
Was Qwen ist (und warum es anders ist)
Qwen (通义千问) ist die LLM-Familie von Alibaba Cloud - ein umfangreicher Katalog von mehr als 145 Modell-IDs, der Text, Vision, Audio, Code, Übersetzung, Videogenerierung und Embeddings umfasst und über einen einzigen API-Key via Qwen Cloud / Alibaba Cloud Model Studio zugänglich ist.
Drei Dinge machen es auf dem LLM-Markt außergewöhnlich:
- Open-Weight-Modelle neben proprietären Modellen. Die gesamte Qwen3-Serie (0,6B bis 235B-A22B) ist unter Apache 2.0 lizenziert und auf Hugging Face verfügbar. Sie können dasselbe Modell, für das Sie die API bezahlen würden, lokal und kostenlos ausführen.
- MoE-Architektur dominiert die Mittelklasse. Der Großteil der wettbewerbsfähigen Preise von Qwen resultiert aus dem Mixture-of-Experts-Design - das Modell 235B-A22B aktiviert nur 22B Parameter pro Token, wodurch seine Inferenzkosten denen eines dichten 22B-Modells ähneln, trotz der Gesamtskala von 235B.
- Volumen in einem Maßstab, den nur wenige Anbieter erreichen. Qwen3.6-Plus war das erste Modell auf OpenRouter, das an einem einzigen Tag mehr als 1 Billion Token verarbeitet hat - ein Signal dafür, wie stark sich die Akzeptanz bei Entwicklern in Richtung der Qwen-Familie verschoben hat.
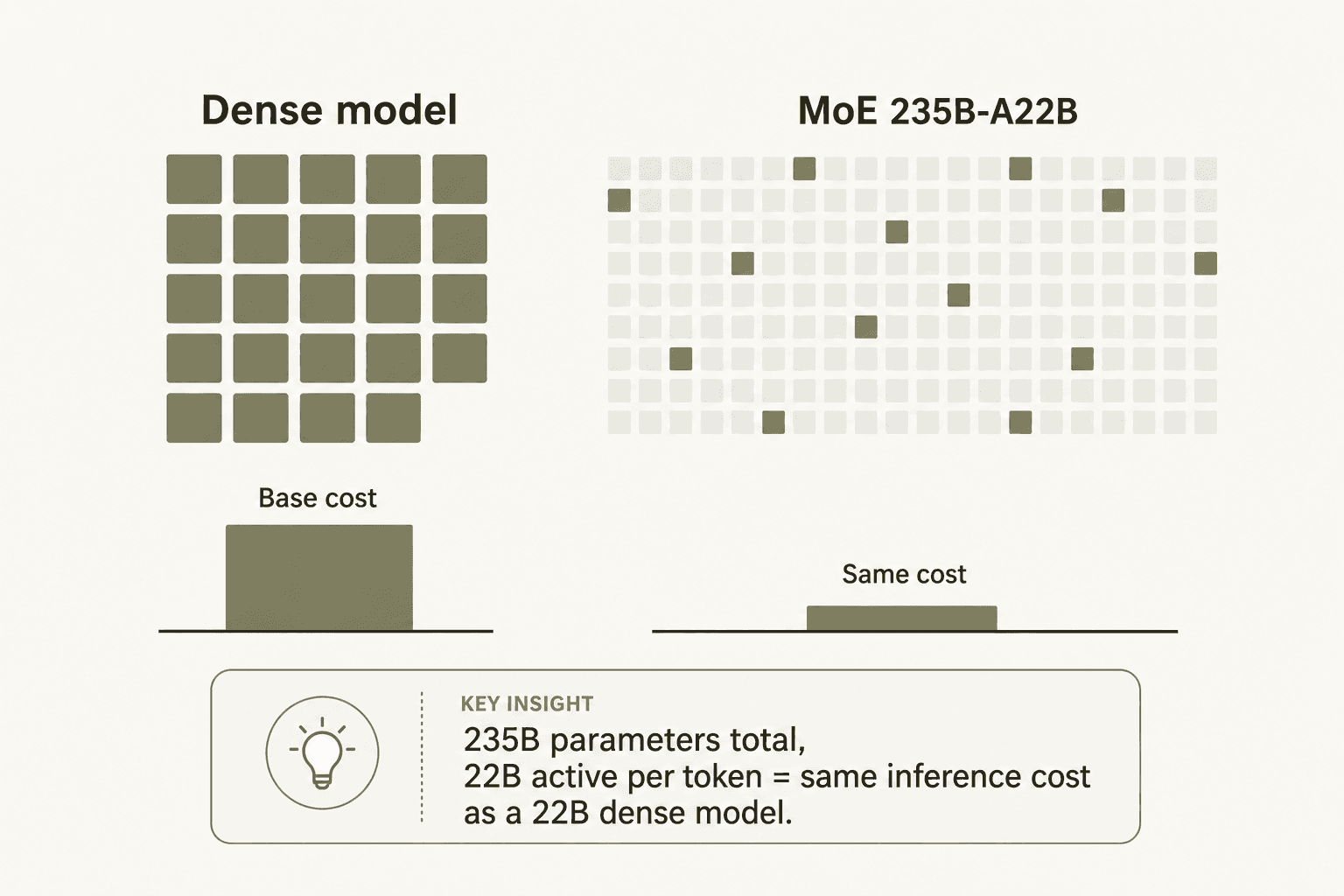
"Das MoE-Design: Die meisten MoE-Modelle fühlen sich wie nachträgliche Erweiterungen an. Die spärliche Aktivierung von Qwen 3.5 ist nativ - nur 4,3 % der Parameter werden pro Token aktiviert. So erhält man eine Leistung der Billionen-Parameter-Klasse ohne Billionen-Parameter-Inferenzkosten. Der Preis von 0,8 RMB pro Million Token ist nicht subventioniert; er ist strukturell verdient."
