ブログ
AIチームメイト、スマートなサポート、より良いチーム作りに関するヒント、ガイド、インサイト。

2026年版:Tidio Lyroの代替ツール7選
Lyroの会話ごとの料金体系はすぐに積み上がり、Tidioの中だけでしか使えません。2026年に試す価値のある代替ツールを7つ紹介します。ヘルプデスクネイティブのAIから無料ライブチャットまで。
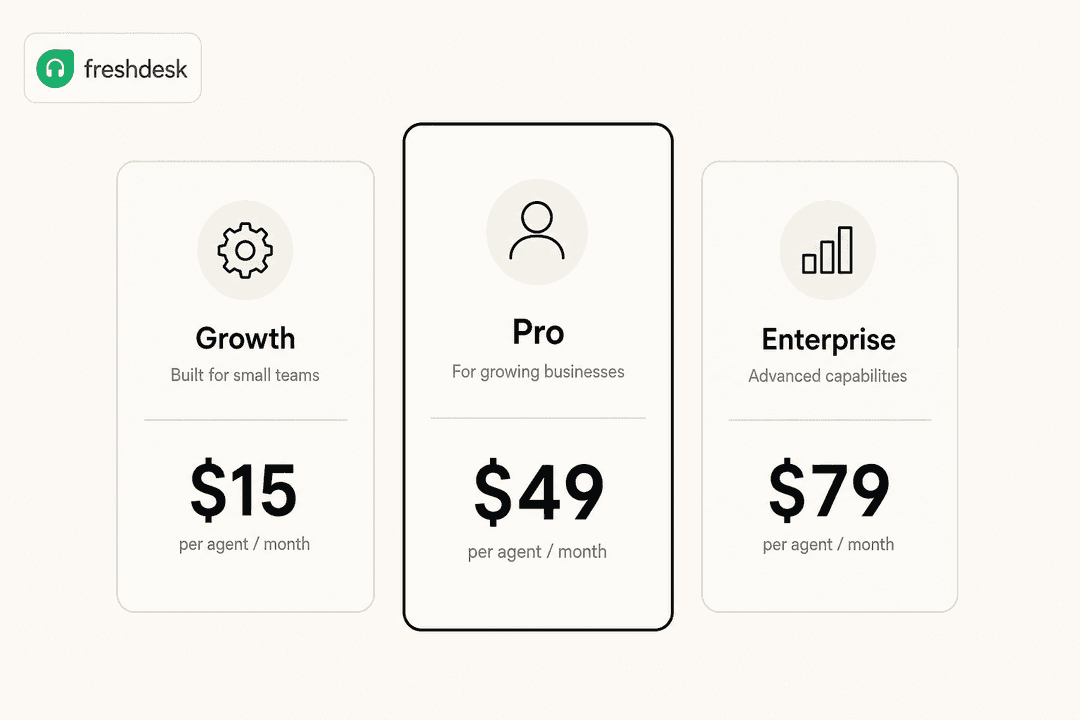
Freshdesk Freddy AI料金の解説:2026年に実際に支払う金額
Freddy AIは3つの独立した製品で、それぞれ異なる価格設定がされています。各製品のコスト、プランに含まれる内容、そしてチームが驚くことが多いポイントについて解説します。

2026年のFreshdesk Freddy代替ツール6選
Freddy AIのセッション料金はすぐに高額になります。移行不要でFreshdeskの上で動く1つを含む、Freshdesk Freddyの代替ツール6選を紹介します。
GorgiasのShopify自動化の設定方法(2026年完全ガイド)
GorgiasはShopifyストア向けに4つの異なる自動化レイヤーを提供しています。それぞれの仕組み、最初に設定すべきもの、そして限界について解説します。
GorgiasのShopifyチャットバブル:完全なセットアップとカスタマイズガイド(2026年)
GorgiasのチャットバブルについてShopifyマーチャントが知っておくべきすべてのこと — 正しいインストール方法、カスタマイズ、不具合が起きたときの修正方法、そしてAIをより実用的にする方法。

