Comment utiliser les clés d'idempotence de l'API Zendesk pour éviter les tickets en double
Stevia Putri
Dernière modification March 2, 2026
Les pannes de réseau arrivent. Votre requête d'API expire, votre client la relance donc. Sans protections appropriées, cette nouvelle tentative crée un deuxième ticket, un troisième ticket, et soudain, votre client a trois demandes d'assistance identiques dans le système. Les clés d'idempotence résolvent ce problème en garantissant que les requêtes répétées avec la même clé produisent le même résultat sans créer de doublons.
Si vous créez des intégrations avec l'API Zendesk, comprendre les clés d'idempotence n'est pas facultatif. C'est essentiel pour les systèmes prêts pour la production qui traitent les données réelles des clients.
Que sont les clés d'idempotence et pourquoi sont-elles importantes ?
Une clé d'idempotence est un identifiant unique que les clients incluent avec les requêtes d'API. Lorsque votre serveur reçoit une requête, il vérifie s'il a déjà vu cette clé. Si la clé est nouvelle, la requête est traitée normalement et le résultat est stocké. Si la clé existe, le résultat stocké est renvoyé sans réexécuter l'opération.
Le concept vient des mathématiques, où une opération idempotente produit le même résultat, qu'elle soit exécutée une ou plusieurs fois. En termes d'API, la publication d'un ticket avec la même clé d'idempotence cinq fois devrait créer exactement un ticket et renvoyer la même réponse à chaque fois.
Voici pourquoi cela est important pour Zendesk en particulier. La création de tickets est une opération d'écriture avec des effets secondaires. Chaque ticket déclenche des notifications, des règles de routage et potentiellement des minuteurs SLA (Service Level Agreement). La création de tickets en double ne fait pas que surcharger votre système. Cela gaspille le temps des agents, déroute les clients qui reçoivent plusieurs accusés de réception et fausse vos mesures.
Scénarios réels où l'idempotence vous sauve :
- Webhooks de paiement Votre processeur de paiement envoie un webhook pour créer un ticket pour les transactions échouées. Le webhook relance en cas de délai d'attente. Sans idempotence, chaque nouvelle tentative crée un nouveau ticket.
- Importations en bloc Vous migrez des tickets d'un ancien système. Le script d'importation rencontre une erreur de réseau et redémarre. Sans idempotence, vous obtenez des enregistrements en double.
- Applications mobiles Un utilisateur appuie deux fois sur Soumettre en raison d'un décalage. Sans idempotence, ils créent deux tickets.
La création manuelle d'une logique de nouvelle tentative fiable est complexe. Vous devez suivre les requêtes qui ont réussi, gérer les échecs partiels et réconcilier l'état entre les systèmes distribués. Les clés d'idempotence poussent cette complexité vers la couche API où elle appartient.
Si vous cherchez à automatiser la création de tickets sans gérer vous-même ces cas extrêmes, notre agent IA gère automatiquement l'idempotence dans le cadre de son intégration Zendesk.
Comment fonctionne l'implémentation de la clé d'idempotence de Zendesk
Zendesk implémente l'idempotence via un simple en-tête HTTP. Pour l'utiliser, incluez un en-tête Idempotency-Key avec une valeur unique dans votre requête :
Idempotency-Key: {clé_unique}
La valeur peut être n'importe quelle chaîne de caractères jusqu'à 255 caractères. Zendesk recommande d'utiliser des UUID ou d'autres identifiants à haute entropie.
Lorsque vous faites une requête avec une clé d'idempotence, la réponse de Zendesk inclut un en-tête x-idempotency-lookup :
x-idempotency-lookup: missC'est la première fois que cette clé est vue. La requête est traitée normalement.x-idempotency-lookup: hitCette clé a été utilisée auparavant. Zendesk renvoie la réponse mise en cache de la requête originale.
Voici la partie critique. Zendesk stocke les clés d'idempotence pendant 2 heures. Après cette fenêtre, une requête avec la même clé sera traitée comme nouvelle. Cela signifie que votre logique de nouvelle tentative doit tenir compte de la fenêtre d'expiration. Si vous relancez une requête d'hier, vous créerez un doublon.
