
Claude Code ist kein Chatbot – hör auf, es so zu prompten
Die meisten Leute kommen von einem Chat-Fenster zu Claude Code und prompten es genauso: eine vage Anfrage, eine Wand aus Hin-und-Her, viel „Nein, nicht so." Es funktioniert meistens, und es ist auch der langsamste Weg, das Werkzeug zu benutzen.
Das mentale Modell ist anders. Wie Anthropic in seinem Best-Practices-Leitfaden beschreibt, „erkundet, plant und implementiert" Claude Code eigenständig: Es liest Dateien, führt Befehle aus und arbeitet sich durch ein Problem, während du zuschaust, umlenkst oder weggehen kannst. Also hört deine Aufgabe auf, „die Antwort zu tippen" und wird zu „die Arbeit aufzusetzen". Sean Tierney, der ein Jahr lang echte Apps mit dem Werkzeug gebaut hat, bezeichnet es als das Lernen, „wie der Spielmacher, nicht der Quarterback zu agieren."
Diese Umdeutung ist der gesamte Beitrag. Alles unten ist ein konkreter Weg, die Arbeit so aufzusetzen, dass Claude es beim ersten Mal richtig macht, nicht beim vierten.
Präzise sein: Beschreibe das Ergebnis, nicht die Schritte
„Je präziser deine Anweisungen, desto weniger Korrekturen brauchst du", bemerkt Anthropic. „Claude kann Absichten ableiten, aber keine Gedanken lesen." Dies ist die einzige Änderung mit dem höchsten Hebel, und sie kostet nichts.
Das Vorher-Nachher in Anthropics eigenem Leitfaden macht es deutlich. Sage nicht „Füge Tests für foo.py hinzu." Sage: „Schreibe einen Test für foo.py, der den Edge-Case abdeckt, bei dem der Benutzer ausgeloggt ist. Keine Mocks." Sage nicht „Behebe den Login-Bug." Sage „Benutzer berichten, dass der Login nach Session-Timeout fehlschlägt, überprüfe den Auth-Flow in src/auth/, insbesondere die Token-Aktualisierung, schreibe einen fehlschlagenden Test, der das Problem reproduziert, und behebe es dann."
