
さて、サポートAIを導入しましたね。これは大きな一歩です。しかし今、あなたはそのAIが本当は何をしているのか気になっていることでしょう。顧客からの返答が遅かったり、まったく見当違いだったりした場合、その原因を突き止めるのは干し草の山から針を探すようなものです。言語モデルの調子が悪かったのか、APIコールが遅かったのか、それともナレッジベースに死角があったのか?内部を覗き見る方法がなければ、あなたのサポートAIはただのブラックボックスです。
ここで役立つのがオブザーバビリティ(可観測性)です。OpenTelemetryというオープンソース標準を使えば、AIがチケットを受け取ってから返信するまで、そのすべての動きを追跡できます。このガイドでは、OpenTelemetryを使ってサポートAIのロギングとトレーシングを手動で設定するプロセスを解説します。主要な概念と、実践的な導入手順をご紹介します。
正直に言うと、このプロセスにはある程度の技術的な労力が必要ですが、信頼できるAIを構築するためには不可欠です。もちろん、手作業を避けたいのであれば、eesel AIのようなプラットフォームがこの複雑な作業をすべて代行してくれるので、テレメトリパイプラインではなく、顧客体験の向上に集中できます。
手動セットアップに必要なもの
具体的な方法に入る前に、手動セットアップが実際に何を伴うのかについて話しましょう。この方法では完全なコントロールが可能になりますが、専門のリソースが必要になります。
必要なものの概要は以下の通りです。
-
開発環境: AIアプリで人気の高いPythonで作業することになるでしょう。
-
OpenTelemetry SDKとライブラリ: コードの動作を記録し始めるために、これらのパッケージをインストールする必要があります。
-
オブザーバビリティバックエンド: すべてのデータを送信し、可視化・分析するためのツールです。Jaeger(オープンソース)やDatadogのようなツールを想像してください。
-
開発者の時間: これは一度やれば終わりというタスクではありません。実装、保守、そして収集したデータを実際に理解するためには、本格的なエンジニアリングの労力が必要です。
その技術的なオーバーヘッドが、多くのチームがマネージドプラットフォームを選択する大きな理由です。eesel AIのようなツールは、ZendeskやFreshdeskなどのヘルプデスクに数分で直接連携できます。一行もコードを書くことなく、サポートに特化した豊富なインサイトを得ることができます。
ステップバイステップガイド
それでは、サポートAIを計測する具体的な手順に入りましょう。ここでの主な目標は、「トレース」と呼ばれる詳細な記録を作成し、単一の顧客リクエストを最初から最後まで追跡することです。
ステップ1:環境をセットアップする
まず最初に、アプリケーション内に基本的なOpenTelemetryフレームワークを設定する必要があります。これには、主に3つのコンポーネントのセットアップが含まれます。
-
Tracer Provider: これは、アプリ内で「トレーサー」を作成する工場のようなものです。すべてのデータ収集を動かすメインエンジンと考えてください。
-
Exporter: この部分は、データをオブザーバビリティバックエンドに送信する役割を担います。アプリから情報を実際に確認できる場所へ移動させるパイプラインです。
-
Span Processor: このコンポーネントは、「スパン」(トレース内の個々のステップ)のライフサイクルを管理し、エクスポーターに渡します。これにより、すべてのデータが正しく処理されることが保証されます。
