As 8 melhores ferramentas de IA para QA de suporte ao cliente em 2026
Riellvriany Indriawan
Katelin Teen
Última edição June 23, 2026

Por que o QA de suporte parece completamente diferente agora
Faco parte da equipe de suporte ao cliente do eesel, entao vivo na fila. O antigo ritual de QA sempre me incomodou: voce pontua um punhado minusculo de tickets, escreve algumas notas, e os padroes que realmente prejudicam (uma politica que todos entendem errado, um problema de tom em um canal) so aparecem semanas depois, se e que aparecem. A maioria das equipes revisa entre 1% e 3% de suas interacoes de suporte manualmente. Os outros 97% sao um ponto cego.
A razao maior pela qual o QA mudou, porem, e que passei os ultimos tres anos no eesel vendo agentes de IA entrarem em filas de suporte ao vivo, e vi um bot confiante dar silenciosamente uma resposta errada. Um cliente, uma equipe dinamarquesa de telematica de veiculos no Zendesk, enfrentou isso cedo: seu bot comecou a dizer aos clientes "sim, suportamos seu modelo de carro" para marcas que nao estavam em seu banco de dados, porque o centro de ajuda dizia "suportamos todos os modelos." Ninguem escreveu isso como regra. A IA inferiu, soou certa e estava errada.
Essa experiencia e exatamente o motivo pelo qual agora simulo cada implantacao contra tickets historicos primeiro, e reencuadra o que "QA de suporte" significa. Agora ha dois trabalhos:
- QA nas conversas que ja aconteceram (humanas ou de IA) — o trabalho classico de scorecard.
- QA no agente de IA antes e depois de responder, para que ele nunca envie o tipo de resposta confiante-mas-errada acima.
A maioria das ferramentas nesta lista e muito boa no trabalho um. Um numero menor faz o trabalho dois. A melhor pilha faz ambos, e vou sinalizar qual e qual para cada ferramenta.
