までに800億ドルのグローバルサポートコスト削減が見込まれているのが、バイヤーがスクリーンショットする見出しです。
しかし、ほとんどの記事がスキップする部分があります。AIを導入した後にコストが横ばいまたは上昇していると47%の企業が報告している理由は、AIではありません。同じ壊れたワークフローにAIを組み込み、その結果を「転送」と呼んでいるからです。これが次のセクションで解説する失敗モードです。
「転送」と「削減」- 言葉は重要
この分野での多くの混乱は、人々がこれらの用語を同義に使用することから来ています。これらは同じものではありません。
- 転送は戦術です:チケットが開かれる前に、顧客が回答(または実際に回答するセルフサービスのパス)を得ることです。
- 削減は成果です:人間の時間を必要とするチケットの減少。削減には転送が含まれますが、数秒でチケットを閉じるAIトリアージ、人間がワンクリックで送信できるドラフト、そもそも質問が発生しないようにするプロアクティブな製品・UXの修正も含まれます。
これが重要な理由:転送率のみを最適化するチームは、Corebeeが50以上のサポートチームのスレッドを分析したように、静かに顧客が人間に到達することを難しくします。削減を最適化するチームはファネル全体を見ます。これには、やはり人間に届くべきチケットも含まれ、ただそれが速く安く行われます。
「私はチケット転送を信じていません。チケットを不要にすることを信じています。違いがあります。転送は顧客をリダイレクトします。チケットを不要にすることは、質問の原因を修正します。」
Corebee.aiのディスカッション分析で引用されたサポートリード
この区別を、この記事の残りの部分で念頭に置いてください。私たちが「AIチケット削減」と言うとき、ダッシュボードの転送数字だけでなく、ファネル全体を意味しています。
14%の問題:ほとんどの転送ダッシュボードが教えていないこと
この記事全体で最も重要な数字があります。そして、それはほぼ誰も引用しない数字です:
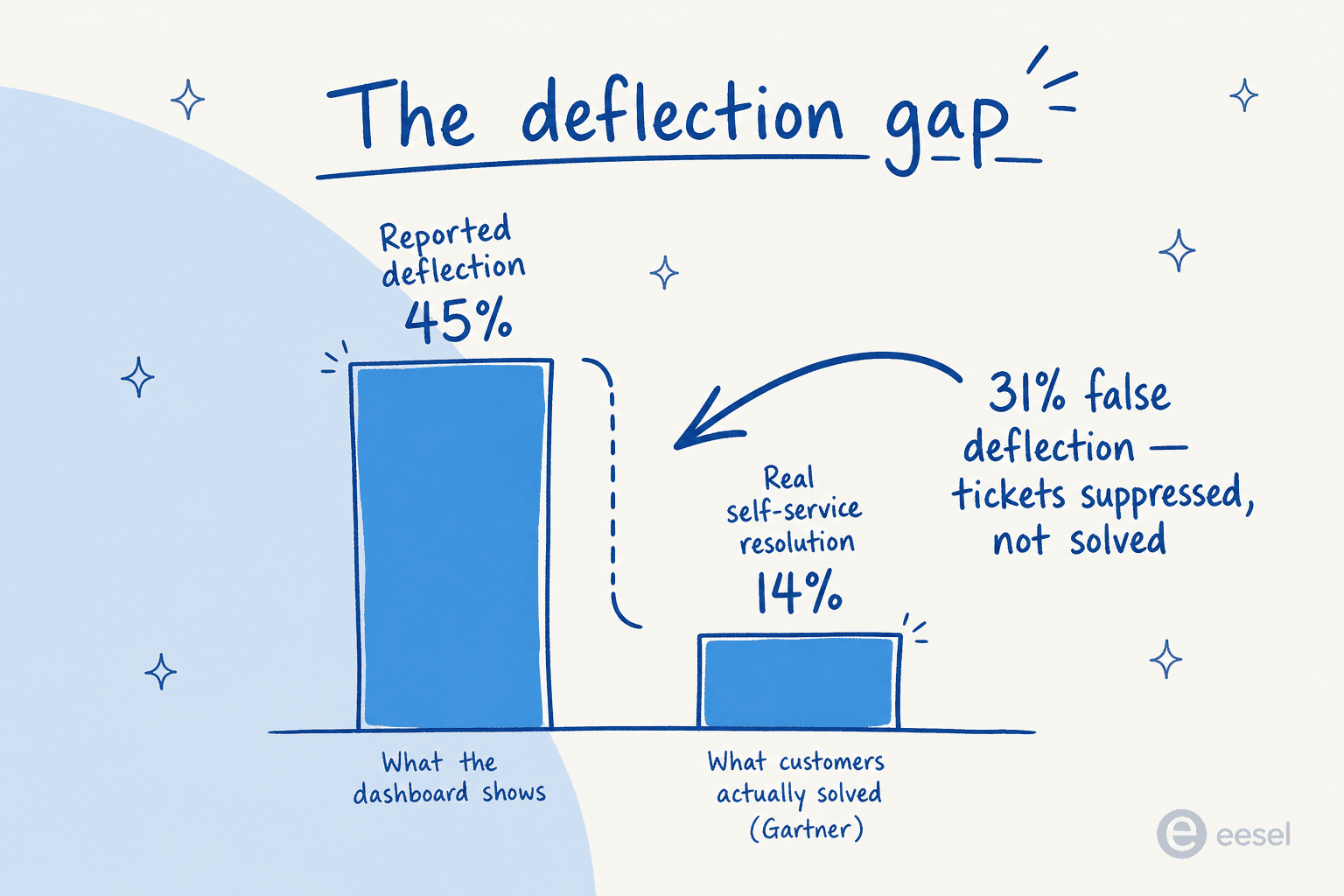
GartnerはAIが顧客クエリの45%以上を転送することを発見していますが、完全なセルフサービス解決に達するのは約14%のみです。残りの約31%が、この分野が偽の転送と呼ぶものです。チケットはあなたのプラットフォームでは開かれませんでしたが、顧客は助けを得ていません。彼らは別の場所、電話、メール、ソーシャルメディア、または競合他社に向かいました。
Corebee.aiが引用した100,050件のサポートインタラクションの別の研究では失敗メカニズムが明らかになりました:AIボットは、転送率をKPIとして最適化するように設定されている場合、人間よりも37%多く問題を解決から遠ざけることがわかっています。ボットの仕事は「会話を閉じること」であり、「問題を解決すること」ではなくなっています。