基本的に、これらのコンポーネントを初期化するコードを記述することで、アプリケーションが常にテレメトリデータをキャプチャして送信できる状態になります。また、データを収集、処理、エクスポートする別のサービスであるOpenTelemetry Collectorをセットアップすることもできます。これにより、アプリケーションコードからデータ処理の作業の一部を分離し、コードを少しクリーンに保つことができます。
ステップ2:ワークフローを計測する
環境が整ったら、AIのロジックにトレーシングを追加していきます。トレースは1つのサポートチケットの全行程を表し、スパンはその行程内の単一のステップを表します。特定のラベルが付いたイベントを持つタイムラインとして想像してください。
例えば、「注文の状況はどうなっていますか?」という典型的なサポートリクエストを追ってみましょう。
AIはこれに答えるために、いくつかのステップを踏むかもしれません。
-
受信したチケットを受け取り、内容を理解する。
-
ユーザーの意図が「注文状況の問い合わせ」であると判断する。
-
内部APIを呼び出して注文詳細を取得する。
-
大規模言語モデル(LLM)を使用して、フレンドリーで人間らしい返信を作成する。
-
回答をチケットに更新し、クローズする。
これらの各アクションは、それぞれ独自のスパンでラップされるべきです。これにより、明確な親子構造が作成され、ワークフロー全体を視覚化し、各ステップにかかった時間を正確に確認できます。このようにプロセスを分解することで、どこで処理が遅くなっているか、または失敗しているかを即座に特定できます。
ステップ3:属性とメトリクスをキャプチャする
ワークフローをトレースするだけでは良い出発点ですが、それだけでは不十分です。真の価値を得るには、属性として知られるデータでスパンにコンテキストを追加する必要があります。幸いなことに、OpenTelemetryから登場した生成AI向けのセマンティック規約があり、これらに標準的な名前を付ける方法が提供されています。サポートAIでは、技術的な詳細とビジネスに関連する情報の両方を追跡したいはずです。
キャプチャすべき主要な属性をいくつか紹介します。
-
モデルパラメータ: "llm.model.name", "llm.temperature"
-
トークン使用量: "llm.usage.prompt_tokens", "llm.usage.completion_tokens"(これはコストを監視する上で非常に重要です)
-
ツールコール: "tool.name", "tool.input", "tool.output"
-
ビジネスコンテキスト: "customer.id", "ticket.id", "ticket.tags"
この種のデータをキャプチャすることで、単にパフォーマンスを監視するだけでなく、重要なビジネス上の問いに答えることができるようになります。応答が遅かったかどうかを知るだけでなく、なぜ遅かったのか、そしてそれが顧客にとって何を意味するのかを理解できるようになります。
| 技術的な属性 | それが答えるビジネス上の問い |
|---|---|
| "llm.usage.total_tokens" | チケット1件を解決するために平均でいくら費やしているか? |
| "tool.call.duration" | サポートの応答が遅い原因は、自社の内部APIか? |
