Warum KI-Ticket-Reduzierung wieder oben auf jeder CX-Agenda steht
Support-Leiter bekommen keine größeren Budgets. Sie erhalten jedoch viel größere Warteschlangen. 53 % der Kundendienst-Praktiker im Jahr 2025 nannten „Ticket-Volumen ohne Personalwachstum verwalten" als ihre größte Herausforderung, laut Freshworks' Customer Benchmark Report 2025, und 90 % der Agenten in Unternehmensdienstleistungen sagen, repetitive Arbeit hindert sie an den wertvollen Tickets.
Der wirtschaftliche Fall schreibt sich von selbst, sobald man zwei Zahlen nebeneinander stellt. Ein vom Menschen bearbeitetes Ticket kostet branchenübergreifend durchschnittlich 8–12 $, laut Forrester, und klettert in B2B-SaaS auf 25–35 $. Ein KI-bearbeitetes Ticket – selbst eines, bei dem die KI Kontodaten abfragt und eine Aktion ausführt – kostet durchschnittlich 0,50–1,05 $. Das ist ein 12- bis 24-facher Kostenvorteil pro Interaktion, der sich mit jedem reduzierten Ticket verstärkt.
Deshalb wird erwartet, dass KI im Kundenservice von 12,06 Mrd. $ im Jahr 2024 auf 47,82 Mrd. $ bis 2030 wächst, ein CAGR von 25,8 %. Und deshalb ist 80 Mrd. $ an prognostizierten globalen Support-Einsparungen bis 2027 laut Gartner die Zahl, die Käufer machen einen Screenshot von.
Aber – und das ist der Teil, den die meisten Beiträge überspringen – der Grund, warum 47 % der Unternehmen nach dem Einsatz von KI flache oder steigende Kosten melden, liegt nicht an der KI. Es liegt daran, dass sie sie in dieselben kaputten Workflows eingeklinkt und das Ergebnis „Deflection" genannt haben. Das ist der Fehlermodus, den der nächste Abschnitt auseinandernimmt.
„Deflection" und „Reduzierung" – die Worte sind wichtig
Ein Großteil der Verwirrung in diesem Bereich entsteht dadurch, dass Menschen diese Begriffe synonym verwenden. Sie sind nicht dasselbe.
- Deflection ist eine Taktik: Der Kunde erhält eine Antwort (oder einen Self-Service-Pfad, der ihm wirklich antwortet) bevor ein Ticket eröffnet wird.
- Reduzierung ist das Ergebnis: weniger Tickets, die menschliche Zeit benötigen. Reduzierung umfasst Deflection, beinhaltet aber auch KI-Triage, die Tickets in Sekunden schließt, Entwürfe, die ein Mensch mit einem Klick senden kann, und proaktive Produkt-/UX-Korrekturen, die die Frage gar nicht erst entstehen lassen.
Der Grund, warum das wichtig ist: Ein Team, das nur für die Deflection-Rate optimiert, wird es Kunden stillschweigend schwerer machen, einen Menschen zu erreichen, wie Corebees Analyse von 50+ Support-Team-Threads dokumentierte. Ein Team, das für Reduzierung optimiert, betrachtet den gesamten Trichter – einschließlich der Tickets, die immer noch zu einem Menschen durchkommen sollten, nur schneller und günstiger.
„Ich glaube nicht an Ticket-Deflection. Ich glaube daran, Tickets unnötig zu machen. Da ist ein Unterschied. Deflection leitet den Kunden um. Tickets unnötig zu machen behebt, was die Frage verursacht hat."
Support-Leiter, zitiert in Corebee.ais Diskussionssynthese
Behalten Sie diese Unterscheidung für den Rest dieses Beitrags im Hinterkopf. Wenn wir „KI-Ticket-Reduzierung" sagen, meinen wir den gesamten Trichter – nicht nur die Headline-Deflection-Zahl auf einem Dashboard.
