品質保証(QA: Quality Assurance)スコアカードは、本格的なカスタマーサポート業務のバックボーンです。これらは、エージェントの会話を体系的にレビューし、測定可能なフィードバックを提供し、チームが一貫したエクスペリエンスを提供できるようにするための評価フォームです。スコアカードがなければ、本質的に盲目的に飛行し、エージェントがその業務を測定または改善するための構造化された方法なしに、エージェントがうまく機能することを期待することになります。
Zendesk QAを使用すると、ヘルプデスクでこれらのスコアカードを直接作成するためのツールが提供されます。ただし、効果的なスコアカードを作成するには、設定画面をクリックするだけでは不十分です。何を測定するか、さまざまな要素にどのように重み付けするか、単に数値を生成するだけでなく、実際に改善を促進するシステムをどのように設計するかを理解する必要があります。
このガイドでは、初期設定から高度な構成まで、Zendesk QAスコアカードの作成プロセス全体を説明します。初めてスコアカードを作成する場合でも、既存のスコアカードを改良する場合でも、すぐに実行できる実践的な手順が見つかります。また、手動レビューを超えることを検討している場合は、eesel AIがZendeskと統合してQAプロセスの一部を自動化する方法を紹介します。
必要なもの
Zendesk QAでスコアカードの作成を開始する前に、次のものがあることを確認してください。
- Quality Assurance(QA)またはWorkforce Engagement Management(WEM)アドオンを備えたZendeskアカウント
- スコアカードを作成および構成するための管理者アクセス権
- サポート目標と、チームにとって最も重要なKPI(Key Performance Indicator)についての明確な理解
- 特定のコンテキストにおける品質の意味に関するエージェントからのインプット
オプションですが推奨:eesel AIが自動会話分析で手動QAの取り組みをどのように補完できるかを検討してください。
ステップ1:スコアカード設定にアクセスする
スコアカードの作成を開始するには、品質保証(QA)設定に移動します。

まず、Zendesk QAワークスペースを開きます。右上隅にあるプロファイルアイコンをクリックし、**[設定]を選択します。アカウントのサイドバーで、[スコアカード]**をクリックします。これは、すべてのQAスコアカードを管理するための中央ハブです。
**[作成]をクリックし、ドロップダウンから[スコアカード]**を選択します。新しいスコアカードの基本設定を構成できるフォームが表示されます。
ステップ2:基本的なスコアカード設定を構成する
名前とワークスペースの割り当てを使用して、スコアカードの基礎を確立します。
スコアカードのわかりやすい名前を入力します。「一般的なサポートQA」または「テクニカルサポートレビュー」のようなものが適切です。この名前は、レビュー担当者にとって、このスコアカードが何のためのものかをすぐに明確にする必要があります。
次に、このスコアカードを適用するワークスペースを選択します。**[ワークスペース]で、このスコアカードで手動でレビューするワークスペースを選択します。[AutoQAが有効になっているワークスペース]**で、自動スコアリングを適用するワークスペースを選択します。
ワークスペースの選択について慎重に検討してください。チーム(セールスサポートとテクニカルサポート)またはチャネル(メール、チャット、電話)ごとに異なるスコアカードが必要になる場合があります。明確なユースケースごとに個別のスコアカードを作成すると、レビューの焦点を絞り、関連性を維持できます。
ステップ3:評価カテゴリを作成して追加する
評価する会話の側面を定義します。
**[カテゴリを追加]をクリックして、評価基準の作成を開始します。Zendesk QAを使用すると、既存のカテゴリから選択したり、名前を入力して[カテゴリを作成]**を選択して新しいカテゴリを作成したりできます。
選択するカテゴリは、サポート品質にとって最も重要なものを反映している必要があります。カスタマーサービス品質ベンチマークレポートによると、最も人気のある評価カテゴリは次のとおりです。
- 解決策(ソリューション):エージェントは顧客の問題を解決しましたか?
- 文法(グラマー):応答は適切に書かれていて、プロフェッショナルでしたか?
- トーン:エージェントはインタラクションに適した声(トーン)を一致させましたか?
- 共感(エンパシー):エージェントは顧客の状況を理解していることを示しましたか?
- パーソナライゼーション:エージェントは顧客を個人として扱いましたか?