| "response.success" (カスタム) | AIは実際に問題を解決している頻度はどのくらいか、それとも単にエスカレーションしているだけか? |
| "knowledge.source.used" (カスタム) | ヘルプ記事のうち、本当に役立っているのはどれで、そうでないのはどれか? |
ステップ4:トレーシングデータを使ってAIを改善する
データがオブザーバビリティツールに流れ込み始めたら、問題を診断し、改善方法を見つけるために掘り下げていくことができます。ここからが、このセットアップの真価が発揮されるところです。
-
遅い応答のデバッグ: 長いトレースを見れば、どのスパンがボトルネックになっているかは一目瞭然です。「tool.call:lookup_order」スパンに5秒かかっている場合、問題はLLMではなく、社内の注文システムにあるとわかります。これで、どこに注力すべきかが正確にわかります。
-
不正解の調査: 「llm.prompt」と「llm.completion」属性を見ることで、AIに与えられた正確な情報と、AIが生成した結果を確認できます。ナレッジベースから取得したコンテキストが古いために「ハルシネーション(幻覚)」を起こしていたことがわかるかもしれません。これにより、症状にパッチを当てるだけでなく、根本原因を修正できます。
-
ナレッジギャップの発見: AIが回答を見つけられないたびにログを記録すれば、すぐに傾向を把握できます。「返金方法」に関するログが多ければ、そのトピックに関するドキュメントを作成または改善する必要があるという明確なシグナルです。サポートAIが、セルフサービスリソースを積極的に改善するためのツールになります。

プロのヒントと避けるべきよくある間違い
OpenTelemetryでサポートAIのロギングとトレーシングを設定するのは、少し難しい場合があります。ここでは、役立つヒントと注意すべき一般的な落とし穴をいくつか紹介します。
-
よくある間違い#1:レイテンシだけを追跡する。 速度にばかり集中しがちですが、本当に重要なのは正確性と有効性です。解決成功率、エスカレーション率、さらにはAIとのやり取りに関連付けられた顧客満足度スコアなどを追跡するために、カスタム属性を作成しましょう。目標は、単に速い回答ではなく、より良いサポートです。
-
よくある間違い#2:複雑さを見くびる。 OpenTelemetryの手動セットアップは、一度設定して終わりというものではありません。AIアプリケーションが成長し変化するにつれて、定期的なメンテナンスが必要です。本当の作業はデータを収集することだけではありません。そのデータを実際に行動に移せるものに変えるダッシュボードやアラートを構築することです。
ここでマネージドプラットフォームが大きな価値を提供します。eesel AIのようなソリューションは、サポートに特化した最も重要なデータをキャプチャするようにあらかじめ設定されています。ダッシュボードをゼロから構築する代わりに、ナレッジギャップを自動的に指摘し、自動化の最良の機会を示してくれるレポートを入手できます。
複雑なデータから明確なインサイトへ
OpenTelemetryを導入することは、サポートAIのブラックボックスを開く素晴らしい方法です。これにより、すべてのリクエストをトレースし、パフォーマンスを測定し、コストを抑制し、最終的にはより信頼性が高く効果的なシステムを構築できます。しかし、これまで見てきたように、これをすべて自分で行うには、エンジニアリング時間と継続的な維持管理に多大な投資が必要です。