Das 14 %-Problem: Was die meisten Deflection-Dashboards Ihnen nicht sagen
Hier ist die einzige wichtigste Zahl in diesem gesamten Beitrag, und sie ist die, die fast niemand zitiert:
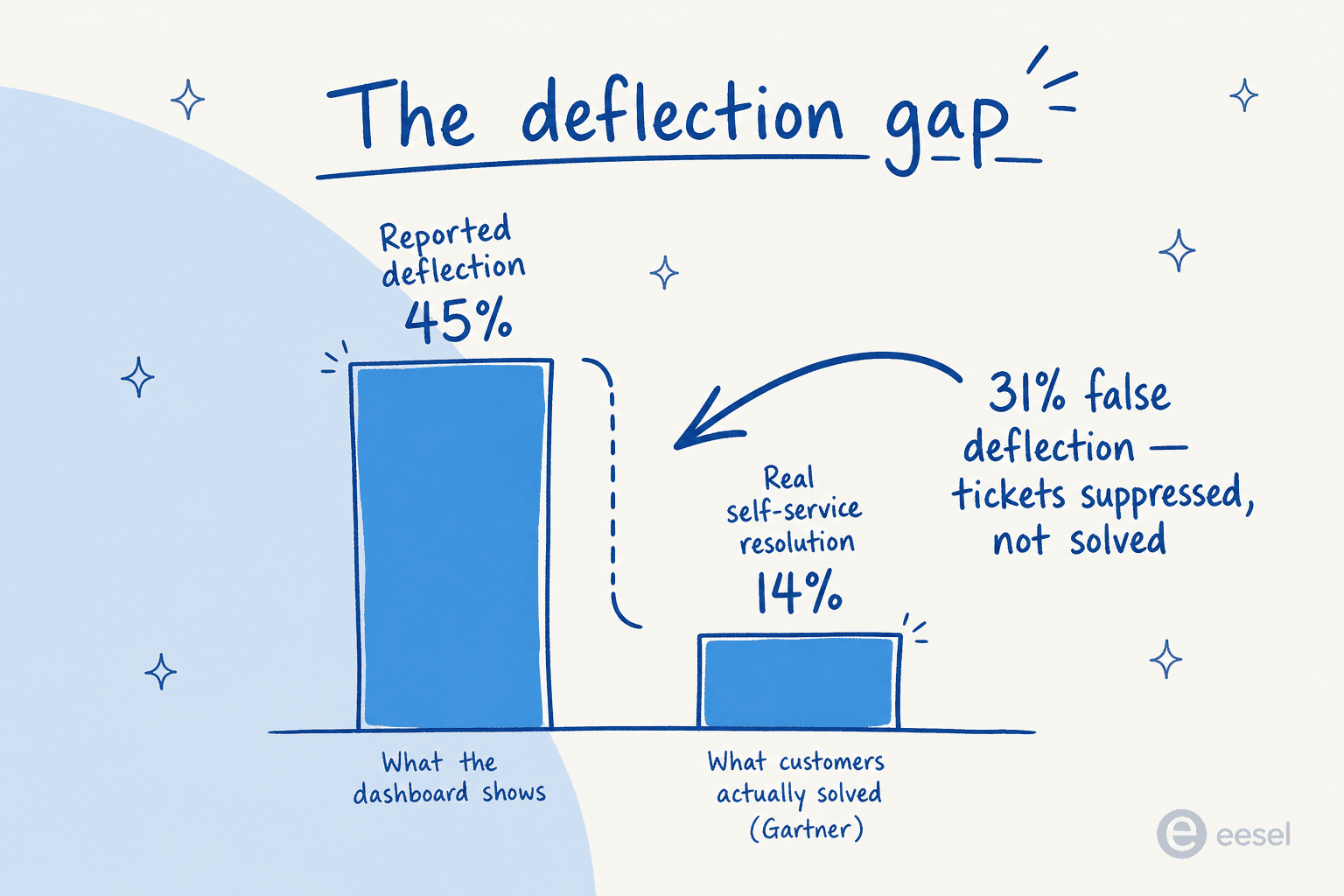
Gartner stellt fest, dass KI mehr als 45 % der Kundenanfragen ablenkt – aber nur rund 14 % erreichen eine vollständige Self-Service-Auflösung. Die verbleibenden ~31 Prozentpunkte sind das, was die Branche als False Deflection bezeichnet: Das Ticket wurde auf Ihrer Plattform nie eröffnet, aber der Kunde hat keine Hilfe erhalten. Er ist woanders hingegangen – Telefon, E-Mail, soziale Medien, ein Konkurrent.
Eine separate Studie von 100.050 Support-Interaktionen, zitiert von Corebee.ai, fand den Fehlermechanismus: KI-Bots sind 37 % häufiger daran beteiligt, Probleme von der Lösung wegzubewegen als Menschen, wenn sie konfiguriert sind, die Deflection-Rate als KPI zu optimieren. Die Aufgabe des Bots wird zu „Gespräch beenden", nicht „Problem lösen".
Die Lücke sieht man am deutlichsten, wenn Teams die angepasste Formel verwenden:
Echte Deflection-Rate = (Self-Service-Auflösungen − 48-Stunden-Rückkontakte) ÷ Gesamtzahl der Hilfesuchenden
Die meisten Teams, die sich die Mühe machen, dies zu berechnen, stellen fest, dass ihre echte Deflection-Rate um 15–25 % niedriger als die gemeldete ist. Ein Dashboard, das 80 % Deflection zeigt, könnte 55–65 % echte Auflösung bedeuten. Ein Dashboard, das 50 % zeigt, könnte 35–40 % bedeuten. Die eigene echte Zahl zu kennen, ist die Voraussetzung, um sie wirklich zu verbessern.
Das Fazit: Machen Sie die Deflection-Rate nicht zu einem isolierten KPI. Verfolgen Sie sie zusammen mit dem CSAT für bot-gelöste Gespräche, der 48-Stunden-Rückkontaktrate und der Kanal-Wechselrate. Die Teams, die ehrliche Ergebnisse erzielen, tun das alle; die Teams mit unterdrückten Metriken nicht.