Vollständige Qwen API-Preistabelle (2026)
Alle Preise in USD, Pay-as-you-go auf dem internationalen Endpunkt (Alibaba Cloud Model Studio, ap-southeast-1). Preise stammen von den Qwen Cloud Modelldetailseiten und PricePerToken.com (Stand 3. Juni 2026).
Textgenerierungsmodelle
| Modell | Input $/1M | Output $/1M | Kontext | Notizen |
|---|---|---|---|---|
| Qwen3.7-Max | 1,25 $ | 3,75 $ | 1M Token | 50 % Promo auf 2,50 $/7,50 $ Listenpreis; nur Text; Start 21.05.2026 |
| Qwen3.7-Plus | 0,32 $ – 0,96 $ | 1,28 $ – 3,84 $ | 1M Token | Nativ multimodal; gestaffelt nach Kontextlänge; Start 01.06.2026 |
| Qwen3-Max | 1,20 $ | 6,00 $ | 262K Token | Agent-optimiert; Cache Read 0,12 $/1M |
| Qwen3.6-Plus | 0,50 $ – 2,00 $ | 3,00 $ – 6,00 $ | 1M Token | Nativ multimodal; Agentic Coding; Vision + Text |
| Qwen3.6-Flash | 0,25 $ – 1,00 $ | 1,50 $ – 4,00 $ | 1M Token | Kostenoptimiertes Vision-Language |
| Qwen3-235B-A22B | 0,70 $ | 2,80 $ / 8,40 $* | 131K Token | MoE-Flaggschiff Open-Weight; *Thinking Mode |
| Qwen3-30B-A3B | 0,20 $ | 0,80 $ / 2,40 $* | 131K Token | Ausgewogenes MoE; *Thinking Mode |
| Qwen3-8B | 0,18 $ | 0,70 $ / 2,10 $* | 131K Token | Dichtes kleines Modell; *Thinking Mode |
| Qwen-Max | 1,60 $ | 6,40 $ | 32K Token | Stabiler Produktions-Alias |
| Qwen-Plus | 0,40 $ | 1,20 $ / 4,00 $* | 1M Token | Stabiler Alias; *Thinking Mode |
| Qwen-Turbo | 0,05 $ | 0,20 $ / 0,50 $* | 131K Token | Günstigste Textstufe; 5M TPM Durchsatz; *Thinking Mode |
| Qwen3.5-0.8B | 0,01 $ | 0,05 $ | - | Absolutes Minimum; für Mikro-Automatisierungsaufgaben |
*Thinking-Mode-Output wird zum höheren Satz abgerechnet, wenn enable_thinking: true gesetzt ist.
Vision-Language und multimodale Modelle
| Modell | Input $/1M | Output $/1M | Kontext |
|---|---|---|---|
| Qwen3-VL-Plus | 0,20 $ | 1,60 $ | 262K Token |
Embedding-Modelle
| Modell | Preis |
|---|---|
| text-embedding-v3 / text-embedding-v4 | 0,07 $/1M Token; 0,035 $/1M Batch |
Videogenerierungsmodelle
| Modell | Preis |
|---|---|
| HappyHorse-1.0 Serie (T2V, I2V, R2V, Edit) | 0,112 $/Sekunde |
| Wan2.7-T2V | 0,10 $/Sekunde |
Preisspannen bei Qwen3.7-Plus und der Qwen3.6-Serie spiegeln gestaffelte Input-Klassen wider - die Kosten pro Million Token steigen, wenn die Input-Länge innerhalb eines einzelnen Requests wächst (nicht nach kumulativer Nutzung). Der Satz von 0,32 $ gilt für kurze Inputs; 0,96 $ greifen bei Long-Context-Anfragen auf Qwen3.7-Plus.
Wie die Abrechnung tatsächlich funktioniert
Die Preisliste zu kennen, ist der erste Schritt. Zu verstehen, wie sich diese Sätze in einem echten Workload summieren, ist der Punkt, an dem viele überrascht werden.