Como o QA de suporte por IA funciona de fato
Se voce so fez QA manual, a mecanica de uma ferramenta AutoQA vale uma rapida olhada, porque e a mesma em quase todos os fornecedores aqui. Voce conecta seu helpdesk ou plataforma de contact center, define um scorecard em linguagem simples (saudacao, verificacao, empatia, resolucao, conformidade), e a IA le cada conversa em relacao a ele, retorna uma pontuacao com o raciocinio anexado e destaca as de alto risco para um humano examinar.
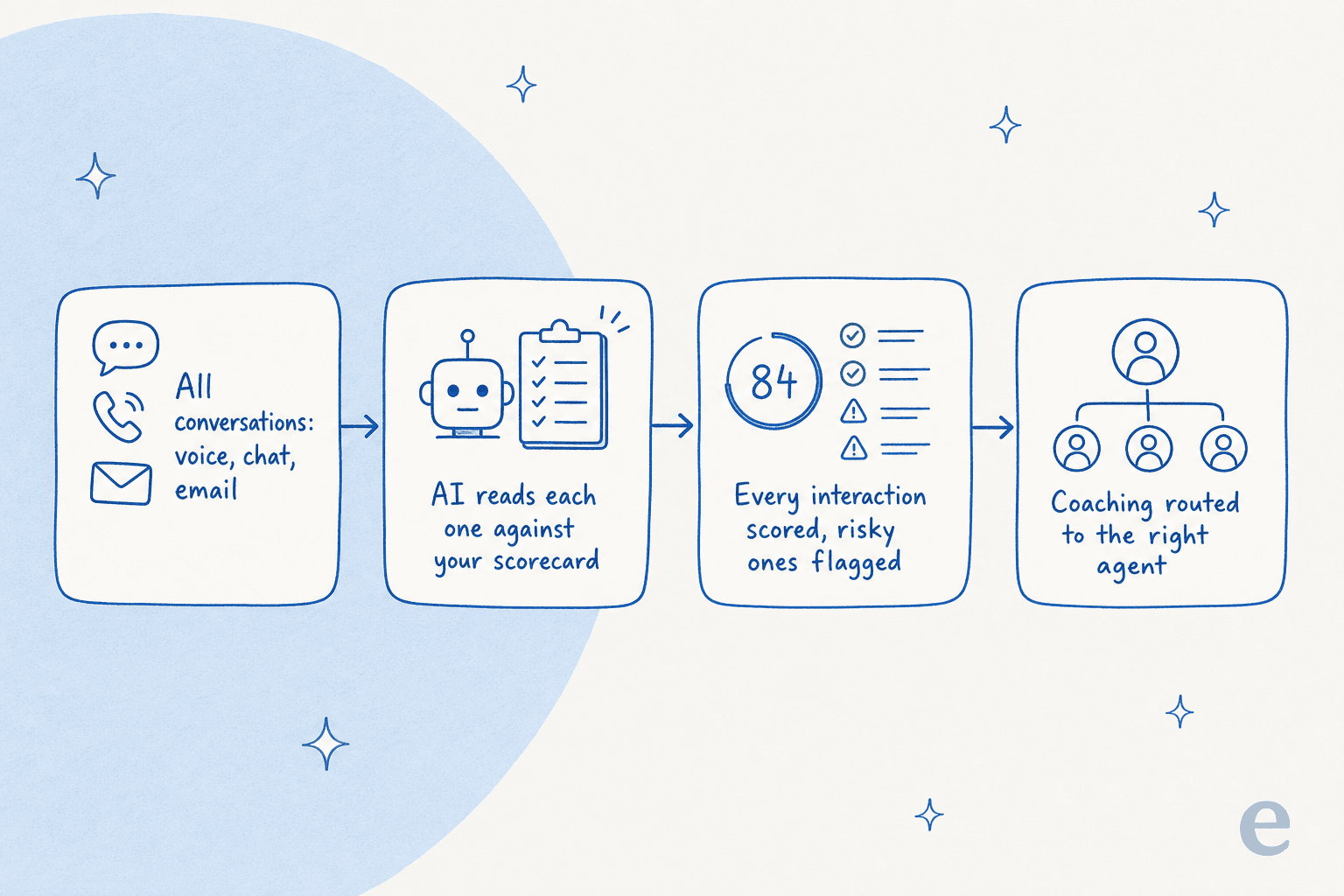
O salto de amostragem para cobertura total e real, e as metricas de suporte nas quais voce finalmente pode confiar (pontuacoes de qualidade consistentes, tendencias de sentimento, padroes de escalonamento) ficam muito mais honestas quando sao baseadas em 100% das conversas em vez de uma selecao aleatoria. O que manter em mente: uma pontuacao automatica e tao boa quanto seu calibracao, portanto toda ferramenta seria aqui permite testar a pontuacao em tickets passados antes de confiar no numero.
O que eu procurei
Eu ponderou esses fatores como faria se estivesse comprando para minha propria equipe:
- Cobertura. Ele realmente pontua 100% das conversas, ou e amostragem com passos extras?
- Flexibilidade do scorecard. Posso escrever meus proprios criterios em linguagem simples e ver o raciocinio por tras de cada pontuacao?
- O ciclo de coaching. Pontuar e metade do trabalho. Ele fecha o ciclo em coaching de agentes e melhoria?
- QA de agentes de IA. Ele pontua (e pre-testa) conversas de bots, nao apenas humanas?
- Honestidade de precos. Posso ver um numero, ou tenho que suportar uma ligacao de vendas para saber se posso pagar?
- Adequacao. Nativo do helpdesk e amigavel para pequenas equipes, ou construido para um contact center de voz com 500 assentos?
