
Soyons réalistes, la plupart des entreprises d'aujourd'hui sont assises sur une montagne de données. Vous avez les interactions avec les clients, les chiffres de vente, les clics sur le site web, les tickets de support... ça fait beaucoup. Le plus difficile n'est pas seulement de collecter toutes ces informations, c'est de leur donner un sens sans attendre une éternité ou dépenser une fortune.
C'est précisément le problème que Amazon Redshift a été conçu pour résoudre. C'est un entrepôt de données cloud conçu pour traiter des quantités massives de données à des fins d'analyse. Cet article est une présentation complète de Redshift pour 2025. Nous aborderons son architecture, ses points forts, le fonctionnement de sa tarification et ses limites afin que vous puissiez décider s'il vous convient.
Qu'est-ce qu'Amazon Redshift ?
Alors, qu'est-ce qu'Amazon Redshift, concrètement ? C'est la version d'AWS d'un entrepôt de données massif, basé sur le cloud. Imaginez une base de données spécialement conçue pour une seule tâche : analyser d'énormes ensembles de données (ce que les professionnels appellent le Traitement Analytique en Ligne, ou OLAP). C'est parfait pour exécuter les requêtes complexes dont vous avez besoin pour la business intelligence, le reporting et l'exploration de vos données.
Bien que ses racines soient dans PostgreSQL, Redshift a été fortement optimisé pour la vitesse d'analyse. Il n'est pas conçu pour les transactions rapides et quotidiennes que gère la base de données de votre application principale, comme le traitement d'une seule commande client. Au contraire, son objectif est de vous offrir des analyses rapides et évolutives sur de grands volumes de données, pour bien moins cher que ce que vous paieriez pour une installation traditionnelle sur site.
L'architecture fondamentale de Redshift
La vitesse de Redshift n'est pas magique ; elle repose sur une architecture intelligente conçue pour le traitement parallèle. Soulevons le rideau pour voir comment cela fonctionne.
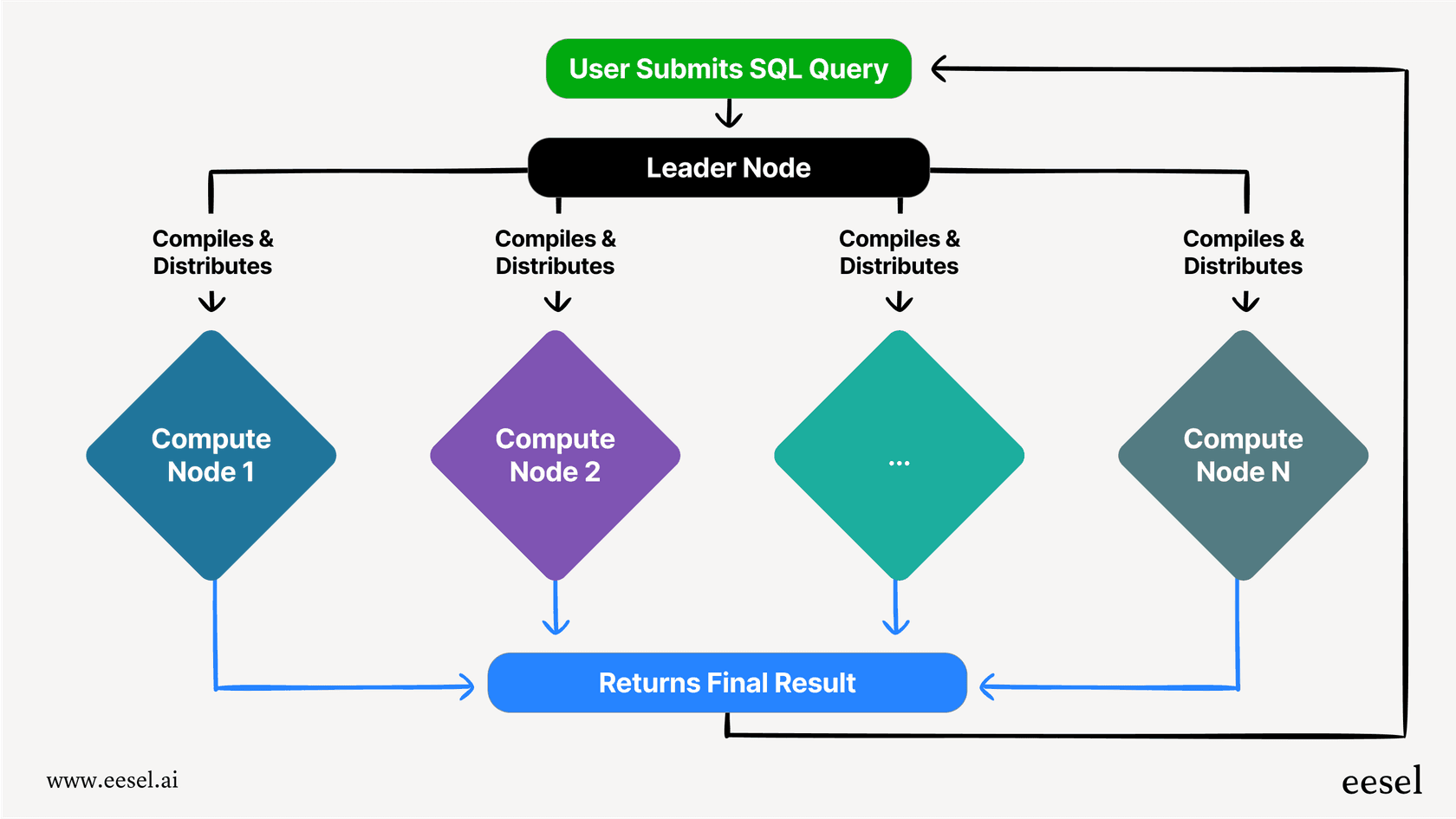
Le nœud principal et les nœuds de calcul