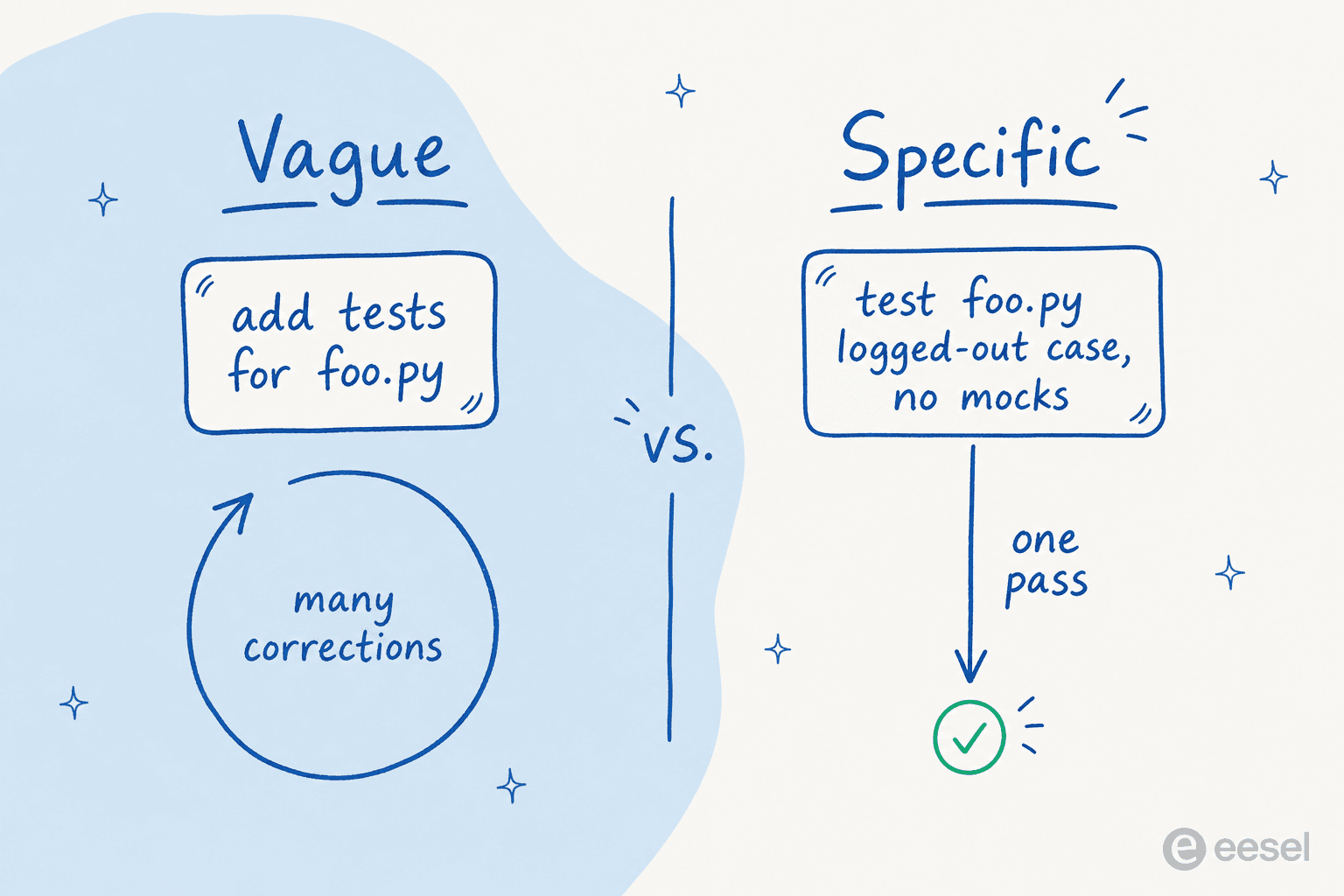
Der Trick besteht darin, das Ergebnis und die Einschränkungen zu nennen und Claude dann das Wo finden zu lassen. Anthropics Hilfe-Center nennt es "Das Ergebnis nennen, nicht die Schritte": nicht „Öffne userService.ts, finde die validate-Funktion, füge einen Null-Check in Zeile 42 ein", sondern „Benutzer ohne E-Mail crashen die Validierung, lass es das elegant behandeln und füge einen Test hinzu." Du managest nicht den Diff im Detail, du beschreibst die Welt, die du haben möchtest.
Ein Vorbehalt lohnt sich: Vage ist gut, wenn du erkundest. „Was würdest du an dieser Datei verbessern?" ist ein großartiger Prompt, weil er Dinge aufdeckt, nach denen du nicht zu fragen gewusst hättest. Präzision ist für wenn du weißt, was du willst, nicht für die Erkundungsphase.
Gib ihm das Rohmaterial: Dateien, Screenshots, URLs, Pipe-Logs
Ein präziser Prompt braucht immer noch Rohmaterial. Claude Code hat mehrere Möglichkeiten, Kontext direkt in die Konversation zu ziehen, und deren Nutzung schlägt das Beschreiben aus dem Gedächtnis:
- Referenziere Dateien mit
@. Das Eintippen von@src/auth/login.tslässt Claude die Datei lesen, bevor es antwortet. Wenn du den Pfad bereits kennst, ist das schneller und günstiger, als es suchen zu lassen. Das ist auch der Grund, warum eine saubere Repo-Struktur sich auszahlt, und warum Beiträge wie Navigieren einer Codebasis mit Claude Code wichtig sind. - Füge Bilder ein. Ziehe einen Screenshot eines Designs oder eines Fehlers hinein oder füge ihn ein und sage dann „Implementiere dieses Design, mache einen Screenshot des Ergebnisses und liste die Unterschiede auf." Claude kann Benutzeroberflächen sehen.
