
Ever typed a question to an AI chatbot and felt that slight, awkward pause before it starts spitting out an answer? It’s a tiny delay, but it’s enough to remind you that you’re talking to a machine. A company called Groq is on a mission to erase that pause entirely, making AI interactions feel as fluid and natural as talking to a person.
While many companies in the AI world are focused on building bigger and more complex models, Groq is tackling a different, equally important problem: speed. They're not just making AI a bit faster; they're aiming for a level of performance that changes what's even possible with real-time AI.
If you've seen the name pop up and wondered what all the excitement is about, you're in the right place. We're going to break down what Groq is, how its unique technology works, who it’s for, and some of the real-world limitations you should know about.
What is Groq?
Let's get the basics down. Groq is an American AI chip company started by Jonathan Ross, who was one of the minds behind Google's own custom AI chip, the Tensor Processing Unit (TPU). Instead of trying to do everything, Groq focuses on one specific thing: building hardware for AI inference.
So what’s this "inference" thing they're so focused on? Think of it as the "performance" part of AI. After a massive AI model has been trained on tons of data, inference is the process of actually using that model to get an answer. Every time you ask a chatbot a question or get an AI-powered recommendation, that’s an inference task.
And no, before you ask, this has nothing to do with Elon Musk’s "Grok" AI model. Different spelling, completely different companies. It's a common mix-up, so let's get that out of the way. Groq's goal is to make AI inference incredibly fast and affordable, which could open the door to a whole new wave of real-time AI tools.
The technology behind Groq: How it achieves record-breaking speed
So how does Groq pull off this incredible speed? It’s not just a minor tweak on existing tech; it’s a whole different way of thinking about the problem. The magic is in their custom-built chip, the Language Processing Unit, or LPU.
Unlike a GPU (Graphics Processing Unit), which is more of a powerful, general-purpose tool that's been adapted for AI, the LPU was designed from day one with a single purpose: running language models as fast as humanly possible.
The real trick is how they handle memory. Most chips you're familiar with, like GPUs, use a type of memory called DRAM. Think of DRAM as a massive library bookshelf. It can hold a ton of books (data), but you have to walk over to get what you need, which takes a little time.
Groq decided to go a different route, using something called SRAM. SRAM is like having the exact book you need open right on your desk. Access is instant, but your desk can only hold a few books at a time. This is the same super-fast memory used for tiny caches on your computer’s main processor. It’s unbelievably quick, which means the LPU almost never has to wait for data.
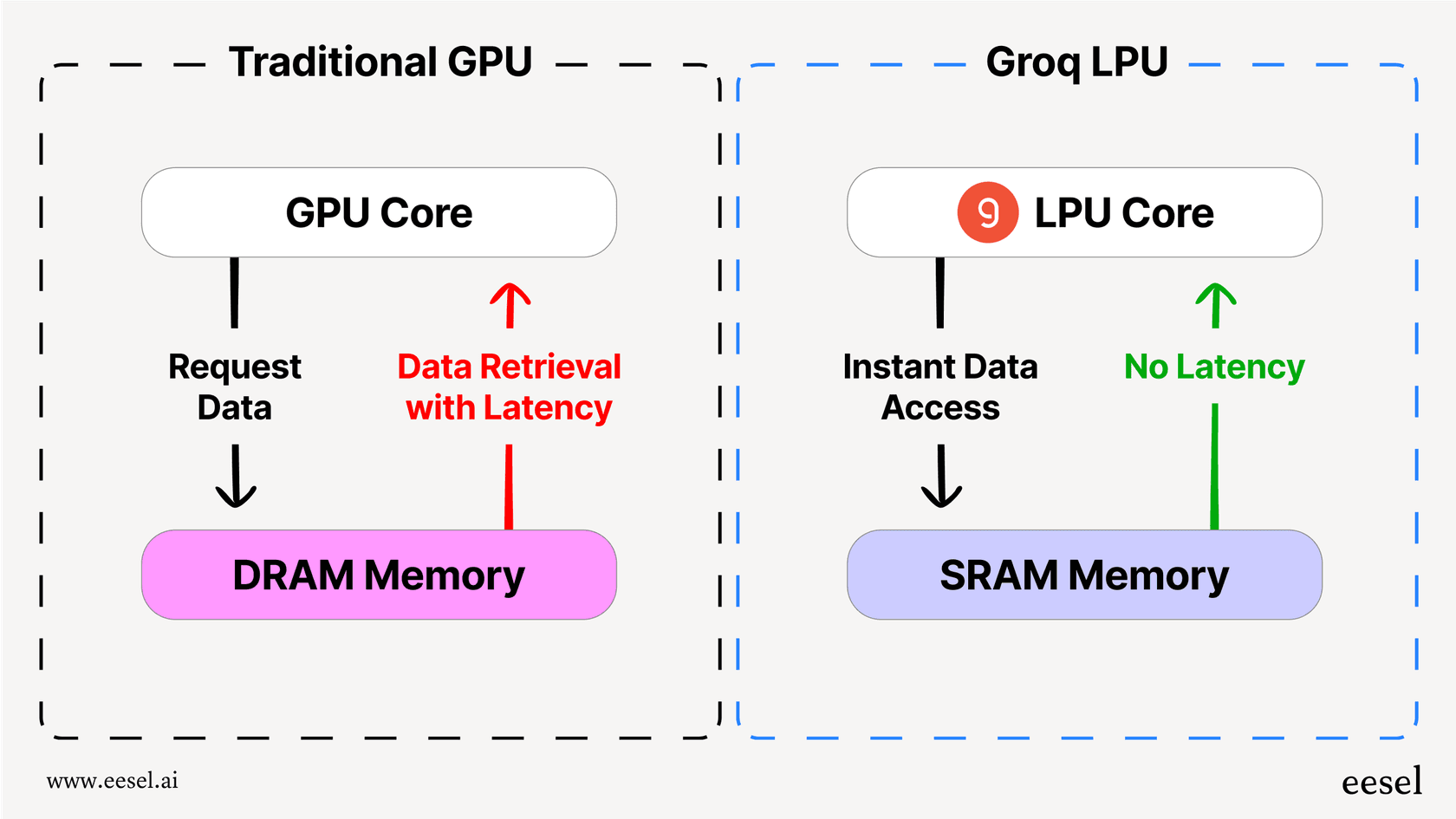
