
Ce pour quoi Together AI vous facture réellement
La plupart des articles sur les tarifs tentent de faire entrer Together AI dans un schéma de niveaux Build / Scale / Enterprise. La page des tarifs ne fonctionne tout simplement pas comme ça. Il n'y a pas de niveaux nommés. Il n'y a pas de frais par utilisateur. Il n'y a pas de minimum mensuel en libre-service. Ce qu'il y a, ce sont quatre compteurs parallèles, chacun mesurant une unité de consommation différente, et n'importe quelle charge de travail peut atterrir sur un, deux ou les quatre, selon la manière dont vous déployez.
Les quatre piliers :
- Inférence serverless - vous appelez un endpoint compatible OpenAI
/v1/chat/completions, vous recevez une réponse, vous payez par million de jetons d'entrée et de sortie. La même surface couvre le chat, la vision, l'image, l'audio, la vidéo, la transcription, les embeddings et la modération, chacun avec son propre tarif par modèle (Tarifs Together AI). - Inférence dédiée - Together met à votre disposition une instance GPU à locataire unique, vous la maintenez active 24h/24 et 7j/7, vous payez par heure-GPU. Le compteur dédié ignore totalement le volume de jetons ; vous payez pour un siège réservé, pas pour les trajets.
- Clusters GPU - vous louez le matériel NVIDIA brut (de 8 à plus de 4 000 GPU, connectés par InfiniBand) à la demande ou en réservé jusqu'à six mois. C'est pour les équipes qui entraînent leurs propres modèles ou gèrent leurs propres moteurs d'inférence.
- Fine-tuning - l'entraînement est facturé par jeton de données d'entraînement, indexé sur la taille du modèle et la méthode (LoRA, FT complet, DPO). Ensuite, le modèle résultant va sur un endpoint dédié, qui possède son propre compteur horaire.
C'est important car choisir le bon compteur est là où se trouvent les économies. Une start-up traitant 5 millions de jetons par jour sur Llama 3.3 70B n'a rien à faire sur un endpoint dédié ; une charge de travail de production stable traitant 500 millions de jetons par jour sur le même modèle, oui. Le PDG de Together AI, Vipul Ved Prakash, présente la plateforme comme le « Cloud d'accélération de l'IA » se situant entre les deux (LinkedIn), et la structure tarifaire reflète cela : serverless pour commencer, dédié quand vous pouvez prédire la charge, clusters quand vous entraînez.

Tarifs de l'inférence serverless
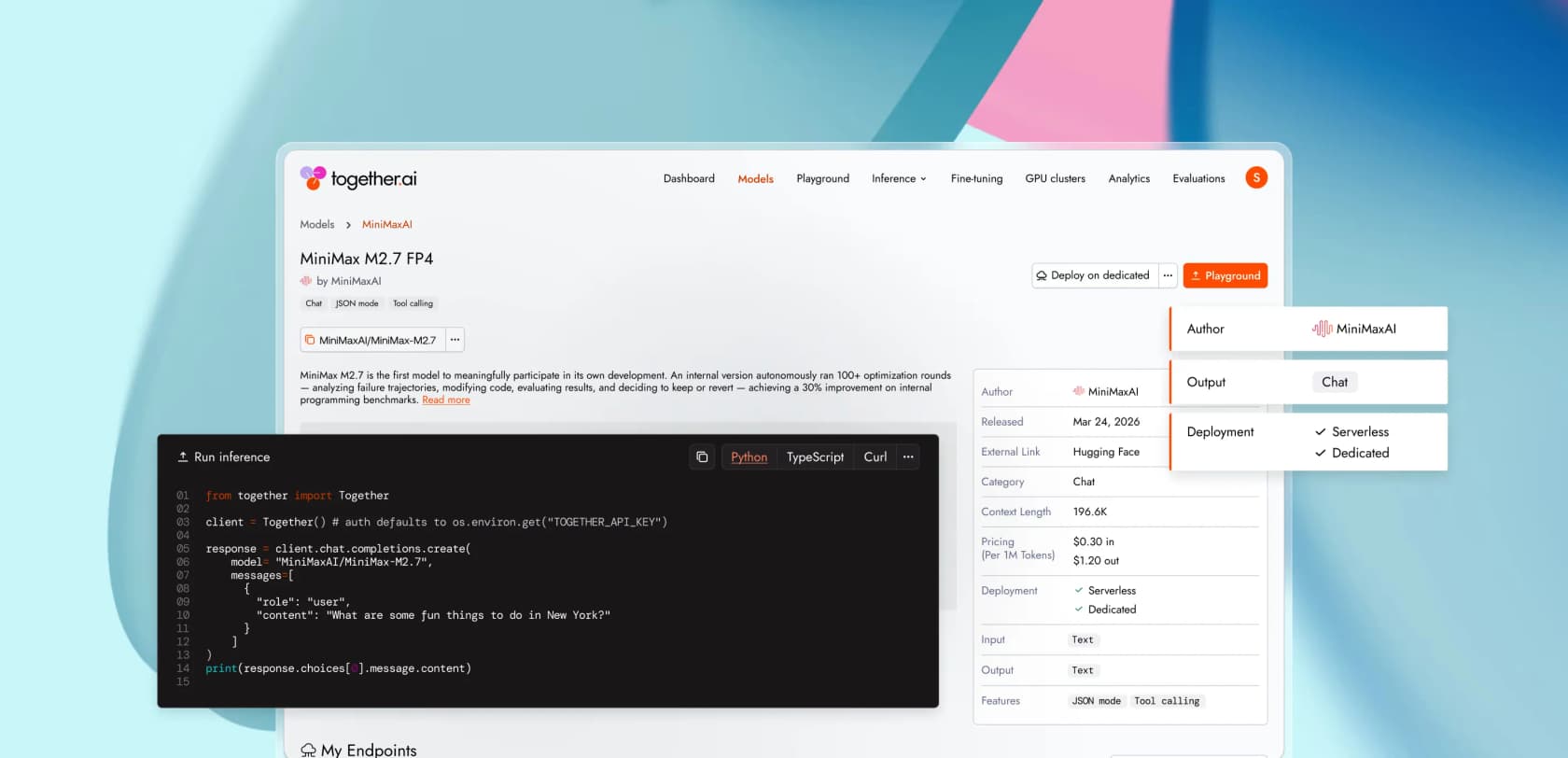
Le serverless est la porte d'entrée, et c'est le compteur sur lequel la plupart des équipes vivront. Le tableau des modèles de chat sur together.ai/pricing liste les tarifs par million de jetons pour chaque modèle supporté, divisés en entrée, sortie, et (sur certains modèles) un tarif d'entrée mise en cache nettement moins cher que le tarif de base.