As melhores ferramentas de IA para QA de suporte em 2026 de relance
| Ferramenta | Melhor para | Cobertura AutoQA | Avalia agentes de IA? | Preco inicial | Avaliacao |
|---|---|---|---|---|---|
| eesel AI | QA do agente de IA antes do lancamento | Simulacao em 100% dos tickets passados | Sim, e sua funcao principal | 0,40 $ / ticket, sem taxa por assento | 4,6 / 5 (G2) |
| Zendesk QA | Equipes ja no Zendesk | 100% (AutoQA) | Sim (QA de agentes de IA) | ~35 $ / agente / mes (complemento) | 4,9 / 5 (Capterra, n=23) |
| MaestroQA | Enterprise, customizacao profunda | 100% (AutoQA) | Sim | Apenas sob consulta | 4,7 / 5 (G2, 324) |
| EvaluAgent | Medio porte, QA + coaching | 100% (AutoQM) | Sim (observabilidade de bots) | 35 $ / usuario / mes | 4,5 / 5 (G2, 440) |
| Loris (Contentsquare) | Analise de conversas em escala | 100% | Sim (analitica de agentes de IA) | Apenas sob consulta | 4,8 / 5 (G2, 11) |
| Level AI | Contact centers que querem tempo real | 100% (QA-GPT) | Parcial | Apenas sob consulta | 4,7 / 5 (G2, 200) |
| Playvox (NiCE) | QA junto com WFM | 100% (AutoQA) | Limitado | Apenas sob consulta | 4,8 / 5 (G2, 1.163) |
| Cresta | Grandes empresas de voz | 100% (gestao de qualidade) | Sim (pontuacao unificada) | Apenas sob consulta | 4,2 / 5 (G2, 43) |
Uma forma de ler o campo: ele se divide claramente por quem voce e. De um lado, nativo do helpdesk e amigavel para pequenas equipes; do outro, voz enterprise e contact center.
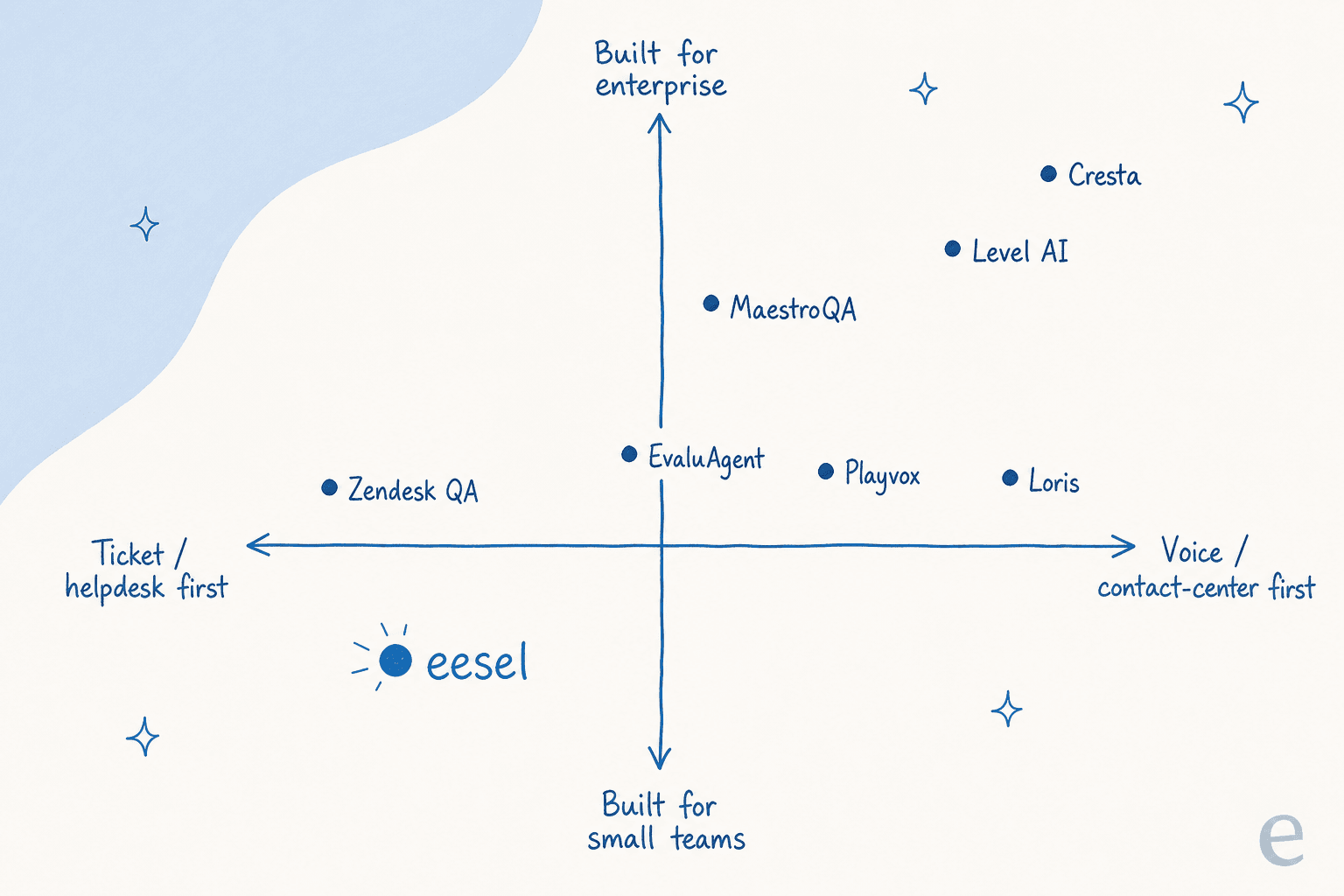
Se preferir nao analisar um quadrante, aqui esta a mesma logica como um seletor rapido.