Was KI-Ticket-Reduzierung unter der Haube wirklich macht
Sobald man weiß, was man messen soll, stellt sich die nächste Frage: Was macht KI eigentlich, wenn sie ein Ticket reduziert? Die meisten Beiträge winken das mit „KI verwendet NLP und Machine Learning" ab. So sieht die Architektur 2026 aus:
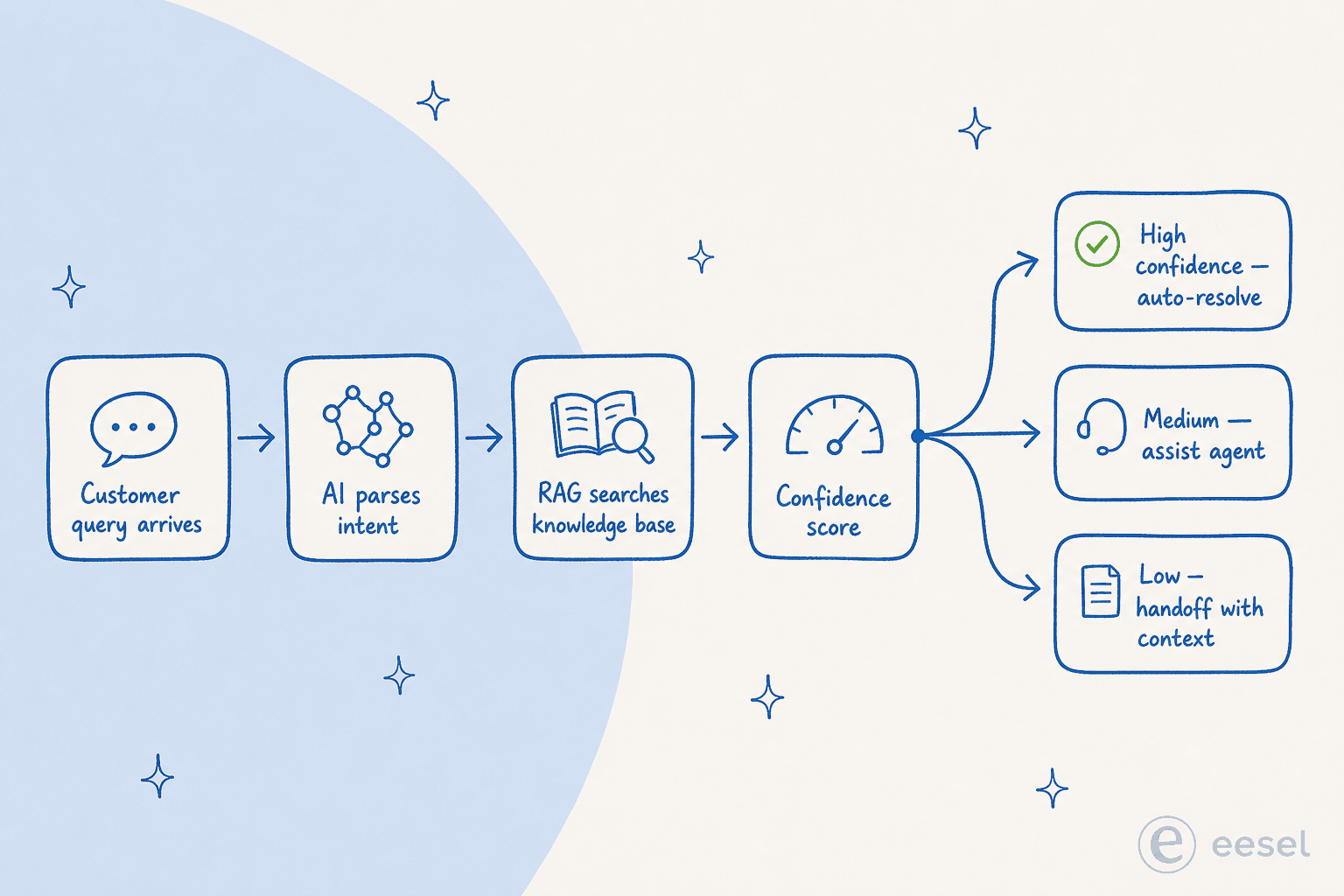
- Intent-Parsing. Ein LLM (GPT-4-Klasse, Claude, Gemini) liest die eingehende Anfrage und extrahiert Intent, Dringlichkeit, Stimmung und relevante Entitäten (Bestellnummer, Konto-Tier, Fehlercode). Das ist die Schicht, die die Schlüsselwort-Chatbots von 2018 ersetzt hat, und es ist das, was dem System ermöglicht, Paraphrasierung und Mehrdeutigkeit zu verarbeiten – „mein Ding funktioniert nicht" wird gleich geroutet wie „kann mich nicht einloggen."
- Wissensdatenbank-Abfrage (RAG). Das System bettet die Anfrage und Ihre Wissensdatenbank in denselben Vektorraum ein, findet semantisch übereinstimmende Artikel und frühere Lösungen und synthetisiert eine Antwort, die auf abgerufenen Inhalten basiert, anstatt sie von Grund auf zu generieren. ClarityArc bringt es auf den Punkt: „Ein Ticket-Deflection-Agent ist ein Wissensdatenbank-Abfragesystem mit einer konversationellen Oberfläche – seine Qualitätsobergrenze wird durch die Qualität der Wissensdatenbank bestimmt, aus der er abruft."