チームが調整された数式を実行すると、ギャップが最も明確に見えます:
実際の転送率 = (セルフサービス解決数 − 48時間以内の再問い合わせ数)÷ ヘルプを求めた総試行数
この計算を行うほとんどのチームは、実際の転送率が報告されている率より15〜25%低いことを発見します。80%の転送を示すダッシュボードは、55〜65%の実際の解決率を意味している可能性があります。50%を示すダッシュボードは35〜40%を意味している可能性があります。実際の数字を把握することが、数字を実際に動かすための前提条件です。
重要なポイント:転送率を単独のKPIにしないでください。 ボットが解決した会話のCSAT、48時間再問い合わせ率、チャネルシフト率と並行して追跡してください。正直な結果を得ているチームはすべてこれを行っています。抑制されたメトリクスを取得しているチームはそうしていません。
AIチケット削減が実際に何をしているか
何を測定するかを把握したら、次の質問はAIがチケットを削減するときに実際に何をしているかです。ほとんどの記事はこれを「AIはNLPと機械学習を使用する」という曖昧な説明で済ませます。2026年におけるアーキテクチャは以下のようになっています:
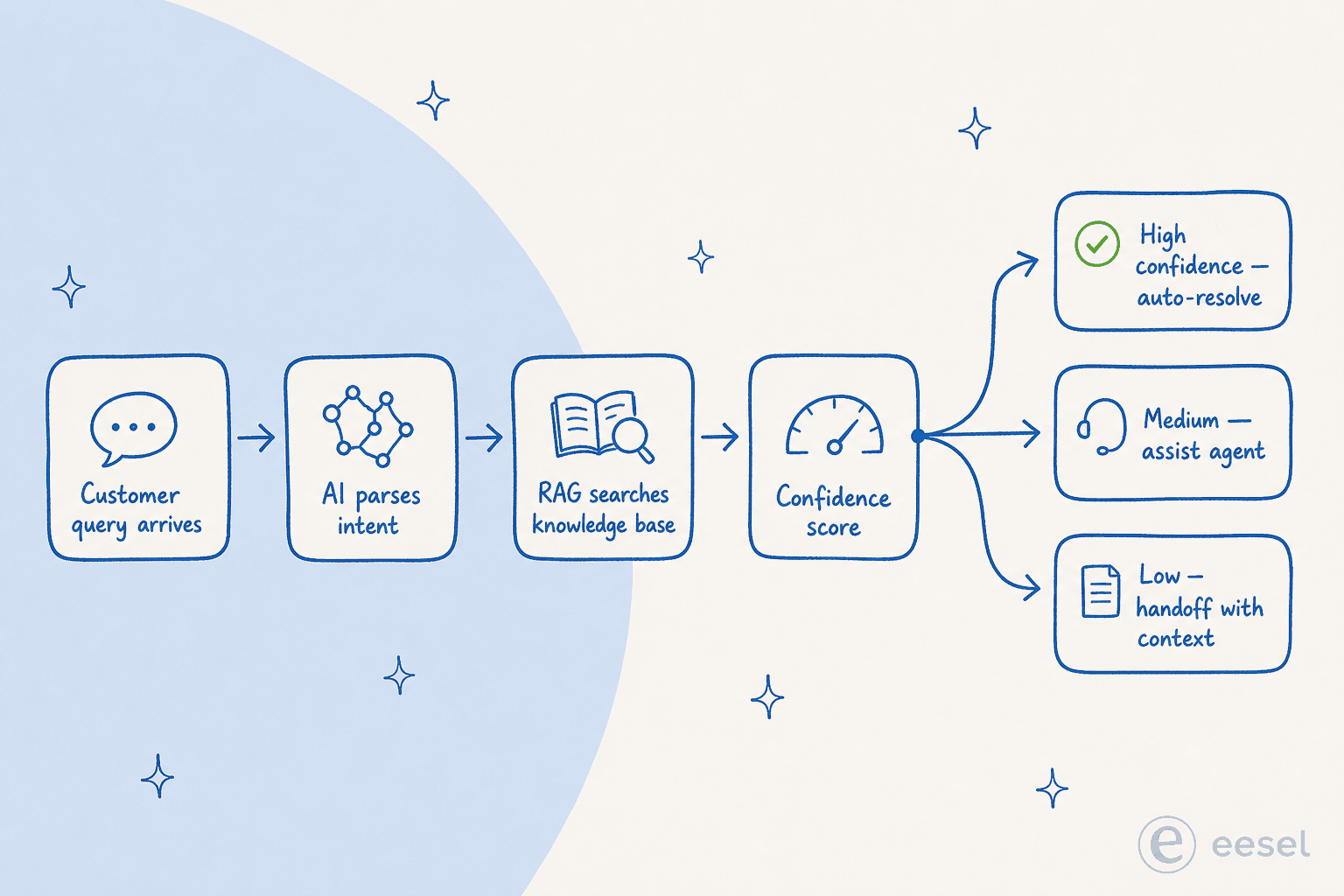
- インテント解析。 LLM(GPT-4クラス、Claude、Gemini)が受信したクエリを読み取り、インテント、緊急度、感情、および関連エンティティ(注文番号、アカウントティア、エラーコード)を抽出します。これが2018年のキーワードマッチングチャットボットに取って代わったレイヤーであり、システムが言い回しや曖昧さを処理できる理由です。「私のものが動かない」は「ログインできない」と同じようにルーティングされます。
- ナレッジベース検索(RAG)。 システムはクエリとナレッジベースを同じベクター空間に埋め込み、意味的に一致する記事と過去の解決事例を見つけ、最初から生成するのではなく取得されたコンテンツに基づいた回答を合成します。ClarityArcはこれを率直に述べています:「チケット転送エージェントは会話型インターフェースを持つ知識検索システムであり、その品質の上限は取得するナレッジベースの品質によって決まります。」
- 信頼度スコアリングとルーティング。 システムは信頼度スコアを割り当て、何をするかを決定します:高信頼度→回答して閉じる;中程度→人間へのパスが目立つ形で回答を提示する;低信頼度→完全なコンテキストとともに即時エスカレーション。
- アカウント固有のアクション。 エージェント型AIの大きなアンロック:記事を取得するだけでなく、エージェントはCRM/課金/注文システムを読み取り、アクションを実行します。注文の確認、返金の処理、サブスクリプションの更新。統合の深さは、ナレッジベースの品質に加えて転送の品質に20〜30%追加します。なぜなら、実際の質問のほとんどは一般的なコンテンツではなくアカウントのコンテキストを必要とするからです。