- 内部プロセスの遵守:エージェントは会社の手順を遵守しましたか?
- 期待を超える:エージェントは基本的な期待を超えましたか?
**[グループセクションを追加]**を使用して、関連するカテゴリをグループにまとめることができます。これにより、レビュー担当者は複雑なスコアカードをより簡単にナビゲートできます。
合計で3〜7個のカテゴリを目指してください。少なすぎると、エージェントのパフォーマンスに関する十分な洞察が得られません。多すぎると、意思決定の疲労と一貫性のないスコアリングが発生します。ベンチマークレポートによると、平均的なスコアカードには14個のカテゴリがありますが、中央値はより管理しやすい8個です。
ステップ4:評価尺度(レーティングスケール)と重みを選択する
各カテゴリのスコアリング方法を決定します。

各カテゴリについて、レビューのスタイルに合った**[評価尺度(レーティングスケール)]**を選択します。
- バイナリ(2点):良い/悪い評価のみの最速のオプション。スピードがニュアンスよりも重要な大量のチームに最適です。
- 3点:「満足」の中間のオプションを追加します。それでも評価は迅速ですが、レビュー担当者により多くの柔軟性が与えられます。
- 4点:中立的なオプションを削除することにより、決定的な評価を強制します。レビュー担当者は、良い/やや良いまたはやや悪い/悪いを選択する必要があります。
- 5点:最も詳細なスケールで、学術的な評価に似ています。ニュアンスのあるフィードバックを提供しますが、評価に時間がかかります。
小規模なスケールは、大量の迅速で一貫性のあるレビューに最適です。大規模なスケールは、コーチングと品質改善のためにより詳細な情報を提供します。
各カテゴリの**[重み]**(0〜100)を設定して、その重要性を定義します。デフォルトは10ですが、優先順位に基づいてこれを調整する必要があります。共感がブランドにとって重要な場合は、文法よりも高い重みを付けます。重みフィールドにカーソルを合わせると、それが全体的な品質スコアにパーセンテージとしてどのように変換されるかが表示されます。
カテゴリを**[重要]**としてマークすることもできます。重要なカテゴリで50%未満の評価は、レビュー全体を失敗させ、0%のスコアになります。これは、規制遵守または必須の動作を追跡するのに役立ちます。
ステップ5:条件付きロジックと根本原因を設定する
よりターゲットを絞ったレビューのために高度な機能を追加します。
**[特定の条件下でのみスコアカードに表示する]**を選択して、特定の会話タイプでのみカテゴリを表示します。これにより、無関係なカテゴリを非表示にすることで、レビュー担当者の時間を節約できます。
次の条件に基づいて条件を作成できます。
- ソースタイプ:チケットソースごとに異なるスコアカード
- 会話チャネル:メール、チャット、電話、またはソーシャルメディア
- ヘルプデスクタグ:チケットタイプを示す特定のタグ
- 満足度スコア(CSAT):満足している顧客と不満な顧客で異なる基準
たとえば、顧客が回答に完全に満足していなかったことを示すCSATスコアが3以下の会話でのみ、「製品知識」カテゴリを表示する場合があります。