But, as with most things in life, there's a catch. A big one. SRAM is incredibly expensive and doesn't hold much data. While a single high-end GPU can store a large chunk of an AI model in its memory, one LPU can only hold a tiny fraction. To run a modern language model, Groq has to chain together hundreds, sometimes thousands, of these LPU chips. This setup is what gives their hardware its lightning-fast inference capabilities, but it also makes it wildly expensive to build yourself.
Use cases and benefits: Who is Groq for?
Okay, so it's ridiculously fast. But who actually needs this kind of speed? Turns out, a lot of people. Anywhere a delay can ruin the experience, Groq has a place.
Here are a few spots where this speed makes a huge difference:
-
Real-time customer support: Instead of a chatbot that feels like you're filling out a slow web form, you get one that can keep up with a real conversation. This eliminates the frustrating pauses that make customers give up and ask for a human agent.
-
Live data analysis: Think of high-pressure fields like finance or even Formula 1 racing, where Groq has a partnership with McLaren. When you need to analyze data and make decisions in a split second, that instant response time is a serious advantage.
-
Interactive applications: For anyone using AI-powered coding assistants or creative tools, the speed of feedback is everything. When the AI can keep up with your train of thought, it feels less like a tool and more like a collaborator.
For businesses and developers using their API, the advantages are pretty straightforward:
-
Unbelievable Speed: Groq can generate hundreds of tokens per second, creating a conversational flow that’s hard to find anywhere else.
-
Potential for Lower Costs at Scale: While buying the hardware is out of reach for most, if your company makes a huge number of AI requests, the efficiency of the LPU could lead to a lower cost for each one.
-
Easy to Adopt: They made their API compatible with OpenAI's standards, which was a smart move. It means developers can often switch their apps over to Groq by changing just a few lines of code.
But raw speed is only half the story. A fast AI that gives the wrong answer is just a fast way to frustrate customers. For something like customer support, that speed needs intelligence and direction. That's where a platform like eesel AI comes into the picture. It acts as the brain, telling the super-fast engine what to do by connecting it to the right information and guiding its actions.
Limitations and considerations of using Groq
Now, it's not all sunshine and rainbows. Groq's approach is highly specialized, and that comes with some serious things to keep in mind before you jump in.
The high price of Groq hardware
This is the biggest hurdle. Unless you're using their cloud API, the cost of setting up your own Groq hardware is staggering. We're not talking a little pricey; we're talking "you need a multi-million dollar budget" pricey just to get started. This effectively puts self-hosting out of reach for almost everyone except the largest corporations.
Limited model selection on GroqCloud
If you're using the GroqCloud API, you have to pick from the models they've decided to support. You can't just grab your favorite open-source model and run it on their system. This is a key difference compared to using general-purpose cloud GPUs, which give you a lot more freedom to experiment.
