
What Gemini Omni Flash is, quickly
Gemini Omni Flash is Google DeepMind's first model in its new "Omni" family: feed it text, image, video, or audio, and it generates high-resolution video you then edit through conversation rather than re-prompting from scratch. It rolled out to consumers first through the Gemini app, Google Flow, and YouTube Shorts, then opened to developers on June 30, 2026 via the Gemini API, Google AI Studio, and the Gemini Enterprise Agent Platform. I've covered what the model actually does and where it falls short elsewhere; this post is just about the number that decides whether it fits your budget.
The full pricing breakdown
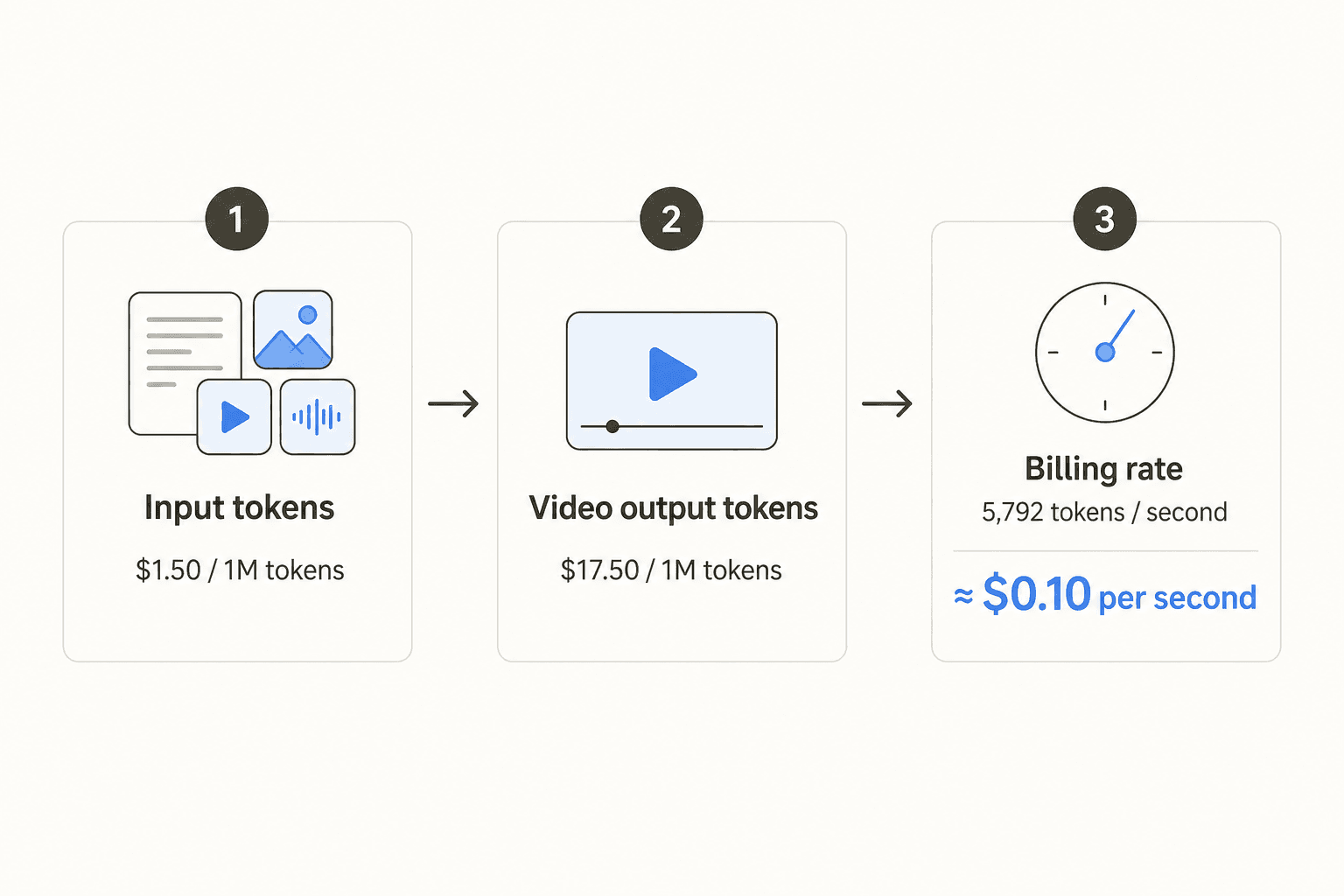
Gemini Omni Flash's Gemini API pricing page is unusually simple to read, mostly because there's only one tier to read. Most Gemini 3.x models split into Standard, Batch, Flex, and Priority tabs; Omni Flash Preview only has Standard.