- Gib ihm URLs. Verweise auf eine Dokumentationsseite oder eine API-Referenz. Du kannst Domains, die du häufig verwendest, mit
/permissionsauf die Whitelist setzen. - Pipe Daten ein.
cat error.log | claudesendet die Datei direkt ein. Dies ist das Tor zur Nutzung von Claude Code im Terminal als zusammensetzbares Unix-Werkzeug.
Das Hilfe-Center hat eine direkte Regel dazu: Gib ihm den Fehler, wortgenau. Füge den vollständigen Stack-Trace ein, anstatt ihn zusammenzufassen. Der genaue Dateiname, die Zeilennummer und die Meldung ermöglichen es Claude, zum richtigen Code zu springen, anstatt zu raten. Für schwierigere Sitzungen geht unser Leitfaden zum Debuggen mit Claude Code tiefer.
Lass es planen, bevor es eine Zeile Code schreibt
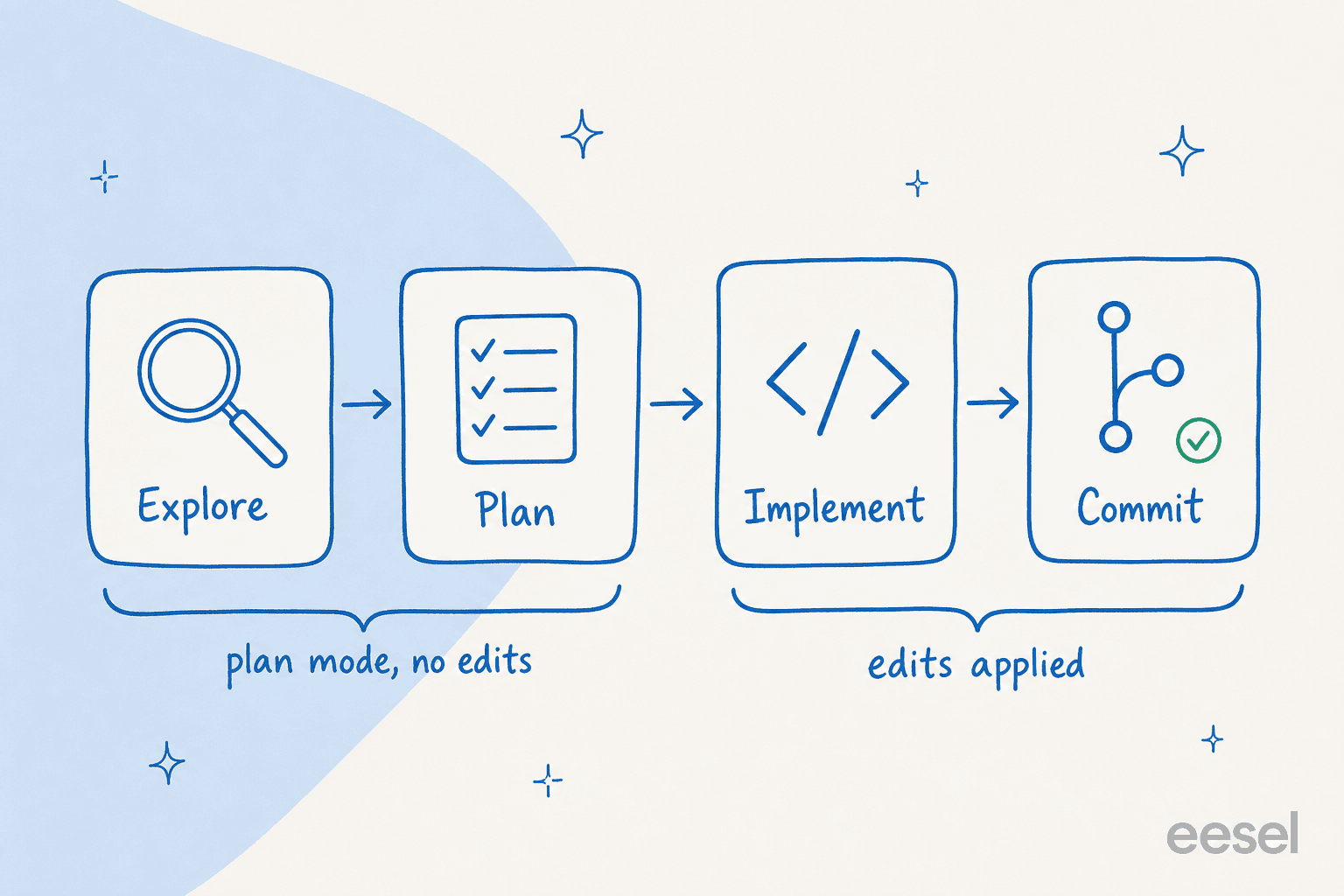
Das ist das, was Menschen, die Claude Code mögen, von denen trennt, die es lieben. „Claude direkt zum Coden springen zu lassen, kann zu Code führen, der das falsche Problem löst", warnt Anthropic. Die Lösung ist eine Vier-Phasen-Schleife: Erkunden, Planen, Implementieren, Committen.