- Confidence-Scoring und Routing. Das System weist einen Confidence-Score zu und entscheidet, was zu tun ist: hohe Konfidenz → antworten und schließen; mittel → die Antwort mit einem prominenten Pfad zu einem Menschen präsentieren; niedrig → sofort eskalieren mit vollständigem Kontext.
- Kontenspezifische Aktionen. Die große Freischaltung in agentic AI: Anstatt nur einen Artikel abzurufen, liest der Agent das CRM/Billing/Bestellsystem und führt die Aktion durch. Eine Bestellung nachschlagen, eine Rückerstattung ausstellen, ein Abonnement aktualisieren. Integrationstiefe fügt 20–30 % hinzu zur Deflection-Qualität obendrauf zur KB-Qualität, weil die meisten echten Fragen Kontokontext brauchen, keine generischen Inhalte.
- Kontextübertragende Eskalation. Wenn die KI es nicht handhaben kann, schickt sie den Kunden nicht zurück zum Anfang. Sie übergibt dem menschlichen Agenten eine vollständige Gesprächszusammenfassung, den relevanten Kontostatus und den Eskalationsgrund. Das ist der Unterschied zwischen „die KI hat es versucht und versagt" und „die KI hat die Triage durchgeführt, damit der Mensch in 90 Sekunden lösen kann."
Zwei Warnungen, die hier erwähnenswert sind, weil sie den gesamten Stack zum Absturz bringen, wenn sie ignoriert werden:
- LLM-Konfidenz ist keine faktische Konfidenz. Ein LLM kann zu 95 % von einer halluzinierten Antwort überzeugt sein – Confidence-Scores messen Token-Wahrscheinlichkeit, keine Wahrheit. Verwenden Sie nie rohe Konfidenz als alleiniges Gate. Kombinieren Sie sie mit KB-Abdeckungssignalen und Themenbereichsregeln (DEV Community HITL Post-mortem).
- Die KB ist Ihre Obergrenze, nicht das Modell. GPT-4 gegen Claude auszutauschen wird eine bei 35 % feststeckende Deflection-Rate nicht beheben. Die Wissensdatenbank zu aktualisieren und den Umfang zu straffen wird es.
Was sich gut reduzieren lässt – und was nicht
Die andere Zahl, über die die meisten Berichte hinwegsehen: KI-Ticket-Reduzierung ist nicht gleichmäßig über Anfragetypen hinweg. Derselbe Agent, auf derselben KB, mit demselben Modell, liefert Ihnen je nach dem, worauf Sie ihn ausrichten, völlig unterschiedliche Zahlen.
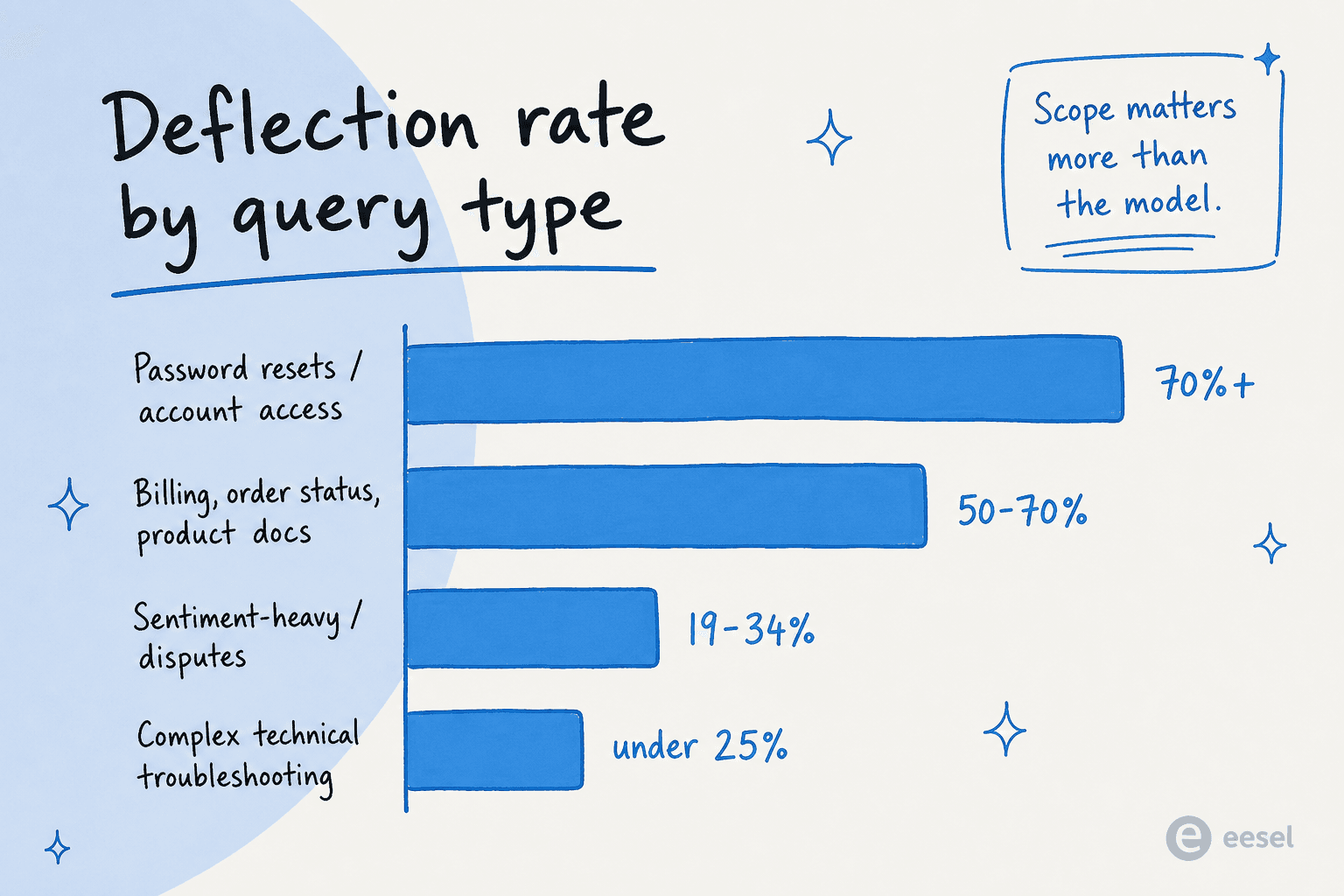
Laut ClarityArcs Benchmarks 2026 und Pylons Deflection-Leitfaden:
| Anfragetyp | Typische Deflection-Rate | Warum |
|---|---|---|
| Passwort-Resets / Kontozugang | 70 %+ | Hohe Volumen, deterministisch, System-of-Record-Antwort |
| Bestellstatus / WISMO | 50–70 % | Backend-Abfrage sobald Integrationen verdrahtet sind |
