Was ist Groq (und warum funktioniert die Preisgestaltung hier anders)?
Groq entwickelt keine Modelle – stattdessen betreiben sie die Modelle anderer (Llama, Qwen, Mistral, Whisper, OpenAIs Open-Weight-Modelle) auf eigener Custom-Hardware: der Language Processing Unit, kurz LPU. 2016 von ehemaligen Google-TPU-Ingenieuren gegründet, sammelten sie $750 Mio. bei einer Bewertung von $6,9 Mrd. im September 2025 ein und bedienen heute über 2 Mio. Entwickler. Das McLaren-F1-Team nutzt Groq für Echtzeit-Rennanalysen – kein Anwendungsfall, bei dem „meistens schnell" ausreichend ist.
Das Preismodell ist einfach: Abrechnung pro Token, keine Kosten für Leerlaufinfrastruktur, keine elastischen Preissprünge. Groqs offizielle Aussage dazu: „Andere Inferenz-Anbieter erhöhen die Kosten ohne Vorwarnung. Einige verstecken sich hinter elastischer Preisgestaltung. Groqs Preise sind linear und vorhersehbar, ohne versteckte Kosten oder Leerlaufinfrastruktur."

Warum die LPU die Kostengleichung verändert
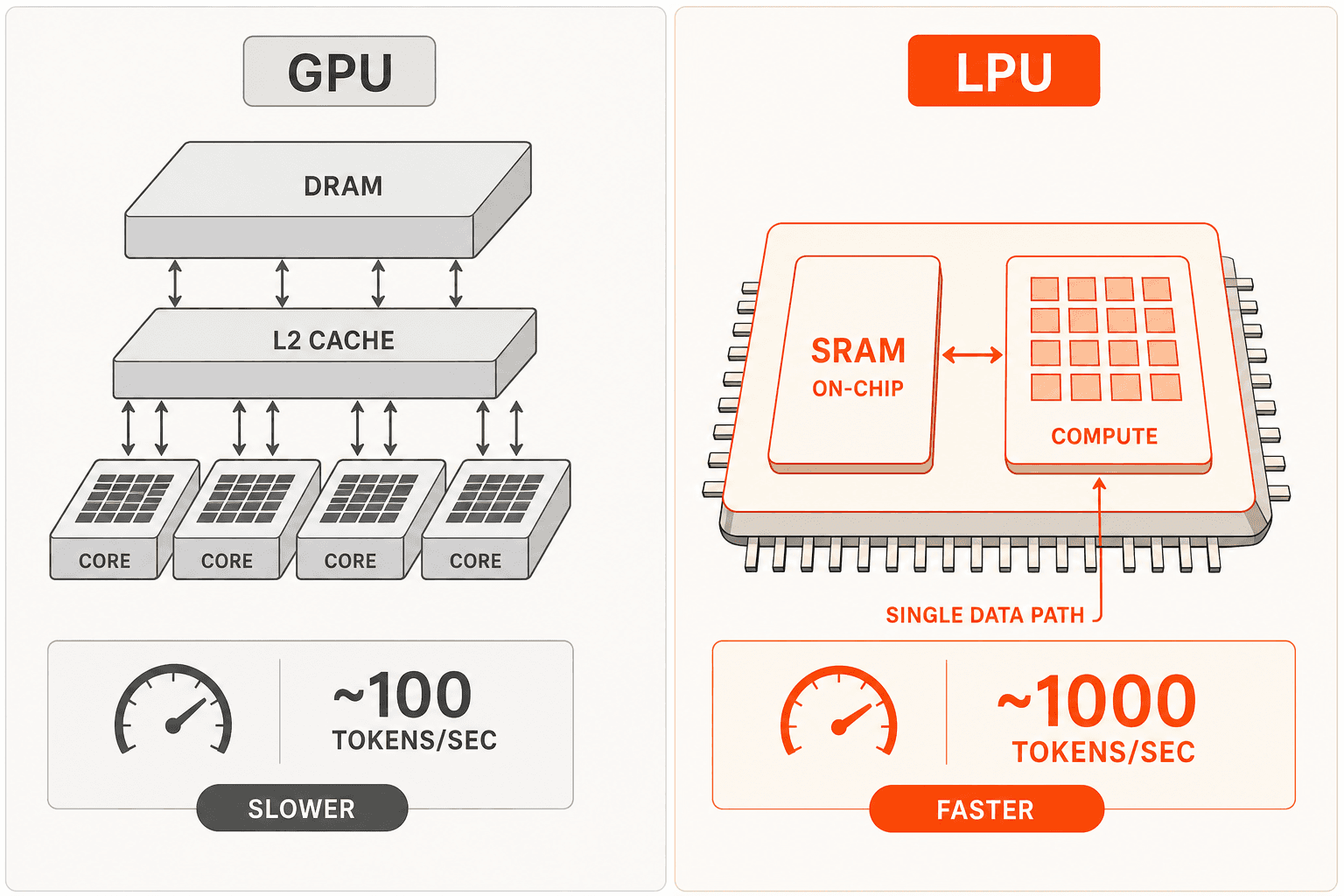
GPUs wurden für das Training entwickelt: große externe DRAM/HBM-Speicherhierarchien, dynamisches Scheduling, Cache-Kohärenzprotokolle. Diese Eigenschaften sind vorteilhaft, wenn Matrixoperationen beim Training auf Tausenden von Kernen parallelisiert werden. Für die Inferenz passen sie schlecht: Die sequenzielle Schichtausführung hat eine geringe arithmetische Intensität, und Speicherzugriffe dominieren die Latenz.
Die LPU-Architektur verfolgt einen anderen Ansatz. On-Chip-SRAM dient als primärer Gewichtsspeicher – kein Cache, sondern der primäre Speicher. Groqs eigens entwickelter Compiler plant jede Operation bis auf einzelne Taktzyklen vor, bevor die Ausführung beginnt, und eliminiert so den Overhead des dynamischen Schedulings vollständig. Das RealScale-Chip-to-Chip-Protokoll lässt hunderte von LPUs als einen einzigen Kern für Tensor-Parallelismus agieren. Da jede Operation statisch geplant ist, kann Groq Pipeline-Parallelismus auf Tensor-Parallelismus aufsetzen: Schicht N+1 beginnt mit der Verarbeitung, während Schicht N noch abgeschlossen wird – etwas, das GPU-dynamisches Scheduling nicht zuverlässig leisten kann.
