So verwenden Sie die Attributpriorität in Zendesk Explore: Eine vollständige Anleitung
Stevia Putri
Zuletzt bearbeitet February 26, 2026
Nicht alle Support-Daten sind gleich. Der aktuelle Status eines Tickets sagt Ihnen das eine. Die vollständige Historie, wie sich dieses Ticket durch Ihr System bewegt hat, sagt Ihnen etwas ganz anderes. Hier wird das Verständnis von Attributen in Zendesk Explore unerlässlich.
Wenn Sie jemals versucht haben, einen Bericht zu erstellen, der Prioritätsänderungen im Zeitverlauf anzeigt, sind Sie wahrscheinlich auf eine Mauer gestoßen. Das Standard-Tickets-Dataset zeigt nur die aktuelle Priorität an, nicht die von gestern oder letzter Woche. Um zu verfolgen, wie sich Tickets entwickeln, müssen Sie verstehen, welche Attribute Sie wann verwenden müssen.
Dieser Leitfaden erläutert, wie Zendesk Explore-Attribute funktionieren, mit besonderem Fokus auf die Verfolgung von Prioritätsänderungen und die Erstellung berechneter Attribute für eine bessere Berichterstellung. Egal, ob Sie SLA-Verstöße beheben oder die Teamleistung analysieren, diese Techniken helfen Ihnen, mehr aus Ihren Daten herauszuholen.
Tools wie eesel AI können diese Arbeit ergänzen, indem sie die Ticketpriorisierung basierend auf Inhalt und Kontext automatisieren und so den manuellen Aufwand reduzieren, der erforderlich ist, um die Prioritäten genau zu halten.
Was sind Attribute in Zendesk Explore?
Attribute sind die Dimensionen, die Sie zum Gruppieren, Filtern und Organisieren Ihrer Support-Daten verwenden. Stellen Sie sie sich als die Beschriftungen vor, mit denen Sie Ihre Berichte aufschlüsseln können: Ticketstatus, Bearbeitername, Erstellungsdatum, Prioritätsstufe. Ohne Attribute betrachten Sie nur Rohzahlen ohne Kontext.
Attribute unterscheiden sich von Metriken. Metriken sind die Zahlen, die Sie messen: Ticketanzahl, Lösungszeit, Antwortanzahl. Attribute sind, wie Sie diese Zahlen aufschlüsseln. Eine Metrik (Gesamtzahl der Tickets) kann anhand von Dutzenden von Attributen analysiert werden (nach Gruppe, nach Kanal, nach Priorität, nach Monat).
Arten von Attributen in Zendesk Explore
Zendesk organisiert Attribute in drei Kategorien:
-
Standardattribute sind in jedem Dataset integriert. Dazu gehören Standardfelder wie Ticket-ID, Status, Priorität und Bearbeiter. Sie sind sofort einsatzbereit.
-
Benutzerdefinierte Attribute sind Felder, die Sie in Ihrer Zendesk-Instanz erstellt haben. Wenn Sie benutzerdefinierte Ticketfelder hinzugefügt haben, werden diese als Attribute in den relevanten Datasets angezeigt.
-
Berechnete Attribute sind Formeln, die Sie mit der Berechnungs-Sprache von Zendesk erstellen. Mit diesen können Sie vorhandene Attribute kombinieren, transformieren oder in neue Dimensionen kategorisieren.
Jedes Dataset in Zendesk Explore enthält einen eigenen Satz von Attributen. Das Tickets-Dataset enthält Attribute, die sich auf Ticket-Eigenschaften beziehen. Das Updates-Verlaufs-Dataset enthält Attribute über Änderungen, die an Tickets vorgenommen wurden. Die Wahl des richtigen Datasets ist der erste Schritt, um die Antworten zu erhalten, die Sie benötigen.
Das Prioritätsattribut in Zendesk verstehen
Priorität in Zendesk ist ein Systemfeld mit vier Stufen: Niedrig, Normal, Hoch und Dringend. Es wirkt sich darauf aus, wie Tickets weitergeleitet werden, welche SLAs gelten und wie Ihr Team die Arbeit priorisiert. Im Gegensatz zu benutzerdefinierten Feldern können Sie das Prioritätsfeld nicht löschen, obwohl Sie anpassen können, wie es sich verhält.