- コンテキストを持つエスカレーション。 AIが処理できない場合、顧客を最初に戻しません。人間のエージェントに完全な会話の要約、関連するアカウントの状態、エスカレーションした理由を渡します。これが「AIが試みて失敗した」と「AIがトリアージを行ったので人間が90秒で解決できる」の違いです。
無視するとスタック全体がクラッシュするため、ここで注意すべき2つの警告があります:
- LLMの信頼度は事実の信頼度ではありません。 LLMはハルシネーションした回答に対して95%の信頼度を持つことがあります。信頼度スコアはトークン確率を測定し、真実を測定するものではありません。生の信頼度を唯一のゲートとして使用しないでください。KBカバレッジシグナルとトピックスコープルールと組み合わせてください(DEV Community HITLポストモーテム)。
- KBがあなたの上限であり、モデルではありません。 GPT-4をClaudeに交換しても、35%で止まっている転送率は修正されません。ナレッジベースを更新してスコープを絞ることで修正されます。
削減しやすいものと難しいもの
ほとんどの記事がぼかすもう一つの数字:AIチケット削減はクエリタイプ間で均一ではありません。同じエージェント、同じKB、同じモデルでも、何に向けるかによって全く異なる数字が得られます。
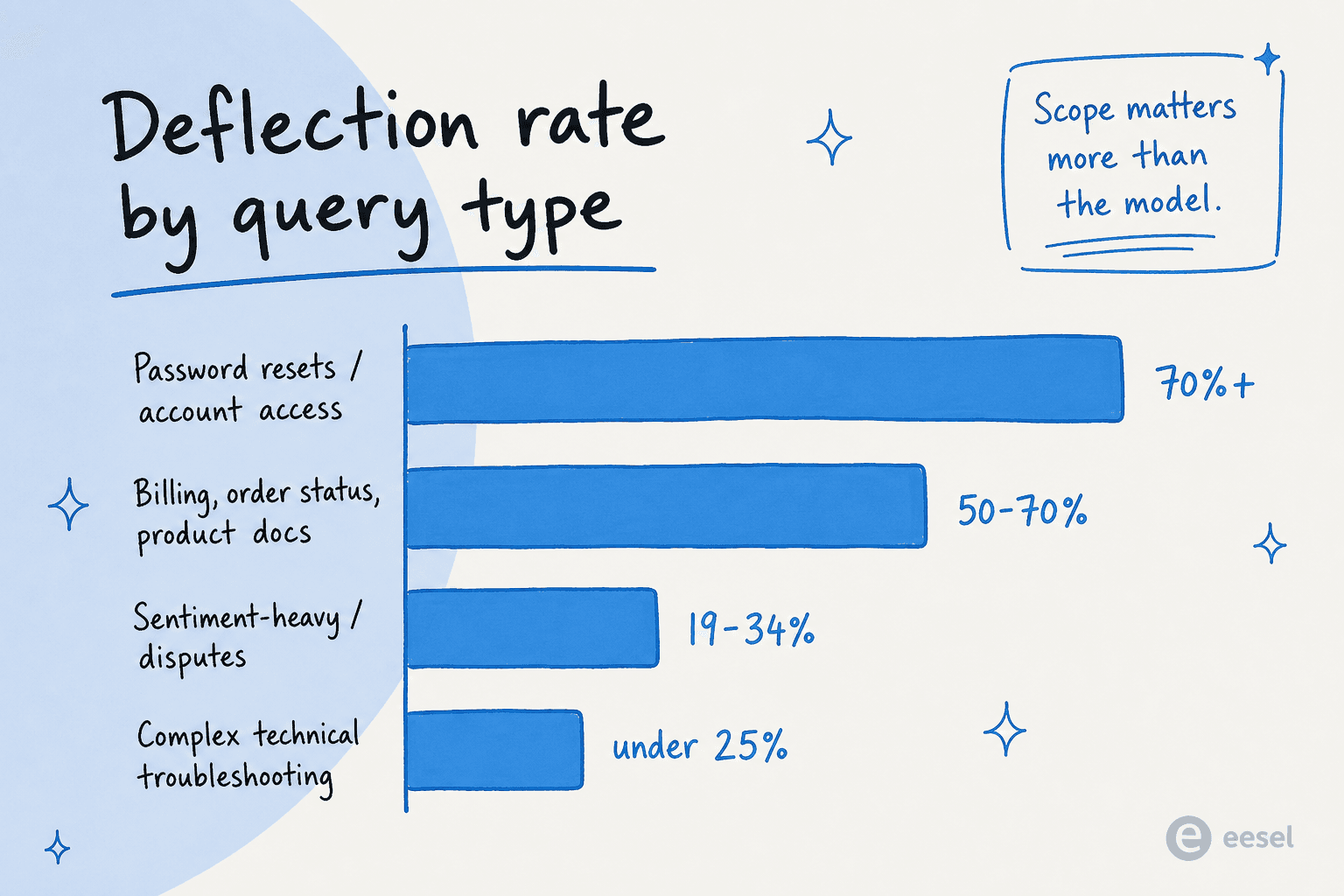
ClarityArcの2026年ベンチマークとPylonの転送ガイドによると:
| クエリタイプ | 典型的な転送率 | 理由 |
|---|---|---|
| パスワードリセット / アカウントアクセス | 70%以上 | 高ボリューム、決定論的、システム・オブ・レコードの回答 |
| 注文状況 / WISMO | 50〜70% | 統合が完了したらバックエンド検索 |
| 返金・返品(標準ポリシー) | 50〜70% | 明確なKB + エージェント型アクション利用可能 |
| 標準的な製品 / ハウツードキュメント | 50〜70% | KB依存、よく整備されている |
| 複雑な技術的トラブルシューティング | 25%未満 | 各ケースは新規;人間の推論が必要 |
| 感情的 / 争議スタイル | 19〜34% | 情報だけでなく感情的コンテキスト |
| 規制 / コンプライアンスが敏感 | 20%未満 | リスクとレビューがスピードより優先 |
これが、AIチケット削減プロジェクトで最もレバレッジが高い決定がベンダー選択ではなくスコープである理由です。テーブルの上半分にある2〜3つのクエリタイプを選び、60〜70%の実際の転送率を達成し、それから拡張します。1日目に「すべて」を選ぶと、平均がそれほど大きく落ち込んでプロジェクトが中止されます。
