
Sie haben also eine Support-KI eingeführt. Das ist ein großer Schritt. Aber jetzt fragen Sie sich wahrscheinlich, was sie wirklich leistet. Wenn ein Kunde eine langsame oder schlichtweg falsche Antwort erhält, kann die Ursachenforschung wie die Suche nach der Nadel im Heuhaufen sein. Hat das Sprachmodell einen schlechten Tag, liegt es an einem trägen API-Aufruf oder an einer Lücke in Ihrer Wissensdatenbank? Ohne eine Möglichkeit, hineinzuschauen, ist Ihre Support-KI nur eine Blackbox.
Genau hier kommt die Observability (Beobachtbarkeit) ins Spiel. Mit einem Open-Source-Standard namens OpenTelemetry können Sie jede Bewegung Ihrer KI verfolgen, von dem Moment, in dem sie ein Ticket aufnimmt, bis sie eine Antwort versendet. Dieser Leitfaden führt Sie durch den manuellen Prozess der Einrichtung von Logging und Tracing für eine Support-KI mit OpenTelemetry. Wir werden die Hauptkonzepte und die praktischen Schritte für den Einstieg behandeln.
Ehrlich gesagt erfordert dieser Prozess einiges an technischem Aufwand, aber er ist unerlässlich, um eine KI zu entwickeln, auf die Sie sich verlassen können. Wenn Sie sich die manuelle Arbeit lieber sparen möchten, übernehmen Plattformen wie eesel AI diese Komplexität für Sie, sodass Sie sich auf Ihr Kundenerlebnis statt auf Ihre Telemetrie-Pipelines konzentrieren können.
Was Sie für eine manuelle Einrichtung benötigen
Bevor wir uns mit der Vorgehensweise befassen, lassen Sie uns darüber sprechen, was eine manuelle Einrichtung eigentlich beinhaltet. Dieser Weg gibt Ihnen die volle Kontrolle, erfordert aber auch einige dedizierte Ressourcen.
Hier ist eine kurze Übersicht dessen, was Sie benötigen werden:
-
Eine Entwicklungsumgebung: Wahrscheinlich werden Sie in Python arbeiten, da es eine beliebte Wahl für KI-Anwendungen ist.
-
OpenTelemetry SDKs und Bibliotheken: Sie müssen diese Pakete installieren, damit Ihr Code aufzeichnen kann, was er tut.
-
Ein Observability-Backend: Dies ist ein Werkzeug, an das Sie all Ihre Daten senden, um sie zu visualisieren und zu analysieren. Denken Sie an Tools wie Jaeger (das Open-Source ist) oder Datadog.
-
Entwicklerzeit: Dies ist keine einmalige Aufgabe. Es erfordert echten Ingenieursaufwand, die gesammelten Daten zu implementieren, zu warten und tatsächlich zu verstehen.
Dieser technische Mehraufwand ist ein Hauptgrund, warum sich viele Teams einfach für eine verwaltete Plattform entscheiden. Ein Tool wie eesel AI verbindet sich in wenigen Minuten direkt mit Ihrem Helpdesk, egal ob es sich um Zendesk oder Freshdesk handelt. Es liefert Ihnen umfassende, auf den Support ausgerichtete Einblicke, ohne dass Sie eine einzige Zeile Code schreiben müssen.
Eine Schritt-für-Schritt-Anleitung
Gut, lassen Sie uns ins Detail gehen und Ihre Support-KI instrumentieren. Das Hauptziel hier ist es, eine detaillierte Aufzeichnung, einen sogenannten „Trace“, zu erstellen, der eine einzelne Kundenanfrage vom Anfang bis zum Ende verfolgt.
Schritt 1: Die Umgebung einrichten
Zuerst müssen Sie das grundlegende OpenTelemetry-Framework in Ihrer Anwendung konfigurieren. Das bedeutet, drei Hauptkomponenten einzurichten:
-
Ein Tracer Provider: Dies ist im Wesentlichen die Fabrik, die „Tracer“ in Ihrer App erstellt. Stellen Sie ihn sich als den Hauptmotor vor, der Ihre gesamte Datenerfassung antreibt.
