Enjambre de tickets con IA: qué es y dónde encaja la IA de verdad
Riellvriany Indriawan
Katelin Teen
Última edición June 19, 2026

¿Qué es el ticket swarming?
El ticket swarming (también conocido como case swarming, support swarming o modelo de soporte colaborativo) es un enfoque en el que, en lugar de escalar un ticket a través de niveles, un grupo de personas colabora en él juntos. Una persona asume la responsabilidad y convoca a los expertos que necesita, en lugar de transferir el ticket y desvincularse.
La versión formal proviene del Consortium for Service Innovation, el mismo organismo detrás de Knowledge-Centered Service (KCS). Acuñaron "Intelligent Swarming" y lo definen como "una forma más inteligente de alinear los recursos con el trabajo… eliminando los niveles de soporte y, cuando es apropiado, recurriendo a la experiencia colectiva de un 'enjambre' de analistas." Zendesk enmarca la misma idea para el soporte al cliente como "un enfoque utilizado por los equipos de servicio al cliente que aprovecha la colaboración en lugar de la escalada para resolver un problema complejo del cliente."
Como Jon Stevens-Hall de BMC expone los principios fundamentales, el swarming es una inversión directa de la ortodoxia por niveles:
- No hay grupos de soporte por niveles.
- No hay escaladas de un grupo a otro.
- El caso va directamente a la persona más probable de resolverlo.
- Quien toma el caso lo acompaña hasta la resolución (mantiene la propiedad incluso mientras involucra a otros).
La idea no es nueva. Un pionero temprano importante fue Cisco, que presentó su "modelo de Digital Swarming en un documento técnico de 2008"; luego el Consortium lo desarrolló en Intelligent Swarming, y HDI menciona a Cisco, BMC, Red Hat y Allscripts como adoptantes tempranos que reportaron mejoras dramáticas. Lo nuevo es la "IA" delante, y eso cambia la matemática de una manera a la que llegaré.
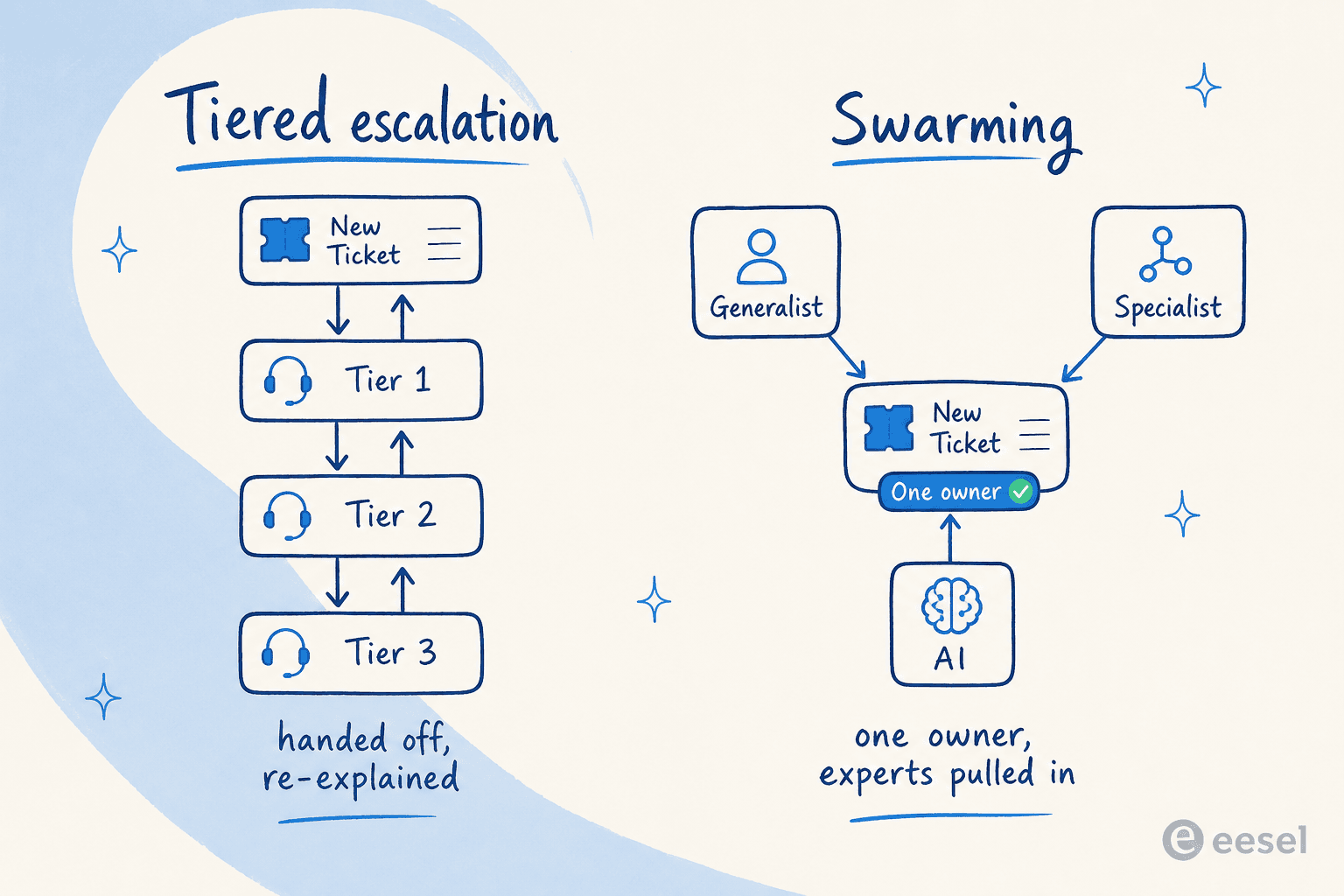
Swarming vs. soporte por niveles
Los niveles no son malos. Son un filtro, y uno bueno, cuando el trabajo encaja. El Consortium mismo señala que el soporte por niveles funciona cuando la mayoría de los problemas son simples y conocidos (95% o más), se resuelven en el primer contacto y cada nivel resuelve el 70-80% de lo que recibe. El problema comienza cuando esa mezcla cambia.
Así es como los dos modelos difieren realmente:
| Dimensión | Soporte por niveles | Swarming |
|---|---|---|
| Estructura | Silos y jerarquías (L1 / L2 / L3) | Un equipo en red |
| Asignación de trabajo | Se sube por la escalera | Se convoca / se adhiere voluntariamente |
| Proceso | Predefinido, lineal | Emergente, colaborativo |
| Movimiento principal | Escalada | Colaboración |
| Propiedad del ticket | Cambia en cada paso | Un responsable, de principio a fin |
| Mejor para | Problemas de alto volumen, repetibles y conocidos | Problemas complejos, multidisciplinares y nuevos |
(Comparación extraída del Consortium's "How Does It Work" y la guía de case swarming de Zendesk.)
El Consortium tiene una gran metáfora para la diferencia: los niveles significan "múltiples equipos que pasan los problemas de un lado a otro mediante enrutamiento, reenrutamiento, escalada y rechazo (jugando al ping-pong)," mientras que el swarming lo colapsa todo en "un solo equipo de personas que colaboran… (juegan a pillar)." La línea práctica de Zendesk: "El soporte por niveles es excelente para problemas recurrentes… El case swarming es ideal para problemas más complejos donde se necesitan diferentes habilidades." La decisión de a dónde va cada ticket es, fundamentalmente, un problema de triaje de tickets.
Por qué todo el mundo dice de repente "ticket swarming con IA"
Esta es la parte que lo une todo. El argumento original para el swarming era demográfico: a medida que los clientes resuelven más de sus problemas conocidos mediante el autoservicio, los tickets que llegan a un humano son más difíciles. Es la misma lógica detrás de todo helpdesk con IA moderno. El Consortium señala que "los clientes de algunas empresas ahora resuelven el 80 por ciento de sus problemas mediante el autoservicio," lo que significa que lo que llega a la cola es desproporcionadamente nuevo, complejo y propenso a escalar, exactamente donde los niveles fallan.
La IA acelera ese cambio con fuerza. Una vez que un agente de IA y un buen autoservicio absorben el volumen repetible, lo que queda para los humanos se inclina aún más hacia los casos genuinamente difíciles. Así que "ticket swarming con IA" no se trata realmente de que la IA se una a un canal de Slack. Son dos trabajos distintos:
- La IA limpia el 95%: los tickets conocidos y repetibles, mediante automatización de tickets y clasificación, para que nunca necesiten un enjambre.
