カスタマーサポートにおける品質保証(QA: Quality Assurance)は、誰もが重要であると認識しているものの、正しく実行できているチームはごくわずかです。マネージャーが少数のチケットを抜き打ちチェックし、エージェントはやり取りから数週間後にフィードバックを受け取り、プロセスが実際に何かを改善しているのかどうか誰もが疑問に思っている、という状況をご存知でしょう。
ここで、耳の痛い事実をお伝えします。ほとんどのチームは、顧客との会話の約2%を手動でレビューしているにすぎません。つまり、チームの作業の98%は評価されていないことになります。コーチングの決定、パフォーマンスレビュー、トレーニングへの投資を、現実を反映していない可能性のあるごくわずかなサンプルに基づいて行っているのです。
このガイドでは、実際に機能する品質保証ワークフローをZendeskで構築する方法を説明します。ゼロから始める場合でも、既存のプロセスを改善したい場合でも、自動スコアリングの設定方法、意味のあるスコアカードの作成方法、QAの洞察を実際のコーチング成果に結び付ける方法を学ぶことができます。
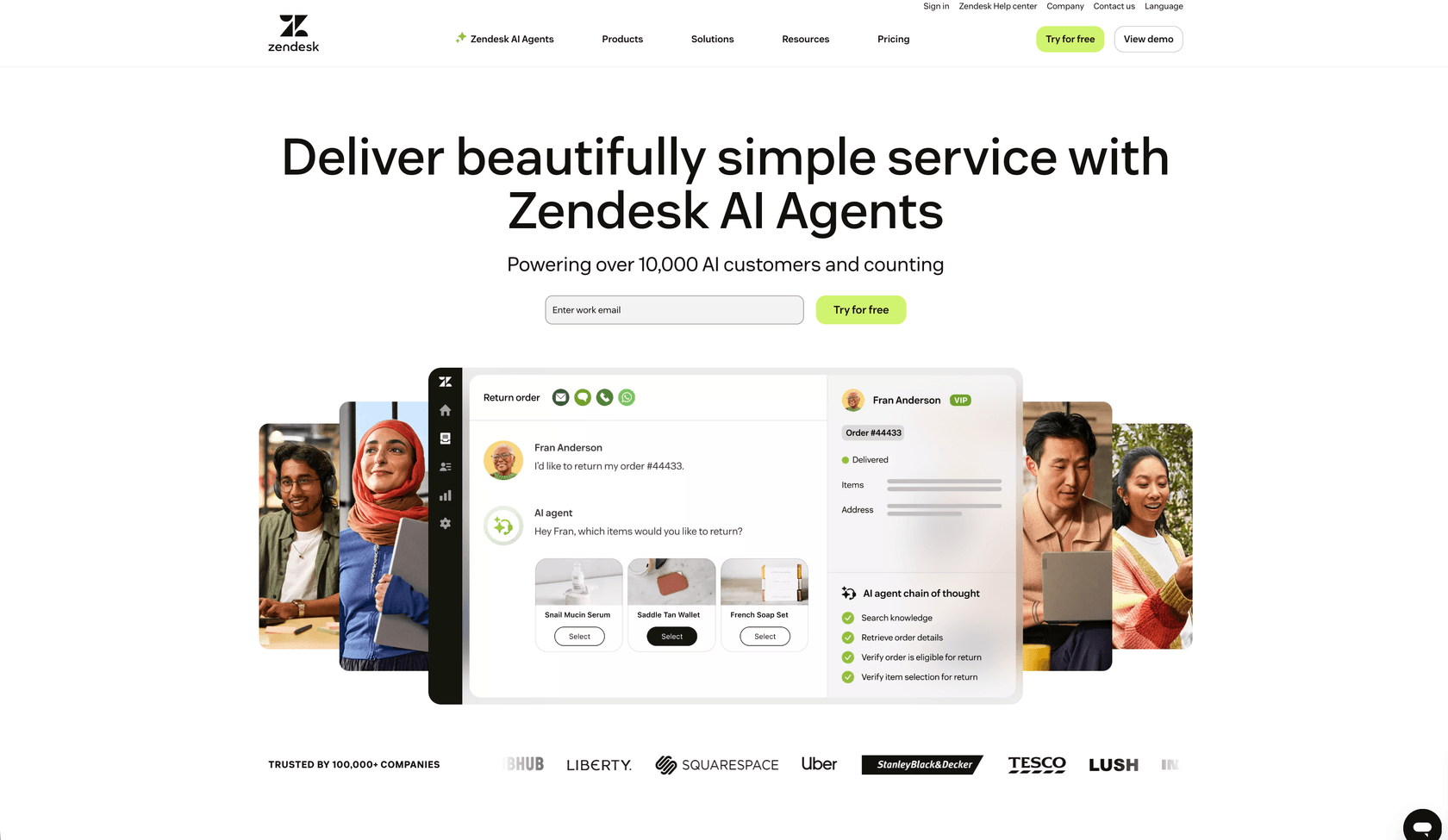
Zendeskにおける品質保証ワークフローとは?