Thinking Mode
Mehrere Modelle der Qwen3-Generation unterstützen einen optionalen enable_thinking: true Parameter, der ein Chain-of-Thought-Reasoning vor der endgültigen Antwort auslöst. Die Thinking-Token werden intern generiert und dann abgerechnet - zu Sätzen, die in der Regel 3- bis 10-mal so hoch sind wie der Standard-Output. Bei Qwen-Plus kostet der Standard-Output beispielsweise 1,20 $/1M, der Thinking-Output jedoch 4,00 $/1M. Bei Qwen3-235B-A22B springt der Thinking-Output von 2,80 $ auf 8,40 $/1M.
Für die meisten Produktions-Workloads - Klassifizierung, Zusammenfassung, strukturierte Extraktion - ist der Thinking Mode übertrieben. Aktivieren Sie ihn nur für reasoning-intensive Aufgaben (komplexe Code-Reviews, mehrstufige Planung, Mathematik) und planen Sie Ihr Budget entsprechend ein.
Prompt Caching
Implizites Prompt Caching erfolgt bei den meisten Qwen-Modellen automatisch: Wiederholte Kontext-Präfixe werden zwischengespeichert, und Cache-Hits werden mit etwa 20 % des Standard-Input-Satzes abgerechnet. Bei Qwen-Plus sind das 0,08 $/1M statt 0,40 $/1M für gecachte Teile.
Es gibt auch ein explizites Cache-Management für Qwen3-Max und Qwen-Plus:
- Cache-Erstellung: ~0,50 $/1M (125 % des Input-Satzes)
- Cache-Read: ~0,04 $/1M (10 % des Input-Satzes)
Der Haken, der in der Community immer wieder genannt wird: Das Caching von Qwen greift weniger zuverlässig als bei der Konkurrenz. Ein Reddit-Nutzer führte dieselbe Code-Review-Aufgabe über vier KI-CLIs aus und stellte fest, dass Qwen 23 % seines monatlichen 30-$-Kontingents für eine einzige Aufgabe verbrauchte - dieselbe Aufgabe verbrauchte weniger als 1 % bei vergleichbaren 100-$-Plänen von Claude und OpenAI. Die explizite Diagnose: "Sie scheinen nicht so gut zu cachen wie andere Modellanbieter."
Batch-Verarbeitung
Die asynchrone Batch-API bietet rund 50 % Rabatt auf die Standardsätze für Workloads, die nicht in Echtzeit erfolgen müssen. Bei Qwen3-Max sinkt der Batch-Input von 1,20 $ auf 0,60 $/1M; der Batch-Output von 6,00 $ auf 3,00 $/1M. Für ETL-Pipelines, Massenklassifizierungsjobs oder die nächtliche Berichterstellung ist der Batch-Modus der richtige Standard.
Sparpläne
Alibaba Cloud bietet AI Savings Plans mit einer Kostenreduzierung von bis zu 47 % durch Nutzungsverpflichtungen an. Es gibt auch einen AI Token Plan - feste Abonnement-Credits über Modelle hinweg - aber die Erfahrungen der Community damit sind gemischt (siehe Was Sie tatsächlich zahlen unten).