- La IA asiste al 5%: cuando se activa un enjambre real, hace la recopilación de contexto, el acceso a la base de conocimientos y la redacción de respuestas para que los humanos dediquen su tiempo a pensar, no a buscar.
El dato del 5% no es mío. La formulación más precisa que he visto vino de un profesional de Salesforce en Reddit, rebatiendo a alguien que no veía el sentido del swarming:
"El principal problema que justifica el swarming es el siguiente: el 5% de los casos consume hasta el 30%… del esfuerzo total de resolución debido a la complejidad, los muchos equipos involucrados, etc. … El swarming no es un juego de volumen; aborda un porcentaje muy pequeño de casos que requieren mucho tiempo para resolverse correctamente."
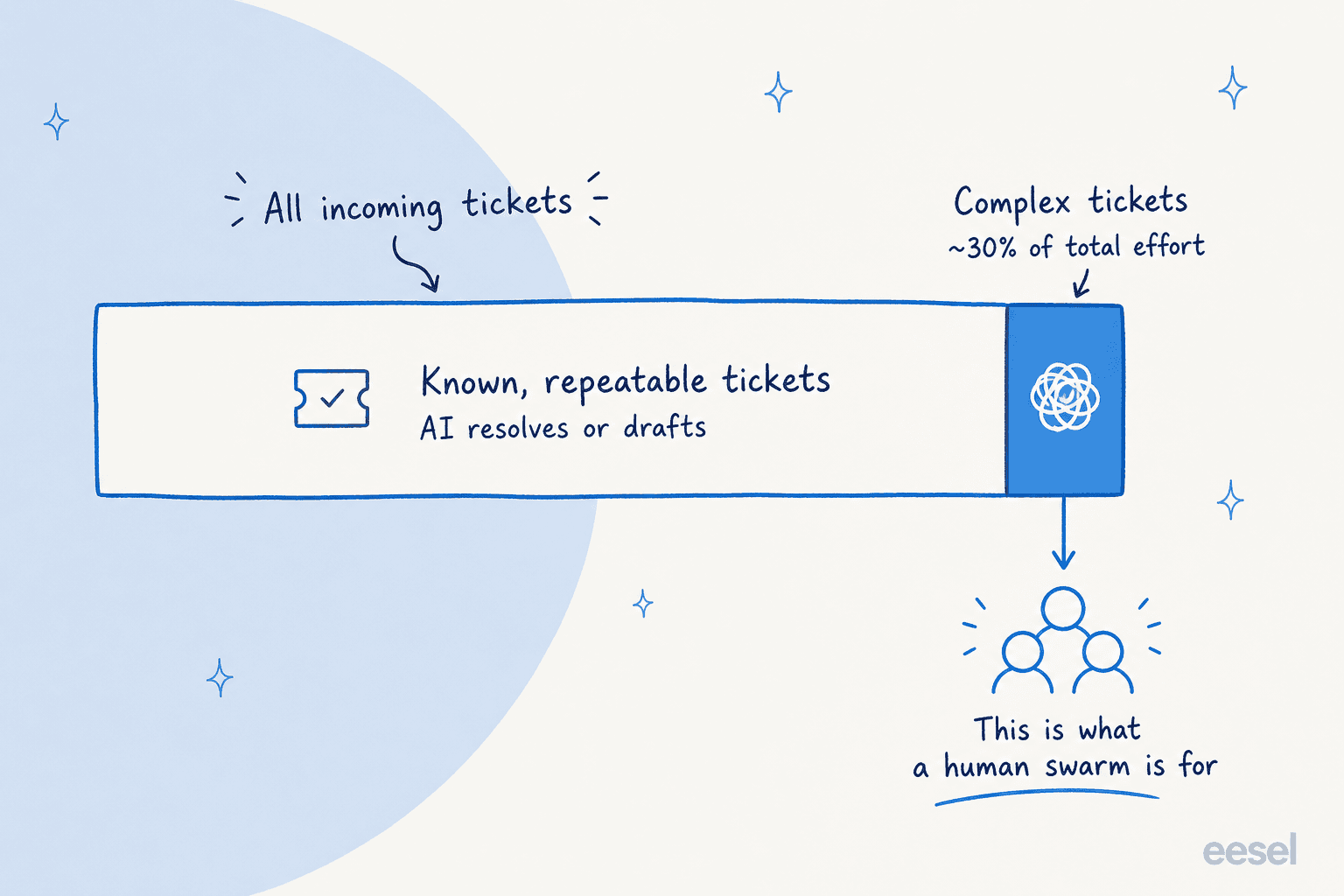
Ese es todo el juego. Si apuntas la IA al segmento equivocado (intentando que enjambre en todo, o intentando que un enjambre humano maneje el volumen), obtienes lo peor de ambos. Acierta con la división y el modelo finalmente funciona como fue diseñado.