-
Ein Exporter: Dieser Teil ist dafür verantwortlich, Ihre Daten an Ihr Observability-Backend zu senden. Er ist die Pipeline, die Informationen von Ihrer App an einen Ort transportiert, an dem Sie sie tatsächlich ansehen können.
-
Ein Span Processor: Diese Komponente verwaltet den Lebenszyklus Ihrer „Spans“ (die einzelnen Schritte in einem Trace) und übergibt sie an den Exporter. Sie stellt sicher, dass jedes Datenelement korrekt behandelt wird.
Im Grunde initialisiert Ihr Code diese Komponenten, sodass Ihre Anwendung immer bereit ist, Telemetriedaten zu erfassen und zu versenden. Sie können auch einen OpenTelemetry Collector einrichten, einen separaten Dienst, der Daten sammelt, verarbeitet und exportiert. Dies kann Ihren Anwendungscode etwas sauberer machen, indem er einen Teil der Datenverarbeitung übernimmt.
Schritt 2: Den Workflow instrumentieren
Sobald Ihre Umgebung bereit ist, ist es an der Zeit, Tracing zu der Logik Ihrer KI hinzuzufügen. Ein Trace repräsentiert die gesamte Reise eines Support-Tickets, und ein Span repräsentiert einen einzelnen Schritt innerhalb dieser Reise. Stellen Sie es sich wie eine Zeitleiste mit spezifischen, beschrifteten Ereignissen vor.
Folgen wir zum Beispiel einer klassischen Supportanfrage: „Wie ist der Status meiner Bestellung?“
Ihre KI könnte einige Schritte durchlaufen, um dies zu beantworten:
-
Das eingehende Ticket empfangen und verstehen.
-
Die Absicht des Benutzers als „Bestellstatusanfrage“ identifizieren.
-
Eine interne API aufrufen, um die Bestelldetails abzurufen.
-
Ein Large Language Model (LLM) verwenden, um eine freundliche, menschlich klingende Antwort zu schreiben.
-
Das Ticket mit der Antwort aktualisieren und schließen.
Jede dieser Aktionen sollte in einem eigenen Span gekapselt werden. Dies schafft eine klare Eltern-Kind-Struktur, die es Ihnen ermöglicht, den gesamten Workflow zu visualisieren und genau zu sehen, wie lange jeder Schritt gedauert hat. Indem Sie den Prozess auf diese Weise aufschlüsseln, können Sie sofort erkennen, wo es zu Verlangsamungen oder Fehlern kommt.
Schritt 3: Attribute und Metriken erfassen
Nur das Tracing des Workflows ist ein guter Anfang, aber es reicht nicht aus. Um echten Mehrwert zu erzielen, müssen Sie Ihren Spans Kontext mit Daten hinzufügen, die als Attribute bekannt sind. Glücklicherweise gibt es einige neue semantische Konventionen für GenAI von OpenTelemetry, die Ihnen eine standardisierte Methode zur Benennung dieser Dinge bieten. Für eine Support-KI möchten Sie sowohl technische Details als auch geschäftsrelevante Informationen erfassen.
Hier sind einige Schlüsselattribute, die Sie erfassen sollten:
-
Modellparameter: „llm.model.name“, „llm.temperature“
-
Token-Nutzung: „llm.usage.prompt_tokens“, „llm.usage.completion_tokens“ (dies ist enorm wichtig, um die Kosten im Auge zu behalten)
-
Tool-Aufrufe: „tool.name“, „tool.input“, „tool.output“
-
Geschäftskontext: „customer.id“, „ticket.id“, „ticket.tags“
Wenn Sie diese Art von Daten erfassen, können Sie von der reinen Leistungsüberwachung zur Beantwortung wichtiger Geschäftsfragen übergehen. Anstatt nur zu wissen, ob eine Antwort langsam war, können Sie verstehen, warum sie langsam war und was das für Ihre Kunden bedeutet.