Das praktische Ergebnis: GPT OSS 20B bei 1.000 Token pro Sekunde. Llama 3.1 8B bei 560–840 TPS. Llama 3.3 70B bei 280–394 TPS. Typische GPU-basierte Cloud-APIs erzielen bei vergleichbaren Modellen 50–100 TPS. Wenn dieselbe Hardware mehr Anfragen pro Sekunde bedient, verteilen sich die Fixkosten auf mehr Token – so wird $0,05 pro 1 Mio. Eingabe-Token kommerziell tragfähig.

Groqs kostenloses Kontingent: was tatsächlich enthalten ist
Das kostenlose Kontingent erfordert keine Kreditkarte und wird durch Rate Limits – nicht durch ein monatliches Token-Budget – geregelt. Hier ist genau aufgelistet, was jedes Modell im kostenlosen Tarif bietet:
| Modell | RPM | TPM | Anfragen/Tag |
|---|---|---|---|
llama-3.1-8b-instant | 30 | 6.000 | 14.400 |
llama-3.3-70b-versatile | 30 | 12.000 | 1.000 |
meta-llama/llama-4-scout-17b-16e-instruct | 30 | 30.000 | 1.000 |
openai/gpt-oss-20b | 30 | 8.000 | 1.000 |
openai/gpt-oss-120b | 30 | 8.000 | 1.000 |
qwen/qwen3-32b | 60 | 6.000 | 1.000 |
groq/compound | 30 | 70.000 | 250 |
whisper-large-v3 | 20 | - | 2.000 Audio-Anfragen |
whisper-large-v3-turbo | 20 | - | 2.000 Audio-Anfragen |
(RPM = Anfragen pro Minute, TPM = Token pro Minute. Quelle: Groq Rate-Limits-Dokumentation)
Zwei Punkte überraschen Entwickler hier. Erstens: Rate Limits gelten auf Organisationsebene, nicht pro API-Schlüssel. Fünf Schlüssel zu erstellen ergibt keine 150 RPM – es bleiben weiterhin 30 RPM, die über das gesamte Konto geteilt werden. Zweitens: Prompt-Caching-Token werden nicht auf Rate Limits angerechnet – ein spürbarer Vorteil bei langen System-Prompts, die sich über viele Aufrufe wiederholen.