| Rückerstattungen & Retouren (Standardrichtlinie) | 50–70 % | Klare KB + agentic action verfügbar |
| Standard-Produkt / How-to-Docs | 50–70 % | KB-gebunden, gut erprobt |
| Komplexe technische Fehlersuche | Unter 25 % | Jeder Fall ist neu; menschliches Denken erforderlich |
| Emotional aufgeladen / Streitigkeiten | 19–34 % | Emotionaler Kontext, nicht nur informationell |
| Reguliert / Compliance-sensibel | Unter 20 % | Risiko und Überprüfung schlagen Geschwindigkeit |
Deshalb ist die Entscheidung mit dem größten Hebel in jedem KI-Ticket-Reduzierungsprojekt der Umfang, nicht die Anbieterauswahl. Wählen Sie die zwei oder drei Anfragetypen, die in der oberen Hälfte dieser Tabelle liegen, bringen Sie diese auf 60–70 % echte Deflection, und dann erweitern. Wählen Sie „alles" am ersten Tag, und der Durchschnitt zieht so stark nach unten, dass das Projekt abgebrochen wird.
Unsere Einschätzung: Wenn Ihr Team gerade erst beginnt, machen Sie zuerst Passwort-Resets und WISMO. Sie haben ein hohes Volumen, sind deterministisch und reduzieren die Warteschlange so merklich, dass der Rest des Teams hinter dem Projekt steht. Den Versuch, Beschwerde-Tickets am ersten Tag abzulenken, ist der Weg, wie KI-Projekte intern an Glaubwürdigkeit verlieren.
Echte Zahlen von echten Teams (und was sie gemeinsam hatten)
Die Fallstudie-Highlights sind real – aber die Schlussfolgerung ist nicht „wir sollten auch 86 % erreichen." Sie lautet „schau, wie eng eingegrenzt jede davon war."
- Grammarly stieg von 60 % auf 87 % Deflection in 10 Tagen mit Forethoughts agentic Plattform, mit CSAT-Verbesserung auf 4,2/5. Das Hinzufügen von System-Integrationen trug weitere 5–10 % bei.
- Bilt Rewards verwaltet 70 % von 60.000 monatlichen Tickets mit KI-Agenten.
- Duolingo läuft mit Decagon über 80 % Deflection.
- Klarnas KI übernimmt zwei Drittel des gesamten Kundenservices – entsprechend 700 Vollzeit-Agenten.
- Freshworks Einzelhandelskunden sehen Freddy AI 53 % aller eingehenden Anfragen lösen.
- Gorgias eCommerce-Kunden erreichen routinemäßig 60 % Deflection sogar mit minimalem Trainingsaufwand.
Der gemeinsame Faden ist nicht die Plattform. Es ist das Betriebsmodell: enger Umfang am ersten Tag, tiefe CRM-/Bestell-/Billing-Integrationen, ein kalibrierter Confidence-Schwellenwert, ein klarer Eskalationspfad und die Gewohnheit, jede Eskalation als Wissensdatenbank-Update zu nutzen. Die Anbieter variieren; die Disziplin nicht.