| Technisches Attribut | Geschäftsfrage, die es beantwortet |
|---|---|
| „llm.usage.total_tokens“ | Wie viel geben wir im Durchschnitt aus, um ein Ticket zu lösen? |
| „tool.call.duration“ | Sind unsere eigenen internen APIs der Grund für langsame Support-Antworten? |
| „response.success“ (benutzerdefiniert) | Wie oft löst die KI tatsächlich Probleme, anstatt sie nur zu eskalieren? |
| „knowledge.source.used“ (benutzerdefiniert) | Welche unserer Hilfeartikel sind wirklich nützlich und welche nicht? |
Schritt 4: Tracing-Daten zur Verbesserung Ihrer KI nutzen
Sobald Ihre Daten in Ihr Observability-Tool fließen, können Sie damit beginnen, Probleme zu diagnostizieren und Verbesserungsmöglichkeiten zu finden. Hier zahlt sich die Einrichtung wirklich aus.
-
Debugging langsamer Antworten: Ein langer Trace macht deutlich, welcher Span der Engpass ist. Wenn der Span „tool.call:lookup_order“ fünf Sekunden dauert, wissen Sie, dass das Problem nicht das LLM ist, sondern Ihr internes Bestellsystem. Jetzt wissen Sie genau, worauf Sie Ihre Bemühungen konzentrieren müssen.
-
Untersuchung falscher Antworten: Durch einen Blick auf die Attribute „llm.prompt“ und „llm.completion“ können Sie genau sehen, welche Informationen die KI erhalten hat und was sie daraus gemacht hat. Sie könnten feststellen, dass der Kontext, den sie aus Ihrer Wissensdatenbank gezogen hat, veraltet war, was sie zum „Halluzinieren“ veranlasste. Dies ermöglicht es Ihnen, die Ursache zu beheben, anstatt nur die Symptome zu bekämpfen.
-
Finden von Wissenslücken: Wenn Sie jedes Mal protokollieren, wenn die KI keine Antwort finden kann, können Sie Trends ziemlich schnell erkennen. Eine Häufung von Protokollen im Zusammenhang mit „Wie erhalte ich eine Rückerstattung“ ist ein klares Signal dafür, dass Sie Ihre Dokumentation zu diesem Thema schreiben oder verbessern müssen. Ihre Support-KI wird zu einem Werkzeug, das Ihnen proaktiv hilft, Ihre Self-Service-Ressourcen zu verbessern.

Profi-Tipps und häufige Fehler, die Sie vermeiden sollten
Die Einrichtung von Logging und Tracing für eine Support-KI mit OpenTelemetry kann etwas knifflig sein. Hier sind ein paar Tipps, die Ihnen helfen, und einige häufige Fallstricke, auf die Sie achten sollten.
-
Häufiger Fehler Nr. 1: Nur die Latenz verfolgen. Es ist leicht, sich zu sehr auf die Geschwindigkeit zu konzentrieren, aber Genauigkeit und Effektivität sind das, was wirklich zählt. Erstellen Sie benutzerdefinierte Attribute, um Dinge wie den Lösungserfolg, Eskalationsraten und sogar Kundenzufriedenheitswerte im Zusammenhang mit KI-Interaktionen zu verfolgen. Das Ziel ist besserer Support, nicht nur schnellere Antworten.
-
Häufiger Fehler Nr. 2: Die Komplexität unterschätzen. Eine manuelle OpenTelemetry-Einrichtung ist nichts, was man einmal einrichtet und dann vergisst. Sie erfordert regelmäßige Wartung, während Ihre KI-Anwendung wächst und sich verändert. Die eigentliche Arbeit besteht nicht nur darin, die Daten zu sammeln, sondern auch darin, die Dashboards und Warnungen zu erstellen, die diese Daten in etwas umwandeln, auf das Sie tatsächlich reagieren können.