Die Herausforderung bei der Prioritätsberichterstellung besteht darin, dass die meisten Datasets nur den aktuellen Wert anzeigen. Wenn ein Ticket gestern als Dringend markiert wurde, heute aber Normal ist, zeigt ein Standardbericht nur Normal an. Dies führt zu blinden Flecken, wenn Sie versuchen, Eskalationsmuster oder die Einhaltung von SLAs zu analysieren.
Wie sich die Priorität auf Ihre Berichterstellung auswirkt
Die Priorität steuert mehrere wichtige Workflows in Zendesk:
-
SLA-Richtlinien haben in der Regel unterschiedliche Ziele basierend auf der Priorität. Dringende Tickets benötigen möglicherweise eine erste Antwort in 15 Minuten, während Tickets mit niedriger Priorität 24 Stunden erhalten.
-
Routing-Regeln verwenden häufig die Priorität, um zu bestimmen, welche Gruppe oder welcher Agent ein Ticket erhält. Probleme mit hoher Priorität überspringen möglicherweise Tier eins und gehen direkt an Spezialisten.
-
Dashboard-Filterung ermöglicht es Managern, sich während Standups oder der Reaktion auf Vorfälle auf dringende Probleme zu konzentrieren.
Wenn sich die Priorität ändert, passen sich diese Workflows automatisch an. Die historische Verfolgung dieser Änderungen erfordert jedoch das richtige Dataset und die richtigen Attribute.
Das Updates-Verlaufs-Dataset verwenden, um Prioritätsänderungen zu verfolgen
Das Updates-Verlaufs-Dataset ist der einzige Ort in Zendesk Explore, an dem Feldänderungen im Zeitverlauf verfolgt werden. Während das Tickets-Dataset Ihnen eine Momentaufnahme der aktuellen Werte gibt, erfasst das Updates-Verlaufs-Dataset jede Änderung: wer sie vorgenommen hat, wann sie vorgenommen wurde und was sich geändert hat.
Dieses Dataset ist unerlässlich, um Fragen wie diese zu beantworten:
- Bei wie vielen Tickets wurde die Priorität im letzten Monat herabgestuft?
- Welche Agenten eskalieren Tickets am häufigsten?
- Wie lange bleiben Tickets vor der Lösung auf der Priorität Dringend?
Schlüsselattribute zum Verfolgen der Priorität
Um einen Bericht über Prioritätsänderungen zu erstellen, arbeiten Sie mit diesen Attributen:
-
Änderungen - Feldname identifiziert, welches Feld geändert wurde. Filtern Sie dies nach "Priorität", um nur Prioritätsänderungen anzuzeigen.
-
Änderungen - Vorheriger Wert zeigt, welche Priorität vor der Änderung hatte.
-
Änderungen - Neuer Wert zeigt, welche Priorität nach der Änderung hatte.
-
Update - Zeitstempel sagt Ihnen genau, wann die Änderung stattgefunden hat.
-
Updater-Name identifiziert, wer die Änderung vorgenommen hat.
Erstellen Ihres ersten Berichts über Prioritätsänderungen
So erstellen Sie einen Bericht, der Prioritätsänderungen anzeigt:
- Öffnen Sie Zendesk Explore und erstellen Sie eine neue Abfrage
- Wählen Sie das Support: Updates-Verlauf-Dataset aus
- Fügen Sie einen Filter für Änderungen - Feldname = "Priorität" hinzu
- Fügen Sie im Abschnitt Zeilen hinzu: Ticket-ID, Änderungen - Vorheriger Wert, Änderungen - Neuer Wert, Update - Datum, Updater-Name
- Fügen Sie Update-ID als Ihre Metrik mit D_COUNT-Aggregation hinzu
Dies gibt Ihnen eine Liste aller Prioritätsänderungen mit vollständigem Kontext. Sie können zusätzliche Filter für Datumsbereiche, bestimmte Gruppen oder Updater-Rollen hinzufügen, um den Fokus einzugrenzen.