Was Sie in der Praxis tatsächlich zahlen
Listenpreise und echte Rechnungen gehen oft auseinander. Hier sind drei durchgerechnete Beispiele basierend auf realen Daten.
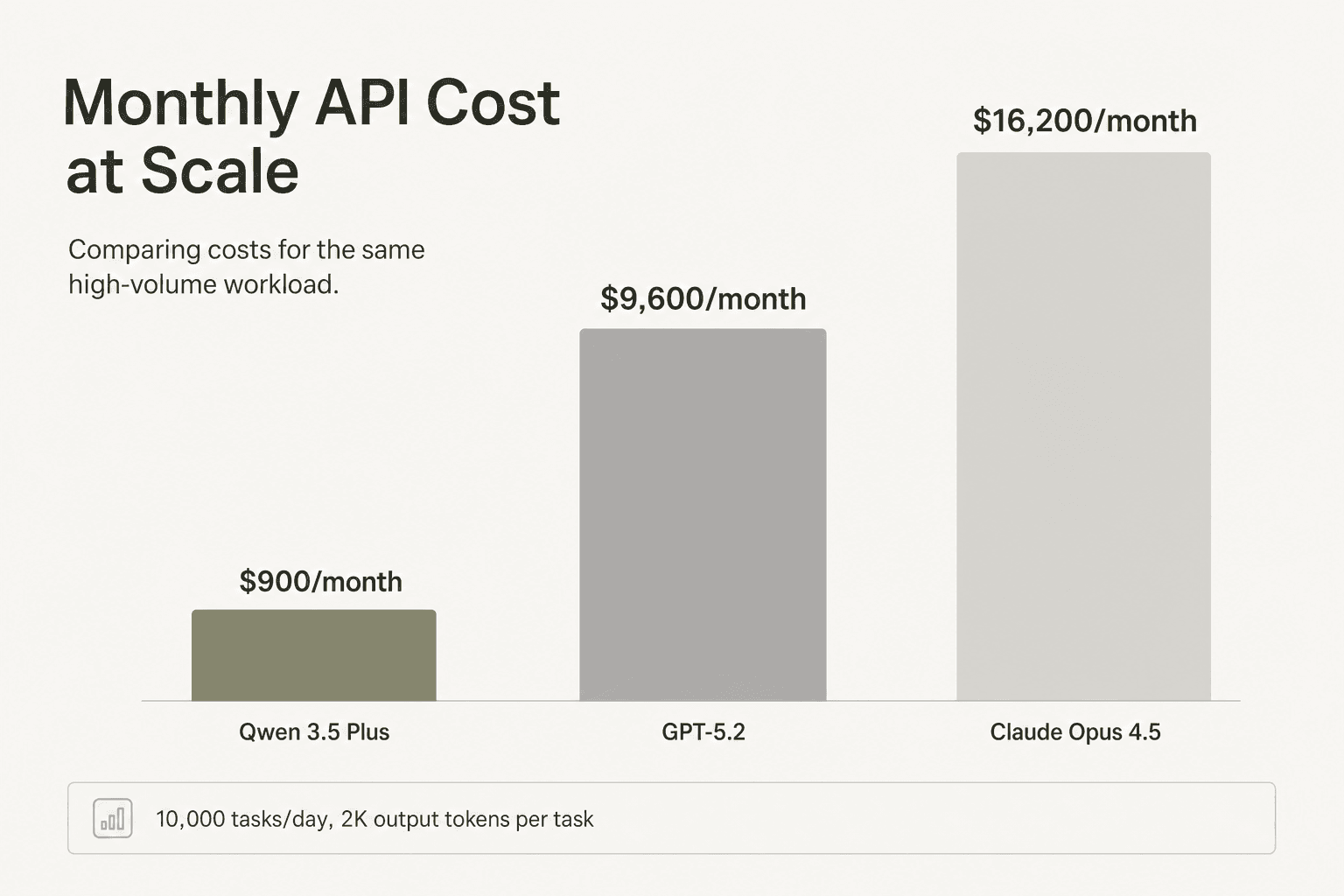
Beispiel 1: Eine Content-Pipeline mit 10.000 Aufgaben/Tag
ChartGen AI hat Qwen 3.5 vs. GPT-5.2 vs. Claude Opus 4.5 in 20 Datenvisualisierungsaufgaben getestet, die jeweils etwa 2.000 Output-Token erforderten. Die wirtschaftliche Betrachtung bei 10.000 Aufgaben/Tag:
| Modell | Kosten pro Aufgabe | Tägliche Kosten | Monatliche Kosten |
|---|---|---|---|
| Qwen 3.5-35B-A3B | ~0,003 $ | ~30 $ | ~900 $ |
| GPT-5.2 | ~0,032 $ | ~320 $ | ~9.600 $ |
| Claude Opus 4.5 | ~0,054 $ | ~540 $ | ~16.200 $ |
Qwen erreichte im Benchmark 163/200 Punkte gegenüber GPT-5.2 mit 178/200 - eine Qualitätslücke von 9 % bei einer 10-fachen Kostenreduzierung.
Das Team von ChartGen wies auch auf den Multi-Agenten-Multiplikator hin:
"In der Pipeline von ChartGen AI wird bei einer einzigen Dashboard-Generierung das Modell 5 bis 8 Mal aufgerufen... Bei diesem Maßstab kann man 10 Qwen 3.5 Agenten zum Preis eines einzigen GPT-5.2 Aufrufs betreiben - und Ensemble-Voting nutzen, um die Genauigkeit jedes einzelnen Modells zu übertreffen."
Steven Cen, ChartGen AI [Quelle]
Beispiel 2: Der Intelligence Index Infrastruktur-Test
Artificial Analysis ließ Qwen3.6 Plus durch ihren vollständigen Intelligence Index Benchmark laufen. Gesamtkosten:
- Qwen3.6 Plus: 483 $ (~100 Mio. Output-Token bei 0,50 $/3,00 $)
- Claude Opus 4.6 (maximaler Aufwand): 4.970 $
Das ist ein 10-facher Kostenunterschied bei einer Differenz von 2 Punkten im Intelligenz-Score (Qwen3.6 Plus erzielte 51, Claude Opus 4.6 53 Punkte auf deren Index). Der Vorbehalt: Qwen generierte pro Aufgabe spürbar mehr Output-Token als die Konkurrenz, was die Kosten im Vergleich zu einem weniger verbosen Modell bei gleichem Token-Satz aufblähte.
Beispiel 3: Der Token Plan Preisschock
Das neuere Abonnement-Angebot von Qwen - der AI Token Plan - rechnet Dollar in Credits auf eine Weise um, die viele Erstanwender verwirrte. Aus einem Reddit-Thread vom Mai 2026:
"Ich habe mich für den 30-$-Plan angemeldet (der 25.000 Credits bietet)... in nur 4 Stunden Nutzung [mit Qwen 3.6 Plus] [habe ich] etwa 8.000 Credits verbraucht (von insgesamt 25.000 Credits im 30-$-Plan)."