品質保証ワークフローとは、顧客とのやり取りを評価して、顧客の基準を満たしていることを確認し、改善の機会を特定する体系的なプロセスです。Zendeskでは、これはチケット、チャット、メール、通話をレビューして、定義された基準に対するエージェントのパフォーマンスをスコアリングすることを意味します。
主なアプローチは2つあります。
- 手動QA: 人間のレビュー担当者がやり取りを読み聞きし、ルーブリックに基づいてスコアリングします。これにより、ニュアンスのあるフィードバックが得られますが、時間がかかり、範囲が限られています。
- 自動QA: AIがすべての会話を基準に照らして分析し、問題を特定し、パフォーマンスを自動的にスコアリングします。これにより、100%のカバレッジが得られますが、人間の監視と組み合わせるのが最適です。
2%問題は現実です。ごく一部の会話しかレビューしていない場合、大規模にしか現れないパターン、繰り返される問題、コーチングの機会を見逃してしまいます。また、偏ったサンプリングのリスクもあります(レビュー担当者は当然、代表的なチケットではなく、興味深いチケットや問題のあるチケットに引き寄せられます)。
Zendeskの設定をAI機能で強化したいチームのために、Zendeskと直接統合して、既存のワークフローを補完する継続的な学習とフィードバックループを提供します。
ZendeskでQAの基盤を構築する
構成に入る前に、QAプロセス全体を導く基盤を確立する必要があります。これは、「品質」がチームにとって実際に何を意味するのかを定義することを意味します。
品質基準を定義する
Zendesk QAは、次の7つの主要な側面から会話を評価します。
- 解決策: 回答は正しく、徹底的でしたか?
- 文法: スペル、句読点、単語の選択
- トーン: カスタマーサービスの声の質
- 共感: 継続的な顧客関係のサポート
- パーソナライズ: 顧客固有のニーズに合わせた対応
- 内部プロセスの遵守: 品質基準の遵守
- 一歩先を行く: 直接的な解決策を超える追加サービス
基準は、ビジネス目標と一致している必要があります。解約を減らそうとしている場合は、共感と思いやりがより重要になる可能性があります。コンプライアンスが重要な場合は、プロセス遵守が不可欠になります。
QAスコアカードを作成する
スコアカードは、会話の評価方法を定義します。Zendesk QAには、一般的なサポート基準を網羅したすぐに使用できるスコアカードが付属していますが、カスタマイズすることをお勧めします。
AIに何を探すべきかをわかりやすい英語で伝えることで、完全に新しいカテゴリを作成できます。たとえば、小売ブランドはエージェントが払い戻しリクエストを正しく処理しているかどうかを確認し、SaaS企業は技術的な正確性を優先する場合があります。
主なスコアカード機能は次のとおりです。
- ビジネスの優先順位を反映するための基準の重み付け
- 合格するために特定の基準を重要としてマークする
- チームまたはチャネルごとに異なるスコアカードを使用する
- チケットタイプに基づいて適用される条件付きスコアカードの設定

レビューチームの構造を構築する
QAの責任は通常、いくつかの役割に分散されます。
- ピアレビュー担当者: 新しい同僚のチケットを毎週数時間かけてレビューする上級エージェント
- QAスペシャリスト: 体系的なチケット監査を実行する専任アナリスト
- チームリーダー: コーチングの会話のためにチームのチケットのサブセットをレビューする
- QAマネージャー: 品質フレームワークを設計し、キャリブレーションを通じて一貫性を確保する
キャリブレーションは非常に重要です。複数のレビュー担当者に同じチケットをスコアリングさせて、「良い」とは何かについて全員が連携していることを確認します。これがないと、スコアは意味がなくなります。
QAワークフローを段階的に実装する
実際の設定プロセスについて説明しましょう。各ステップは前のステップに基づいて構築されているため、先に進まないでください。
ステップ1:Zendesk QA設定を構成する
上部のバーにあるZendesk製品アイコンからZendesk QAにアクセスし、[品質保証]を選択します。チケットの会話データは自動的にインポートされ、4〜6時間ごとに同期されます。
まず、ヘルプデスクの接続設定を確認します。選択したコンテンツをフィルタリングしてプライバシーを保護し(クレジットカード番号や個人情報など)、非アクティブな会話のデータ保持期間を設定できます。