**[評価を説明するために根本原因を追加する]**を有効にして、レビュー担当者に詳細なフィードバックを求めます。肯定的な評価と否定的な評価に対して、個別の根本原因リストを定義できます。これにより、エージェントは自分が何をしたかだけでなく、なぜそれが重要だったのかを理解できます。
また、レビュー担当者が複数の根本原因を選択し、標準外の説明のためにコメントフィールド付きの「その他」オプションを提供できるようにすることもできます。
ステップ6:スコアカードを公開して使用を開始する
レビューのためにスコアカードを確定してアクティブ化します。
公開する前に、すべての設定を確認してください。カテゴリがサポート目標と一致し、重みが優先順位を反映し、条件付きロジックが正しく構成されていることを再確認してください。
**[公開]をクリックしてスコアカードをレビュー担当者が利用できるようにするか、ライブに移行する前にさらにインプットを収集する必要がある場合は[下書きとして保存]**をクリックします。
公開したら、新しいスコアカードについてレビュー担当者をトレーニングします。各カテゴリを説明し、評価尺度(レーティングスケール)を説明し、さまざまなスコアが実際に何を意味するかを話し合います。複数のレビュー担当者が同じ会話を評価し、結果を比較するキャリブレーションセッションをスケジュールします。これにより、バイアスが排除され、チーム全体で一貫したスコアリングが保証されます。
効果的なZendesk QAスコアカード作成のヒント
実際にサポート品質を向上させるスコアカードを作成するには、設定手順に従うだけでは不十分です。留意すべきベストプラクティスを次に示します。
**シンプルに始めて、徐々に拡張します。**すべてを一度に測定しようとするのではなく、3〜5個のコアカテゴリから開始します。QAプログラムが成熟するにつれて、いつでもカテゴリを追加できます。
**カテゴリを実際の顧客の期待と一致させます。**重要だと思うものを測定するだけでなく、実際に顧客満足度を高めるものを測定します。CSATフィードバックを確認して、顧客が最も気にかけていることを特定します。
**チャネルごとにカスタマイズします。**メールのスコアカードは、文法と完全性を重視する必要があります。チャットのスコアカードは、応答時間とマルチタスクに焦点を当てる必要があります。電話のスコアカードは、トーン、ペース、およびアクティブリスニングを評価する必要があります。
**エージェントをプロセスに関与させます。**彼らは評価される側であるため、品質を構成するものに関する彼らのインプットは貴重です。スコアカードの作成を支援するエージェントは、QAプロセスを購入する可能性が高くなります。
**定期的にレビューして反復処理を行います。**スコアカードは固定されていません。四半期ごとのレビューをスケジュールして、カテゴリがまだ関連性があるかどうか、および重みが優先順位を正確に反映しているかどうかを確認します。
Zendesk QAスコアカード作成で避けるべき一般的な間違い
経験豊富なサポートリーダーでさえ、QAプログラムを構築する際にこれらのエラーを犯します。