Der direkte Vergleich des Nutzers qu1etus ist vernichtend für den Token Plan im Speziellen:
"qwen3.7-max (mit qwen cli - 30-$-Plan): 23 % meiner monatlichen Quote verbraucht. gpt-5.5 xhigh (mit codex cli - 100-$-Plan): <1 % der monatlichen Quote verbraucht. opus 4.7 (mit claude code - 100-$-Plan): <1 % der monatlichen Quote verbraucht. Was die Kosten angeht, bin ich raus. Sie scheinen nicht so gut zu cachen wie andere Modellanbieter und ihr Preismodell ist kaputt."
Die rohen Pay-as-you-go API-Sätze sind besser als es die Token-Plan-Rechnung vermuten lässt. Wenn Sie Qwen mit Claude oder OpenAI vergleichen, halten Sie sich an die API-Preise pro Token statt an die Abonnement-Stufen.
Qwen Preisstufen: Das richtige Modell wählen
Nicht jeder Workload benötigt die Max-Stufe. Die Entscheidung über die Architektur ist meist wichtiger als die Modellgeneration.

Qwen-Turbo (0,05 $/0,20 $) - Die richtige Wahl für Klassifizierung, Routing, Extraktion und alle Workloads, bei denen Sie hohen Durchsatz zu geringen Kosten benötigen. Mit einem Rate Limit von 5 Mio. Token pro Minute bewältigt es aggressive Batch-Pipelines, ohne an Grenzen zu stoßen. Ein Reddit-Nutzer drückte es unverblümt aus: "Bei sieben Cent pro Million Token fühlt es sich wie Betrug an."
Qwen3-30B-A3B (0,20 $/0,80 $) - Die ausgewogene MoE-Wahl. Das 30B-A3B aktiviert bei der Inferenz nur 3B Parameter, läuft mit ~137 Token/Sekunde auf einer einzelnen H20 GPU und deckt die überwiegende Mehrheit der Coding- und Reasoning-Aufgaben ab, die keine Max-Level-Kapazität erfordern. Community-Konsens auf r/LocalLLaMA: Die 35B-A3B MoE-Variante läuft 15-mal schneller als die dichte 27B-Variante zu einem Bruchteil der Kosten - wählen Sie immer MoE, wenn eines in Ihrer Zielgröße verfügbar ist.
Qwen-Plus (0,40 $/1,20 $) - Der stabile Produktions-Alias mit 1M Kontext. Wenn Sie eine berechenbare API-ID benötigen, die sich zwischen Modell-Updates nicht ändert, ist dies die richtige Wahl. Thinking Mode verfügbar für 4,00 $/1M Output.
Qwen3.7-Plus (0,32 $ – 0,96 $ / 1,28 $ – 3,84 $) - Die native multimodale Option mit 1M Kontext und Agentic-Coding-Fähigkeiten. Gut geeignet für Pipelines, die Text, Bilder und Tool-Calling im selben Aufruf mischen.
Qwen3-Max / Qwen3.7-Max (1,20 $ – 1,25 $ / 6,00 $ – 3,75 $) - Hier nähert man sich dem preislichen Spitzenfeld. Die Community stellte fest, dass die 480B MoE Coder Variante oft sinnvoller ist als Max für intensives Coding bei 1,50 $/7,50 $, es sei denn, Sie benötigen speziell die Optimierung der Agent-Pipeline der Max-Architektur. Mit den rabattierten 1,25 $ für Qwen3.7-Max ist es konkurrenzfähig zu den Preisen von GPT-5 der Mittelklasse - aber der Rabatt ist als zeitlich begrenzt gelistet.
Die Situation beim Free Tier im Jahr 2026
Dies ist der Teil, der die meisten Leute verwirrt.
Was kostenlos ist: Die Qwen Studio Consumer-Chat-App - keine Anmeldung erforderlich, keine Rate-Limits kommuniziert, unterstützt auf iOS, Android, macOS und im Web. Das wird nicht verschwinden. Alibaba hat starke kommerzielle Anreize, das Endverbraucherprodukt kostenlos zu halten.
Was kostenlos war und nun weg ist: Das kostenlose Kontingent der Entwickler-OAuth-API - das 1.000 (später 100) Requests pro Tag via API erlaubte - wurde am 15. April 2026 eingestellt. Das kostenlose Coding-Tier der Qwen Code CLI mit 2.000 Requests pro Tag wurde etwa zur gleichen Zeit ebenfalls gestrichen. Die Reaktion der Community war unmittelbar:
"Ehrlich gesagt, habe ich jetzt Claude abonniert. Ich habe Qwen .md-Dateien von allem erstellen lassen, damit Claude einfach dort weitermachen konnte."
u/ihateroomba, 3 Upvotes
Ein analytisch scharfer Reddit-Kommentar erklärte den Unterschied gut:
"Es ist wichtig, zwischen zwei Welten zu unterscheiden, die bei Alibaba koexistieren: Die 'Consumer Product' Welt (Qwen Studio): Die App, die Sie auf Ihrem Handy nutzen, ist ein fertiges Produkt. Alibaba hat jedes Interesse daran, sie kostenlos zu halten... Die 'Developer / API' Welt: Hier hat sich die Politik geändert... Es ist eine klassische Strategie: Nutzer mit der kostenlosen Version anlocken und dann zur Kasse bitten, wenn sie skalieren."