Agora, as ferramentas em detalhe.
1. eesel AI
Melhor para: QA do seu agente de suporte por IA antes e depois de tocar um cliente.
Deixe-me ser direto sobre por que o eesel lidera uma lista de QA, porque nao e uma ferramenta de scorecard tradicional. O eesel e um agente de suporte por IA que se conecta ao seu helpdesk existente, aprende com seus tickets e documentos passados e responde tickets. A razao pela qual ele pertence aqui e que o QA de maior risco em 2026 e sobre as proprias respostas da IA, e o eesel e construido em torno de testar essas respostas antes de entrarem em producao.
O que ele faz para QA. O modo de simulacao do eesel executa a IA contra milhares de seus tickets historicos reais e mostra exatamente como ela teria respondido, o que teria resolvido e onde teria falhado, dividido por tema. Voce ve cobertura e precisao antes de um unico cliente ser afetado, corrige as lacunas e reexecuta. No lado ao vivo, o roteamento baseado em confianca evita que a IA responda quando nao tem certeza: tickets de baixa confianca se tornam rascunhos para um humano em vez de respostas autonomas. Esse e o mecanismo que teria detectado o erro "suportamos seu modelo de carro".
Pontos fortes.
- Avalia o que a maioria das listas ignora: a propria saida da IA, antes do lancamento.
- Aprende de tickets resolvidos, nao apenas de artigos do centro de ajuda, entao a simulacao reflete como sua equipe realmente responde.
- Cada resposta ao vivo pode ser revisada e corrigida, e essas correcoes melhoram as respostas futuras.
- Configuracao verdadeiramente de autoatendimento, com mais de 100 integracoes no Zendesk, Freshdesk, Gorgias, Front, HubSpot e Slack.
Limitacoes.
- Nao e uma plataforma de scorecard para agentes humanos. Se seu trabalho e avaliar 200 agentes humanos em um criterio e fazer sessoes de calibracao, uma ferramenta dedicada como Zendesk QA ou MaestroQA e mais adequada, e a resposta honesta e usar o eesel junto com uma delas.
- Os relatorios sao focados em desempenho de IA e temas de tickets, nao em recursos formais de QA ou planos de desempenho prontos para RH.
Precos. Baseado em uso e transparente, o que e raro nesta categoria.
| Plano | Preco | Notas |
|---|---|---|
| Teste gratuito | 50 $ em uso gratuito | Sem cartao de credito |
| Pague conforme usa | A partir de 0,40 $ / ticket | Sem taxa por assento, sem taxa de plataforma, sem minimo |
| Compromisso anual | 25% menos | Compromisso de 300 $/mes ou mais no ano |
| Enterprise | 1.000 $/mes taxa de plataforma + uso | SSO, HIPAA, BAA, SE dedicado |
Minha opiniao: Escolha o eesel quando o agente de IA e o que voce precisa avaliar. Um cliente, Gridwise, viu o eesel resolver 73% das solicitacoes de nivel 1 no primeiro mes, com resultados visiveis durante um teste de 7 dias, precisamente porque eles puderam simular primeiro e confiar na cobertura antes de ativa-lo. Combine-o com uma ferramenta de scorecard abaixo se voce tambem precisar de QA formal de agentes humanos.
2. Zendesk QA (anteriormente Klaus)
Melhor para: equipes que ja trabalham no Zendesk.