Zendesk valide également que les requêtes avec la même clé d'idempotence ont des paramètres identiques. Si vous envoyez la même clé avec un sujet ou une description différente, vous obtenez une erreur 400 :
{
"error": "IdempotentRequestError",
"description": "Les paramètres de la requête ne correspondent pas à la clé d'idempotence donnée"
}
Cela empêche l'utilisation abusive accidentelle des clés à travers différentes opérations. Cela signifie également que vous devez générer une nouvelle clé pour chaque opération distincte, et ne pas réutiliser les clés à travers différents tickets.
Limitation importante : la clé d'idempotence n'est pas stockée dans le cadre du ticket. Lorsque vous récupérez un ticket plus tard, vous ne verrez pas quelle clé a été utilisée pour le créer. Si vous avez besoin de suivre cette corrélation, stockez-la dans votre propre système.
Tous les points de terminaison de l'API Zendesk ne prennent pas en charge l'idempotence. Le cas d'utilisation principal est la création de tickets (POST /api/v2/tickets.json). Consultez la documentation officielle pour le point de terminaison spécifique que vous utilisez.
Implémentation des clés d'idempotence dans votre code
Passons en revue une implémentation pratique. Nous utiliserons Python avec la bibliothèque requests, mais le modèle s'applique à n'importe quel langage.
Étape 1 : Générer des clés d'idempotence uniques
Générez votre clé d'idempotence avant de faire la première requête, pas pendant les nouvelles tentatives. La clé doit être unique par opération logique.
import uuid
idempotency_key = str(uuid.uuid4())
request_context = {
'idempotency_key': idempotency_key,
'payload': ticket_data,
'attempt': 0
}
Utilisez UUIDv4 ou une autre chaîne aléatoire avec au moins 128 bits d'entropie. Évitez les modèles prévisibles comme les horodatages, les ID séquentiels ou les hachages de la charge utile seule. Ceux-ci peuvent entrer en collision ou être devinés.
Étape 2 : Ajouter l'en-tête à vos requêtes d'API
Incluez la clé d'idempotence dans vos en-têtes de requête avec votre authentification.
Exemple Python :
import requests
import os
subdomain = os.getenv('ZENDESK_SUBDOMAIN')
email = os.getenv('ZENDESK_EMAIL')
api_token = os.getenv('ZENDESK_API_TOKEN')
url = f'https://{subdomain}.zendesk.com/api/v2/tickets.json'
auth = (f'{email}/token', api_token)
headers = {
'Content-Type': 'application/json',
'Idempotency-Key': idempotency_key
}
data = {
'ticket': {
'subject': 'Notification d'échec de paiement',
'comment': {'body': 'La méthode de paiement du client a été refusée'},
'requester': {'email': 'customer@example.com'}
}
}
response = requests.post(url, json=data, auth=auth, headers=headers)
Exemple cURL :
curl https://yourcompany.zendesk.com/api/v2/tickets.json \
-d '{"ticket": {"subject": "Ticket de test", "comment": {"body": "Ceci est un test"}}}' \
-H "Content-Type: application/json" \
-H "Idempotency-Key: 550e8400-e29b-41d4-a716-446655440000" \
-u your@email.com/token:your_api_token \
-X POST
Exemple JavaScript/Node.js :
const response = await fetch('https://company.zendesk.com/api/v2/tickets.json', {
method: 'POST',
headers: {
'Content-Type': 'application/json',
'Authorization': 'Basic ' + Buffer.from(`${email}/token:${token}`).toString('base64'),
'Idempotency-Key': idempotencyKey
},
body: JSON.stringify(ticketData)
});
Étape 3 : Gérer les réponses et les nouvelles tentatives
Votre logique de nouvelle tentative doit vérifier le statut et les en-têtes de la réponse pour déterminer s'il faut relancer.