私たちの見解: チームが始めたばかりなら、まずパスワードリセットとWISMOから始めましょう。これらは高ボリューム、決定論的であり、チームの残りのメンバーがプロジェクトを支持するほど目立ってキューを削減します。1日目に苦情チケットを転送しようとすることが、AIプロジェクトが社内の信頼を失う原因です。
実際のチームからの実際の数字(そして共通点)
事例研究のハイライトリールは本物ですが、重要なのは*「私たちも86%を達成すべきだ」ということではありません。それは「各ケースがどれほど厳密にスコープが絞られていたかを見てください」*ということです。
- Grammarly はForethoughtのエージェント型プラットフォームを使用して10日間で転送率が60%から87%に上昇し、CSATは4.2/5に改善されました。システム統合の追加によりさらに5〜10%貢献しました。
- Bilt Rewards はAIエージェントで毎月60,000件のチケットの70%を処理しています。
- Duolingo はDecagonで80%以上の転送率を維持しています。
- KlarnaのAI は全カスタマーサービスの3分の2を処理しています。フルタイムエージェント700人相当です。
- Freshworksの小売顧客 はFreddy AIがすべての受信クエリの53%を解決しています。
- GorgiasのeCoommerce顧客 はトレーニング時間を最小限にしても60%の転送率を通常達成しています。
共通の要素はプラットフォームではありません。オペレーティングモデルです:初日のタイトなスコープ、深いCRM/注文/課金統合、調整された信頼度閾値、クリーンなエスカレーションパス、そしてすべてのエスカレーションをナレッジベースの更新として使用する習慣。ベンダーは変わりますが、規律は変わりません。
eeselの独自の顧客ベンチマークも同じパターンを反映しています。ZendeskビジネスのギグエコノミードライバーアナリティクスはZendesk Businessで、7日間のトライアル後の最初の月にティア1リクエストの73%を解決しました。Jira Service ManagementのIT内部ヘルプデスクは、KBとエージェントスコープが拡大するにつれて、55%を目標に現在15%の転送率を達成しています。動く数字はモデルではなく、入力です。
実際に数字を動かすチームが正しくやっていること5つ
Corebee.aiが分析した50以上の本番デプロイのドシエ、Pylonの転送ガイド、ClarityArcの本番プレイブック全体で、正直な60%以上の削減を達成するすべてのチームに同じ5つの変数が現れています。
1. まずナレッジベースの品質、次にAI
これはシステム全体で最も影響力の高いレバーです。よく構造化されたドキュメントはモデル設定に触れる前に本物の解決率を15〜25%向上させます。ほとんどのパイロットが停滞する理由は、チームが必要なKBではなく、持っているKBにAIを向けているからです。持っているKBは、製品をすでに知っている人間のエージェントのために書かれており、冷たく回答しなければならないAIのためではありません。