Die TPM-Limits pro Minute sind in der Regel die eigentliche Engstelle, nicht die täglichen Anfragegrenzen. Ein 2.000-Token-Prompt verbraucht ein Drittel des TPM-Budgets von Llama 8B in einem einzigen Aufruf.
„Ich nutze die Groq-API ununterbrochen und denke ständig: ‚Wie habe ich immer noch keine Art von Free-Tier-Limit erreicht?'" – @ctatedev, Mai 2024
Das Whisper-Freikontingent ist der herausragende Mehrwert. Artificial Analysis bestätigte, dass Groq zu den günstigsten Whisper Large v3-Anbietern gehört. Im kostenlosen Tarif stehen täglich 2.000 Audio-Transkriptionsanfragen zur Verfügung – bei Batching mit dem Mindestwert von 10 Sekunden pro Anfrage entspricht das etwa 2 Stunden Audio pro Stunde. OpenAI berechnet $0,36/Stunde für Whisper-Zugang; Groqs kostenpflichtiger Tarif berechnet $0,04–$0,111/Stunde, sodass das kostenlose Kontingent ein großzügiger Einstieg ist.
„Ihre kostenlose API für Speech-to-Text ist erstaunlich, so großzügig, absolut empfehlenswert." – Trustpilot-Rezension

Groq-API-Preise: jedes Modell
Alle Preise in USD pro 1 Mio. Token (Eingabe / Ausgabe), sofern nicht anders angegeben. Quelle: Groq-Preisseite.
Text-/LLM-Modelle
| Modell | Modell-ID | Geschwindigkeit (TPS) | Kontext | Eingabe $/1M | Ausgabe $/1M | Status |
|---|---|---|---|---|---|---|
| Llama 3.1 8B Instant | llama-3.1-8b-instant | 560–840 | 128k | $0,05 | $0,08 | Produktion |
| GPT OSS 20B | openai/gpt-oss-20b | 1.000 | 128k | $0,075 | $0,30 | Produktion |
| Llama 4 Scout (17Bx16E) | meta-llama/llama-4-scout-17b-16e-instruct | 594–750 | 128k | $0,11 | $0,34 | Vorschau |
| GPT OSS 120B | openai/gpt-oss-120b | 500 | 128k | $0,15 | $0,60 | Produktion |
| Qwen3 32B | qwen/qwen3-32b | 400–662 | 131k | $0,29 | $0,59 | Vorschau |
| Llama 3.3 70B Versatile | llama-3.3-70b-versatile | 280–394 | 128k | $0,59 | $0,79 | Produktion |
| Kimi K2 Instruct | moonshotai/kimi-k2-instruct-0905 | - | - | $1,00 ($0,50 gecacht) | $3,00 | - |
| Llama Prompt Guard 2 22M | meta-llama/llama-prompt-guard-2-22m | - | 512 | $0,03 | $0,03 | Vorschau |
| Llama Prompt Guard 2 86M | meta-llama/llama-prompt-guard-2-86m | - | 512 | $0,04 | $0,04 | Vorschau |
Einige Modellhinweise, die hervorgehoben werden sollten. GPT OSS 20B – OpenAIs Open-Weight-Modell, nicht GPT-4 – läuft mit 1.000 Token pro Sekunde bei $0,075 Eingabe / $0,30 Ausgabe. Das ist gleichzeitig das schnellste Modell der Plattform und eines der günstigsten pro Ausgabe-Token. Llama 4 Scout unterstützt Bildeingaben (bis zu 20-MB-Dateien), befindet sich aber noch in der Vorschau – nicht für den Produktionseinsatz geeignet. Kimi K2 ist das einzige Modell, bei dem Prompt-Caching explizit in der Preiszeile ausgewiesen ist: $0,50 pro 1 Mio. gecachte Eingabe-Token gegenüber $1,00 ohne Cache.