Eesels eigene Kunden-Benchmarks spiegeln dasselbe Muster wider. Ein Gig-Economy-Fahrer-Analyse-Unternehmen auf Zendesk Business löste 73 % der Tier-1-Anfragen in seinem ersten Monat nach einem 7-tägigen Test. Ein interner IT-Helpdesk auf Jira Service Management liegt bei 15 % Deflection mit einem Ziel von 55 %, wenn ihre KB und der Agenten-Umfang erweitert werden. Die Zahl, die sich bewegt, ist nicht das Modell – es sind die Eingaben.
Die fünf Dinge, die Teams, die wirklich die Zahl bewegen, richtig machen
In der Dossier von 50+ Produktions-Deployments Corebee.ai analysiert, Pylons Deflection-Leitfaden und ClarityArcs Produktions-Playbook tauchen dieselben fünf Variablen bei jedem Team auf, das eine ehrliche Reduzierung von 60 %+ erreicht.
1. Zuerst Wissensdatenbank-Qualität, dann KI
Dies ist der einzige wichtigste Hebel im gesamten System. Gut strukturierte Dokumentation erhöht die echte Auflösung um 15–25 % – bevor Sie eine Modelleinstellung ändern. Der Grund, warum die meisten Piloten ins Stocken geraten: Teams richten KI auf die KB, die sie haben, nicht auf die KB, die sie brauchen. Die KB, die sie haben, wurde für menschliche Agenten geschrieben, die das Produkt bereits kennen, nicht für eine KI, die kalt antworten muss.
Die Lösung ist mechanisch: Wählen Sie die zwei oder drei Intents aus, die Sie eingrenzen werden, prüfen Sie die entsprechenden KB-Artikel, schreiben Sie sie für natürlichsprachliche Fragen statt für interne Fachsprache um und fügen Sie aktuelle gelöste Tickets als Arbeitsbeispiele in die KB ein. Dann deployen.
Wenn Sie von einer dünnen KB starten, behandeln unsere Leitfäden zum Aufbau eines KI-Wissensdatenbank-Chatbots und zur Auswahl der richtigen KI-Wissensdatenbank-Tools die Daten-Plumbing.
2. Eng eingrenzen. Dann noch enger.
Das konsistenteste Versagensmuster in der Diskussionsanalyse sind Teams, die versuchen, am ersten Tag „alles" abzudecken. Beginnen Sie mit 2–3 Anfragetypen, bei denen die KB wirklich vollständig ist. Decken Sie diese gut ab – ehrlich messen, Lücken schließen, über 60 % echte Deflection hinausschieben – und erweitern Sie erst dann.
Was aus dem ersten Tag herausgeschnitten wird:
- Alles Emotional-Aufgeladene (Rückerstattungsstreitigkeiten, Beschwerden, Eskalationen von benannten Konten)
- Alles Regulierte oder Compliance-Sensible
- Alles, was Kontext außerhalb der KB erfordert (Engineering-Bugs, Systemstatus bei Vorfällen)
- Tickets von Ihren Top-Tier-Konten – VIPs gehen bei der ersten Nachricht zu Menschen, Ende der Geschichte
3. Tief genug integrieren, damit die KI handeln kann, nicht nur beschreiben
Wenn die KI nur KB-Artikel abrufen kann, wird sie bei etwa 35–40 % Deflection ein Plateau erreichen. Die 60–90 %-Deployments haben alle CRM-, Billing- und Bestellsystem-Integration, die es dem Agenten ermöglicht, die tatsächliche Aktion durchzuführen – die Bestellung nachschlagen, die Retoure bearbeiten, den Plan ändern.
ClarityArcs Daten zeigen, dass Integrationstiefe 20–30 % obendrauf zur KB-Only-Deflection beiträgt. Das stärkste Praktiker-Zitat dazu:
„Das wirkliche Freischalten ist, wenn KI das Problem tatsächlich end-to-end über Ihre Systeme hinweg lösen kann, nicht nur vorschlagen, was zu sagen ist."
Das ist auch der Grund, warum aufgesetzte regelbasierte Chatbots dazu neigen zu versagen. Sie rufen ab, aber handeln nicht. Kunden stellen eine Frage, die Kontodaten erfordert, der Bot versagt, Deflection-Zahlen steigen während CSAT sinkt. KI-native Plattformen – solche, die Ihren Helpdesk, Ihr CRM und Ihr Bestellsystem in einem Runtime lesen – schließen diese Lücke.
4. Confidence-Routing kalibrieren – und der KI erlauben, „Ich weiß es nicht" zu sagen
Das war der entscheidende Einwand in unserem eigenen Kundendossier:
„Die KI wird nie 100 % der Fragen beantworten können, aber wenn sie es versucht und einfach ‚tut mir leid, das weiß ich nicht' antwortet, kann ich nicht alle meine 7.000 Tickets durchgehen, um zu sehen, ob die KI wirklich eine gute Antwort gegeben hat. Ich brauche eine KI, die nur die Tickets bearbeitet, bei denen sie sich sicher ist, und bei allen anderen einfach die Finger weg lässt."