Un échantillon représentatif de l'onglet chat, repris textuellement (Tarifs Together AI) :
| Modèle | Entrée $/M | Sortie $/M | Entrée en cache $/M |
|---|---|---|---|
| GLM-5.1 | 1,40 $ | 4,40 $ | - |
| MiniMax M2.7 | 0,30 $ | 1,20 $ | 0,06 $ |
| Kimi K2.6 | 1,20 $ | 4,50 $ | 0,20 $ |
| DeepSeek V4 Pro | 2,10 $ | 4,40 $ | 0,20 $ |
| DeepSeek V4 Flash | - (pas de prix affiché) | - | - |
| Qwen3.6-Plus | 0,50 $ | 3,00 $ | - |
| Qwen3.7-Max | 1,25 $ | 3,75 $ | 0,13 $ |
| gpt-oss-120B | 0,15 $ | 0,60 $ | - |
| gpt-oss-20B | 0,05 $ | 0,20 $ | - |
| Llama 3.3 70B | 1,04 $ | 1,04 $ | - |
| Qwen3 235B A22B FP8 Throughput | 0,20 $ | 0,60 $ | - |
| LFM2 24B A2B | 0,03 $ | 0,12 $ | - |
| Cogito v2.1 671B | 1,25 $ | 1,25 $ | - |
Trois points méritent d'être soulignés dans ce tableau.
Premièrement, le tarif des entrées mises en cache est le levier dont personne ne parle. Le coût d'entrée de DeepSeek V4 Pro passe de 2,10 $/M à 0,20 $/M lorsque le préfixe du prompt est mis en cache - une réduction de 10,5 fois. Kimi K2.6 baisse de 6 fois. MiniMax M2.7 de 5 fois. Si votre charge de travail réutilise un long prompt système ou possède des contextes utilisateur répétés (la plupart des boucles d'agents, la plupart des pipelines RAG), le tarif en cache est le tarif réel. Le chiffre hors cache du tableau est le pire scénario.
Deuxièmement, la vague de modèles sur laquelle vous surfez compte plus que le fournisseur. gpt-oss-20B et LFM2 24B coexistent sur la même page de tarifs que DeepSeek V4 Pro et GLM-5.1. L'écart de 100 fois entre 0,03 $/M (entrée LFM2) et 4,50 $/M (sortie Kimi K2.6) est bien plus important que l'écart entre Together et ses concurrents pour le même modèle. « Together est bon marché » n'est pas une affirmation utile ; « ce modèle spécifique est bon marché sur Together » l'est généralement.
Troisièmement, la vision, l'image, l'audio et la vidéo portent tous des compteurs séparés par modèle - les modèles d'image facturent par mégapixel ou par image (FLUX.2 [pro] est à 0,03 $/image ; Google Imagen 4.0 Ultra est à 0,06 $/MP), les modèles vidéo facturent par vidéo terminée (Sora 2 est à 0,80 $, Google Veo 3.0 avec audio est à 3,20 $), et l'audio est divisé entre le tarif par minute (Whisper Large v3 à 0,0015 $) et par million de caractères (Cartesia Sonic-3 à 65 $) (Tarifs Together AI). Si vous construisez une application multimodale, vous touchez plusieurs compteurs à la fois et votre « facture Together » est la somme, pas un taux unique.
L'entrée serverless inclut également une API Batch : traitez jusqu'à 30 milliards de jetons par modèle de manière asynchrone avec un coût jusqu'à 50 % inférieur au serverless synchrone (Mises à jour de l'API Batch Inference 2025). Pour les charges de travail qui n'ont pas besoin de latence en temps réel - génération de données synthétiques, classification hors ligne, enrichissement de logs - le batch est le chemin légitime le moins cher sur la plateforme.
Together met en avant le niveau serverless tant sur la vitesse que sur le prix. D'après la page produit d'inférence, les comparaisons publiées indiquent « jusqu'à 2,75x plus rapide » sur Qwen3 235B 2507, « plus de 65 % plus rapide » sur Kimi K2 0905, et « 2x plus rapide » sur gpt-oss-20B par rapport au fournisseur suivant le plus rapide sur chaque benchmark. Un nombre plus élevé de jetons par seconde par GPU est, en fin de compte, ce qui permet à Together de facturer moins tout en conservant ses marges - c'est le même matériel, mais effectuant plus de travail par seconde.
Nos chercheurs et ingénieurs s'engagent à accélérer l'inférence de l'IA pour qu'elle soit aussi rapide que les lois de la physique le permettent.
Ce Zhang, CTO, via Ryan Pollock sur LinkedIn
Tarifs de l'inférence dédiée
Une fois que votre charge de travail dépasse le serverless partagé - ou, plus souvent, une fois que la latence imprévisible des infrastructures partagées devient un problème pour votre produit - les endpoints dédiés de Together AI vous permettent de provisionner une instance GPU à locataire unique et de payer à l'heure (Tarifs Together AI) :
| Matériel | Prix par heure |
|---|---|
| 1× H100 80 Go | 6,49 $ |
| 1× H200 140 Go | Nous contacter |
| 1× HGX B200 180 Go | 11,95 $ |
Le calcul est brutal dans un sens. Un H100 laissé en marche 24 heures sur 24, 30 jours par mois, coûte 4 672,80 $/mois par GPU. Un B200 sur la même période revient à 8 604 $. Le volume de jetons est sans importance - même avec zéro requête, le compteur tourne.
Il est aussi brutal dans l'autre sens, de manière positive. À un volume de requêtes suffisamment élevé, le coût effectif par jeton sur un endpoint dédié chute sous le tarif serverless. Le seuil de rentabilité dépend du modèle, mais en règle générale pour un modèle de classe 70B sur serverless à 1,04 $/M de jetons dans les deux sens, vous commencez à économiser sur le dédié au-delà de ~5 milliards de jetons/mois de trafic régulier et prévisible. En dessous, le serverless gagne presque toujours sur le coût ; au-dessus, le dédié gagne et vous bénéficiez en plus d'une latence constante.