Was immer noch als kostenloser Test verfügbar ist: Neue Konten im Alibaba Cloud Model Studio erhalten über 70 Mio. Token kostenlos über verschiedene Qwen-Modelle hinweg (1 Mio. Token pro Modell), plus 1.650 Sekunden Videogenerierungs-Guthaben. Gültig für 90 Tage, nur Singapur-Endpunkt. Der Endpunkt US Virginia bietet kein kostenloses Kontingent.
Die Preisuntergrenze beim Selbsthosten
Es gibt eine Zahl, die die API-Preistabellen nicht zeigen: 0,00 $ pro Token, verfügbar für jeden, der bereit ist, seine eigene Inferenz zu betreiben.
Alle Qwen3-Modelle (0,6B bis 235B-A22B) sind Apache 2.0 Open-Weight und auf Hugging Face verfügbar. @WolframRvnwlf testete den Qwen3-30B-A3B Unsloth quantisierten Build auf einem M4 MacBook Pro:
"Der 30B-A3B Unsloth Quant lieferte 82,20 %, während er lokal mit ~45 tok/s und ohne API-Ausgaben lief... Quantisierte 30B-Modelle bringen einen jetzt auf ~98 % der Genauigkeit der Spitzenklasse - bei einem Bruchteil der Latenz, Kosten und Energie."
vLLM und SGLang sind die empfohlenen Frameworks für das Selbsthosten; die Qwen3-Dokumentation enthält vollständige Deployment-Befehle. Für Teams, die sensible Daten verarbeiten oder in Gerichtsbarkeiten tätig sind, in denen Compliance-Fragen bezüglich China-basierter Clouds eine Rolle spielen, löst das Selbsthosten auch die Frage der Datenresidenz vollständig.
Der Kompromiss: Die Hardwarekosten sind real. Ein einzelner H20 GPU-Knoten kostet bei Cloud-Anbietern etwa 3 bis 5 $/Stunde. Für moderate Workloads (unter ein paar Millionen Token pro Tag) ist die API wahrscheinlich günstiger als dedizierte Rechenleistung. Aber bei großen Volumina - oder mit einer GPU, die man bereits besitzt - gewinnt oft das Selbsthosten.
Qwen vs. Claude vs. GPT: Der ehrliche Vergleich
Das Argument "Qwen ist 9-mal günstiger als Claude" ist richtig, aber unvollständig.
"Der API-Preisvergleich erzählt die Geschichte deutlich. Claude Opus 4.6 kostet 5 $ Input und 25 $ Output pro Million Token. GPT-5.3 Codex kostet 1,75 $ und 14 $. Qwen 3.5 Plus liegt bei 0,40 $ und 2,40 $. Das ist kein geringfügiger Unterschied. Das ist eine strukturelle Verschiebung darin, wer es sich leisten kann, mit KI auf Spitzenmodell-Niveau zu bauen."
Die Nuance, die Artificial Analysis hinzufügt: Qwen-Modelle generieren pro Aufgabe mehr Output-Token als vergleichbare Modelle. Qwen3.5-27B verbrauchte 98 Mio. Output-Token, um deren Intelligence Index Benchmark abzuschließen - deutlich mehr als MiniMax-M2.5 (56 Mio.) oder DeepSeek V3.2 (61 Mio.). Wenn Ihr Workload lange Outputs generiert, gleicht die Token-Verbosität den Rabatt pro Token teilweise wieder aus.
Rishabh Choudharys LinkedIn-Analyse von Qwen3.6-Plus bringt die Kernfrage auf den Punkt:
"Es erzielte 78,8 auf SWE-bench Verified... Claude Opus 4.5 erreichte 80,9. Das ist eine Lücke von 2 Punkten. Die Preislücke? Nicht 2 Punkte. Eher das 17-fache... Die Frage ist nicht, ob chinesische Modelle aufholen. Das tun sie ganz offensichtlich. Die Frage ist, ob die verbleibenden Qualitätsunterschiede so schwer wiegen, dass sie einen 17-mal höheren Preis rechtfertigen. Für viele Anwendungsfälle lautet die ehrliche Antwort mittlerweile: Nein."
Die Vorbehalte von Praktikern, die Qwen in der Produktion eingesetzt haben, sollten ebenfalls ernst genommen werden. Aus den Kommentaren desselben LinkedIn-Posts: Eine Latenz von 11 Sekunden bis zum ersten Token im kostenlosen Preview-Tier (ein Problem für mehrstufige Agenten-Loops, bei denen sich die Wartezeit summiert) und eine berichtete Halluzinationsrate von 26 % beim Code-Reasoning in Produktionstests, die "eine Verifizierungsebene erfordern, die einen Teil der Kosteneinsparungen bei den Token wieder auffrisst".