Die ersten beiden Phasen finden im Planungsmodus statt, wo Claude Dateien liest und einen Ansatz vorschlägt, aber null Bearbeitungen vornimmt. Du betrittst ihn mit Shift+Tab (zweimal drücken, um den Planungsmodus zu erreichen), oder starte eine Sitzung mit claude --permission-mode plan. In VS Code öffnet sich der Plan als Markdown-Dokument, das du inline kommentieren kannst; im Terminal öffnet Ctrl+G den Plan in deinem Editor, damit du ihn direkt bearbeiten kannst, bevor Claude fortfährt. Den vollständigen Setup findest du in unserem Leitfaden zum interaktiven Modus.
Der Konsens unter Praktikern ist noch stärker als Anthropics Empfehlung. Hier ist Sean Tierney, der täglich mit dem Werkzeug baut:
„Starte immer im Planungsmodus. Widerstehe der Versuchung, direkt in die Implementierung einzutauchen. Du kannst CC denselben Prompt geben, aber indem du zuerst im Planungsmodus startest und es die Dinge im Voraus durchdenken lässt, erhältst du jedes Mal ein viel besseres Ergebnis, weil es einen Plan vorschlagen und verteidigen muss. Diese leicht verzögerte Befriedigung gegenüber dem Stürzen in die Implementierung ist die 2-Minuten-Wartezeit absolut wert." - Sean Tierney, Vibecode Lisboa
Wann nicht zu planen? Anthropics Faustregel ist die, die ich verwende: Wenn du den Diff in einem Satz beschreiben könntest, überspringe den Plan. Ein Tippfehler, eine Log-Zeile, ein Variablen-Umbenennen – frage einfach danach. Das Planen lohnt sich, wenn du dir über den Ansatz unsicher bist, die Änderung mehrere Dateien umfasst, oder du den Code noch nicht gut kennst.
Gib Claude eine Möglichkeit, seine eigene Arbeit zu überprüfen
Hier ist das Fehlermuster, vor dem niemand warnt: Claude hört auf, wenn die Arbeit fertig aussieht. Ohne eine ausführbare Prüfung ist „sieht fertig aus" das einzige Signal, das es hat, was bedeutet, dass du die Verifikationsschleife wirst und jeden Diff manuell nachliefst.
Die Lösung besteht darin, ihm etwas zu übergeben, das Bestanden oder Fehlgeschlagen zurückgibt: eine Testsuite, einen Build, einen Linter, ein Skript, das die Ausgabe gegen ein Fixture vergleicht, oder einen Screenshot zum Vergleich gegen ein Design. „Gib Claude eine Prüfung, die es ausführen kann", sagt Anthropic. „Es ist der Unterschied zwischen einer Sitzung, die du beobachtest, und einer, von der du weggehen kannst." Also gehört die Verifizierung in den Prompt: „Schreibe eine validateEmail-Funktion, Beispiel-Testfälle: user@example.com ist true, invalid ist false, user@.com ist false, führe die Tests nach der Implementierung aus."