Spezielles Verfolgen von Prioritätsherabstufungen
Ein häufiger Anwendungsfall ist die Identifizierung von Tickets, deren Priorität reduziert wurde. Dies kann auf Umfangänderungen, SLA-Manipulationen oder einfach auf Tickets hinweisen, die anfänglich überpriorisiert wurden.
Um Herabstufungen zu verfolgen, erstellen Sie eine standardmäßige berechnete Metrik mit dieser Formel:
IF ([Änderungen - Feldname] = "Priorität"
AND [Änderungen - Vorheriger Wert] != NULL
AND [Änderungen - Neuer Wert] != NULL
AND [Änderungen - Vorheriger Wert] != [Änderungen - Neuer Wert]
AND (
([Änderungen - Vorheriger Wert] = "dringend" AND [Änderungen - Neuer Wert] = "hoch") OR
([Änderungen - Vorheriger Wert] = "hoch" AND [Änderungen - Neuer Wert] = "normal") OR
([Änderungen - Vorheriger Wert] = "normal" AND [Änderungen - Neuer Wert] = "niedrig")
)
)
THEN [Update-ID]
ENDIF
Diese Formel erfasst nur echte Herabstufungen, wobei Prioritätserhöhungen oder unveränderte Werte ausgeschlossen werden. Sie können die Logik an Ihre spezifischen Berichtsanforderungen anpassen.
Erstellen berechneter Attribute für erweiterte Berichterstellung
Mit berechneten Attributen können Sie benutzerdefinierte Dimensionen erstellen, die standardmäßig nicht in Ihren Daten vorhanden sind. Mithilfe der Formelsprache von Zendesk können Sie Felder kombinieren, bedingte Logik anwenden und Werte in Formate transformieren, die für Ihr Unternehmen sinnvoll sind.
Wann berechnete Attribute verwendet werden sollten
Erwägen Sie die Erstellung eines berechneten Attributs, wenn Sie Folgendes benötigen:
- Kombinieren Sie mehrere Felder zu einem (wie das Verknüpfen von Kategorie und Unterkategorie)
- Erstellen Sie Buckets oder Gruppierungen (wie "Geschäftszeiten" vs. "Nach Geschäftsschluss")
- Standardisieren Sie inkonsistente Werte (wie das Normalisieren von E-Mail-Domänen)
- Extrahieren Sie Teile von Textfeldern (wie das Abrufen der Domäne aus einer E-Mail-Adresse)
Attribute zusammenführen
Eine der häufigsten Verwendungen für berechnete Attribute ist das Zusammenführen von zwei Feldern. Dies ist nützlich, wenn Sie nach Kombinationen filtern möchten, die nicht als einzelne Attribute verfügbar sind.
So erstellen Sie ein Jahr-Monat-Attribut für eine bessere Datums-Gruppierung:
STRING([Ticket erstellt - Jahr])+" "+[Ticket erstellt - Monat]
So kombinieren Sie Gruppe und Bearbeiter für eine teamspezifische Filterung:
[Ticketgruppe]+" - "+[Bearbeitername]
So führen Sie Kategorie- und Unterkategoriefelder zusammen:
[Kategorie]+" - "+[Unterkategorie]
Beachten Sie, dass, wenn eine Komponente eines zusammengeführten Attributs NULL enthält, das gesamte Ergebnis NULL ist. Möglicherweise müssen Sie eine Fehlerbehandlung für unvollständige Daten hinzufügen.
Bedingte Attribute
Mit bedingter Logik können Sie Attribute erstellen, die Tickets basierend auf mehreren Kriterien kategorisieren. Dies ist leistungsstark für die Erstellung unternehmensspezifischer Gruppierungen.