Die Prompt-Guard-Modelle ($0,03–$0,04 pro 1 Mio. Token) sind Sicherheits-Klassifikatoren, die Prompt-Injection und Jailbreak-Versuche erkennen – nützlich für kundenorientierte KI-Anwendungen, die eine leichtgewichtige Filterschicht vor dem Hauptmodell benötigen.
Rate Limits im Developer-Tarif
Der Sprung vom kostenlosen Tarif zum Developer-Tarif ist erheblich:
| Modell | Developer-TPM | Developer-RPM |
|---|---|---|
llama-3.1-8b-instant | 250.000 | 1.000 |
llama-3.3-70b-versatile | 300.000 | 1.000 |
openai/gpt-oss-20b | 250.000 | 1.000 |
openai/gpt-oss-120b | 250.000 | 1.000 |
meta-llama/llama-4-scout-17b-16e-instruct | 300.000 | 1.000 |
qwen/qwen3-32b | 300.000 | 1.000 |
whisper-large-v3-turbo | 400.000 ASH | 400 |
groq/compound | 200.000 | 200 |
(Quelle: console.groq.com/docs/models)
Groqs Preise im Vergleich zu OpenAI und anderen Anbietern
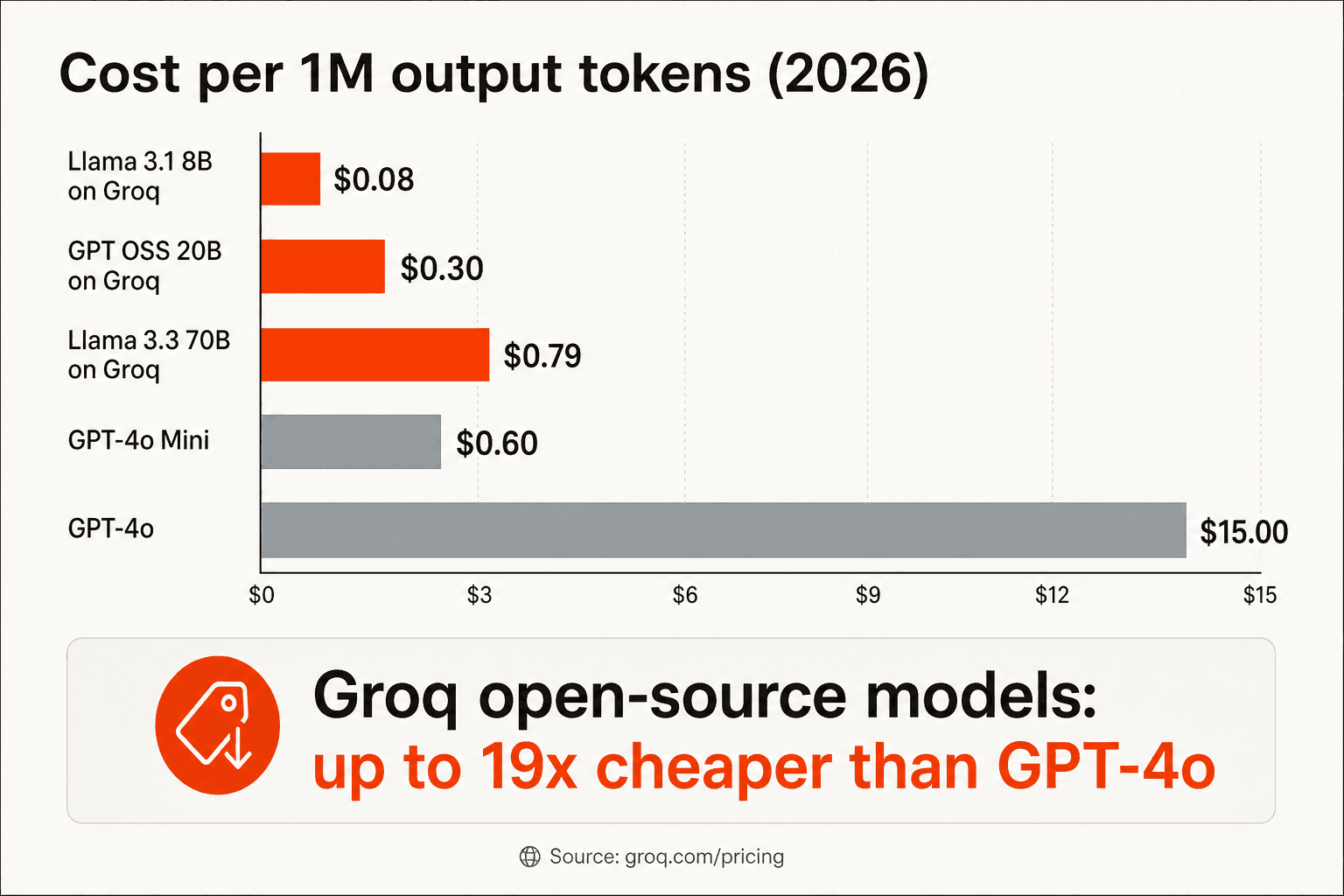
Die in Entwicklerkreisen am häufigsten genannte Zahl ist „10–20-mal günstiger als OpenAI für vergleichbare Open-Source-Modelle." Das ist grob korrekt, mit dem notwendigen Hinweis, dass keine identischen Modelle verglichen werden.
„LLM-Inferenz auf Groq kostet etwa 10-mal weniger als OpenAIs Preise für GPT-4o. Groq ist 10–20-mal günstiger, allerdings für ein etwas weniger leistungsfähiges Modell – Llama 3-70B im Vergleich zu GPT-4o." – Balazs Kocsis, Medium, August 2024
Der ehrlichste Vergleich ist nicht Groq gegen OpenAIs proprietäre Modelle – sondern Groq gegen andere Open-Source-Hosting-Anbieter wie Together AI oder Fireworks AI, die dieselben Modelle betreiben. Dabei ist Groq laut dem Awesome Agents 8-Wochen-Produktionstest bei vergleichbaren Modelltiers 20–50 % günstiger mit deterministischer Tail-Latenz, bei der p99 innerhalb von 15 % des Medians bleibt – ein bedeutender Vorteil gegenüber GPU-Workloads, bei denen Tail-Latenz-Spitzen häufig auftreten.