Deshalb funktioniert testgetriebenes Prompten so gut. Bitte Claude, zuerst die Tests zu schreiben, bestätige, dass sie scheitern, und implementiere dann, bis sie bestehen. Und bitte es, Beweise zu zeigen statt Erfolg zu behaupten: die Testausgabe, den ausgeführten Befehl, den Screenshot. Das Überprüfen der Beweise ist schneller als das erneute Ausführen der Prüfung selbst. Wenn du das strikter gestalten möchtest, kannst du es in einen deterministischen Hook eskalieren, der ausgelöst wird, wenn Claude versucht, fertig zu werden, was unsere Hooks-Referenz erläutert.
Behandle dein Kontextfenster wie ein Budget
Fast jedes Prompting-Problem in Claude Code führt auf eine Sache zurück: Das Kontextfenster enthält die gesamte Sitzung (jede Nachricht, jede gelesene Datei, jede Befehlsausgabe) und die Modellleistung nimmt ab, wenn sich das Fenster füllt. Eine einzelne Debugging-Sitzung kann Zehntausende von Tokens verbrennen, und sobald es voll ist, beginnt Claude, deine früheren Anweisungen zu „vergessen".
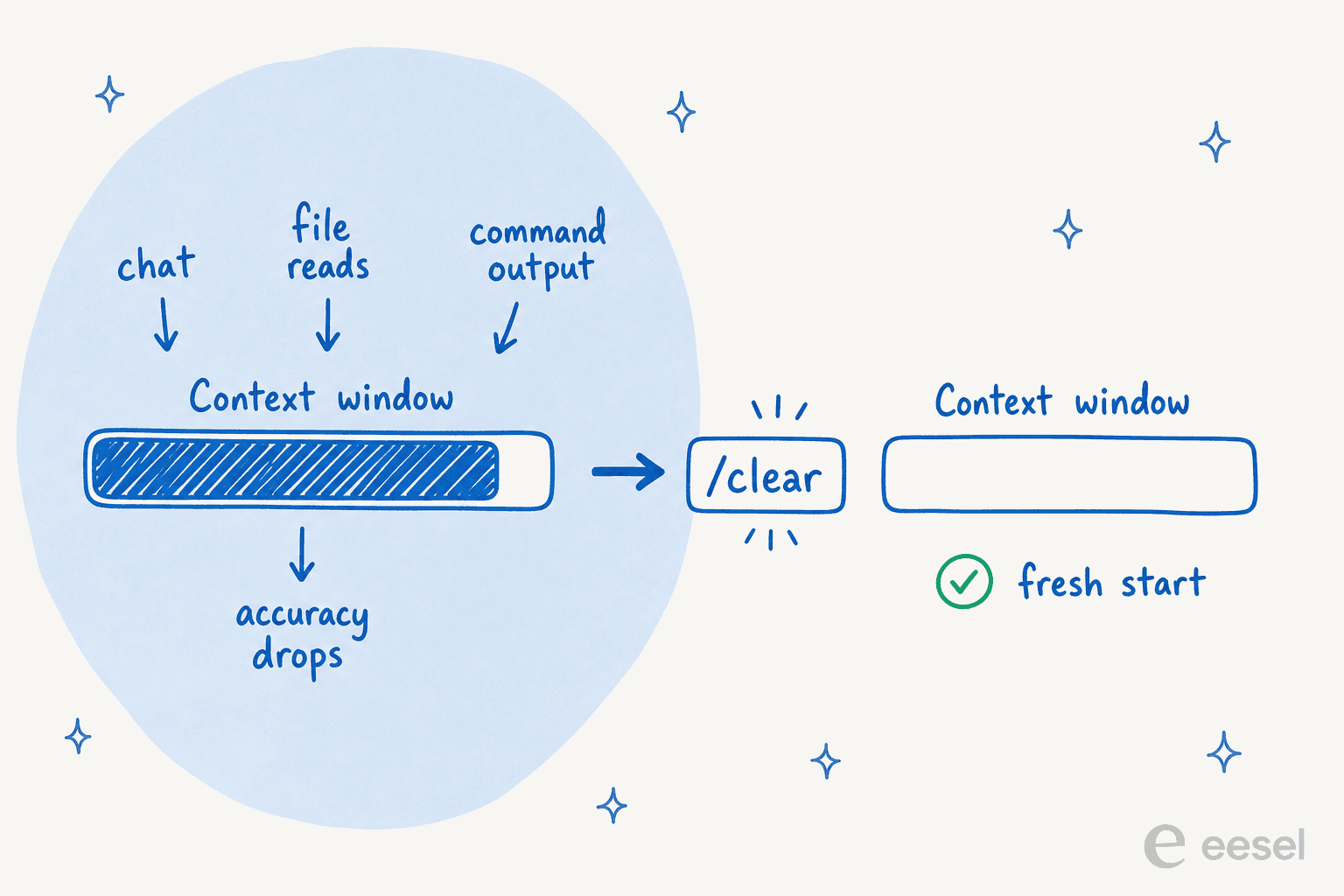
Also verwalte es bewusst:
/clearzwischen nicht zusammenhängenden Aufgaben. Das ist das Wichtigste. Tierney nennt es die „Nuklear-Option, großzügig zwischen Features verwenden." Ein frisches Fenster mit einem präzisen Prompt schlägt ein langes, voller Sackgassen./compact <Anweisungen>wenn du weitermachen, aber Überflüssiges kürzen möchtest, zum Beispiel/compact Fokus auf die API-Änderungen.