Hier bietet eine verwaltete Plattform einen enormen Mehrwert. Lösungen wie eesel AI sind bereits so konfiguriert, dass sie die wichtigsten supportspezifischen Daten erfassen. Anstatt Dashboards von Grund auf neu zu erstellen, erhalten Sie Berichte, die automatisch auf Wissenslücken hinweisen und Ihnen die besten Automatisierungsmöglichkeiten aufzeigen.
Von komplexen Daten zu klaren Einblicken
Die Implementierung von OpenTelemetry ist eine großartige Möglichkeit, die Blackbox Ihrer Support-KI zu öffnen. Es ermöglicht Ihnen, jede Anfrage zu verfolgen, die Leistung zu messen, die Kosten unter Kontrolle zu halten und letztendlich ein System zu schaffen, das zuverlässiger und effektiver ist. Aber wie wir besprochen haben, ist es eine ernsthafte Investition in Ingenieurszeit und laufende Wartung, alles selbst zu machen.
Erhalten Sie KI-Observability sofort einsatzbereit mit eesel AI
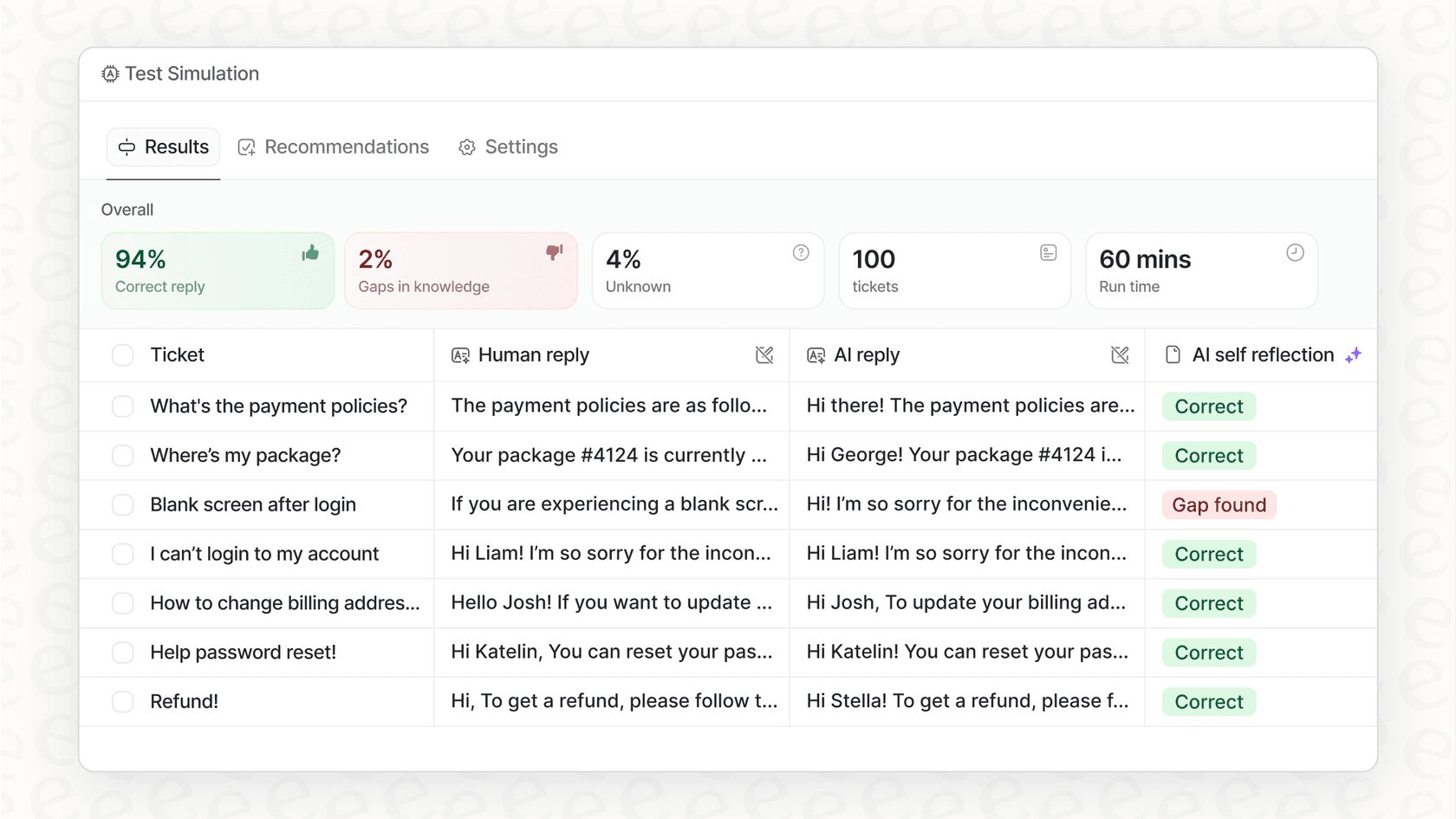
Wenn Sie alle Vorteile einer tiefen KI-Observability ohne den Aufwand wollen, wurde eesel AI für Sie entwickelt. Unsere Plattform verfügt über integriertes, umfassendes Logging und Tracing, das speziell für Kundensupport-Teams entwickelt wurde. Sie können die Leistung bei historischen Tickets simulieren, um Ihren potenziellen ROI zu sehen, handlungsorientierte Berichte über Wissenslücken erhalten und in Minuten statt Monaten live gehen.
Bereit zu sehen, wozu Ihre Support-KI wirklich fähig ist? Starten Sie noch heute Ihre kostenlose Testversion.
Häufig gestellte Fragen
Es [verwandelt Ihre Support-KI von einer Blackbox](https://devops.com/next-generation-observability-combining-opentelemetry-and-ai-for-proactive-incident-management/) in ein transparentes System, das es Ihnen ermöglicht, ihre Aktionen zu verstehen. Diese Transparenz ist entscheidend für die Fehlersuche, die Identifizierung von Engpässen und die Gewährleistung einer zuverlässigen Leistung und Kosteneffizienz.