Zendesk AIエージェントレビュー(2026年):機能、料金、ユーザーの本音
2026年版Zendesk AIエージェントの実態レビュー:エージェンティックAIが何をこなせるか、AR料金モデルの仕組み、G2の6,837件のレビューとRedditコミュニティの本音。
Zendeskの最低費用:2026年に実際に支払う金額
Zendeskは$19/エージェント/月からのプランを宣伝していますが、アドオン、年間契約、シート数を考慮すると、実際の運用チームのほとんどはその2〜5倍を支払っています。

CapCutの料金体系(2026年):無料、スタンダード、プロプランの完全ガイド
CapCutの最近の料金変更に混乱していませんか?ご安心ください。2026年版ガイドでは、無料、スタンダード、プロプランを詳しく解説し、機能、費用、そして実際にお支払いいただく金額を比較します。
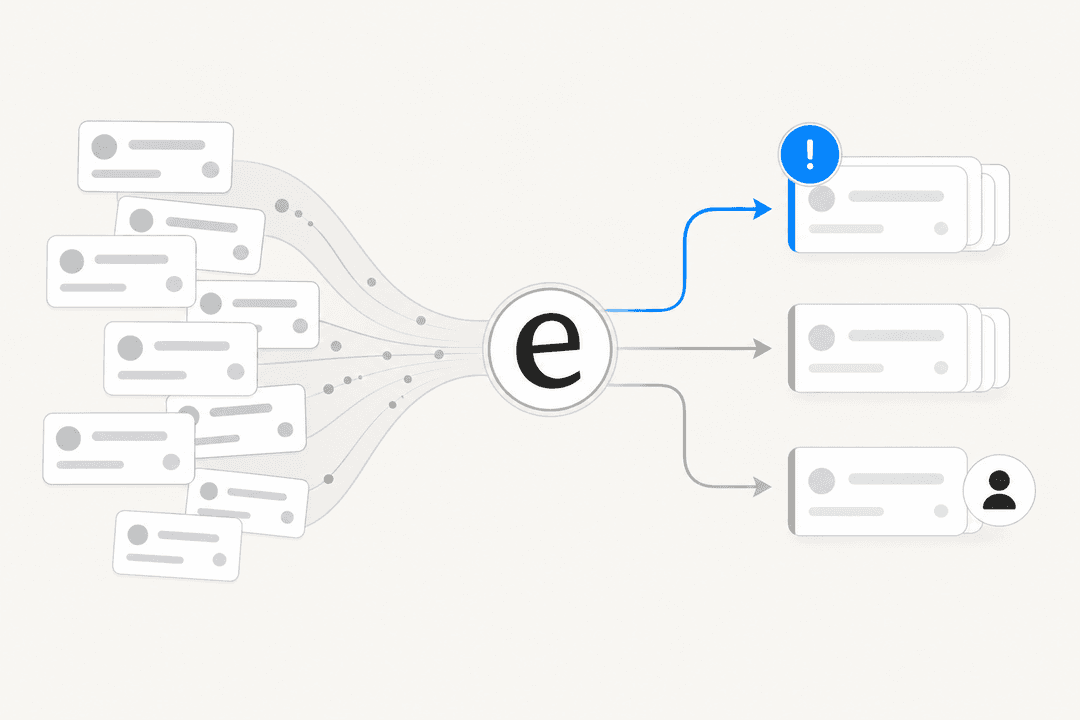
チケットトリアージを自動化する方法:サポートチーム向けのステップバイステップガイド
手動のチケットトリアージでは15〜25%のチケットが誤ルーティングされ、チームに年間数十万ドルのコストをかけています。ここでは、再割り当てを減らし、解決を速める9つのステップで自動化する方法を紹介します。
AIチームメイトを採用する準備はできましたか?
数分でセットアップ。クレジットカード不要。