Dónde encaja la IA concretamente en un enjambre
¿Qué hace la IA dentro de esto, concretamente? En los equipos con los que trabajo, el patrón que se mantiene es este: la IA se sitúa al frente de la cola como primer respondiente y una comprobación de confianza decide qué sucede a continuación.
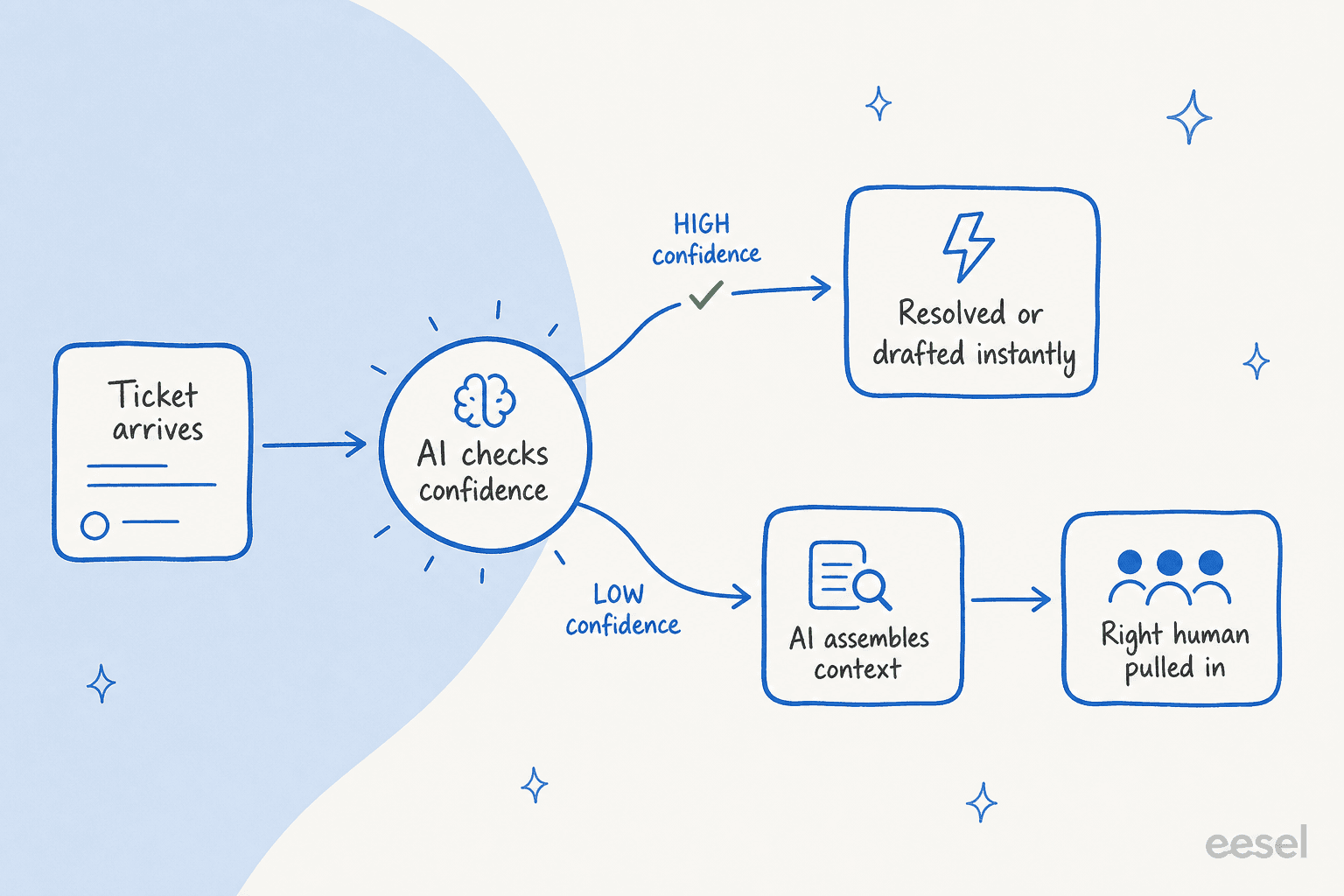
Cuando la IA está segura, resuelve el ticket o redacta una respuesta para que la envíe un agente. Cuando no lo está, no adivina; deja el ticket silenciosamente para un humano, pero no vacío: etiqueta y enruta el ticket, recopila los tickets y documentos relevantes del pasado y deja una respuesta sugerida como nota interna. El humano que lo recoge entra en contexto, no en punto cero.