Für einen direkten Vergleich mit den beliebtesten Alternativen siehe Claude Preise, Gemini Preise und Mistral AI Preise.
Benchmark-Kontext
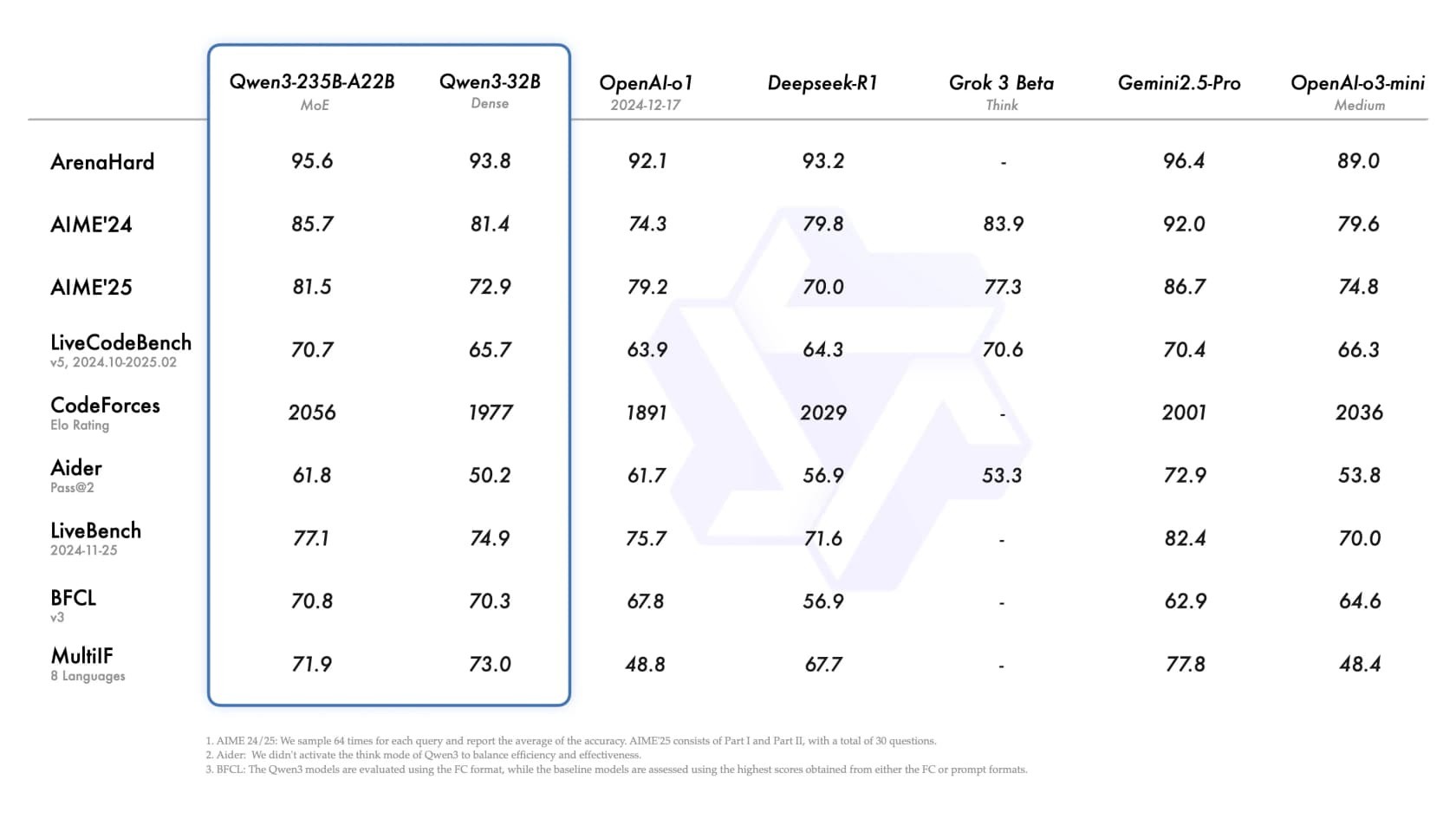
Das MoE-Flaggschiff Qwen3-235B-A22B konkurriert bei öffentlichen Benchmarks direkt mit OpenAI o1, DeepSeek-R1 und Gemini 2.5 Pro - ArenaHard 95,6, AIME'24 85,7, LiveCodeBench 70,7, BFCL 70,8. Mit 0,70 $/2,80 $ pro 1M Token (Standard) unterbietet es die meisten dieser Modelle beim Preis bei gleichzeitig vergleichbaren Scores. Die Verfügbarkeit als Open-Weight bedeutet zudem, dass Sie es selbst herunterladen und ausführen können, ohne von einer API abhängig zu sein.