Groq is for inference, and only inference
These LPU chips are built for one job: running AI models fast. They are not designed for training a new model from scratch or even fine-tuning an existing one. This means any company using Groq will still need access to traditional GPU hardware for their model development, making it one specialized tool in a larger toolkit, not a complete replacement.
This highlights why it's smart to build your AI tools on a more flexible platform. You don't want to be locked into a single engine. Think of it this way: while Groq might be the Formula 1 engine you use for speed, a platform like eesel AI is the car itself. It lets you connect to your helpdesk like Zendesk or Intercom, pulls in knowledge from places like Confluence, and gives you the controls to steer the AI's personality and behavior. You can even test it on past support tickets to see how it would perform, all before it ever talks to a real customer.
Groq pricing: API vs. on-premise
So, how much does this all cost? Groq has two main ways you can pay, and they're worlds apart.
The GroqCloud API
This is the path most people will take. You pay as you go based on how many tokens (pieces of words) you process. It's the standard model for AI APIs.
| Model | Input Price (per 1M tokens) | Output Price (per 1M tokens) |
|---|---|---|
| Llama3-8b-8192 | $0.05 | $0.10 |
| Llama3-70b-8192 | $0.59 | $0.79 |
| Mixtral-8x7b-32768 | $0.24 | $0.24 |
| Gemma-7b-it | $0.10 | $0.10 |
Note: Prices can change, so it's always best to check the official Groq pricing page for the most current rates.
On-premise Groq deployment
This is the "if you have to ask, you probably can't afford it" option. It's for huge companies with very specific security or performance needs that justify building their own Groq cluster. While there's no public price list, industry chatter suggests you're looking at millions of dollars for a basic setup, with large-scale deployments costing much, much more.
Groq: Speed is just the beginning
So, what's the bottom line on Groq? They’ve found a very specific problem, AI inference speed, and have thrown everything they have at solving it. Their LPU chips, with their all-SRAM design, are in a class of their own for real-time responses. For any app that needs to feel truly conversational, Groq is a name to know.
But it’s not a magic bullet for every AI problem. The high cost of buying the hardware yourself and the limited model selection on their API mean it's a specialized tool for a specialized job. For most of us, Groq will be the engine behind a specific feature that needs to be lightning-fast.
Still, the need for instant AI is only going to get bigger as it works its way into more of our tools. Groq is definitely a company to watch, but harnessing that speed effectively takes more than just a fast chip.
Put the speed of Groq to work with a smarter AI agent
Fast hardware is great, but for customer support, the real goal is to get fast, accurate answers that actually solve problems. You need a system that can take that raw speed and channel it into something genuinely helpful.
Ready to build an AI support agent that’s both incredibly fast and completely in your control? Start your free trial with eesel AI today.
Frequently asked questions
What exactly is Groq and what problem does it solve in AI?
Groq is an American AI chip company that specializes in building hardware for extremely fast AI inference. Its mission is to eliminate the latency (pause) in AI interactions, making them feel instantaneous and natural.
How does Groq's LPU technology achieve such record-breaking speeds for AI inference?
Groq achieves its speed through its custom-built Language Processing Unit (LPU), designed specifically for language models. Unlike GPUs, LPUs use super-fast SRAM memory for instant data access, minimizing wait times and maximizing processing speed.
For what types of applications is Groq most beneficial, and why does its speed matter there?
Groq is most beneficial for applications requiring real-time AI responses, such as interactive customer support, live data analysis in critical fields like finance, and fluid AI-powered creative tools. Its speed eliminates frustrating delays, making AI feel like a seamless collaborator.
Is Groq the same company as the one behind Elon Musk's "Grok" AI model?
No, Groq (with a 'q') is a completely different company from Elon Musk's "Grok" AI model. Groq is an AI chip company focused on hardware for fast inference, while "Grok" is an AI chatbot model.
What are the main limitations a business should consider before adopting Groq's technology?
Key limitations include the extremely high cost of on-premise Groq hardware, limiting its accessibility to most businesses. Additionally, if using the GroqCloud API, you are limited to their supported models, and the chips are solely for inference, not for training AI models.
What is the typical pricing model for using Groq, and are there different options?
Groq offers two main options: the GroqCloud API, where you pay as you go based on tokens processed, which is generally accessible. For on-premise Groq solutions, the cost is significantly higher, often in the millions of dollars, reserved for large corporations with specific needs.
Can I use Groq's LPU chips to train new AI models or fine-tune existing ones?
No, Groq's LPU chips are specifically designed and optimized for AI inference, the process of using a trained model to generate responses. They are not built for training new models from scratch or for fine-tuning existing ones; those tasks still require traditional GPU hardware.