O Zendesk QA e a antiga startup estoniana Klaus, adquirida pelo Zendesk no inicio de 2024 e incorporada a plataforma como um complemento por agente. E a escolha mais natural se seu suporte ja funciona no Zendesk, e os clientes do eesel o usam regularmente para avaliar o desempenho de agentes de IA.
O que ele faz. AutoQA pontua cada interacao em todos os canais, incluindo agentes de IA e voz, com categorias prontas para uso (Empatia, Solucao) mais categorias personalizadas sem codigo baseadas em prompts. O Spotlight sinaliza automaticamente riscos de churn, escalonamentos e lacunas de conhecimento, e o QA de agentes de IA compara pontuacoes humanas e de bots lado a lado.
Pontos fortes.
- Cobertura de 100% em vez de amostragem, nativo do Zendesk.
- Categorias personalizadas sem codigo que voce escreve em linguagem simples.
- Forte reputacao da era Klaus. Como disse um usuario do Reddit ao comparar fornecedores: "+1 para Klaus, nunca tive problemas com eles, o suporte era incrivel."
"Amostragem + CSAT capta apenas uma fracao dos problemas, entao os padroes aparecem tarde."
um gerente de suporte descrevendo o problema que o AutoQA resolve, r/Zendesk
Limitacoes.
- E um complemento pago em cima de uma base ja cara. Um avaliador do Capterra expressou a desvantagem claramente: "Um pouco caro."
- A customizacao e mais superficial que o MaestroQA para criterios incomuns.
- A interface de relatorios fica lenta com muitos agentes.
Precos. O preco do complemento de QA autonomo nao e publicado; estimativas da comunidade o colocam em torno de $35/agente/mes, e o pacote WFM + QA agrupado e de 50 $/agente/mes, tudo em cima de um plano base de 19 a 115 $/agente.
Minha opiniao: Se voce esta no Zendesk, esta e a escolha padrao e uma boa. Tem avaliacao de 4,9/5 no Capterra (amostra pequena, n=23). Apenas calcule o custo acumulado do complemento e lembre-se de que ele pontua as conversas apos o fato em vez de pre-testar seu bot.
3. MaestroQA
Melhor para: equipes enterprise que querem pontuacao profunda, transparente e customizavel.
O MaestroQA comecou como uma ferramenta de QA para contact centers em 2017 e se reposicionou como uma "plataforma de dados de conversacao", usada por organizacoes de suporte na Etsy, DraftKings, Stitch Fix e Brex. Fica no extremo enterprise e merece isso.
O que ele faz. O AutoQA analisa 100% dos tickets e direciona explicitamente os revisores humanos para onde o julgamento importa. O destaque e a Plataforma de IA, um motor de prompt para metrica onde voce escreve a regra, a testa em tickets reais e ve o raciocinio antes de lacar, posicionado contra "ferramentas de caixa preta". Adicione analise de causa raiz potenciada por GPT e calibracao de IA.
Pontos fortes.
- Customizacao profunda. Um operador de suporte que o usou em varias empresas disse que "permite um grande grau de customizacao" e se adequa a "ambientes maiores onde voce tem metricas mais orientadas por dados."
- Pontuacao transparente e controlavel (voce ve o raciocinio).
- Forte integracao com Zendesk e 16+ conectores.
Limitacoes.
- Apenas sob consulta e caro. O G2 marca o custo percebido na faixa mais alta "$$$$$", e uma desvantagem recorrente e que "os recursos de IA exigem compra adicional que aumenta significativamente o custo."
- Aproximadamente 3 meses de implementacao; pesado para equipes pequenas.
"Usei o Maestro em algumas empresas e geralmente fiquei satisfeito... ele permite um grande grau de customizacao. Os novos recursos baseados em IA sao meio interessantes, mas nao os implantei, entao nao posso falar sobre o quanto realmente funcionam."
Brosenjew, r/Zendesk
Minha opiniao: A escolha para uma equipe de QA seria e bem equipada que quer ser dona do seu criterio e ver o raciocinio por tras de cada pontuacao. Tem avaliacao de 4,7/5 de 324 avaliacoes do G2. Equipes menores o acharao excessivo, e voce nao pode verificar o preco sem uma ligacao de vendas.