| Item | Price |
|---|---|
| Input (text, image, video, audio, one flat rate) | $1.50 / 1M tokens |
| Output - text | $9.00 / 1M tokens |
| Output - video | $17.50 / 1M tokens |
| Effective video rate | ≈ $0.10 / second of 720p video |
| Free tier | None |
| Batch API discount | Not offered |
Google's pricing page spells out the conversion directly: billing runs on total output token consumption, at a fixed 5,792 tokens per second of 720p video. Multiply that by the $17.50-per-1M-token video rate and you land at roughly $0.1014 a second, which Google rounds to "approximately $0.10" on the page itself.
Gemini API dev-relations lead Logan Kilpatrick announced the rate in exactly those terms when the model opened up to developers:
"Omni Flash is SOTA at video editing at $0.10 / sec, same as Veo 3.1 Fast!"
Google isn't hiding that it's matching a direct competitor. The launch post itself states the price is set to be "priced competitively... which is the same as Veo 3.1 Fast." I couldn't find an independent, sourced Veo 3.1 Fast rate to double-check that claim against, so treat the comparison as Google's own framing, not a third-party verification, but it does tell you where Google positioned this model against its closest rival on day one.
What a clip actually costs, at 1x and at scale
At the current 10-second cap, video output alone runs about $1.01 per clip (10 seconds x $0.1014/sec). Input adds a bit more depending on how much text, reference image, or reference video you feed in, since that's billed separately at the flat $1.50/1M rate, but for a short prompt with one or two reference images that's typically a small fraction of a cent by comparison to the video output charge.
Scale that out and the monthly bill for a content or marketing team starts looking like this, video-output cost only:
| Clips per month | Approx. video output cost |
|---|---|
| 10 | $10.10 |
| 50 | $50.50 |
| 100 | $101.00 |
| 500 | $505.00 |
That's a real number to budget against, not a "starts at" figure. If you're running a small test batch, $10-$50 a month is nothing. If a marketing team wants Omni Flash chained into a production pipeline generating a few hundred clips a month, you're looking at low four figures before you've paid for a single human hour of review.
Where Omni Flash sits against the rest of the Gemini lineup
Because Omni Flash only has a Standard tier, it's worth seeing how that compares to the discount structure everything else in the Gemini 3.x family gets. Gemini 3.5 Flash, for example, offers Standard, Batch (roughly 50% off Standard), Flex, and Priority tiers, plus a genuine free tier with limited access. Omni Flash gets none of that flexibility.

For reference, here's where Omni Flash's headline numbers land next to a few other models on the same pricing page:
| Model | Input (Standard) | Output (Standard) | Free tier |
|---|---|---|---|
| Gemini Omni Flash (video) | $1.50 / 1M tokens | $17.50 / 1M tokens (video) | No |
| Gemini 3.5 Flash | $1.50 / 1M tokens | $9.00 / 1M tokens | Yes |
| Gemini 3.1 Pro Preview | $2.00-$4.00 / 1M tokens | $12.00-$18.00 / 1M tokens | No |
| Gemini 2.5 Flash | $0.30-$1.00 / 1M tokens | $2.50 / 1M tokens | Yes |
Nano Banana 2 Lite (image, gemini-3.1-flash-lite-image) | $0.25 / 1M tokens | $0.034 per 1K-resolution image | No |
If you just need still images rather than motion, Nano Banana 2 Lite is the far cheaper sibling model Google shipped in the same announcement, at roughly 3.4 cents an image against a dollar-plus per video clip.