„Auf Wiedersehen, OpenAI-API. Heute bekommt man dieselbe Grundintelligenz – Llama-3 oder seine Open-Source-Konkurrenten – zu Preisen, die gegen null tendieren, oft unter $0,20 pro Million Token. Das ist eine Preissenkung von 99 % in achtzehn Monaten." – Aparna Pradhan, GoPenAI, Dezember 2025
Das in der Entwickler-Community entstandene Praxis-Denkmodell – zusammengefasst von Jolly Gupta auf LinkedIn (114 Likes, September 2025): Groq für geschwindigkeitskritische und kostensensitive Open-Source-Workloads nutzen, OpenAI wenn GPT-4os Fähigkeiten oder multimodale Tiefe benötigt werden. Die meisten Produktionsstacks verwenden beides.
Groq erschien auch in der Artificial Analysis-Umfrage als einer der Top-5-Inferenzanbieter nach Entwickleradoption – neben OpenAI, Google, Anthropic und Microsoft.
Audio-Preise: Whisper und TTS
Speech-to-Text
Groq betreibt beide Whisper Large v3-Varianten auf LPU-Hardware und liefert Transkriptionen mit 217–228-facher Echtzeit-Geschwindigkeit. Eine Stunde Audio wird in etwa 15 Sekunden verarbeitet.
| Modell | Geschwindigkeitsfaktor | Preis | Max. Dateigröße |
|---|---|---|---|
whisper-large-v3 | 217-fache Echtzeit | $0,111 / Stunde | 100 MB |
whisper-large-v3-turbo | 228-fache Echtzeit | $0,04 / Stunde | - |
Für die meisten Workloads ist Turbo bei $0,04/Stunde die klare Wahl – schneller und 2,8-mal günstiger als das Vollmodell, mit nur marginalen Qualitätsunterschieden bei den meisten Audiodaten. Audio wird mit einem Minimum von 10 Sekunden pro Anfrage abgerechnet, unabhängig von der tatsächlichen Länge – das Zusammenfassen kurzer Clips lohnt sich daher implementierungstechnisch.