ステップ2:自動スコアリングのためにAutoQAを設定する
AutoQAは、会話の100%を分析するエンジンです。基準に基づいてやり取りをスコアリングし、チケットの2%のレビューから完全なカバレッジに移行します。
ビジネスにとって重要な自動スコアリングカテゴリをアクティブにします。すぐに使用できるオプションには、共感、トーン、理解が含まれます。自然言語プロンプトを使用して、カスタムカテゴリを作成することもできます。
AIはすべてのやり取りをスコアリングし、疲れたり偏見を持ったりしない一貫した評価を提供します。ただし、AutoQAは問題を特定し、パフォーマンスをスコアリングすることを忘れないでください。複雑な状況での人間の判断に代わるものではありません。
ステップ3:リスク検出のためにスポットライトを構成する
スポットライトは、人間の注意が必要な会話を自動的に強調表示します。チケットをランダムにサンプリングする代わりに、価値が高く、重要で、有益なケースに焦点を当てることができます。
事前定義されたスポットライトは、以下を識別します。
- 解約リスクのある会話
- 外れ値と異常なパターン
- エスカレーション
- 例外的なサービス(肯定的な強化も重要です)
- 通話中の無音
- 行き詰まった会話ループ
自然言語を使用してカスタムスポットライトを作成することもできます。AIに何を探すべきかを伝えれば、一致する会話にフラグを立ててレビューします。
ステップ4:人間のレビュープロセスを確立する
AIは大部分の評価を処理しますが、人間はニュアンスとコンテキストを追加します。レビューワークフローを設定します。
フラグが立てられた会話を適切なレビュー担当者に自動的にルーティングする割り当てを作成します。各エージェントに対して、週に5つの技術チケットをレビューするなど、特定の基準に基づいて定期的なタスクを設定できます。
レビュー担当者は、AIが生成したスコアに手動でメモを追加したり、トレーニング目的で会話を固定したり、AIの評価に同意しない場合にスコアに異議を唱えたりできます。このフィードバックループは、システムが時間の経過とともに改善されるのに役立ちます。
ステップ5:レポートとコーチングワークフローを設定する
QAダッシュボードは、チームリーダーに、チーム全体の最近のパフォーマンス、フラグが立てられたやり取り、コーチングの機会のスナップショットを提供します。エージェントは、自分のスコアを確認したり、質の高いやり取りの例を表示したり、Zendeskで直接フィードバックを受け取ったりできます。
特定の会話とメモを正式なコーチングセッションにバンドルして、QAデータをコーチングに接続します。コーチングがいつ行われたか、エージェントがフィードバックを確認したかどうかを追跡します。これにより、評価と改善の間のループが閉じます。
ZendeskにおけるAIを活用したQA自動化
AIは人間のレビュー担当者に取って代わるものではありません。彼らを強化するものです。以下に、その組み合わせが実際にどのように機能するかを示します。
AutoQAは、すべての会話をスコアリングすることでボリュームの問題を処理し、何も見過ごされないようにします。これにより、手動のみのプログラムを悩ませるサンプリングバイアスが解消されます。
スポットライトはノイズをフィルタリングし、実際に人間の注意が必要な会話の5〜10%を表面化します。レビュー担当者は、ランダムに選択されたチケットではなく、影響の大きいコーチングの機会に時間を費やします。
リアルタイムのQAインサイトは、ライブのやり取り中にエージェントワークスペースに直接表示されます。エージェントは、会話がまだ開いている間に品質ガイダンスを確認できるため、問題がエスカレートするのを防ぎます。
音声QAは、音声テキスト変換を使用して、電話の通話を分析して、沈黙、コンプライアンスの遵守、品質マーカーを確認します。これにより、QAプログラムが書面によるチャネルを超えて拡張されます。
さらに進みたいチームのために、当社のAIエージェントは、修正とフィードバックから継続的に学習します。応答を編集したり、内部メモを残したりすると、システムはその学習をすぐに組み込みます。再トレーニングサイクルや再アップロードは必要ありません。ZendeskでAIがどのように機能するかと、品質保証の自動化に対するさまざまなアプローチについて詳しく読むことができます。