4. EvaluAgent
Melhor para: equipes de medio porte que querem QA mais coaching, com precos que voce pode ver de verdade.
O EvaluAgent e uma plataforma britanica de QA e inteligencia de conversacoes que promete "visibilidade completa de cada agente, humano e de IA". E a rara ferramenta nesta categoria que publica precos orientativos, o que eu aprecio.
O que ele faz. AutoQM pontua cada conversa automaticamente em voz, chat e e-mail, com itens de linha de IA SmartScore que anexam raciocinio a cada pontuacao. Scorecards mesclados combinam verificacoes automaticas com observacao humana ("a IA cuida do rotineiro, as pessoas cuidam do julgamento"), e o Motor de Contexto tem um console de teste para experimentar alteracoes de pontuacao em conversas arquivadas antes de entrar em producao. Sua observabilidade de agentes de IA classifica bots de qualquer fornecedor em relacao a sua base de conhecimento, incluindo deteccao de alucinacoes.
Pontos fortes.
- Um dos ciclos de coaching mais completos da categoria: 1 a 1, planos prontos para RH, gamificacao, contestacoes de agentes.
- Precos genuinamente transparentes e um CSM dedicado em cada nivel.
- Forte postura de conformidade (SOC 2 Tipo II, ISO 27001, LGPD, HIPAA), adequado para setores regulamentados.
Limitacoes.
- A configuracao do scorecard e o ponto de atrito. A principal reclamacao de um avaliador do G2: "o tempo e a clareza necessarios para projetar um scorecard... o construtor de scorecard assistido por IA deveria ser melhorado."
- A interface tem uma curva de aprendizado para iniciantes, de acordo com o G2.
Precos. Publicados e por assento.
| Plano | Preco | Para |
|---|---|---|
| AutoQM & Melhoria | A partir de 35 $ / usuario / mes | Agentes humanos: pontuacao automatica + coaching |
| AutoQM + Inteligencia de Conversacoes | A partir de 65 $ / usuario / mes | Adiciona sentimento, intencao, VoC preditivo |
| AutoQM para agentes de IA | A partir de 0,05 $ / conversa | Pontuacao de qualidade de bots |
| Pacote completo para agentes de IA | A partir de 0,13 $ / conversa | QA de bots + inteligencia de conversacoes |
Minha opiniao: Meu favorito entre as ferramentas de scorecard dedicadas para equipes de medio porte. Tem avaliacao de 4,5/5 de 440 avaliacoes do G2, a profundidade do coaching e real, e voce pode realmente orcamentar. Apenas planeje tempo para a configuracao do scorecard.
5. Loris (agora Contentsquare Conversation Intelligence)
Melhor para: analise de conversacoes e voz do cliente em escala.
O Loris tem uma origem incomum que vale saber: comecou como um spin-off com fins lucrativos da Crisis Text Line, o que se tornou uma notavel controversia de privacidade em 2022, e foi adquirido pela Contentsquare em 2025. Agora e distribuido como a linha de Inteligencia de Conversacoes da Contentsquare.
O que ele faz. O QA automatizado avalia cada conversa e, importante, vincula sinais de qualidade a resultados reais como contatos repetidos e escalonamentos para que a pontuacao nao seja um numero de vaidade. Conversation Insights revelam intencao e mudancas de sentimento ao longo do tempo, e a analitica de agentes de IA rastreia contencao do bot, transferencias e abandonos.
Pontos fortes.
- Profundidade analitica e marcacao de intencao pronta para uso que os avaliadores destacam.
- Equipe de implementacao e suporte excepcional (o elogio mais consistente no G2).
- Vincula o QA a resultados, nao apenas as taxas de aprovacao no criterio.
Limitacoes.
- O sentimento nao e perfeito. O proprio resumo do G2 sinaliza que a IA "pode nao representar sempre com precisao o sentimento do cliente", o que importa para uma ferramenta cuja proposta e a pontuacao automatizada.
- Agora e um recurso de uma suite analitica maior, nao um fornecedor de QA independente.
- Apenas sob consulta, voltado para enterprise, e a pequena amostra do G2 (11 avaliacoes) dificulta a validacao coletiva.