OpenAI berechnet $0,36/Stunde für Whisper; Groq bei $0,04/Stunde ist 9-mal günstiger beim Turbo-Modell. Levels.io stellte fest, dass Whisper + TTS auf Groq bereits 2024 „sehr günstig" war; die Preise sind seitdem stabil geblieben.
Text-to-Speech (Vorschau)
Groq hat kürzlich TTS über Canopy Labs' Orpheus-Modelle eingeführt:
| Modell | Preis | Hinweise |
|---|---|---|
canopylabs/orpheus-v1-english | $22,00 / 1 Mio. Zeichen | Englisch, ~100 Zeichen/Sek. |
canopylabs/orpheus-arabic-saudi | $40,00 / 1 Mio. Zeichen | Arabisch (saudischer Dialekt) |
Diese befinden sich noch im Vorschau-Status. Der LPU-Geschwindigkeitsvorteil ist auch hier sichtbar – Orpheus generiert auf Groq mit 100 Zeichen pro Sekunde, was Echtzeit-nahe Sprachanwendungen ermöglicht.

Compound-KI-Systeme: wenn Tools extra kosten
GroqClouds Compound-Systeme – groq/compound und groq/compound-mini – sind agentische Wrapper, die einem Sprachmodell integrierte Websuche und Code-Ausführung ermöglichen. Die Preisgestaltung umfasst Modell-Token-Kosten plus Tool-Nutzung:
| Tool | Preis |
|---|---|
| Einfache Websuche | $5 / 1.000 Anfragen |
| Erweiterte Websuche | $8 / 1.000 Anfragen |
| Website besuchen | $1 / 1.000 Anfragen |
| Code-Ausführung | $0,18 / Stunde |
| Browser-Automatisierung | $0,08 / Stunde |
Das Compound-System läuft mit ~450 TPS bei 131k Kontext. Es ist ein praktischer Einstiegspunkt für agentische KI-Workloads, bei denen die Tool-Use-Orchestrierung an die Plattform delegiert werden soll, anstatt sie selbst zu entwickeln.

Zwei versteckte Rabatte, die es zu kennen gilt
Batch-API: 50 % Rabatt für asynchrone Workloads
Die Batch-API halbiert die Kosten für jedes Modell, indem Jobs asynchron ausgeführt werden. Eine JSONL-Datei (bis zu 50.000 Zeilen, 200 MB) wird eingereicht, die Verarbeitung erfolgt innerhalb von 24 Stunden bis 7 Tagen, und es wird 50 % des Standard-Token-Preises berechnet. Keine Auswirkung auf die Standard-Rate-Limits.
Dies ist die richtige Wahl für: Dokumentenklassifizierungspipelines, Massen-Content-Generierung, nächtliche Datenanreicherung, Content-Moderation in großem Maßstab – alles, bei dem Latenztoleranz einen erheblichen Rabatt einbringt. Die Tool-Nutzung in Compound-Systemen wird weiterhin zu Standardpreisen berechnet.
Prompt-Caching: 50 % Rabatt auf wiederkehrende Präfixe
Prompt-Caching ist automatisch – keine Code-Änderungen, keine zusätzlichen Gebühren. Wenn dasselbe Präfix (ein langer System-Prompt, ein Referenzdokument) sich über mehrere Aufrufe wiederholt, speichert Groq es bis zu 2 Stunden im Cache. Cache-Treffer kosten 50 % des normalen Eingabepreises.