Sie benötigen hauptsächlich einen Tracer Provider, um Tracer zu erstellen, einen Exporter, um Daten an Ihr Observability-Backend zu senden, und einen Span Processor, um die Lebenszyklen der Spans zu verwalten. Ein optionaler OpenTelemetry Collector kann die Datenverarbeitung zusätzlich optimieren.
Über grundlegende Workflow-Traces hinaus sollten Sie Attribute wie LLM-Modellparameter, Token-Nutzung, Tool-Aufrufe und Geschäftskontext (z. B. Kunden-ID, Ticket-Tags) erfassen. Diese liefern entscheidenden Kontext für eine tiefere Analyse und ein besseres Verständnis.
Es ermöglicht Ihnen, [langsame Antworten durch die Identifizierung von Engpässen zu debuggen](https://learn.microsoft.com/en-us/azure/ai-foundry/how-to/develop/trace-agents-sdk), falsche Antworten durch die Überprüfung von Prompts und Vervollständigungen zu untersuchen und Wissenslücken durch das Tracking erfolgloser KI-Interaktionen zu erkennen. Diese Daten ermöglichen gezielte, datengesteuerte Verbesserungen.
Eine manuelle Einrichtung erfordert erheblichen Entwickleraufwand für die erstmalige Implementierung, die laufende Wartung und die Erstellung benutzerdefinierter Dashboards für die Analyse. Sie gibt Ihnen die volle Kontrolle, erfordert aber einen engagierten und nachhaltigen Ingenieursaufwand.
Ja, verwaltete Plattformen wie eesel AI bieten integrierte Observability, die speziell für Support-KI entwickelt wurde. Sie kümmern sich um die zugrunde liegende Komplexität und liefern sofort einsatzbereite Einblicke und Berichte, ohne dass eine manuelle Einrichtung oder benutzerdefinierter Code erforderlich ist.
Share this article

Article by
Stevia Putri
Stevia Putri is a marketing generalist at eesel AI, where she helps turn powerful AI tools into stories that resonate. She’s driven by curiosity, clarity, and the human side of technology.