L'équipe de recherche de Salesforce est l'un des points de référence publiés pour ce niveau :
Nous avons été impressionnés par Together. Ils ont permis une réduction de 2x de la latence et ont réduit nos coûts d'environ un tiers.
Caiming Xiong, VP, Salesforce AI Research, page d'inférence Together AI
Si vous envisagez le dédié, la question à laquelle vous devez répondre n'est pas « le H100 à 6,49 $/h de Together est-il moins cher que X ? » - c'est « ai-je une charge de travail assez stable pour qu'un GPU tournant 24h/24 soit moins cher que des jetons facturés principalement pendant les heures de bureau ? » Pour beaucoup d'équipes, la réponse honnête est non.
Tarifs des clusters GPU - à la demande vs réservés
Sous les endpoints dédiés se trouve le niveau le plus brut de la pile : des clusters GPU loués que vous opérez vous-même (gpu-clusters). C'est ici que finissent les équipes qui entraînent leurs propres modèles, gèrent des moteurs d'inférence personnalisés ou montent en charge au-delà de ce que les endpoints dédiés proposent.
Tarifs des clusters à la demande (libre-service, paiement à l'usage, résiliation possible à tout moment, jusqu'à 256 GPU) (Tarifs Together AI) :
| Matériel | Prix par GPU par heure |
|---|---|
| NVIDIA HGX H100 | 5,49 $ |
| NVIDIA HGX H200 | 6,79 $ |
| NVIDIA HGX B200 | 9,95 $ |
Les tarifs des clusters réservés diminuent avec la durée, avec un engagement maximal publié de 180 jours ; tout ce qui dépasse nécessite un formulaire de demande de cluster GPU pour un tarif entreprise personnalisé (Tarifs Together AI) :
| Matériel | 7-30 jours | 31-90 jours | 91-180 jours | 181+ jours |
|---|---|---|---|---|
| NVIDIA HGX H100 | 4,99 $ | 4,49 $ | 3,99 $ | Nous contacter |
| NVIDIA HGX H200 | 5,95 $ | 4,99 $ | 4,55 $ | Nous contacter |
| NVIDIA HGX B200 | 9,65 $ | 9,35 $ | 9,09 $ | Nous contacter |
| NVIDIA GB200 NVL72 | Nous contacter | Nous contacter | Nous contacter | Nous contacter |
| NVIDIA GB300 NVL72 | Nous contacter | Nous contacter | Nous contacter | Nous contacter |
Trois éléments rendent le niveau cluster intéressant comparé à une location de GPU chez un hyperscaler.
Premièrement, des performances bare-metal avec une interconnexion InfiniBand partout. L'argument de Together est que « notre interconnexion InfiniBand maintient une synchronisation rapide des gradients et une faible surcharge de communication - ainsi vos entraînements se terminent plus vite, pas seulement en plus grand » (Together AI gpu-clusters). C'est important car un entraînement 30 % plus rapide sur le même matériel est, en effet, une remise de 30 % sur le même tarif horaire.
Deuxièmement, la collection de noyaux Together (Together Kernel Collection) est livrée avec le cluster. TKC (conçue par le chercheur en chef Tri Dao, créateur de FlashAttention) est la même couche d'optimisation qui alimente l'inférence serverless de Together, et elle est disponible aussi sur les clusters. Le benchmark publié : « L'entraînement d'un modèle d'architecture Llama de 70B paramètres (BF16) avec un TorchTitan optimisé + Together Kernel Collection (TKC) a atteint 15 264 jetons/seconde/GPU sur NVIDIA HGX B200, contre 8 080 jetons/seconde sur NVIDIA HGX H100 - un bond de 90 % de la vitesse d'entraînement » (Together AI gpu-clusters).
Troisièmement, le stockage n'est pas une réflexion après coup. Les clusters sont livrés avec des systèmes de fichiers parallèles Weka ou VAST attachés à 0,16 $/Gio/mois sans frais de sortie (egress) (Tarifs Together AI). Quiconque a déjà quitté un hyperscaler de rage à cause des frais de sortie S3 comprendra pourquoi c'est important.
Together AI fournit la performance et la fiabilité dont nous avons besoin pour la génération d'images et de vidéos de haute qualité en temps réel à grande échelle.
Victor Perez, Co-fondateur, Krea, Together AI gpu-clusters
Tarifs du fine-tuning - et le coût d'hébergement dont personne ne vous prévient
Le fine-tuning sur Together est facturé par jeton de données d'entraînement, et non par époque ou par heure-GPU (docs de fine-tuning Together AI). Le calcul est explicite sur la page des tarifs : « Le prix est basé sur la somme des jetons traités dans le jeu de données d'entraînement (taille du jeu de données × nombre d'époques) plus les jetons éventuels dans le jeu de données d'évaluation optionnel (taille du jeu de données de validation × nombre d'évaluations) » (Tarifs Together AI).