修正は機械的です:スコープを設定する2〜3つのインテントを選び、対応するKB記事を監査し、内部用語の代わりに自然言語の質問のために書き直し、最近解決されたチケットを具体的な例としてKBに取り込みます。それから展開します。
スパースなKBから始める場合は、AIナレッジベースチャットボットの構築と適切なAIナレッジベースツールの選択に関するガイドでデータ配管をカバーしています。
2. タイトにスコープを設定する。さらに狭く。
ディスカッション分析で最も一貫した失敗モードは、チームが初日に「すべて」をカバーしようとすることです。KBが本当に完全な2〜3つのクエリタイプから始めます。それらをうまくカバーして、正直に測定し、ギャップを修正し、60%以上の実際の転送率を超えてからのみ拡張します。
初日のスコープから除外されるもの:
- 感情的なもの(返金の争議、苦情、名前のついたアカウントからのエスカレーション)
- 規制またはコンプライアンスに敏感なもの
- KB以外のコンテキストの読み取りが必要なもの(エンジニアリングのバグ、インシデント中のシステム状況)
- 最上位アカウントからのチケット - VIPは最初のメッセージで人間に転送、常に
3. AIが説明するだけでなく実行できるほど深く統合する
AIがKB記事のみを取得できる場合、転送率は約35〜40%でプラトーになります。60〜90%の導入はすべて、エージェントが実際のアクションを実行できるCRM、課金、注文システムの統合を持っています。注文の確認、返品の処理、プランの変更。
ClarityArcのデータは統合の深さがKBのみの転送に加えて20〜30%追加することを示しています。これに関する最も強力な実践者の引用:
「本当のアンロックは、AIがシステム全体で問題をエンドツーエンドで実際に解決できる場合です。何を言うべきかを提案するだけではありません。」
これは、ボルトオンのルールベースチャットボットが失敗する傾向がある理由でもあります。これらは取得しますが、実行しません。顧客がアカウントデータが必要な質問をし、ボットが失敗し、転送率が上がりながらCSATが下がります。AIネイティブプラットフォーム、つまりヘルプデスク、CRM、注文システムを1つのランタイムで読み取るプラットフォームは、そのループを閉じます。
4. 信頼度ルーティングを調整する - AIが「わからない」と言えるようにする
これは私たち自身の顧客コールドシエの中での行き詰まった異議申し立てでした:
「AIは100%の質問に答えることはできませんが、試みて『すみません、これはわかりません』とだけ答えても、7,000件のチケットすべてをチェックしてAIが実際に良い回答をしたかどうかを確認することはできません。私は、処理に自信があるチケットのみを処理し、他のチケットはすべてほっておくようなAIが必要です。」