Modelle, die Prompt-Caching unterstützen, und ihre gecachten Preise:
| Modell | Standard-Eingabe | Gecachte Eingabe |
|---|---|---|
openai/gpt-oss-20b | $0,075 / 1M | $0,0375 / 1M |
openai/gpt-oss-120b | $0,15 / 1M | $0,075 / 1M |
moonshotai/kimi-k2-instruct-0905 | $1,00 / 1M | $0,50 / 1M |
Der doppelte Vorteil: Gecachte Token kosten halb so viel und werden nicht auf Rate Limits angerechnet. Für Workloads mit langen System-Prompts – RAG-Pipelines, Dokumenten-Q&A, KI-Kundensupport-Agenten mit großen Wissenskontexten – verlängert dies den effektiven Durchsatz spürbar, ohne dass ein Upgrade der Rate-Limit-Stufe erforderlich ist.
Rate Limits: was passiert, wenn man sie überschreitet
Wenn ein Rate Limit überschritten wird, gibt Groq HTTP 429 mit einem retry-after-Header zurück, der anzeigt, wie viele Sekunden gewartet werden soll. Der Fehlerkörper ist spezifisch:
„Rate limit reached for model
openai/gpt-oss-20b… service tier: on_demand … Limit 200.000 · Used 199.336 · Requested 1.524 · Please try again in 6m 11.52s." – Standard Time Projektmanagement-Tool-Dokumentation, April 2026
Die Antwort-Header enthalten auch x-ratelimit-limit-requests, x-ratelimit-remaining-tokens und x-ratelimit-reset-requests – genug, um präzises exponentielles Backoff ohne Versuch und Irrtum zu implementieren.
Der wichtigste operative Aspekt: Rate Limits gelten pro Organisation und pro Modell. Wenn mehrere Dienste oder Teammitglieder dasselbe Groq-Konto nutzen, teilen sie denselben Limit-Pool. Für Produktions- und Entwicklungsumgebungen sollten separate Organisationskonten verwendet werden, oder Groq kann über console.groq.com/settings/limits wegen höherer Limits für spezifische Workloads kontaktiert werden.
Enterprise-Preise
Es gibt keine öffentliche Enterprise-Preistabelle. Für den Zugang zu Folgendem muss groq.com/enterprise-access kontaktiert werden:
- Höhere Rate Limits für spezifische Workloads
- GroqRack On-Premises-Deployment
- LoRA-feinabgestimmte Modelle
- Exklusive Enterprise-Modelle (Minimax M2.5, Qwen3-VL 32B mit Vision)
- Regionales Deployment und Datenresidenz-Optionen
- SOC 2-, DSGVO- und HIPAA-Compliance-Dokumentation
Zur Verfügbarkeit: Der Awesome Agents Produktionstest maß über 8 Wochen eine Verfügbarkeit von 99,94 % mit p99-Latenz innerhalb von 15 % des Medians – besseres Tail-Verhalten als GPU-basierte Mitbewerber, da das LPU-Scheduling deterministisch ist. Enterprise-SLA-Garantien erfordern eine formelle Vereinbarung.
Die Nachhaltigkeitsfrage
Die meisten Groq-Preisleitfäden lassen dies aus. Hier nicht.
Im September 2024 veröffentlichte Kyle Corbitt auf X, dass er von einem Groq-Mitarbeiter gehört hatte, die Token-Kosten des Unternehmens seien „1–2 Größenordnungen höher als der berechnete Preis". Der Beitrag erreichte 271.000 Aufrufe. Bereits früher 2024 rechnete @swyx nach und stellte fest, dass die Preisgestaltung nur bei einer Batch-Größe von ~512 funktioniert – völlig unüblich bei normaler Inferenz – und bei einer normalen Batch-Größe von 64 auf ~$1,84 pro Million Token sinkt.
Das Gegenargument: Groq sammelte $750 Mio. von BlackRock, Samsung, Cisco und Disruptive AI ein, gerade weil die Volumen- und Neuchip-These glaubwürdig ist. Ihre Kundenfallstudien zeigen GPTZero bei 7-facher Geschwindigkeit und 50 % niedrigeren Kosten, ReBlink bei 14-fach niedrigeren Kosten pro Spiel, Recall bei 10-fach niedrigeren Kosten. PeerSpot-Mindshare-Daten zeigen einen leichten Rückgang im Jahresvergleich (13,7 % auf 9,8 %) bei Enterprise-KI-Infrastruktur-Evaluatoren, was auf Unsicherheit bei NVIDIA-Deals zurückzuführen sein könnte – erwähnenswert.