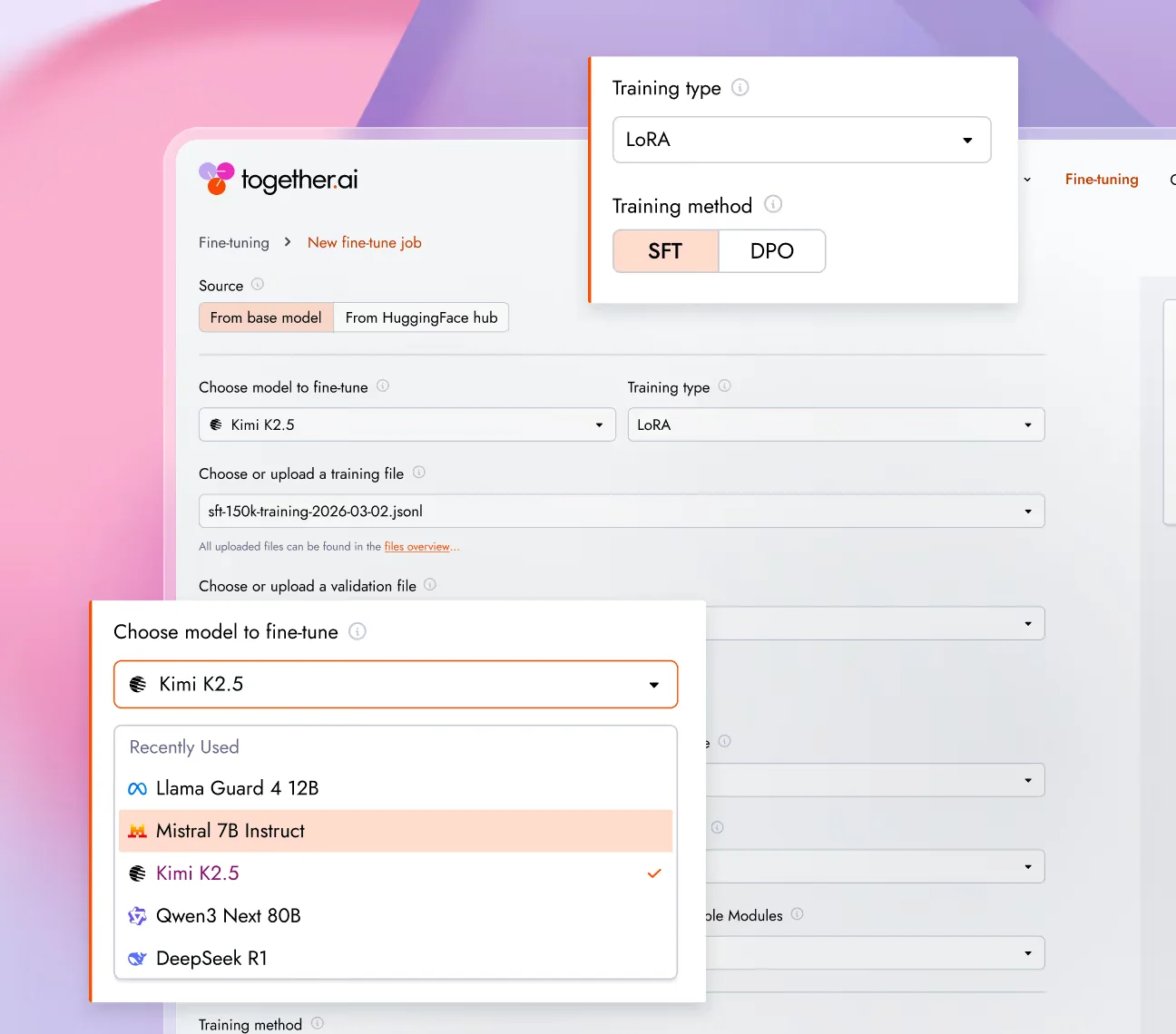
Le tableau des tarifs standards varie selon la taille du modèle de base et la méthode de réglage (Tarifs Together AI) :
| Taille du modèle de base | SFT - LoRA | SFT - Complet | DPO - LoRA | DPO - Complet |
|---|---|---|---|---|
| Jusqu'à 16B | 0,48 $ / M | 0,54 $ / M | 1,20 $ / M | 1,35 $ / M |
| 17B–69B | 1,50 $ / M | 1,65 $ / M | 3,75 $ / M | 4,12 $ / M |
| 70B–100B | 2,90 $ / M | 3,20 $ / M | 7,25 $ / M | 8,00 $ / M |
Au-delà de 100B paramètres, Together tarifie le fine-tuning par modèle dans un niveau « spécialisé », souvent avec une charge minimale par tâche (Tarifs Together AI) :
| Modèle | SFT (LoRA) | DPO (LoRA) | Minimum |
|---|---|---|---|
| Famille DeepSeek-R1 / V3 / V3.1 | 10,00 $ / M | 25,00 $ / M | 20,00 $ |
| GLM-4.6 / 4.7 | 9,00 $ / M | 22,50 $ / M | 27,00 $ |
| GLM-5 / GLM-5.1 | 40,00 $ / M | 100,00 $ / M | 60,00 $ |
| gpt-oss-120B | 5,00 $ / M | 12,50 $ / M | 6,00 $ |
| Kimi K2 (Thinking / Instruct / Base) | 15,00 $ / M | 37,50 $ / M | 60,00 $ |
| Llama 4 Maverick / Maverick Instruct | 8,00 $ / M | 20,00 $ / M | 16,00 $ |
| Llama 4 Scout | 3,00 $ / M | 7,50 $ / M | 6,00 $ |
| Qwen3-Coder-480B-A35B-Instruct | 9,00 $ / M | 22,50 $ / M | 18,00 $ |
| Qwen3-235B-A22B / Instruct-2507 | 6,00 $ / M | 15,00 $ / M | Pas de min. |
| Qwen3.5-122B-A10B | 6,00 $ / M | 15,00 $ / M | 10,00 $ |
| Qwen3.5-397B-A17B | 8,00 $ / M | 20,00 $ / M | 22,00 $ |
Le tableau ci-dessus est celui que la plupart des gens citent. Le chiffre qu'ils oublient est qu'une fois le modèle entraîné, son hébergement est une charge séparée et continue.
D'après la documentation : « Une fois l'entraînement terminé, l'inférence s'exécute sur un endpoint dédié » (docs Together AI). Cet endpoint dédié est facturé aux mêmes tarifs que le niveau d'inférence dédiée - 6,49 $/h pour un H100 ou 11,95 $/h pour un B200 (Tarifs Together AI). Un LoRA sur une base de 16B peut s'entraîner pour moins d'un dollar par million de jetons d'entraînement, mais maintenir le modèle résultant actif sur un seul H100 en permanence coûte environ 4 700 $/mois par GPU, peu importe s'il traite une requête ce mois-là.
C'est le plus gros piège tarifaire de la plateforme. Des équipes calculent régulièrement que « le fine-tuning nous coûtera 30 $ pour l'exécution » - ce qui est correct - puis découvrent que la facture d'hébergement est de deux ordres de grandeur supérieure. Prévoyez le cycle de vie complet, pas seulement l'étape d'entraînement.
Quelques autres détails sur le fine-tuning faciles à manquer :
- Pas de niveau gratuit annoncé. Chaque exécution d'entraînement est facturée par jeton dès le premier jeton.
- LoRA est l'option par défaut, le fine-tuning complet est optionnel. Les écarts de prix entre LoRA et Complet sont minimes (environ 0,30 $/M sur le niveau 70B), donc le choix porte généralement sur la qualité, pas sur le coût.