Gorgias + Shopify(月約7,000チケット)のDTCサプリメントブランドのCXリード、eesel顧客ドシエ(同意に基づいて匿名化)
これは一つの引用に凝縮された信頼度ルーティングに関するすべての論旨です。すべてに回答するAIは、半分に回答して残りを明確にエスカレーションするAIよりも悪い。 高/中/低の閾値は感覚ではなく実際のトラフィックでのテストを通じて調整し、KBが進化するにつれて四半期ごとに再調整します。
これについてより深く読みたい場合は、Zendesk AIエージェントのインテント信頼度閾値の内訳で、実際のヘルプデスクがどのように実装するかを解説しています。
5. すべてのエスカレーションを学習シグナルとして扱う
AIがエスカレーションするたびに、3つのことのいずれかを教えています:KBにギャップがある、スコープがこのインテントに対して間違っていた、または信頼度閾値の調整が必要です。最も高い転送率を達成するチームは、20〜30件のエスカレーションされた会話の週次レビューを行い、パターンをKBの更新、スコープの変更、またはルーティングルールに変換します。
反対のパターン、つまりエスカレーションが未読のまま積み重なり、ボットが静かに間違った回答をし、誰も監査しない、これが65%の転送率が静かに65%の抑制率になり、6ヶ月後にチャーンが急増する仕組みです。
AIチケット削減がうまくいかない場合(設計すべき失敗モード)
Corebeeが分析した50以上のサポートチームのスレッド、DEV Communityのポストモーテム、SaaStrの2025年6月の分析の実践者の会話で同じパターンが繰り返されます。これをロールアウトする場合は、初日からこれらを設計に組み込んでください:
- 転送率がKPIになる。 それが人々が評価される数字になると、システムはその数字を達成するように設計されます。顧客体験を犠牲にしてでも。CSATと再問い合わせ率と並行してシグナルとして追跡し、目標としてではなく。
- VIPがボットにあたる。 最も高コストな失敗モードは、月40ドルの顧客が人間を得る一方で、最上位アカウントがAIの壁に当たることです。VIPはメッセージ1から常に人間に直接ルーティングしてください。
- 自信を持った間違った回答。 ボットはエスカレーションすべきクエリに回答し、顧客はそれを信頼し、単純な質問が信頼の危機になります。修正はトピックスコープのガードレール(ボットはXについて回答することが許可されているが、Yについては許可されていない)であり、信頼度閾値だけではありません。
- エスカレーションなしのボットループ。 4クリック深くに埋もれた「人間と話す」ボタン、ボットがすでに尋ねた質問を再び尋ねるエスカレーションパス、または人間へのパスがまったくない。顧客はこれが体験になると静かにチャーンします。