- An Subagenten delegieren. Das Untersuchen einer großen Codebasis füllt dein Fenster mit Dateilektüren. Ein Subagent erledigt diese Lektüre in seinem eigenen Fenster und berichtet nur die Zusammenfassung. „Da Kontext deine fundamentale Einschränkung ist, sind Subagenten eines der mächtigsten verfügbaren Werkzeuge", sagt Anthropic. Sage einfach „Verwende einen Subagenten, um zu untersuchen, wie wir Token-Aktualisierungen handhaben." Unser Leitfaden zu Claude Code-Subagenten, die du bauen kannst, hat mehr Muster.
Wenn du genau sehen möchtest, was dein Fenster frisst, visualisiert /context, was geladen ist, einschließlich welcher verbundenen Werkzeuge die Token-Fresser sind.
Schnell korrigieren und wissen, wann man neu anfangen muss
Anthropic ist klar, dass „die besten Ergebnisse aus engen Feedback-Schleifen kommen." Du wartest nicht, bis Claude einen falschen Weg beendet hat, um dann alles nochmal zu erklären. Die Korrekturwerkzeuge:
Escstoppt Claude mitten in der Aktion. Der Kontext bleibt erhalten, sodass du sofort umlenken kannst.Esc Esc(oder/rewind) öffnet das Rewind-Menü, um einen früheren Konversations- oder Code-Zustand wiederherzustellen.- „Mach das rückgängig" lässt Claude seine eigenen Änderungen zurücksetzen.
Hier gibt es einen Ton-Hinweis, der wichtiger ist, als er klingt: Korrigiere es wie einen Kollegen, nicht wie eine Suchmaschine. Du tippst nicht die gesamte Anfrage neu, du sagst einfach, was falsch ist, zum Beispiel „Das ändert die öffentliche API, behalte die Signatur bei", und Claude passt nur das an. Und die Heuristik, auf die ich mich am stärksten verlasse: Wenn du Claude mehr als zweimal zu demselben Problem korrigiert hast, ist der Kontext mit fehlgeschlagenen Ansätzen verschmutzt. Führe /clear aus und starte neu mit einem besseren Prompt, der das Gelernte einbaut. Eine saubere Sitzung übertrifft fast immer eine lange, die angesammelte Korrekturen trägt.