QAの成功を測定する:追跡する主要なメトリック
測定しないものは改善できません。QAプログラムを評価するには、次のメトリックに焦点を当ててください。
内部品質スコア(IQS: Internal Quality Score): 評価されたすべての会話のスコアカード評価から計算された主要な品質メトリック。
CSAT相関: QAスコアと顧客満足度評価を比較します。低いQAスコアは、低いCSATと相関している必要があります。そうでない場合、スコアカードが間違ったものを測定している可能性があります。
一般的な失敗カテゴリ: エージェントが最も苦労している側面を追跡します。チーム全体の共感スコアが一貫して低い場合は、個別のコーチングではなく、共感トレーニングが必要です。
エージェントのパフォーマンスの傾向: 個々のエージェントのスコアが時間の経過とともにどのように変化するかを監視します。目標は改善であり、完璧ではありません。
時間の節約: 自動スコアリングと手動レビューでチームが節約できる時間を測定します。ほとんどのチームは、レビュー時間が80%削減されることを確認しています。
QAを実装するときに避けるべき一般的な間違い
数十のチームがQAワークフローを設定するのを支援した後、同じ間違いが繰り返し発生しているのを見てきました。
レビューする会話が少なすぎる: サンプリングトラップは、誤った自信を与えます。いくつかの問題を見つけて修正し、完了したと思います。一方、何百もの問題のあるやり取りが見過ごされています。
キャリブレーションなしの一貫性のないスコアリング: 同じチケットをスコアリングする3人のレビュー担当者は、同様のスコアに到達する必要があります。そうでない場合、データは信頼できません。
否定的なフィードバックのみに焦点を当てる: QAは、間違いを見つけるだけではありません。例外的なサービスを認識し、優れた仕事の例を共有します。
QAをコーチングに接続しない: アクションのないスコアは単なる数字です。低いスコアはすべて、コーチングの会話またはトレーニング介入をトリガーする必要があります。
遅延したフィードバックループ: やり取りから数週間後に配信されたフィードバックは、影響を失います。数週間ではなく、数日以内のフィードバックを目指してください。
Zendesk品質保証ワークフローのスケーリング
小さく始めて拡大します。1つのチームまたはチャネルから開始し、スコアカードを改良し、組織全体に展開する前に価値を証明します。
スケーリングするときは、以下を検討してください。
- チャネルの追加: QAを音声、ソーシャルメディア、AIエージェントのやり取りに拡張します
- チーム固有のスコアカード: チームごとに異なる基準が必要です。請求チームとテクニカルサポートチームは、同じスコアカードを使用しないでください。
- 部門横断的な洞察: QAデータは、サポートチームを超えて製品の問題、プロセスのギャップ、トレーニングのニーズを明らかにします。製品、エンジニアリング、運用と洞察を共有します。
目標は完璧なスコアではありません。一貫した改善と品質が重要な文化です。
AIを活用したツールで品質保証を合理化
効果的なQAワークフローを構築するには、時間と反復が必要です。成功するチームは、それを1回限りの設定ではなく、継続的なプロセスとして扱います。
Zendeskの設定をAI機能で補完したい場合は、フィードバックから継続的に学習する統合を提供しています。AIが生成したスコアを修正したり、コーチングノートを残したりすると、システムはすぐに改善されます。再トレーニングサイクルを待つ必要はありません。
当社のアプローチでは、カスタマイズにわかりやすい英語の指示を使用します。サポートのやり取りで何を探すべきかをAIに伝えれば、特定の基準とビジネスコンテキストに適応します。
料金をご覧になり、品質保証プロセスの合理化にどのように役立つかをご覧ください。
よくある質問
Share this article

Article by
Stevia Putri
Stevia Putri is a marketing generalist at eesel AI, where she helps turn powerful AI tools into stories that resonate. She’s driven by curiosity, clarity, and the human side of technology.