- Le DPO coûte environ 2,5x le SFT sur tous les niveaux de taille. Si vous alignez un modèle sur des préférences, prévoyez le budget en conséquence.
- BYOM (Bring Your Own Model) vous permet de charger une base hors catalogue. Les tarifs pour l'entraînement BYOM tombent dans le segment de taille standard correspondant ; l'hébergement suit les tarifs dédiés habituels.
Sandbox, interpréteur de code et stockage managé
Deux compteurs plus petits méritent d'être notés car ils surprennent beaucoup de constructeurs d'agents.
Code Sandbox vous permet de lancer des sandboxes VM isolées pour que les agents IA y exécutent du code. C'est facturé par vCPU et par Gio de mémoire, à l'heure (Tarifs Together AI) :
| Ressource | Prix par heure |
|---|---|
| Par vCPU | 0,0446 $ |
| Par Gio RAM | 0,0149 $ |
Une sandbox modeste de 4 vCPU et 8 Gio maintenue active pendant une journée de travail (8 heures) revient à environ 2,39 $ - peu individuellement, mais pour une flotte d'agents qui en lancent des dizaines en parallèle, les totaux peuvent vite grimper.
Code Interpreter est le cousin plus léger : une sandbox à session unique pour exécuter du code généré par LLM sans surcharge de pool actif, facturée 0,03 $ par session de 60 minutes (Tarifs Together AI). C'est le choix par défaut le plus sage pour la plupart des flux d'utilisation d'outils par des agents.
Managed Storage est le système de fichiers parallèle qui accompagne les clusters. Il est à 0,16 $ par Gio par mois sans frais de sortie (Tarifs Together AI). Un ensemble de travail de 10 To coûte environ 1 638 $/mois - comparable à un système de fichiers haute performance chez un hyperscaler, mais sans la facture de bande passante en sortie.
Ce qui est gratuit, et ce qui ne l'est pas
Cette partie est courte, car il n'y a pas grand-chose.
- Pas de niveau gratuit annoncé sur la page des tarifs publique. La page n'indique aucun montant de crédit à l'inscription, aucune période d'essai gratuit, ni aucun quota mensuel de tâches gratuites.
- L'API Batch est le seul mécanisme de réduction intégré : jusqu'à 50 % de réduction sur la plupart des modèles de chat pour les charges de travail asynchrones (Mises à jour de l'API Batch Inference 2025).
- Des remises sur volume ou engagement existent mais ne sont pas publiées - la page vous redirige vers Nous contacter pour les tarifs entreprise.
- L'entrée en cache est ce qui se rapproche le plus d'un cadeau : réduction de 5 à 10 fois sur les jetons d'entrée pour certains modèles de chat lorsque les préfixes sont réutilisés.
Les praticiens ont historiquement mentionné un crédit de démarrage :
Un crédit gratuit de 25 $ va loin quand même les modèles les plus chers sont à 0,9 $/million de jetons.
Chris Samiullah, ingénieur ML, LinkedIn
Ce chiffre n'est pas actuellement publié comme une politique fixe sur la page des tarifs. Si vous prévoyez un budget, considérez ce crédit comme un élément à « demander à votre gestionnaire de compte » plutôt que comme une garantie.
Comment les tarifs de Together AI se comparent à Fireworks, Groq, Replicate et les autres
La réponse honnête est que savoir si Together est le moins cher dépend entièrement du modèle que vous utilisez, du débit dont vous avez besoin et si vous êtes en serverless ou en dédié. Voici un comparatif pour les modèles partagés les plus courants, avec les tarifs tirés des pages de prix en direct de chaque fournisseur au 05/06/2026 :
| Fournisseur | Llama 3.3 70B entrée / sortie $/M | DeepSeek R1 entrée / sortie $/M | Mixtral 8x22B entrée / sortie $/M | Crédits gratuits | Modèle tarifaire |
|---|---|---|---|---|---|
| Together AI | 1,04 $ / 1,04 $ | DeepSeek V4 Pro : 2,10 $ / 4,40 $ (cache 0,20 $ entrée) | Absent de la gamme actuelle | Aucun annoncé ; Batch -50% | Serverless par jeton, dédié par heure-GPU |
| Fireworks AI | 0,90 $ / 0,90 $ (catégorie >16B) | DeepSeek V4 Pro : 1,74 $ / 3,48 $ | 1,20 $ / 1,20 $ (MoE 56-176B) | 1 $ de crédit gratuit | Serverless par jeton, à la demande par seconde-GPU |
| Groq | 0,59 $ / 0,79 $ | Absent de la gamme | Absent de la gamme | Inscription gratuite console | Serverless par jeton |
| Replicate | Par seconde de matériel | 3,75 $ / 10,00 $ | Par seconde de matériel | Aucun annoncé | Par seconde de matériel + par jeton pour certains modèles |
| Anyscale | Déploiement propre sur H100 à 9,29 $/h | Idem | Idem | 100 $ de crédit | Par heure-GPU (Anyscale Compute Units) |
| Modal | Auto-déploiement sur H100 ~3,95 $/h équiv. | Idem | Idem | 30 $/mois Starter, 100 $/mois Team | Par seconde de calcul |
| Hugging Face | Fournisseurs d'inférence tiers | Tiers | Tiers | PRO 9 $/mois + ZeroGPU gratuit | Heure d'endpoint + jetons tiers |
| OpenRouter | 0,10 $ / 0,32 $ | 0,50 $ / 2,15 $ (R1 0528) | 2,00 $ / 6,00 $ | Variantes gratuites limitées | Marketplace par jeton |
Quelques tendances ressortent de ce tableau.