import time
def create_ticket_with_retry(ticket_data, max_retries=3):
idempotency_key = str(uuid.uuid4())
for attempt in range(max_retries + 1):
headers = {
'Content-Type': 'application/json',
'Idempotency-Key': idempotency_key
}
response = requests.post(
url,
json=ticket_data,
auth=auth,
headers=headers
)
# Vérifier si c'était une réponse mise en cache
lookup_status = response.headers.get('x-idempotency-lookup')
if lookup_status == 'hit':
print(f"La requête a été mise en cache (tentative {attempt + 1})")
# Cas de succès
if response.status_code == 201:
return response.json()
# Incompatibilité d'idempotence - ne pas relancer, c'est une erreur de logique
if response.status_code == 400 and 'IdempotentRequestError' in response.text:
raise ValueError(f"Incompatibilité de clé d'idempotence : {response.json()['description']}")
# Limite de débit atteinte - attendre et relancer
if response.status_code == 429:
retry_after = int(response.headers.get('Retry-After', 60))
time.sleep(retry_after)
continue
# Erreurs de serveur - relancer avec un repli exponentiel
if response.status_code in [500, 502, 503, 504]:
if attempt < max_retries:
backoff = (2 ** attempt) + (hash(idempotency_key) % 1000 / 1000)
time.sleep(backoff)
continue
# Erreurs de client (4xx) - ne pas relancer
response.raise_for_status()
raise Exception("Nombre maximal de nouvelles tentatives dépassé")
Points clés pour votre logique de nouvelle tentative :
- Réutiliser la même clé d'idempotence à travers toutes les nouvelles tentatives de la même opération logique
- Ne pas relancer sur les erreurs 400 avec
IdempotentRequestErrorcela indique un bogue de logique dans votre code - Respecter les limites de débit (429) en utilisant l'en-tête
Retry-After - Utiliser un repli exponentiel pour les erreurs de serveur afin d'éviter de surcharger l'API
Pour plus de détails sur la structure de l'API de tickets Zendesk, consultez notre guide sur la création de tickets Zendesk en utilisant l'API.
Meilleures pratiques pour les implémentations de production
Une fois que vous avez les bases qui fonctionnent, considérez ces pratiques prêtes pour la production.
Stratégies de stockage des clés. Pour les systèmes à volume élevé, vous pouvez suivre les clés d'idempotence dans votre propre base de données ou cache. Cela vous permet de :
- Détecter si une clé est sur le point d'expirer (fenêtre de 2 heures de Zendesk)
- Vérifier quelles opérations ont réussi ou échoué
- Implémenter une logique de déduplication personnalisée au-delà de celle de Zendesk
Redis est un choix populaire pour cela. Définissez un TTL (Time To Live) légèrement plus court que la fenêtre de 2 heures de Zendesk pour éviter les cas extrêmes :
import redis
redis_client = redis.Redis(host='localhost', port=6379)
redis_client.setex(f"zendesk:idempotency:{key}", 5400, response_data)
Gérer les requêtes simultanées. Si deux requêtes avec la même clé d'idempotence arrivent simultanément, Zendesk en traitera une et renverra le résultat mis en cache pour l'autre. Cependant, votre client pourrait voir des conditions de concurrence. Implémentez la déduplication des requêtes au niveau de votre couche d'application si cela vous préoccupe.
Empreinte digitale de la requête. Pour détecter les bogues où vous réutilisez accidentellement une clé avec des paramètres différents, hachez la charge utile de la requête et stockez-la avec la clé d'idempotence. Avant d'envoyer, vérifiez que le hachage correspond :
import hashlib
import json
def get_request_fingerprint(payload):
return hashlib.sha256(json.dumps(payload, sort_keys=True).encode()).hexdigest()
fingerprint = get_request_fingerprint(ticket_data)
store_key_with_fingerprint(idempotency_key, fingerprint)
if get_fingerprint_for_key(idempotency_key) != fingerprint:
raise ValueError("La charge utile a changé pour la clé d'idempotence existante")
Journalisation et surveillance. Suivez l'utilisation de la clé d'idempotence dans vos journaux :
- Enregistrez la clé et le statut
x-idempotency-lookuppour chaque requête - Alertez sur les taux élevés de réponses
hit(peut indiquer des nouvelles tentatives excessives) - Surveillez les
IdempotentRequestError(indique des bogues)
Tester votre implémentation. Écrivez des tests qui vérifient votre logique d'idempotence :
def test_duplicate_request_returns_same_ticket():
key = str(uuid.uuid4())
# Première requête
response1 = create_ticket(ticket_data, idempotency_key=key)
ticket_id = response1['ticket']['id']
# Deuxième requête avec la même clé
response2 = create_ticket(ticket_data, idempotency_key=key)
assert response2['ticket']['id'] == ticket_id
assert response2.headers['x-idempotency-lookup'] == 'hit'
Erreurs courantes et comment les éviter
Même les développeurs expérimentés font ces erreurs lors de l'implémentation de l'idempotence.