Minha opiniao: Solido se voce quer analise de conversacoes e VoC junto com QA, e esta confortavel em comprar no ecossistema da Contentsquare. Tem avaliacao de 4,8/5 no G2, mas a baixa contagem de avaliacoes e a mudanca de propriedade sao consideracoes reais.
6. Level AI
Melhor para: contact centers que querem AutoQA semantico mais assistencia em tempo real.
O Level AI se posiciona como a "camada de inteligencia e orquestracao para a experiencia do cliente", analisando 100% das interacoes em voz, chat e e-mail usando compreensao semantica em vez de correspondencia de palavras-chave.
O que ele faz. Seu motor QA-GPT usa um LLM treinado em seus proprios dados para avaliar mais de 90% dos padroes de scorecard, incluindo itens subjetivos, e entrega pontuacoes transparentes com evidencias de suporte. Combina isso com gravacao de tela do agente, assistencia AgentGPT em tempo real e um modulo de coaching.
Pontos fortes.
- NLU semantico pontua itens subjetivos do criterio, nao apenas frases exatas. Um operador: "passamos de pontuar manualmente 1-2% de nossas ligacoes para pontuar 100%."
- Assistencia em tempo real mais gravacao de tela com forte reducao, valorizada em setores regulamentados.
Limitacoes.
- A precisao de pontuacao ainda esta amadurecendo — a desvantagem mais comum no G2. Um avaliador notou que o sistema "pode penalizar o agente" por nao usar uma palavra exata mesmo quando claramente cumpriu.
- Apenas sob consulta com uma pagina de precos publica que retorna erro 404, e aproximadamente 3 meses de implementacao.
- Construido para call/contact centers; pesado para uma pequena equipe baseada em tickets.
"Tornou o QA significativo para minha equipe. Era facil de configurar e usar." (A desvantagem: "A configuracao do prompt requer algum ajuste para ficar exatamente certa.")
Avaliador validado, Level AI no G2
Minha opiniao: Uma escolha solida para contact centers, avaliado em 4,7/5 de 200 avaliacoes do G2. A camada em tempo real e o diferencial. Espere ter que ajustar a pontuacao e falar com vendas para obter um numero.
7. Playvox by NiCE
Melhor para: equipes que querem QA integrado a uma suite completa de gestao de forca de trabalho.
O Playvox e uma suite de engajamento de forca de trabalho digital-first (QA, WFM, coaching, aprendizagem, VoC, gamificacao) que foi adquirida pela NiCE em outubro de 2024 e esta sendo incorporada na pilha CXone.
O que ele faz. AutoQA (construido sobre sua aquisicao do Prodsight) estende o QA a 100% das interacoes com pontuacao baseada em sentimento, e fica em uma suite ao lado de WFM e coaching. Conecta-se ao Zendesk, Salesforce, Freshdesk, Kustomer e Help Scout.
Pontos fortes.
- Amplitude: QA, WFM, coaching, aprendizagem e gamificacao em uma plataforma.
- Fortes integracoes nativas (20+) e um tema dominante de facilidade de uso nas avaliacoes.
- Avaliacoes muito altas: 4,8/5 em 1.163 avaliacoes do G2.
Limitacoes.
- Incerteza pos-aquisicao. A NiCE lidera com o angulo de WFM, o site independente esta esvaziado e o roadmap esta em fluxo.
- As desvantagens no G2 sinalizam relatorios fracos e customizacao limitada.
- Apenas sob consulta, sem versao gratuita, e um peso de suite ampla que e pesado para uma equipe pequena.
Minha opiniao: Faz mais sentido se voce quer QA como parte de uma pilha completa de gestao de forca de trabalho, especialmente se ja esta indo em direcao ao NiCE CXone. Como uma ferramenta de QA focada e em evolucao independente, e menos certa do que era ha um ano.
8. Cresta
Melhor para: grandes operacoes de voz enterprise que querem coaching em tempo real.
O Cresta e uma plataforma de IA de CX enterprise surgida do Stanford AI Lab em 2017, com mais de 280 milhoes de dolares captados, servindo grandes operacoes de voz como United Airlines, Marriott e Verizon. Bem financiada, em escala e inequivocamente enterprise.