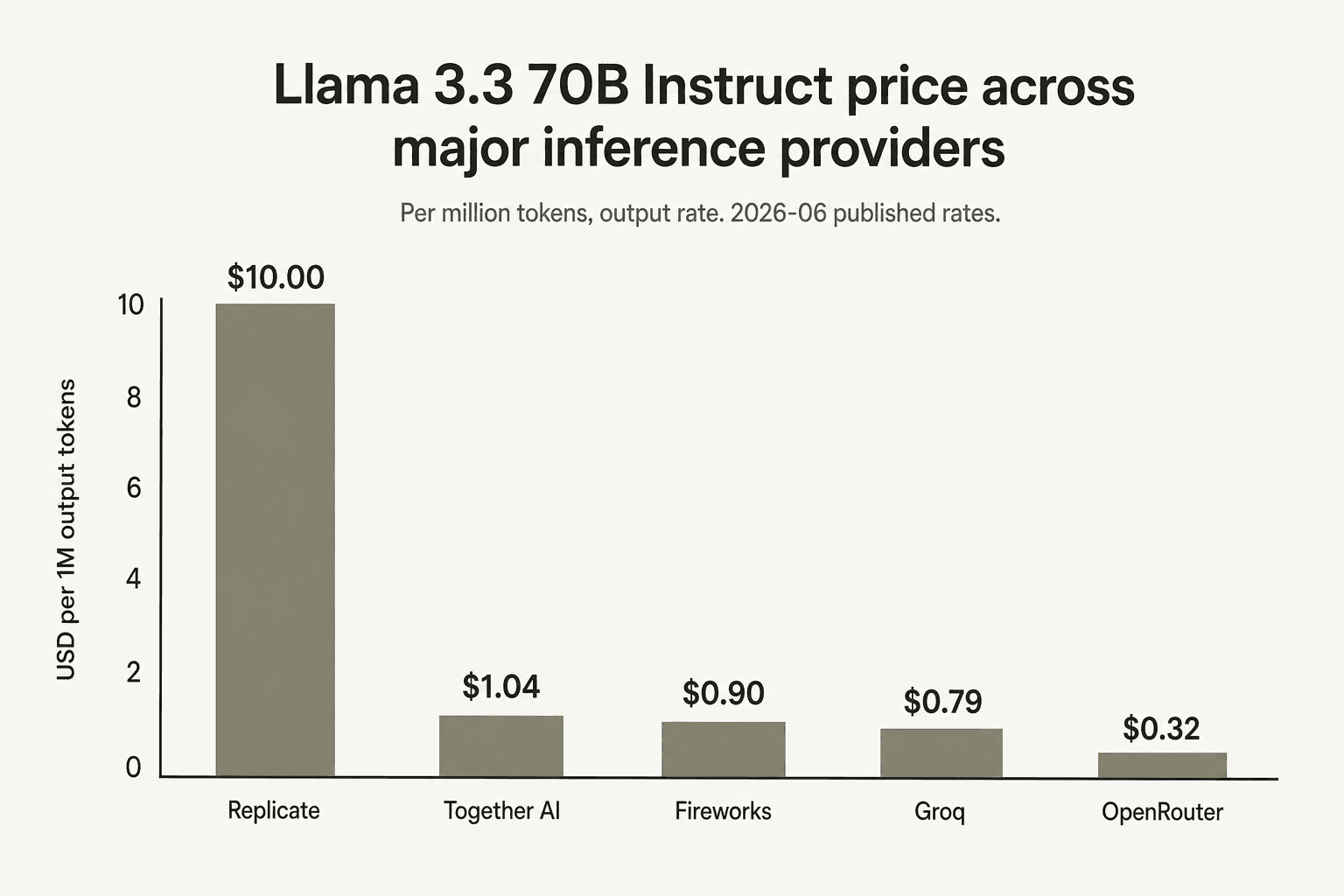
Sur Llama 3.3 70B spécifiquement, Together AI est dans la moyenne. Groq est le fournisseur direct le moins cher sur ce modèle classique populaire (0,59 $/0,79 $), Fireworks suit (0,90 $ fixe), Together est troisième (1,04 $/1,04 $), Replicate ne le propose pas au jeton, et OpenRouter - qui est une place de marché redirigeant vers le fournisseur sous-jacent le moins cher - devance tout le monde à 0,10 $/0,32 $. Si votre charge de travail consiste en « beaucoup d'inférence Llama 3.3 70B », Groq et OpenRouter méritent toute votre attention.
Sur les modèles de la nouvelle vague - Kimi K2.6, GLM-5.1, DeepSeek V4, Qwen3.6-Plus - Together est compétitif mais pas toujours le moins cher. Fireworks a tendance à lister ses nouveaux Kimi et DeepSeek individuellement avec des tarifs d'entrée en cache qui égalent ou battent ceux de Together. La différence se joue généralement entre 10 et 30 %, pas sur l'écart de 5 à 10 fois que l'on voit parfois dans les argumentaires marketing.
Pour l'hébergement GPU dédié, le paysage est plus vaste. Modal bat presque tout le monde sur le calcul par seconde (H100 ≈ 3,95 $/h équivalent à 0,001097 $/sec). Hugging Face Endpoints annonce 4,50 $/h pour un H100. Together est à 6,49 $/h pour l'inférence dédiée, 5,49 $/h pour un cluster à la demande, et 3,99 $/h pour un cluster réservé de 91-180 jours. Produits différents, factures différentes - et votre coût réel dépend de votre capacité à absorber la complexité opérationnelle d'un déploiement vLLM sur Modal plutôt que de laisser Together héberger un modèle pour vous.
Pour les embeddings, Together est parmi les moins chers à 0,02 $/M de jetons (Multilingual e5 large instruct) (Tarifs Together AI). Le compte d'entreprise de Together a historiquement annoncé un « coût jusqu'à 4x plus bas qu'OpenAI » sur les embeddings (@togethercompute sur X), et les tarifs actuels sont dans cet ordre de grandeur.
Pour les charges de travail batch, la remise de 50 % de l'API Batch de Together est l'argument phare. Fireworks propose aussi 50 % ; Groq également. Replicate, Modal et Anyscale n'ont pas de niveau de remise asynchrone comparable.
Pour des analyses plus poussées par fournisseur, nos comparatifs sur les tarifs Fireworks AI, les tarifs Baseten et les tarifs SambaNova Cloud complètent celui-ci. En résumé : choisissez le fournisseur le moins cher pour le modèle spécifique que vous déployez, pas le fournisseur le moins cher dans l'absolu.
Trois exemples concrets de ce que les équipes paient réellement
Le calcul des jetons est facile ; la facture à la fin du mois est ce qui compte. Voici trois scénarios avec les chiffres réels.
Exemple 1 - Une équipe SaaS gérant un assistant de chat intégré sur Llama 3.3 70B
Trafic : 5 000 conversations/jour, moyenne de 1 500 jetons d'entrée (prompt système + contexte récupéré) et 400 jetons de sortie par conversation. Environ 21 jours ouvrés par mois.