Ein CX-Leiter bei einer DTC-Nahrungsergänzungsmittelmarke auf Gorgias + Shopify (~7K Tickets/Monat), eesel-Kundendossier (anonymisiert nach Einwilligung)
Das ist die gesamte These zum Confidence-Routing in einem Zitat. Eine KI, die alles beantwortet, ist schlechter als eine KI, die die Hälfte beantwortet und den Rest klar eskaliert. Kalibrieren Sie Ihre hoch/mittel/niedrig-Schwellen durch Tests am echten Traffic, nicht nach Bauchgefühl – und rekalibrieren Sie sie vierteljährlich, wenn sich die KB weiterentwickelt.
Wenn Sie eine tiefere Lektüre dazu wollen, behandelt unser Überblick über den Zendesk KI-Agenten Intent-Confidence-Schwellenwert, wie ein echter Helpdesk es implementiert.
5. Jede Eskalation als Lernsignal behandeln
Jedes Mal, wenn die KI eskaliert, teilt sie Ihnen eines von drei Dingen mit: Die KB hat eine Lücke, der Umfang war für diesen Intent falsch, oder der Confidence-Schwellenwert muss angepasst werden. Teams, die die höchsten Deflection-Raten erzielen, machen eine wöchentliche Überprüfung von 20–30 eskalierten Gesprächen und verwandeln die Muster in KB-Updates, Umfangsänderungen oder Routing-Regeln.
Das Gegenteil – sich anhäufende Eskalationen ungelesen, der Bot beantwortet still falsch, niemand prüft – ist, wie eine Deflection-Rate von 65 % still zu einer Suppression-Rate von 65 % und einem Churn-Anstieg sechs Monate später wird.
Wie KI-Ticket-Reduzierung schief geht (die Fehlermodi, die man von Anfang an einplanen sollte)
Dieselben Muster treten in den 50+ Support-Team-Threads, die Corebee analysiert hat, den DEV Community Post-mortems und den Praktiker-Gesprächen in SaaStrs Juni-2025-Analyse auf. Wenn Sie das einrollen, planen Sie diese von Anfang an ein:
- Deflection-Rate wird zum KPI. Sobald es eine Zahl ist, gegen die Menschen bezahlt werden, wird das System darauf ausgelegt, die Zahl zu treffen – auch auf Kosten der Kundenerfahrung. Verfolgen Sie sie als Signal neben CSAT und Rückkontaktrate, nicht als Ziel.
- VIPs treffen den Bot. Der teuerste Fehlermodus ist, dass Ihre Top-Tier-Konten gegen eine KI-Wand laufen, während ein 40 $/Monat-Kunde einen Menschen bekommt. Routen Sie VIPs direkt zu Menschen bei Nachricht eins. Immer.
- Konfident-falsche Antworten. Der Bot beantwortet eine Anfrage, die er hätte eskalieren sollen, der Kunde vertraut ihm, und eine einfache Frage wird zu einer Vertrauenskrise. Die Lösung sind Themenbereichs-Leitplanken (der Bot darf über X antworten, nicht über Y), nicht nur ein Confidence-Schwellenwert.
- Bot-Schleifen ohne Eskalation. Ein „mit einem Menschen sprechen"-Button vier Klicks tief vergraben, ein Eskalationspfad, der dieselben Fragen, die der Bot bereits gestellt hat, erneut stellt, oder überhaupt kein menschlicher Pfad. Kunden verlassen still, wenn das die Erfahrung ist.
- Rückkontakt-Anstieg über andere Kanäle. Ihre Plattform-Deflection-Rate steigt, Ihre Telefonwarteschlange steigt noch mehr. Überprüfen Sie immer die Kanal-Volumen, bevor Sie einen Deflection-Sieg feiern.
Ein DEV Community Post-mortem eines Teams, das täglich mehr als 12.000 Agenten-Aufgaben verarbeitet, macht den Fall drastisch. Bevor sie Human-in-the-Loop-Prüfungen für hochriskante Aufgaben hinzufügten, lag ihre kritische Fehlerrate bei 23,4 %. Der Agent schloss automatisch 34 Tickets, die zum Engineering hätten gehen sollen, darunter drei aktive Produktionsvorfälle. Ein Kunde verlor sechs Stunden Daten.
„Dieser Vorfall kostete uns einen Jahresvertrag von 280.000 $ und ein sehr unangenehmes Post-mortem."
Nach HITL für die richtigen Aufgaben (keine allgemeine Überprüfung von allem) sank die kritische Fehlerrate auf 5,1 % – eine Reduzierung um 78 % – und der menschliche Überprüfungsaufwand sank um 62 %. Die Lektion, die das Team zusammenfasste: „Der schwierige Teil ist nicht, den Agenten zu bauen – sondern zu entscheiden, wann man ihm vertraut."