The hidden line items
Two details in the pricing page's footnotes are easy to miss and both push the real cost, or the real risk, higher than the headline rate suggests.
No Batch discount. Most paid-tier Gemini models let you cut costs roughly in half by submitting requests through the Batch API instead of Standard, in exchange for asynchronous processing. Omni Flash Preview doesn't offer that trade at all right now, so there's no "cheaper if you can wait" lever to pull.
Content used to improve Google's products, even on the paid tier. Most paid-tier Gemini models are marked "No" for this on the pricing page, which is the whole point of paying: your data isn't used for training. Gemini Omni Flash Preview is one of the few paid-tier rows marked "Yes." If you're feeding it anything sensitive, brand assets, unreleased footage, a client's product shots, that's worth knowing before you hit generate, not after.
Independent AI-news account Rohan Paul, breaking down the launch on X, flagged a related practical limit that affects how far your dollars actually stretch per clip:
"Gemini Omni Flash currently generates 10-second clips and lacks API audio reference support. [...] Google says the API accepts video references up to 3 seconds, but Gemini Omni Flash does not process them correctly yet."
So the $1-per-clip math assumes you're getting a clean 10-second result on the first try. If character consistency drifts across an edit, per the model's own documented limitation, and you regenerate, that cost compounds fast.
Metered pricing vs. flat pricing
Every metered API, Omni Flash included, puts the budgeting work on you: read the rate, do the multiplication, watch usage against a cap. That's a fine trade for a generative-media model where output volume is genuinely variable clip to clip. It's a worse trade when the thing you're pricing is a predictable, recurring workload, like a support queue that gets roughly the same number of tickets every week.
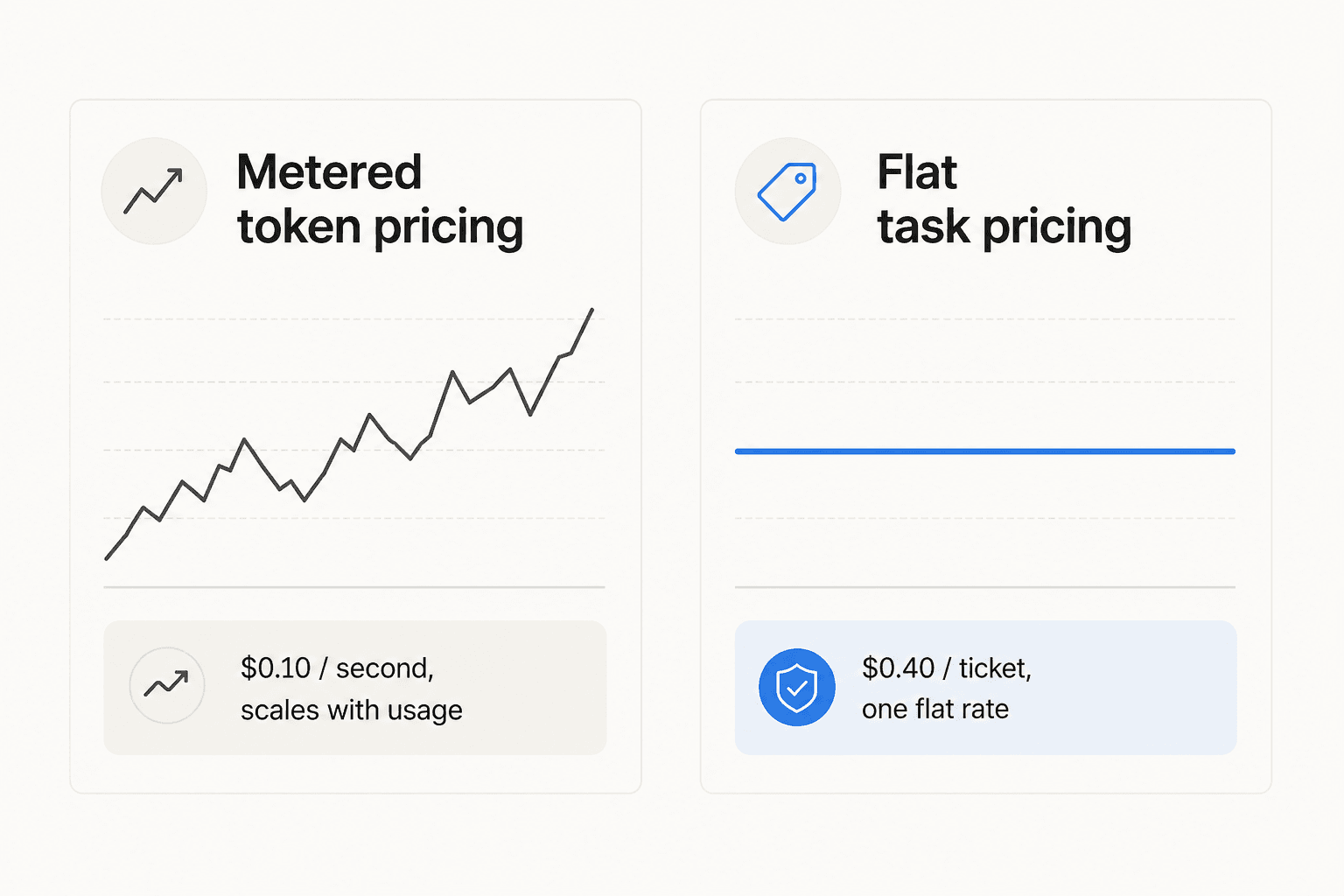