Calcul serverless au tarif Together de 1,04 $/M entrée + 1,04 $/M sortie :
- Entrée : 5 000 × 1 500 × 21 = 157,5 M jetons × 1,04 $ = 163,80 $/mois
- Sortie : 5 000 × 400 × 21 = 42 M jetons × 1,04 $ = 43,68 $/mois
- Total : ~207 $/mois pour l'inférence
Si cette équipe choisit Groq à 0,59 $ entrée / 0,79 $ sortie :
- 157,5 M × 0,59 $ + 42 M × 0,79 $ = 92,92 $ + 33,18 $ = ~126 $/mois
S'ils passent par OpenRouter à 0,10 $ entrée / 0,32 $ sortie :
- 157,5 M × 0,10 $ + 42 M × 0,32 $ = 15,75 $ + 13,44 $ = ~29 $/mois
Conclusion : à ce volume, le coût pur de l'inférence est assez faible pour que le choix se porte probablement sur la latence, la fiabilité régionale ou la réactivité du support - et non sur le tarif d'inférence.
Exemple 2 - Une start-up AI-native gérant une boucle d'agents Kimi K2.6 à grande échelle
Trafic : 200 M jetons d'entrée/jour, 50 M jetons de sortie/jour, avec environ 80 % d'entrées mis en cache (long prompt système + définitions d'outils réutilisées). 30 jours par mois.
Calcul Together avec tarif en cache intégré :
- Entrée (en cache) : 200 M × 0,80 × 30 × 0,20 $/M = 960 $/mois
- Entrée (hors cache) : 200 M × 0,20 × 30 × 1,20 $/M = 1 440 $/mois
- Sortie : 50 M × 30 × 4,50 $/M = 6 750 $/mois
- Total : ~9 150 $/mois
Sans la remise sur l'entrée en cache, la partie entrée seule serait de 7 200 $, ce qui signifie que ce levier permet d'économiser environ 5 800 $/mois dans ce scénario. La plupart des équipes sous-estiment l'importance de la remise sur l'entrée en cache car la plupart des comparaisons de prix citent le tarif hors cache.
Exemple 3 - Une équipe affinant Llama 4 Scout et l'hébergeant 24h/24
Entraînement : 500 M jetons de données d'entraînement sur Llama 4 Scout. Dans le niveau spécialisé, c'est 3,00 $/M Lo SFT avec un minimum de 6 $.
- Coût d'entraînement : 500 × 3,00 $ = 1 500 $ (frais unique)
Hébergement : 1× endpoint dédié H100 maintenu actif pour la production.
- 6,49 $/h × 24 h × 30 jours = 4 672,80 $/mois, chaque mois
Facture totale du premier mois : 1 500 $ + 4 672,80 $ ≈ 6 173 $. Régime de croisière à partir du deuxième mois : 4 673 $.
Le coût de l'entraînement semble être le chiffre principal. Le coût d'hébergement est la facture récurrente réelle. Si vous pouvez héberger le modèle affiné sur une capacité dédiée existante, ou si votre trafic justifie le serverless sur le modèle de base avec du prompt engineering ciblé au lieu d'un fine-tuning complet, vous pouvez supprimer totalement la ligne de 4 673 $. Prévoyez le cycle de vie.

Là où les tarifs de Together ont surpris les équipes
Le point commun le plus constant dans les avis négatifs sur G2 et Trustpilot ne concerne pas les tarifs affichés, mais la mécanique de facturation. Trois griefs reviennent souvent.
Frais d'autorisation non remboursés. Plusieurs utilisateurs sur Trustpilot décrivent l'ajout d'une carte bancaire suivi d'une autorisation de 1 $ censée être annulée, mais qui ne leur est jamais créditée :
Lorsque vous ajoutez une carte, il est explicitement dit : « Il y aura une charge immédiate de 1 $ pour autorisation, qui sera créditée en retour. » J'ai ajouté ma carte, j'ai été débité de 1 $, mais je ne les ai jamais récupérés.
Utilisateur sur Trustpilot, Together AI sur Trustpilot
Facturations à intervalles rapides et faible suivi des remboursements. Un autre problème de facturation :
Ils facturaient la carte bancaire à des intervalles de quelques secondes avec des montants bizarres - j'ai dû bloquer la carte en urgence. Support injoignable.
Utilisateur sur Trustpilot, Together AI sur Trustpilot
Après 2 semaines, ils n'ont toujours pas remboursé le solde restant sur mon compte prépayé, et ils n'ont pas non plus remboursé le montant pour le dépannage de la clé API désactivée.
Utilisateur sur G2, Together AI sur G2
Ces expériences ne sont pas forcément représentatives du client médian - la plupart des avis G2 sont positifs - mais elles sont assez fréquentes pour que l'on comprenne que les points négatifs concernent la facturation et la réactivité du support, pas les fonctionnalités. Si vous êtes une petite équipe sans gestionnaire de compte, utilisez une carte d'entreprise séparée avec une limite stricte et ne pré-chargez pas de gros soldes.
Surprise sur l'hébergement du fine-tuning. Nous l'avons couvert plus haut, mais il faut le répéter : le coût de maintien d'un modèle affiné est souvent 50 à 200 fois supérieur au coût de son entraînement pour un volume mensuel raisonnable. Cela surprend beaucoup d'équipes. Le compteur de l'endpoint dédié ne s'arrête pas quand le modèle est inactif.
Le temps d'ingénierie est le plus gros coût invisible. Extrait d'une critique récurrente de praticiens sur LinkedIn et X à propos des tarifs de Together AI :
Utiliser Together AI n'est pas exactement une expérience plug-and-play. Cela demande beaucoup de temps de développement pour intégrer son API, construire une application autour, puis maintenir ce système dans le temps. Ces coûts d'ingénierie peuvent vite s'accumuler et finissent souvent par être bien plus élevés que l'utilisation de l'API elle-même.
Critique de praticien via les discussions LinkedIn / X sur les tarifs de Together AI
Ce n'est pas un reproche spécifique à Together ; cela s'applique à toute plateforme d'inférence brute par API. Si le temps de votre équipe d'ingénieurs n'est pas gratuit, le tableur comparant le Llama 3.3 70B à 1,04 $/M de Together au 0,59 $/M de Groq devrait aussi inclure les semaines-ingénieurs nécessaires pour gérer l'authentification, la logique de réessai, l'observabilité, la validation des sorties structurées, le versionnage des prompts, les pipelines d'évaluation et l'astreinte. Pour beaucoup d'équipes, ces postes d'ingénierie éclipsent totalement la ligne de frais d'inférence.