Unsere Einschätzung: Wir wissen nicht, ob die aktuelle Preisgestaltung strukturell nachhaltig oder eine bewusste Land-and-Expand-Strategie vor der zweiten Chip-Generation ist. Was wir wissen: Die Preise sind durch 2025–2026 stabil geblieben, und die eingesammelten $750 Mio. verschaffen Zeit. Groq dort einsetzen, wo das Preis-Leistungs-Verhältnis stimmt; keine Architektur aufbauen, die von einem einzelnen Anbieter abhängt, von dem man sich nicht lösen kann.
Wer Groq verwenden sollte (und wer nicht)
Groq nutzen, wenn:
- Echtzeit-Sprach- oder Chat-Schnittstellen entwickelt werden, bei denen 280–1.000 TPS das Nutzererlebnis beeinflusst
- Der Modell-Stack auf Llama, Qwen, Whisper oder OpenAIs Open-Weight-Modellen basiert
- Günstige Transkription in großem Maßstab benötigt wird – Whisper Turbo bei $0,04/Stunde ist schwer zu schlagen
- Prototypen entwickelt werden – das kostenlose Kontingent deckt die meisten Entwicklungsworkloads ohne Kreditkarte ab
- Asynchrone Batch-Workloads vorhanden sind – der 50 %-Batch-API-Rabatt verändert die Wirtschaftlichkeit erheblich
Alternativen suchen, wenn:
- GPT-4o, Claude oder Gemini benötigt werden – nicht auf GroqCloud verfügbar
- Robuste Multimodal-Unterstützung benötigt wird – Llama 4 Scout befindet sich nur in der Vorschau
- On-Premises-Deployment mit Standard-Supportbedingungen benötigt wird – GroqRack erfordert Enterprise-Verhandlungen
- Feinabgestimmte proprietäre Modelle benötigt werden – LoRA-Feinabstimmung erfordert Enterprise-Zugang
Für einen breiteren Funktionsvergleich behandelt unser Groq-Review das vollständige Produkt ausführlich. Wer noch Anbieter abwägt, findet in Groq-Alternativen einen Vergleich von Together AI, Fireworks, Cerebras und anderen nach denselben Preis-Leistungs-Dimensionen.
eesel für KI-gestützten Kundensupport ausprobieren
Wer Groq für Kundensupport oder Helpdesk-Automatisierung evaluiert, findet in eesel eine gute Ergänzung. eesel setzt autonome KI-Agenten direkt in bestehenden Tools ein – Zendesk, Freshdesk, Slack, E-Mail – und leitet Support-Tickets basierend auf ihrer Komplexität an das richtige Modell weiter. Einfache, hochvolumige Anfragen gehen an ein schnelles, günstiges Modell-Tier (genau das, wofür Groqs Llama 8B und GPT OSS 20B entwickelt wurden); komplexe Eskalationen gehen an ein leistungsfähigeres Modell.
Teams, die mehr als 100.000 Tickets pro Monat bearbeiten, nutzen eesel-Agenten, die Probleme tatsächlich lösen, anstatt sie nur abzuwimmeln – keine neue Oberfläche zu erlernen, kein Prompt-Engineering erforderlich. Der Agent wird so eingewiesen, wie man einen neuen Mitarbeiter einarbeiten würde, und erledigt den Rest.

Häufig gestellte Fragen
Wie viel kostet die Groq-API pro 1 Mio. Token?
Hat Groq ein kostenloses Kontingent?
Wie schneiden Groqs Preise im Vergleich zu OpenAI ab?
Welche Rate Limits gelten bei Groqs kostenpflichtigem Developer-Tarif?
Bietet Groq gutes Preis-Leistungs-Verhältnis für Produktions-Workloads?

Article by
Rama Adi Nugraha
Rama is a software engineer at eesel AI with two years of experience writing about B2B SaaS, AI tools, and customer support technology. Based in Bali, Indonesia, he brings a developer's perspective to product comparisons — cutting through marketing copy to what the integrations and APIs actually do.