**カテゴリが多すぎる。**レビュー担当者が15個以上のカテゴリに直面すると、評価を急いで行ったり、一貫性のない評価を行ったりします。焦点を絞ってください。
あいまいなカテゴリ定義を使用する。「良いトーン」は人によって意味が異なります。各スコアレベルがどのようなものかを具体的な例で定義します。
**戦略なしに任意の重みを設定する。**簡単だからといって、すべてのカテゴリに同じ重みを付けないでください。どのカテゴリが実際に顧客満足度とビジネス成果に影響を与えるかを検討してください。
**エージェントのフィードバックを無視する。**エージェントが特定のカテゴリまたは評価について一貫して質問する場合は、彼らに耳を傾けてください。彼らはスコアカードのデザインに実際の問題を特定している可能性があります。
**スコアカードを1回限りのプロジェクトとして扱う。**市場は変化し、製品は進化し、顧客の期待は変化します。スコアカードも進化する必要があります。
自動化によるQAのさらなる発展
手動QAには根本的な制限があります。効率的なチームでさえ、会話の約2%しかレビューできません。つまり、顧客とのやり取りの98%は評価されていません。実際のサポートボリュームのほんの一部のサンプルに基づいて、トレーニング、コーチング、およびプロセス改善に関する意思決定を行っています。
AI(人工知能)を活用したQAは、この方程式を変えます。サンプリングする代わりに、会話の100%を自動的に分析できます。これは、手動スコアカードに取って代わるものではありません。それらを補完します。
eesel AIはZendeskと連携して、自動会話分析を提供します。当社のAIはすべてのインタラクションをレビューし、サポートボリューム全体のパターンを特定し、人間の注意が必要な会話を強調表示します。自動化の広範なカバレッジと、最も重要な場合に人間のレビュー担当者のニュアンスのある判断が得られます。
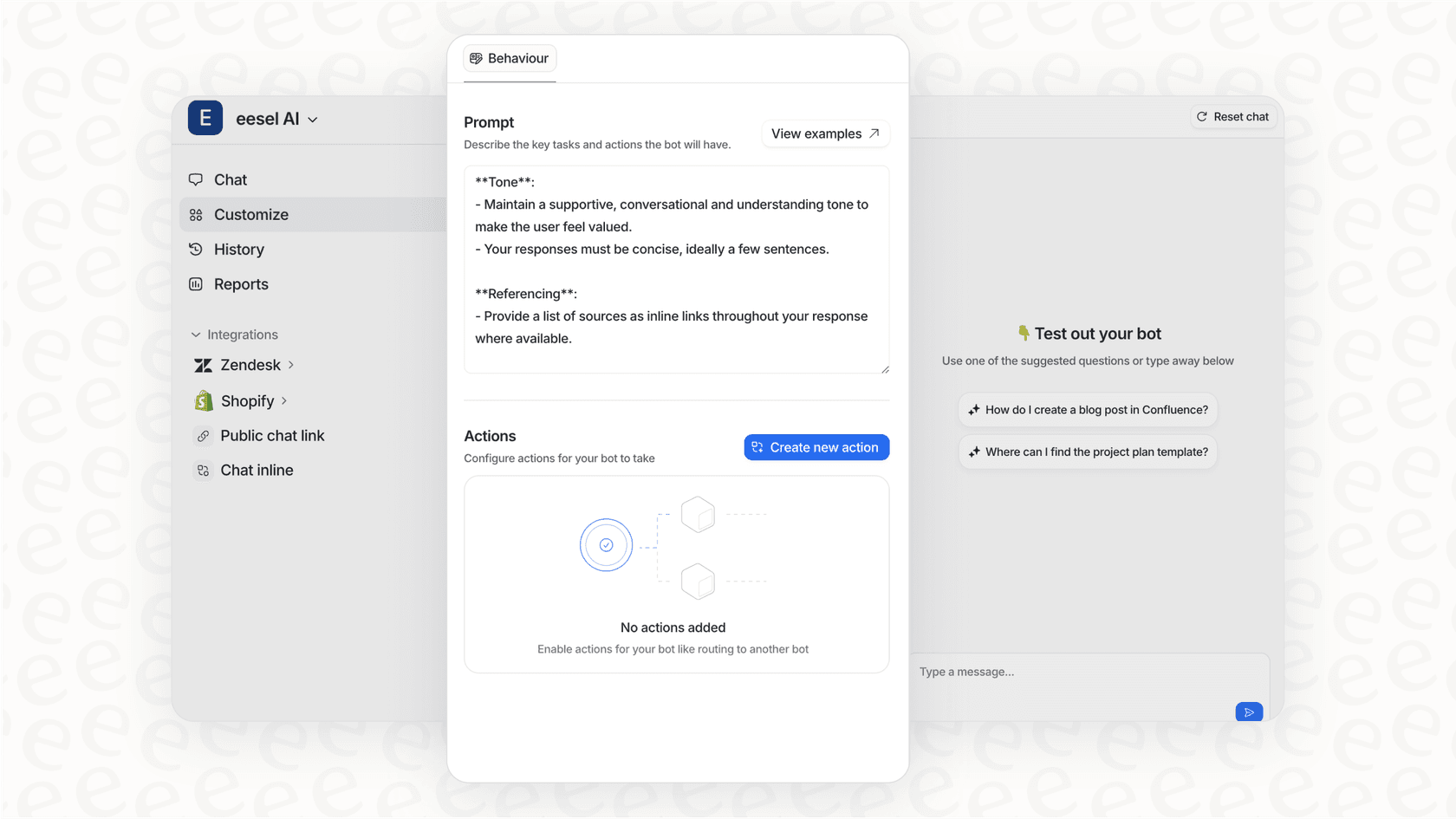
すでにZendesk QAを使用しているチームの場合、eesel AIは会話を事前にスクリーニングし、手動レビューに値する会話にフラグを立てることができます。チケットをランダムにサンプリングする代わりに、レビュー担当者はコーチングの機会またはプロセス改善が含まれている可能性が最も高いインタラクションに焦点を当てます。
Zendesk QAの構造化されたスコアカードとeesel AIのAIを活用した分析を組み合わせることで、品質保証プログラムに深さと幅の両方を提供します。スコアカードが提供する詳細な基準ベースの評価と、自動化のみが提供できる包括的なカバレッジが得られます。
手動レビューを超える準備ができている場合は、eesel AIの価格をチェックして、包括的なQAカバレッジがどれだけ手頃な価格になるかを確認してください。
よくある質問
Share this article

Article by
Stevia Putri
Stevia Putri is a marketing generalist at eesel AI, where she helps turn powerful AI tools into stories that resonate. She’s driven by curiosity, clarity, and the human side of technology.