So kennzeichnen Sie Tickets, die während der Geschäftszeiten erstellt wurden (vorausgesetzt 9:00 bis 17:00 Uhr):
IF ([Ticket erstellt - Stunde] >= 9 AND [Ticket erstellt - Stunde] <= 17)
THEN "Geschäftszeiten"
ELSE "Nach Geschäftsschluss"
ENDIF
So erstellen Sie Prioritäts-Buckets für eine vereinfachte Berichterstellung:
IF ([Ticketpriorität] = "Dringend" OR [Ticketpriorität] = "Hoch")
THEN "Kritisch"
ELSE "Standard"
ENDIF
So identifizieren Sie Tickets mit mehreren Neuzuweisungen:
IF (VALUE(Bearbeiterstationen) > 2)
THEN "High Touch"
ELIF (VALUE(Bearbeiterstationen) = 2)
THEN "Medium Touch"
ELSE "Low Touch"
ENDIF
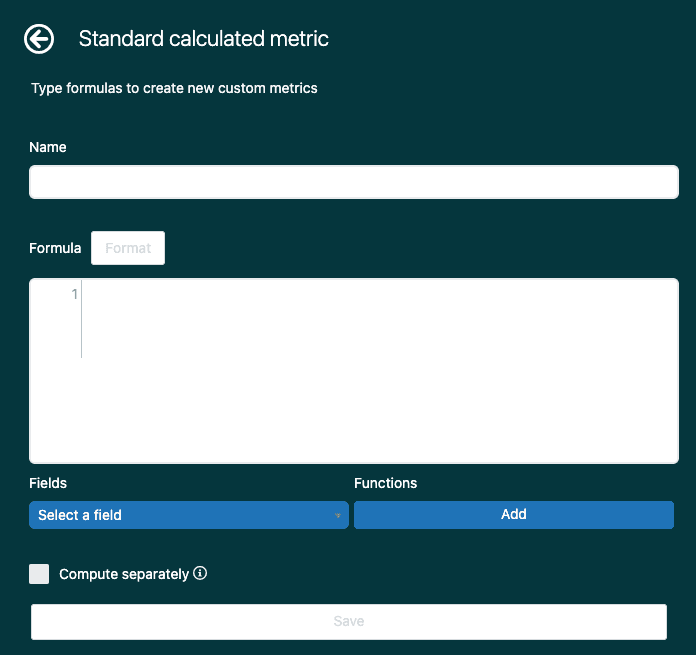
Häufige Herausforderungen bei der attributbezogenen Berichterstellung
Auch mit den richtigen Attributen werden Sie auf Probleme stoßen. Hier sind die häufigsten Probleme und wie Sie sie lösen können.
NULL-Werte verarbeiten
NULL-Werte unterbrechen Verknüpfungen und Berechnungen. Berücksichtigen Sie beim Kombinieren von Attributen immer fehlende Daten:
IF ([Kategorie] != NULL AND [Unterkategorie] != NULL)
THEN [Kategorie]+" - "+[Unterkategorie]
ELIF ([Kategorie] != NULL)
THEN [Kategorie]+" - Unspezifiziert"
ELSE "Nicht kategorisiert"
ENDIF
Dadurch wird sichergestellt, dass Ihre Berichte aussagekräftige Werte anstelle von leeren Zellen anzeigen.
Attribute werden nicht im erwarteten Dataset angezeigt
Wenn Sie ein Attribut nicht finden können, überprüfen Sie, welches Dataset Sie verwenden. Benutzerdefinierte Felder werden nur in Datasets für das Produkt angezeigt, in dem sie erstellt wurden. Ein benutzerdefiniertes Ticketfeld wird beispielsweise nicht im Talk-Dataset angezeigt.
Das Updates-Verlaufs-Dataset hat einen anderen Satz von Attributen als das Tickets-Dataset. Felder wie "Änderungen - Vorheriger Wert" sind nur im Updates-Verlauf vorhanden.
Sortierprobleme mit verknüpften Attributen
Verknüpfte Textattribute werden alphabetisch und nicht chronologisch sortiert. Wenn Sie Jahr und Monat verknüpfen, wird "2025 Januar" vor "2025 Februar" sortiert, aber "2025 Dezember" wird vor "2025 Januar" sortiert, da "D" vor "J" kommt.
Um Datumsangaben korrekt zu sortieren, verwenden Sie die numerische Formatierung:
STRING([Ticket erstellt - Jahr])+"-"+DATE_FORMAT([Ticket erstellt - Datum],"MM")
Dies erzeugt "2025-01", "2025-02" usw., die in der richtigen Reihenfolge sortiert werden.