- 他のチャネルを通じた再問い合わせの急増。 プラットフォームの転送率は上がりますが、電話キューはそれ以上に増えます。転送の勝利を喜ぶ前に、常にチャネルのボリュームをクロスチェックしてください。
1日あたり12,000以上のエージェントタスクを処理するチームのDEV Communityのポストモーテムは、このことを明確に示しています。高リスクタスクに人間のループのチェックを追加する前は、重大なエラー率は23.4%でした。エージェントはエンジニアリングに送るべき34件のチケットを自動クローズしました。3つのアクティブな本番インシデントを含みます。1人の顧客はデータ6時間分を失いました。
「そのインシデントは私たちに年間28万ドルの契約と非常に不快なポストモーテムを犠牲にさせました。」
適切なタスク(すべてのブランケットレビューではなく)にHITLを追加した後、重大なエラー率は5.1%に低下し、78%の削減であり、人間のレビューのオーバーヘッドは62%低下しました。チームが要約した教訓:「難しい部分はエージェントを構築することではなく、いつ信頼するかを決めることです。」
信頼を壊さないロールアウトプレイブック
これをすべて次の90日間で実際に実行できるものにまとめます:
1〜2週目 - 診断。 最後の1,000件のチケットを引き出します。インテントでタグ付けします。ボリュームとKB完全性で上位3つのインテントを見つけます。ボリューム単独では選ばないでください - 薄いKBの高ボリュームインテントはプロジェクトであり、クイックウィンではありません。
3〜4週目 - KBの準備。 各候補インテントについて、KB記事を書き直すか更新します。実際に解決されたチケットから5〜10の具体的な例を追加します。内部用語を排除します。ジュニアエージェントにKBから冷たく回答するように依頼してテストします。できない場合、AIもできません。
5〜6週目 - 統合の設定。 ヘルプデスク、CRM、注文/課金システムを接続します。エージェントはアカウントの状態への読み取りアクセスと、実際に実行させたいアクションへの書き込みアクセスが必要です。
7〜8週目 - コパイロットモードでパイロット。 AIをコパイロットとして実行します。返信のドラフト作成のみで、自律的に送信しません。人間のエージェントが変更なしでドラフトを送信する頻度、軽く編集する頻度、最初から書き直す頻度を測定します。スコープされたインテントでの「変更なしで送信」率が60%以上に達したら、自律型の準備ができています。
9〜12週目 - 最も安全なインテントで自律型に昇格。 1つのインテントから始めます。高い信頼度閾値。積極的なエスカレーションデフォルト。週次の会話監査。データがサポートする場合にのみ閾値を下げます。
これが、正直な60%以上の削減を報告するチームと80%に見えるように80%の転送率を報告するチームを分ける運営規律であり、テクノロジーではありません。より完全なウォークスルーについては、AIでサポートチケットを削減するための実践ガイドをご覧ください。