Schreibe eine CLAUDE.md: der Prompt, den du nur einmal schreibst
Alles bisher war pro Sitzung. Eine CLAUDE.md-Datei ist der Teil deines Prompts, der bestehen bleibt. Claude liest sie am Anfang jeder Konversation, also ist das der Ort, an dem der ständige Kontext deines Projekts lebt: die Build-Befehle, die es nicht raten kann, deine Code-Style-Regeln, Repo-Etikette, die Entwicklungsumgebungs-Besonderheiten, die Tücken. Das Hilfe-Center nennt es „das Briefing, das du einem fähigen neuen Teammitglied an ihrem ersten Morgen geben würdest."
Führe /init aus, um einen Startpunkt aus deinem Projekt zu generieren, und halte ihn dann schlank. Anthropics Warnung ist eindringlich: „Aufgeblähte CLAUDE.md-Dateien veranlassen Claude, deine eigentlichen Anweisungen zu ignorieren." Frage für jede Zeile: „Würde das Entfernen davon Claude einen Fehler machen lassen?" Wenn nicht, streiche es. Füge eine Regel hinzu, wenn Claude etwas zweimal falsch macht, bereinige vierteljährlich und committe die Datei, damit das gesamte Team beiträgt. Die vollständige Konfigurationsgeschichte, einschließlich wo die Datei lebt und wie sie über Verzeichnisse hinweg zusammengeführt wird, findest du in unserem Claude Code-Konfigurationsleitfaden und der settings.json-Referenz. Für wiederholbare Workflows erstreckt sich dieselbe Logik auf Slash-Befehle.
Die Prompting-Gewohnheiten, die still deine Tokens verschwenden
Die meisten verschwendeten Sitzungen entstehen durch eine Handvoll wiederholbarer Fehler. Anthropic nennt fünf, und die Lösung für jeden ist eine Prompting-Gewohnheit:
| Fehlermuster | Die Lösung |
|---|---|
| Küchen-Sinken-Sitzung: eine Aufgabe, dann eine unzusammenhängende, dann zurück, alles in einem Fenster | /clear zwischen nicht zusammenhängenden Aufgaben |
| Immer wieder korrigieren: Kontext mit fehlgeschlagenen Versuchen verschmutzt | Nach zwei fehlgeschlagenen Korrekturen /clear und einen schärferen Prompt schreiben |
| Überspecifizierte CLAUDE.md: so lang, dass Claude die Hälfte ignoriert | Gnadenlos kürzen, stehende Regeln in Hooks umwandeln |
| Vertrauen-dann-Verifizieren-Lücke: plausibler Code, der Edge-Cases verpasst | Immer eine Prüfung geben; wenn du es nicht verifizieren kannst, shippe es nicht |
| Endlose Erkundung: ein nicht eingeschränktes „Untersuche" liest Hunderte von Dateien | Eng eingrenzen oder an einen Subagenten weiterleiten |
Der Meta-Punkt, mit dem Anthropic schließt, ist es wert zu behalten: Dies sind Ausgangspunkte, keine Gesetze. Manchmal solltest du den Kontext ansammeln lassen (wenn du tief in einem harten Problem steckst), den Plan überspringen (bei explorativer Arbeit), oder einen vagen Prompt werfen (um zu sehen, wie es interpretiert, bevor du einschränkst). Beachte, was passiert, wenn die Ausgabe großartig ist, und frage warum, wenn es Probleme gibt. So baust du die Intuition auf, die keine Checkliste ersetzen kann. Wenn du einen kuratierten Satz möchtest, sammelt unsere Zusammenstellung von Claude Code Best Practices die, die den Kontakt mit echten Projekten überlebt haben.
Was das mit KI zu tun hat, die Support-Tickets beantwortet
Hier ist das, was ich nicht erwartet hatte, als ich anfing, Claude Code zu verwenden: Die Prompting-Disziplin ist dieselbe Disziplin, die wir verwenden, um KI auf eine Live-Support-Warteschlange zu setzen. Gib dem Agenten den richtigen Kontext. Schränke ein, was er berühren darf. Lass es verifizieren, bevor es handelt. Schnell korrigieren und die Lektion festhalten.