Utilisation de modèles de clés prévisibles. Les horodatages, les ID séquentiels ou les hachages simples de la charge utile peuvent entrer en collision ou être devinés. Utilisez toujours des valeurs cryptographiquement aléatoires comme UUIDv4.
Génération de nouvelles clés lors de la nouvelle tentative. Le but est d'utiliser la même clé pour les nouvelles tentatives. Si vous générez un nouvel UUID à chaque tentative, vous créerez des doublons au lieu de les empêcher.
Ignorer l'expiration de 2 heures. Si votre logique de nouvelle tentative s'étend sur plus de 2 heures (peut-être en raison de pannes prolongées), votre clé d'idempotence ne fonctionnera plus. Pour les processus de longue durée, implémentez votre propre couche de déduplication.
Ne pas gérer les erreurs d'incompatibilité de paramètres. Lorsque vous obtenez une IdempotentRequestError, c'est généralement un bogue dans votre code. Vous réutilisez une clé avec des données différentes. Enregistrez-les de manière agressive et corrigez la cause première.
Mise en cache incorrecte des réponses d'erreur. Certaines implémentations mettent en cache toutes les réponses, y compris les erreurs 5xx. Cela signifie qu'une erreur de serveur transitoire est « bloquée » et que toutes les nouvelles tentatives renvoient la même erreur. Ne mettez en cache que les réponses réussies (codes de statut 2xx).
Conditions de concurrence dans les environnements simultanés. Sans verrouillage approprié, deux threads pourraient tous les deux vérifier l'existence d'une clé, tous les deux voir qu'elle est manquante et tous les deux envoyer des requêtes. Utilisez des opérations atomiques ou des verrous distribués si vous traitez des volumes élevés.
Automatiser la création de tickets sans la complexité
La création et la maintenance des intégrations d'API prennent du temps. Vous devez gérer l'authentification, la logique de nouvelle tentative d'erreur, la limitation du débit, l'idempotence et la maintenance continue à mesure que les API changent.
Si votre objectif est d'automatiser la création de tickets plutôt que de créer une intégration personnalisée, demandez-vous si vous avez réellement besoin d'écrire du code. Des outils comme eesel AI peuvent gérer la création de tickets et les réponses sans aucun travail de développement.