eesel AIでAIオブザーバビリティをすぐに利用する
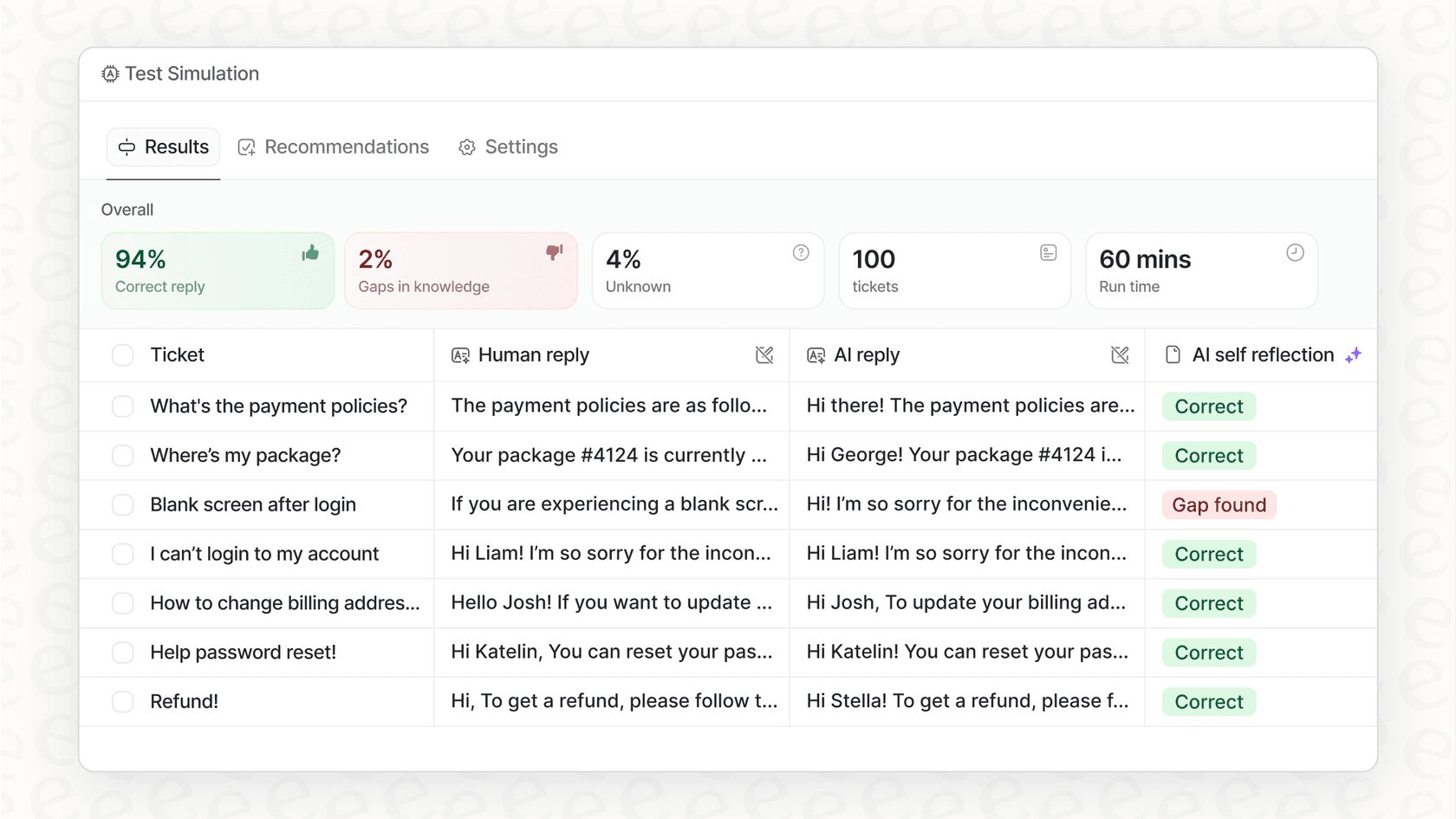
もし、深いAIオブザーバビリティのすべての利点を手間なく享受したいなら、eesel AIが最適です。当社のプラットフォームには、カスタマーサポートチーム向けに特別に設計された包括的なロギングとトレーシングが組み込まれています。過去のチケットでパフォーマンスをシミュレーションして潜在的なROIを確認したり、ナレッジギャップに関する実用的なレポートを入手したり、数ヶ月ではなく数分で本番稼働させたりできます。
あなたのサポートAIが本当に持つ能力を確かめてみませんか? 今すぐ無料トライアルを開始。
よくある質問
これにより、あなたの[サポートAIがブラックボックスから](https://devops.com/next-generation-observability-combining-opentelemetry-and-ai-for-proactive-incident-management/)透明なシステムに変わり、その動作を理解できるようになります。この可視性は、問題のデバッグ、ボトルネックの特定、そして信頼性の高いパフォーマンスとコスト効率を確保するために不可欠です。
主に、トレーサーを作成するためのTracer Provider、データをオブザーバビリティバックエンドに送信するためのExporter、そしてスパンのライフサイクルを管理するためのSpan Processorが必要です。オプションとして、OpenTelemetry Collectorもデータ処理を効率化できます。
基本的なワークフローのトレースに加えて、LLMのモデルパラメータ、トークン使用量、ツールコール、ビジネスコンテキスト(例:顧客ID、チケットタグ)などの属性をキャプチャしてください。これらは、より深い分析と理解のために重要なコンテキストを提供します。
[ボトルネックを特定して遅い応答をデバッグ](https://learn.microsoft.com/en-us/azure/ai-foundry/how-to/develop/trace-agents-sdk)したり、プロンプトと補完内容を確認して不正解を調査したり、失敗したAIインタラクションを追跡してナレッジギャップを発見したりすることができます。このデータにより、的を絞ったデータ駆動型の改善が可能になります。
手動でのセットアップには、初期実装、継続的なメンテナンス、分析用のカスタムダッシュボード構築のために、かなりの開発時間が必要です。完全なコントロールが可能になりますが、専門的かつ持続的なエンジニアリングの努力が求められます。
はい、eesel AIのようなマネージドプラットフォームは、サポートAI向けに特別に設計された組み込みのオブザーバビリティを提供します。基盤となる複雑さを処理し、手動でのセットアップやカスタムコードを必要とせずに、すぐに使えるインサイトやレポートを提供します。
Share this article

Article by
Kenneth Pangan
Writer and marketer for over ten years, Kenneth Pangan splits his time between history, politics, and art with plenty of interruptions from his dogs demanding attention.