Ich habe diese Reihenfolge auf die harte Tour gelernt. Früh haben wir zugesehen, wie selbstsicher klingende Bots stillschweigend falsche Antworten an Kunden weitergaben, weshalb wir jetzt jeden Rollout gegen die historischen Tickets eines Unternehmens simulieren, bevor eine einzige Live-Antwort rausgeht. Das ist der Planungsmodus für Support: die Welt lesen, vorschlagen, wie du damit umgehst, Genehmigung einholen, dann handeln. Als Gridwise es ausführte, löste der Agent 73% ihrer Tier-1-Anfragen im ersten Monat, und die Ergebnisse zeigten sich während einer 7-tägigen Testphase. Die Zahl kam vom Setup, nicht von einem intelligenteren Modell.
Wenn du Inhalte auf dieselbe Weise schreibst, gilt die Parallele auch für KI-Schreiben: Der eesel AI Blog-Schreiber ist unter der Haube ein Agent, den du briefst und verifizierst, anstatt ein Chat-Fenster, mit dem du ringst.
Probiere eesel aus
eesel AI setzt dieselbe agentische Disziplin auf deiner Helpdesk ein. Du verbindest deine bestehenden Tools (Zendesk, Freshdesk, HubSpot, Gorgias, Slack und 100+ mehr), und der Agent lernt am ersten Tag aus deinen vergangenen Tickets und Hilfedokumentation. Der Teil, der direkt auf alles oben Genannte abbildet: Du konfigurierst es in einfacher Sprache und führst es in der Simulation gegen Tausende deiner echten vergangenen Tickets aus, bevor es jemals einem Kunden antwortet, sodass du genau siehst, was es gesagt hätte und wo es eskaliert hätte.

Es ist dieselbe Lektion wie das Prompten von Claude Code, auf deine Support-Warteschlange gerichtet: Der Agent ist nur so gut wie der Kontext und die Leitplanken, die du ihm gibst. Du kannst eesel ausprobieren kostenlos, ohne Kreditkarte, und es gegen deine eigene Geschichte laufen sehen, bevor du es einem Kunden vertraust.
Häufig gestellte Fragen
Wie schreibe ich einen guten Prompt für Claude Code?
@ auf die betreffenden Dateien, füge den genauen Fehler ein und gib Claude eine Möglichkeit, seine eigene Arbeit zu überprüfen (einen Test oder Build). Das Wichtigste beim Prompten von Claude Code ist Präzision: „Schreibe einen Test für foo.py, der den ausgeloggten Edge-Case abdeckt, keine Mocks“ schlägt „Füge Tests für foo.py hinzu“ jedes Mal. Mehr dazu in den Claude Code Best Practices.Was ist eine CLAUDE.md-Datei und brauche ich eine?
CLAUDE.md ist eine Markdown-Datei, die Claude am Anfang jeder Sitzung liest: deine Build-Befehle, Code-Style-Regeln und Projekt-Besonderheiten. Es ist der Teil deines Prompts, den du nur einmal schreibst. Führe /init aus, um einen Startpunkt zu generieren, halte ihn kurz und committe die Datei, damit das Team sie teilt. Die vollständige Mechanik findest du in unserem Claude Code settings.json-Leitfaden und der Konfigurationsübersicht.Warum wird Claude Code bei langen Sitzungen schlechter?
/clear zwischen nicht zusammenhängenden Aufgaben aus, um es zurückzusetzen. Eine saubere Sitzung mit einem präziseren Prompt schlägt fast immer eine lange, mit fehlgeschlagenen Versuchen überladene Sitzung.Sollte ich den Planungsmodus für jede Claude Code-Aufgabe verwenden?
Ist das Prompten eines KI-Coding-Agenten dasselbe wie das Prompten eines KI-Support-Agenten?

Article by
Rama Adi Nugraha
Rama is a software engineer at eesel AI with two years of experience writing about B2B SaaS, AI tools, and customer support technology. Based in Bali, Indonesia, he brings a developer's perspective to product comparisons — cutting through marketing copy to what the integrations and APIs actually do.