Quand Together AI est le bon choix - et quand il ne l'est pas
Là où la tarification de Together brille réellement :
- Vous utilisez des modèles open-source affinés avec un trafic de production stable et prévisible. Les endpoints dédiés à 6,49 $/h ou les clusters réservés à 3,99 $/h par H100 sont compétitifs face aux locations de GPU des hyperscalers et coûtent une fraction du prix des API propriétaires de pointe pour des niveaux de qualité équivalents.
- Vous avez besoin de clusters GPU avec InfiniBand sans avoir à gérer votre propre centre de données. La gamme de 8 à plus de 4 000 GPU de Together et sa présence dans plus de 25 villes, combinées à l'avantage de performance de la Together Kernel Collection, sont réellement compétitives en dehors des plus grands hyperscalers (gpu-clusters).
- Vous construisez des expériences multimodales et voulez une API unique. Le niveau serverless couvre le chat, la vision, l'image, l'audio, la vidéo, la transcription, les embeddings et la modération, vous évitant de jongler entre six comptes différents.
- Vous gérez de grosses charges de travail asynchrones ou batch. La réduction de 50 % de l'API Batch, s'ajoutant à des tarifs serverless déjà compétitifs, est difficile à battre pour la résumé hors ligne, la génération de données synthétiques, l'enrichissement de logs et la classification à grande échelle.
Là où Together AI n'est pas l'outil idéal :
- Vous voulez simplement l'endpoint Llama 3.3 70B le moins cher possible. Groq est plus rapide et moins cher sur ce modèle spécifique. OpenRouter est encore moins cher. Together est dans la moyenne pour les modèles hérités.
- Vous êtes une petite équipe qui souhaite un agent IA managé pour un besoin spécifique - tickets de support, chat de vente, aide interne - et vous ne voulez pas assembler vous-même l'inférence + la récupération + l'utilisation d'outils + l'interface + l'évaluation. C'est là qu'une plateforme facturée au résultat a plus de sens ; nous y reviendrons.
- Vous voulez une tarification prévisible et plafonnée. Le paiement à l'usage sur plusieurs compteurs est difficile à prévoir. Sans plafond de dépense, une boucle d'agent incontrôlée peut coûter cher avant que quelqu'un ne s'en aperçoive.
- Vous avez besoin d'un SLA publié sur le temps de réponse du support. Plusieurs avis négatifs signalent un manque de réactivité du support pour les litiges de facturation, point à négocier en amont dans un contrat entreprise.
Pour des comparatifs d'alternatives plus poussés, consultez notre tour d'horizon des alternatives à Together AI, notre avis sur Together AI et le guide plus large qu'est-ce que Together AI.
Essayez eesel quand vous préférez acheter des résultats plutôt que des jetons
Un article sur les prix de Together AI traite presque toujours des matières premières d'un produit IA - jetons, heures-GPU, latence d'inférence, jetons d'entraînement de fine-tuning. Ce sont les bonnes primitives si vous créez une entreprise de modèles de base ou un moteur d'inférence personnalisé. Ce sont les mauvaises primitives si ce que vous voulez vraiment, c'est un agent IA fonctionnel dans vos outils actuels.

eesel adopte l'approche opposée : une tarification par tâche pour un coéquipier IA entièrement managé qui s'intègre dans les helpdesks, les applications de chat et les boîtes de réception que vous utilisez déjà (Zendesk, Freshdesk, intégration Intercom, Slack, Gmail, Shopify et plus de 100 autres). Un ticket de support coûte 0,40 $. Une question sur un tableau de bord est gratuite. La génération d'un long article de blog coûte 4 $. L'inférence, la récupération, l'itération des prompts, les tentatives, l'évaluation et l'observabilité sont tous inclus dans ce chiffre - vous ne les voyez pas sur la facture et vous n'avez pas à les construire vous-même.
Embauchez des coéquipiers IA. Des coéquipiers totalement autonomes et incroyablement capables, présents dans vos applications actuelles et prêts en quelques minutes.
Comparatif concret pour l'équipe SaaS de l'Exemple 1 ci-dessus - 5 000 conversations/jour, assistant de chat intégré. Sur Together, la ligne d'inférence est d'environ 207 $/mois plus le temps d'ingénierie pour assembler la récupération, la logique de réessai, la validation de sortie, le versionnage de prompt et l'analytique. Sur eesel, ces mêmes 5 000 conversations × 21 jours = 105 000 tâches/mois à 0,40 $ chacune = 42 000 $/mois pour le même résultat - bien plus cher sur le papier, mais cela inclut un produit fini de bout en bout et un SLA sur les résolutions. La réponse dépend de si votre équipe préfère passer du temps à construire l'infrastructure ou à construire le produit.
Pour la plupart des équipes où le support IA, le chat IA ou le contenu IA est le résultat et non la technologie centrale, le modèle par tâche est gagnant. L'essai gratuit de 50 $ d'eesel vous permet de tester une charge de travail réelle - un agent de helpdesk, un rédacteur de blog, un agent d'e-commerce - sans carte requise, et la réduction sur l'engagement annuel est de 25 % au-delà de 300 $/mois de dépenses. Pas de frais par siège, pas de frais de plateforme en libre-service, pas de minimum mensuel.
Si vous êtes déjà sur Together AI et que vous en êtes satisfait, vous devriez y rester. Si vous êtes sur Together AI parce que vous ne trouviez pas d'alternative de plus haut niveau - c'est précisément le besoin qu'eesel comble.
Foire aux questions
Combien coûte l'utilisation de Together AI en 2026 ?
Together AI propose-t-il un niveau gratuit ou des crédits de démarrage ?
Together AI est-il moins cher que Fireworks AI, Groq ou Replicate ?
Quels coûts cachés dois-je surveiller sur Together AI ?

Article by
Rama Adi Nugraha
Rama is a software engineer at eesel AI with two years of experience writing about B2B SaaS, AI tools, and customer support technology. Based in Bali, Indonesia, he brings a developer's perspective to product comparisons — cutting through marketing copy to what the integrations and APIs actually do.







Comment fonctionne la tarification du fine-tuning sur Together AI ?