Leistungsüberlegungen
Komplexe berechnete Attribute können das Laden von Berichten verlangsamen. Wenn Ihre Berichte eine Zeitüberschreitung verursachen:
- Vereinfachen Sie Formeln, indem Sie unnötige Bedingungen entfernen
- Berechnen Sie Werte nach Möglichkeit in benutzerdefinierten Feldern vor
- Filtern Sie Ihr Dataset frühzeitig, um die Anzahl der zu verarbeitenden Zeilen zu reduzieren
- Teilen Sie komplexe Berichte in mehrere einfachere Abfragen auf
Mehr aus Ihrer Zendesk-Berichterstellung herausholen
Native Zendesk Explore hat Grenzen. Komplexe Analysen erfordern oft den Export von Daten in externe Tools. Bevor Sie diesen Punkt erreichen, stellen Sie sicher, dass Sie Explore voll ausschöpfen.
Beginnen Sie mit diesen Praktiken:
- Dokumentieren Sie Ihre berechneten Attribute, damit Ihr Team versteht, was sie messen
- Erstellen Sie einen freigegebenen Ordner mit Standardberichten für häufige Fragen
- Planen Sie die Zustellung von Dashboards, um Stakeholder ohne manuelle Arbeit auf dem Laufenden zu halten
- Verwenden Sie die Drill-In-Funktionalität, um Anomalien direkt von Dashboards aus zu untersuchen
Wenn Sie an die Grenzen von Explore stoßen, überlegen Sie, ob die Analyse wirklich externe Tools erfordert. Manchmal löst ein besser berechnetes Attribut oder eine andere Dataset-Auswahl das Problem, ohne die Komplexität zu erhöhen.
Wie KI bei der Priorisierung helfen kann
Während sich dieser Leitfaden auf die Berichterstellung konzentriert, ist die Ursache vieler prioritätsbezogener Herausforderungen bei der Berichterstellung eine inkonsistente Priorisierung. Wenn Agenten Prioritätsstufen unterschiedlich anwenden, werden Ihre Berichte weniger aussagekräftig.
Hier können KI-Tools helfen. eesel AI lernt aus Ihren vergangenen Tickets, um Prioritäten basierend auf Inhalt und Kundenkontext vorzuschlagen oder automatisch festzulegen. Durch die Standardisierung der Priorisierung zum Zeitpunkt der Ticketerstellung reduzieren Sie das Rauschen in Ihrer nachgelagerten Berichterstellung.
Unser KI-Triage-Produkt kann auch helfen, indem es Tickets automatisch basierend auf dem Inhalt kennzeichnet und weiterleitet, um sicherzustellen, dass Probleme mit hoher Priorität sofort das richtige Team erreichen.
Nächste Schritte für eine bessere Berichterstellung
Fangen Sie klein an. Wählen Sie ein berechnetes Attribut aus, das Ihrem Team helfen würde, und erstellen Sie es. Testen Sie es anhand historischer Daten, um zu überprüfen, ob es die erwarteten Ergebnisse liefert. Sobald Sie zuversichtlich sind, fügen Sie es Ihren Standard-Dashboards hinzu.
Im Laufe der Zeit werden Sie eine Bibliothek mit benutzerdefinierten Attributen und Metriken erstellen, die auf Ihr Unternehmen zugeschnitten sind. Dieses institutionelle Wissen macht Ihre Berichterstellung wertvoller und hilft neuen Teammitgliedern zu verstehen, wie Ihre Support-Operation funktioniert.
Wenn Sie über die Berichterstellung hinausgehen und tatsächlich verbessern möchten, wie Tickets bearbeitet werden, überlegen Sie, wie KI die Fähigkeiten Ihres Teams erweitern kann. Wir integrieren uns direkt in Zendesk, um Teams bei der Automatisierung routinemäßiger Arbeiten zu unterstützen und sich auf das Wesentliche zu konzentrieren.
Häufig gestellte Fragen
Share this article

Article by
Stevia Putri
Stevia Putri is a marketing generalist at eesel AI, where she helps turn powerful AI tools into stories that resonate. She’s driven by curiosity, clarity, and the human side of technology.