Ein Rollout-Playbook, das das Vertrauen nicht zerstört
All das in etwas umgewandelt, das Sie in den nächsten 90 Tagen tatsächlich tun können:
Wochen 1–2 – Diagnose. Ziehen Sie Ihre letzten 1.000 Tickets. Taggen Sie sie nach Intent. Finden Sie die drei wichtigsten Intents nach Volumen und KB-Vollständigkeit. Wählen Sie nicht nur nach Volumen – ein hoher-Volumen-Intent mit dünner KB ist ein Projekt, kein schneller Gewinn.
Wochen 3–4 – KB vorbereiten. Für jeden ausgewählten Intent schreiben oder aktualisieren Sie die KB-Artikel. Fügen Sie 5–10 Arbeitsbeispiele aus echten gelösten Tickets hinzu. Entfernen Sie interne Fachsprache. Testen Sie, indem Sie einen Junior-Agenten bitten, kalt von der KB zu antworten; wenn er es nicht kann, wird Ihre KI es auch nicht.
Wochen 5–6 – Integrationen verdrahten. Verbinden Sie den Helpdesk, das CRM und das Bestell-/Billing-System. Der Agent benötigt Lesezugriff auf den Kontostatus und Schreibzugriff auf die Aktionen, die er tatsächlich ausführen soll.
Wochen 7–8 – Pilot im Copilot-Modus. Betreiben Sie KI als Copilot – Antworten entwerfen, niemals autonom senden. Messen Sie, wie oft menschliche Agenten den Entwurf unverändert senden, leicht bearbeiten oder von Grund auf neu schreiben. Wenn die „unverändert senden"-Rate 60 %+ bei Ihren eingegrenzten Intents erreicht, sind Sie bereit für autonomen Betrieb.
Wochen 9–12 – Zum autonomen Betrieb für den sichersten Intent übergehen. Beginnen Sie mit einem Intent. Hoher Confidence-Schwellenwert. Aggressive Eskalations-Defaults. Wöchentliche Gesprächsprüfungen. Senken Sie den Schwellenwert nur, wenn die Daten es unterstützen.
Das ist die Betriebsdisziplin, nicht die Technologie, die Teams trennt, die ehrliche 60 %+ Reduzierung melden von Teams, die eine 35 %-Deflection-Rate als 80 % verkleidet betreiben. Für eine vollständigere Anleitung sehen Sie unseren praktischen Leitfaden zur Reduzierung von Support-Tickets mit KI.
eesel ausprobieren
Wenn Sie KI-Ticket-Reduzierung einrollen und eine Plattform wollen, die für das obige Playbook ausgelegt ist und nicht dagegen – Confidence-basiertes Routing, tiefe Integrationen mit Zendesk, Freshdesk, Gorgias und 100+ weiteren, Umfangskontrolle nach Ticket-Typ und Preisgestaltung, die Sie nicht für Tests bestraft – genau dafür wurde eesel gebaut.
Eesel-Agenten leben innerhalb Ihres bestehenden Helpdesks (kein Plattformersatz), lernen ab dem ersten Tag von Ihrer bestehenden Ticket-Historie und KB und lassen sich in natürlicher Sprache briefen – „bearbeit die WISMO-Warteschlange, eskaliere alles über 500 $ an Rückerstattungen, lass die aufgebrachten Tickets in Ruhe." Die Preisgestaltung ist pro Aufgabe, nicht pro Sitz oder pro Auflösung, sodass Sie nur für Tickets bezahlen, die die KI tatsächlich berührt.
Echte Kunden haben sich schnell bewegt. Ein Gig-Economy-Fahrer-Analyse-Unternehmen auf Zendesk Business löste 73 % der Tier-1-Anfragen in seinem ersten Monat nach einem 7-tägigen Test. Ein britisches Support-Team erzielte 56 gelöste Aufgaben aus nur 9 synchronisierten Makros. Der kostenlose Tier (50 $ Guthaben, keine Karte erforderlich) reicht für einen echten Pilot mit Ihren eigenen Daten.
eesel kostenlos ausprobieren → – oder buchen Sie eine 30-minütige Demo, wenn Sie möchten, dass wir Ihren Stack gemeinsam durchgehen.
Häufig gestellte Fragen
Was ist KI-Ticket-Reduzierung?
Wie viel kann KI-Ticket-Reduzierung realistischerweise ablenken?
Was ist der Unterschied zwischen KI-Ticket-Reduzierung und KI-Ticket-Deflection?
Wie lange dauert es, bis sich KI-Ticket-Reduzierung amortisiert?
Welche Support-Tickets lassen sich am leichtesten mit KI reduzieren?
Wie messe ich KI-Ticket-Reduzierung ehrlich?
Werden durch KI-Ticket-Reduzierung meine Support-Agenten ersetzt?
Was ist das beste KI-Ticket-Reduzierungs-Tool für Zendesk, Freshdesk oder Gorgias?

Article by
Riellvriany Indriawan
Riell is a designer and writer at eesel AI with about two years of experience researching CX platforms, AI chatbots, and helpdesk software. She combines her design background with a sharp eye for how these tools actually look and feel in practice — making her comparisons unusually visual and user-focused.