Try eesel
AIチケット削減をロールアウトしていて、上記のプレイブックに対して(対立するのではなく)設定されたプラットフォームが必要な場合、信頼度ベースのルーティング、Zendesk、Freshdesk、Gorgias、その他100以上との深い統合、チケットタイプ別のスコープ制御、テストに対してペナルティを与えない価格設定、これがまさにeeselが構築された目的です。
eeselのエージェントは既存のヘルプデスク内に組み込まれ(プラットフォームの置き換えなし)、既存のチケット履歴とKBから初日に学習し、自然言語で簡単に指示できます。「WISMOキューを処理し、500ドル以上の返金はエスカレーション、怒っているチケットはほっておいて。」価格はタスクごとであり、シートごとや解決ごとではないため、AIが実際に触れたチケットにのみ支払います。
実際の顧客は素早く動きました。Zendesk BusinessのギグエコノミードライバーアナリティクスはZendesk Businessで、7日間のトライアル後の最初の月にティア1リクエストの73%を解決しました。 英国のサポートチームは、わずか9つのシンクされたマクロから56件の解決済みタスクを実現しました。無料ティア(50ドルのクレジット、カード不要)は、実際のデータで本物のパイロットを行うのに十分です。
eeselを無料で試す → - または、スタックを一緒に確認したい場合は30分のデモを予約するしてください。
よくある質問
AIチケット削減とは何ですか?
AIチケット削減で現実的にどのくらい削減できますか?
AIチケット削減とAIチケット転送の違いは何ですか?
AIチケット削減の投資回収にはどのくらいかかりますか?
AIで削減しやすいサポートチケットはどれですか?
AIチケット削減を正直に測定するにはどうすればよいですか?
AIチケット削減でサポートエージェントは不要になりますか?
Zendesk、Freshdesk、またはGorgiasに最適なAIチケット削減ツールは何ですか?

Article by
Riellvriany Indriawan
Riell is a designer and writer at eesel AI with about two years of experience researching CX platforms, AI chatbots, and helpdesk software. She combines her design background with a sharp eye for how these tools actually look and feel in practice — making her comparisons unusually visual and user-focused.