O que ele faz. O Cresta Quality Management pontua automaticamente 100% das conversacoes com IA generativa, correlaciona comportamentos dos agentes a resultados de negocio e pontua tanto agentes humanos quanto virtuais em um unico criterio. Sua assinatura e a Assistencia ao Agente em tempo real, treinando agentes ao vivo no meio de uma conversa em vez de apenas apos a ligacao.
Pontos fortes.
- Tempo real, nao apenas pos-ligacao. Um diretor da Holiday Inn Club Vacations: "O Cresta e instantaneo... e 100% melhor porque e coaching instantaneo."
- Cobertura de 100% com resultados quantificados. Um VP da Oportun: "passamos de uma abordagem de amostragem para 100% de QA" com uma reducao de 50% na carga de trabalho da equipe de QA.
- Nomeado lider na Forrester Wave for Conversation Intelligence, Q2 2025.
Limitacoes.
- Apenas para enterprise. O proprio ICP do Cresta cita "250+ funcionarios" e "250 M$+" em receita, e lista pequenas empresas como nao ideais.
- Precificacao opaca e baseada em modulos que exige um ciclo de vendas para estimar.
- As integracoes sao lideradas por servicos. Um ex-funcionario no Reddit notou que elas sao "todas gerenciadas por uma equipe de servicos profissionais."
Minha opiniao: Se voce gerencia um grande contact center de voz e quer coaching ao vivo, o Cresta e um lider genuino, mesmo com um modesto 4,2/5 de 43 avaliacoes do G2. Para um helpdesk moderno baseado em tickets ou uma equipe pequena, tem a forma errada e o orcamento errado.
Entao, qual voce realmente escolhe?
Apos viver neste espaco, a decisao e menos "qual ferramenta e melhor" e mais "o que voce esta fazendo QA":
- Voce esta pontuando agentes humanos em um helpdesk: Zendesk QA se estiver no Zendesk, EvaluAgent se quiser precos transparentes e coaching, MaestroQA se for enterprise e quiser ser dono do criterio.
- Voce gerencia uma grande operacao de voz: Cresta ou Level AI para a camada em tempo real, ou Playvox se quiser integrado ao WFM.
- Voce esta colocando um agente de IA na sua fila: comece com QA na propria IA. Essa e a conversa mais propensa a enviar uma resposta confiante-mas-errada, e e aquela que uma ferramenta de scorecard so detecta depois que o cliente ja a viu.
Esse ultimo ponto e o que eu mais enfatizaria, porque e a lacuna que vejo as equipes caindo. Voce pode comprar a melhor plataforma de scorecard desta lista e ainda ter seu agente de IA dizendo coisas erradas aos clientes, porque o QA acontece apos a resposta. A solucao e fazer QA no bot antes de ele falar.
Experimente o eesel para QA de agentes de IA
Se voce esta implantando um agente de suporte por IA, e aqui que o eesel merece seu lugar na lista. Em vez de esperar para avaliar as respostas da IA depois que os clientes as viram, o modo de simulacao do eesel repete milhares de seus tickets historicos reais e mostra exatamente como a IA teria respondido, o que teria resolvido e onde teria errado — antes de entrar em producao. Entao o roteamento baseado em confianca impede que ela responda quando esta insegura.

Conecta-se ao seu helpdesk existente em minutos, aprende com seus tickets resolvidos e e gratis para testar sem cartao de credito. Se sua verdadeira preocupacao com o suporte por IA e "ele vai responder errado", essa e exatamente a preocupacao para a qual o eesel foi construido para resolver. Experimente o eesel.
Perguntas frequentes
Qual e a melhor IA para QA de suporte ao cliente em 2026?
Quanto custa um software de QA de suporte com IA?
A IA pode realmente pontuar 100% das conversas de suporte?
O que devo procurar em uma ferramenta de QA de suporte com IA?
O QA de suporte por IA e diferente de fazer QA de um agente de IA?
O Zendesk tem controle de qualidade por IA integrado?
Como faco QA de um agente de suporte por IA antes de colocado em producao?

Article by
Riellvriany Indriawan
Riell is a designer and writer at eesel AI with about two years of experience researching CX platforms, AI chatbots, and helpdesk software. She combines her design background with a sharp eye for how these tools actually look and feel in practice — making her comparisons unusually visual and user-focused.