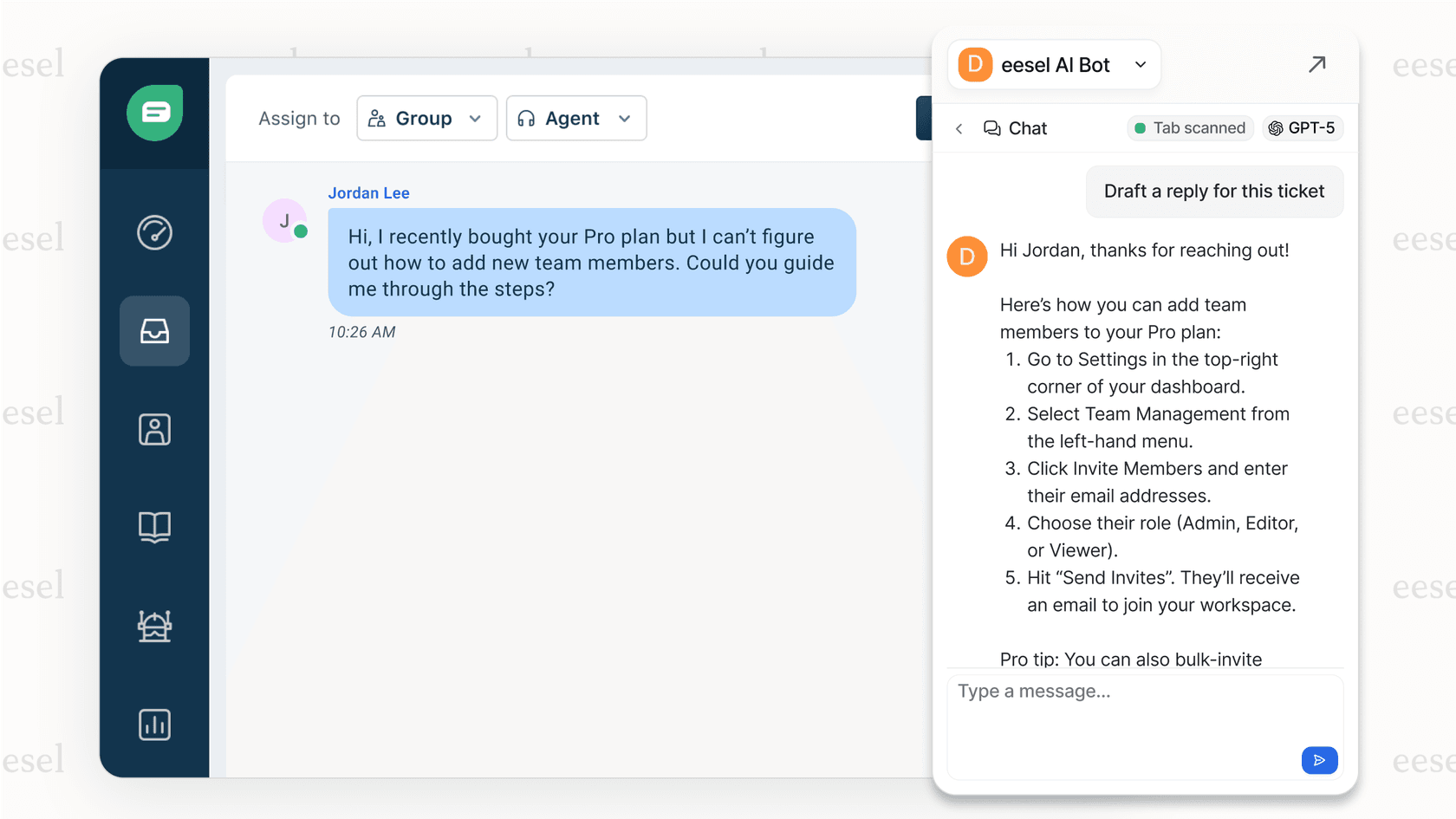
Voici la différence. Avec l'approche API, vous écrivez des scripts pour créer des tickets auxquels les humains répondront. Avec un agent IA, vous formez un système pour comprendre votre entreprise et gérer l'ensemble du cycle de vie des tickets, de la création à la résolution. Vous le connectez à votre compte Zendesk, et il apprend de vos anciens tickets, des articles du centre d'aide et des macros.
Le modèle de déploiement progressif signifie que vous commencez par l'IA qui rédige des réponses pour examen, puis vous passez à l'automatisation complète à mesure qu'elle fait ses preuves. Pour les équipes qui cherchent à réduire le volume de tickets plutôt qu'à simplement automatiser la création, cela donne souvent des résultats plus rapides que le développement d'API personnalisées.
Notre AI Copilot peut également vous aider en rédigeant des réponses que vos agents examinent avant de les envoyer, vous offrant ainsi une assistance IA sans la complexité de la création d'une logique de nouvelle tentative idempotente.
Foire aux questions
Share this article

Article by
Stevia Putri
Stevia Putri is a marketing generalist at eesel AI, where she helps turn powerful AI tools into stories that resonate. She’s driven by curiosity, clarity, and the human side of technology.