Das Signal bei den Open-Source-Downloads ist eindeutig: Qwen belegt 7 der Top 10 Plätze in den Open-Model-Download-Rankings von Hugging Face, so Nathan Lambert (ML-Forscher). Qwen2.5-7B-Instruct kommt auf 52,4 Mio. Downloads und mehrere Qwen3-Varianten finden sich in den Top 5. Dieser Grad der Akzeptanz schafft Community-Tooling, quantisierte Builds und Ökosystem-Integrationen, die das Selbsthosten immer zugänglicher machen.
API-Zugang: So starten Sie
Die internationale API läuft über Alibaba Cloud Model Studio. Sie ist OpenAI-kompatibel, was bedeutet, dass der Wechsel vom SDK von OpenAI zu Qwen meist nur eine Änderung von zwei Zeilen erfordert - Base-URL und API-Key.
from openai import OpenAI
client = OpenAI(
base_url="https://[workspace-id].ap-southeast-1.maas.aliyuncs.com/compatible-mode/v1",
api_key="ihr-dashscope-api-key"
)
Verfügbare Regionen: Südostasien (primär), Frankfurt (seit 20.03.2026) und Hongkong (seit 17.03.2026). Der Endpunkt US Virginia ist verfügbar, bietet jedoch kein kostenloses Testkontingent.
Die Rate Limits liegen bei 600 RPM / 1M TPM für die meisten Modelle; Qwen-Turbo liegt mit 5M TPM höher, was es zur richtigen Wahl für stoßartige Hochvolumen-Pipelines macht. Enterprise-Konten können Quotenerhöhungen per Support-Ticket beantragen.
Wer Qwen bereits einsetzt und wer noch abwartet
Die Akzeptanz bei Entwicklern ist stark - die Dominanz bei den Hugging Face Downloads und das Token-Volumen auf OpenRouter machen das unbestreitbar. NVIDIA hat Qwen 3.5 am Launch-Tag offiziell unterstützt und Entwickler auf den NeMo-Build-Pfad verwiesen.
Bei der Einführung in Unternehmen sieht die Sache anders aus. Wie ein LinkedIn-Kommentator anmerkte:
"Bei unseren Fortune 500 / Unternehmenskunden sind die meistgenutzten Modelle: 1. Gemma 2. Mistral 3. GPT-OSS 4. Llama... Einige unserer fortschrittlicheren Unternehmenskunden fangen an, Qwen zu nutzen, aber es ist noch nicht die Mehrheit."
Andrew Jardine, Enterprise AI [Quelle]
Die genannten Hindernisse: Compliance-Prüfungen aufgrund der Herkunft aus China in regulierten Branchen (Finanzdienstleistungen, Gesundheitswesen, Behörden) und die Latenz der kostenlosen Preview-Endpunkte. Die Qwen3-Serie verfügt über eine ISO 27001 Zertifizierung für die bezahlte API, aber viele Sicherheitsprüfungen in Unternehmen erfordern zusätzliche Freigaben zur Datenresidenz und zum Logging des Modellzugriffs, bevor die Beschaffung fortfahren kann. Selbsthosting umgeht das meiste davon.
Für Teams außerhalb dieser Compliance-Einschränkungen - insbesondere Startups, mittelständische SaaS-Entwickler und Betreiber kostensensibler Agenten-Pipelines - sind die wirtschaftlichen Vorteile kaum von der Hand zu weisen.
Testen Sie eesel
Wenn Sie KI-gestützte Workflows in großem Maßstab betreiben und Token-Kosten eine Rolle spielen, ist eesel einen Blick wert. Es integriert autonome KI-Agenten direkt in die Tools, die Ihr Team bereits nutzt - Zendesk, Slack, Freshdesk, E-Mail, Shopify - ohne dass eine neue Oberfläche oder ein Abonnement pro Nutzer erforderlich ist. Sie zahlen pro Aufgabe (0,40 $ pro gelöstem Ticket, 4,00 $ pro entworfenem Blog-Post), und die Agenten pausieren automatisch, wenn Sie Ihr Ausgabenlimit erreichen. Das Preismodell umgeht den Aufwand für das Token-Zählen komplett. Starten Sie mit 50 $ Gratis-Guthaben, keine Kreditkarte erforderlich.

Häufig gestellte Fragen
Wie viel kostet Qwen pro Million Token?
Ist Qwen im Jahr 2026 noch kostenlos?
Wie schneiden die Preise von Qwen im Vergleich zu ChatGPT und Claude ab?
Was ist der Thinking Mode von Qwen und wie wird er abgerechnet?
enable_thinking: true, der Chain-of-Thought-Reasoning aktiviert. Thinking-Output-Token werden zu einem höheren Satz als Standard-Output abgerechnet - in der Regel 3-10x so hoch. Zum Beispiel berechnet Qwen-Plus 1,20 $/1 Mio. für Standard-Output, aber 4,00 $/1 Mio. für Thinking-Output. Standard-Input-Token werden zum gleichen Satz abgerechnet, unabhängig davon, ob Thinking aktiviert ist.