Ese control de confianza es la decisión de diseño más importante, y es la que más les importa a los compradores. Una vez estuve en una llamada con una directora de CX en una marca que gestionaba 7.000 tickets al mes, y ella formuló el requisito mejor que cualquier briefing de producto. Sus palabras, aproximadamente: "La IA nunca podrá responder el 100% de las preguntas… Necesito una IA que solo gestione los tickets en los que está segura, y todos los demás, que los deje en paz."
Ese es el principio sobre el que está construido eesel. Estableces un umbral de confianza, excluyes los tipos de tickets que aún no estás listo para automatizar y la IA transfiere silenciosamente todo de lo que no está segura. Y porque hemos visto bots que suenan seguros dar respuestas incorrectas, cada implementación se simula primero contra tus tickets históricos para que puedas ver la cobertura y la tasa de error por tipo de ticket antes de que nada salga en vivo, en lugar de descubrirlo en producción. En una prueba real con tráfico en vivo, ese enfoque de simulación primero arrojó un 93% de precisión en el triaje y un 100% de detección de spam antes de que el equipo activara la respuesta automática, que es el tipo de análisis de tickets de soporte que deseas antes de confiar en cualquier automatización.
También existe una versión con visión de futuro de esto que los profesionales ya están imaginando. Como escribió un responsable de TI en LinkedIn:
"Imagina un 'enjambre inteligente' impulsado por IA y aprendizaje automático, anticipando problemas, sugiriendo soluciones e incluso automatizando algunas tareas de remediación."
Las partes del swarming que la IA no resuelve
Ahora la parte honesta, porque aquí es donde la mayoría de las publicaciones de proveedores se callan. El swarming tiene fallos reales y documentados, y la IA soluciona algunos mientras deja otros completamente intactos. Si vas a hacer esto, hazlo con los ojos abiertos.
La transferencia del "teléfono roto". El swarming puede degradarse en teléfono roto cuando el responsable no entiende realmente el problema que está transmitiendo. Un administrador de sistemas en Reddit describió vivirlo como usuario final:
"Una vez que el primer técnico terminó su guión y empezó a involucrar soporte de equipos más técnicos, se convirtió en teléfono roto con un turnaround de 24 horas… Intentar explicárselo tenemos que hacerlo a través del técnico L1 y nuestra explicación se filtra a través de su comprensión."
La IA genuinamente ayuda aquí, capturando el contexto completo del ticket en un solo lugar para que el especialista lea el detalle original en lugar de una paráfrasis de una paráfrasis.
Rechazo de invitación. Esto la IA no lo resuelve por sí sola. Como un operador lo formuló en LinkedIn, "La teoría detrás de Intelligent Swarming es impecable… [pero] en la práctica, veo un punto de fricción significativo: el problema del 'rechazo de invitación'. Cuando invitas a un experto a un enjambre de Slack, le estás pidiendo que rompa su propio enfoque para resolver el rompecabezas de otra persona." Si tus expertos se miden puramente por cerrar sus propios tickets, ninguna IA hará que quieran unirse a tu enjambre. Es un problema de métricas e incentivos.
Costo de coordinación. El Consortium es claro en que "la colaboración lleva tiempo porque se necesita más interacción… entre los colaboradores," que es exactamente por qué no todos los tickets deberían enjambrarse. La IA reduce el número de tickets que necesitan un enjambre, pero un enjambre que se activa sigue costando tiempo humano real.