That's the design decision behind eesel's own pricing: $0.40 per resolved support ticket or chat session, flat, regardless of how many messages it takes or which underlying model handles it. Under the hood, eesel already routes work across OpenAI, Anthropic, and Google's own Gemini models depending on the task, including using Gemini to power eesel's free SEO Keyword Generator. The token-level pricing complexity you just read through in this post is exactly what that flat-rate structure is designed to absorb, so a support lead doesn't have to become a pricing-page analyst to know what next month's bill looks like.
Try eesel if the number you're actually budgeting is a ticket, not a clip
If you landed here pricing out AI for a growing support queue rather than a video pipeline, eesel is the AI teammate I build for exactly that job. It plugs into Zendesk, Freshdesk, Intercom, or whatever helpdesk you're already running, learns from your past tickets and help docs from day one, and drafts, triages, or resolves tier-1 requests.

Pricing is $0.40 per resolved ticket, no seat fees, no platform fee on the self-serve plan, and the first $50 of usage is free so you can see the real number against your own ticket volume before committing to anything. It's how Gridwise resolved 73% of tier-1 requests in its first month, and how Smava runs a fully automated agent across 100,000+ tickets a month without a token-math spreadsheet in sight. Gemini Omni Flash is a good answer if the question is "how much does a video cost." If the question is "how much does my support queue cost," try eesel and get a flat answer instead of a formula.
Frequently Asked Questions
How much does Gemini Omni Flash cost?
Does Gemini Omni Flash have a free tier?
How is the $0.10-per-second price actually calculated?
Is there a flat-rate alternative to metered AI pricing for customer support automation?

Article by
Alicia Kirana Utomo
Kira is a writer at eesel AI with a Computer Science background and over a year of hands-on experience evaluating AI-powered customer service tools. She focuses on breaking down how helpdesk platforms and AI agents actually work so that support teams can make better buying decisions.