La propiedad se convierte en juego. Cuando "el equipo lo resuelve" se convierte en "el técnico que lo tomó lo resuelve," la gente se adapta. Un administrador de sistemas advirtió que los usuarios empiezan a jugar con el sistema, intentando eludir tu herramienta de tickets y solicitar técnicos específicos, arruinando silenciosamente tu enrutamiento y métricas. Es un problema de diseño de procesos que la IA puede apoyar (con enrutamiento y etiquetado coherentes) pero no puede resolver por sí sola.
El resumen honesto: la IA es una respuesta fantástica a los problemas de volumen y contexto, y ninguna respuesta a los problemas de cultura e incentivos. Quien te venda el "ticket swarming con IA" como solución para la segunda categoría está exagerando.
Cómo hacer que el ticket swarming con IA funcione de verdad
Si quieres poner esto en práctica sin el caos, esta es la secuencia que seguiría:
- Delimita el enjambre estrechamente. Decide qué tipos de tickets son genuinamente suficientemente complejos como para justificar la colaboración, y protégelos. Todo lo demás debería encaminarse hacia la automatización o el autoservicio, no hacia una reunión.
- Deja que la IA limpie primero el volumen conocido. Conecta un agente de helpdesk con IA a tu sistema de tickets existente y deja que gestione los tickets repetibles. Cuantos menos tickets fáciles haya en la cola, más libre estará la atención de tu equipo para los difíciles.
- Controla todo mediante confianza. Establece el umbral para que la IA solo responda automáticamente cuando esté segura, y enrute silenciosamente el resto. Esta es la diferencia entre una IA que ayuda y una que crea nuevos problemas silenciosamente.
- Convierte a la IA en el tomador de notas del enjambre. Antes de que se involucre un humano, la IA ya debería haber reunido el contexto, localizado los documentos relevantes y redactado un punto de partida como nota interna.
- Simula antes de lanzar. Ejecuta todo contra tus últimos miles de tickets primero, para conocer la cobertura y la precisión por tipo de ticket. Adivinar es cómo terminas con el bot seguro-pero-equivocado que todos temen.
- Arregla los incentivos tú mismo. Asegúrate de que tus expertos sean reconocidos por ayudar en los enjambres, no solo por cerrar su propia cola. Ninguna herramienta hace esto por ti.
La mayor parte de esto trata de acertar con la división, decidir en qué dirección debe fluir cada ticket, y luego hacer que la IA cargue tanto del peso como pueda de forma segura en ambos lados de esa línea.
Prueba eesel para el ticket swarming con IA
Si el modelo anterior te parece correcto, eesel AI está construido para ser el primer miembro siempre activo de tu enjambre. Se conecta a tu helpdesk existente (Zendesk, Freshdesk, Gorgias, HubSpot, Front y más), aprende de tus tickets pasados y documentos de ayuda desde el primer día, y resuelve o redacta los tickets conocidos para que la atención de tu equipo esté libre para los complejos que genuinamente necesitan un humano.
El diferenciador para el swarming específicamente es el despliegue de simulación primero: ejecutas la IA contra miles de tus tickets históricos, ves exactamente qué tipos puede manejar de forma segura y dónde debe transferir, y estableces el umbral de confianza en consecuencia antes de que toque a un cliente en vivo. Un equipo, Gridwise, vio a eesel resolver el 73% de las solicitudes de nivel 1 en el primer mes, resultados que aparecieron durante una prueba de 7 días. Los precios son basados en uso sin tarifas por asiento, por lo que no pagas por las personas que intentas liberar.

Es gratuito de probar, sin tarjeta de crédito, y la simulación se ejecuta en tus propios datos para que puedas ver la división por ti mismo antes de comprometerte.
Preguntas frecuentes
¿Qué es el ticket swarming?
¿Qué es el ticket swarming con IA?
¿En qué se diferencia el ticket swarming del soporte por niveles?
¿El ticket swarming realmente reduce el tiempo de resolución?
¿Puede la IA reemplazar a un enjambre humano?
¿Cómo evito que la IA responda tickets que no debería?
¿Qué necesito antes de implementar el ticket swarming con IA?

Article by
Riellvriany Indriawan
Riell is a designer and writer at eesel AI with about two years of experience researching CX platforms, AI chatbots, and helpdesk software. She combines her design background with a sharp eye for how these tools actually look and feel in practice — making her comparisons unusually visual and user-focused.