Chaque configuration Redshift, ou « cluster », comporte deux parties principales. D'abord, il y a le nœud principal (leader node). Vous pouvez le considérer comme le chef de projet. Lorsque votre application envoie une requête, le nœud principal la reçoit, détermine le meilleur plan pour l'exécuter, puis délègue le travail à une équipe de nœuds de calcul.
Les nœuds de calcul (compute nodes) sont ceux qui effectuent le gros du travail. Ce sont les ouvriers qui stockent vos données et exécutent réellement les parties de la requête qui leur sont assignées. Une fois leur travail terminé, ils renvoient les résultats au nœud principal, qui rassemble le tout et vous livre la réponse finale.
Le traitement massivement parallèle (MPP)
L'ingrédient secret qui rend Redshift si rapide est quelque chose appelé le Traitement Massivement Parallèle (MPP). Au lieu d'essayer de résoudre une requête géante et compliquée avec une seule machine puissante, le MPP la découpe en morceaux plus petits et plus faciles à gérer. Ces morceaux sont ensuite exécutés en même temps (en parallèle) sur tous les différents nœuds de calcul.
Imaginez que vous essayez de compter une pile massive de bulletins de vote. Une seule personne y passerait toute l'année. Mais si vous donnez une petite pile à cent personnes différentes, elles peuvent toutes compter leur pile en même temps et finir beaucoup plus vite. C'est l'idée de base derrière la façon dont Redshift traite vos requêtes.
Le stockage en colonnes
La plupart des bases de données que vous connaissez utilisent probablement un stockage par lignes. Cela signifie que toutes les informations d'un seul enregistrement (comme le nom, l'adresse et l'historique d'achat d'un client) sont stockées ensemble dans une ligne. Redshift renverse cette logique et utilise le stockage en colonnes, qui regroupe toutes les données d'une seule colonne.
Cela peut sembler être un petit détail technique, mais cela fait une énorme différence pour l'analyse. Lorsque vous exécutez un rapport, vous ne vous intéressez généralement qu'à quelques colonnes, pas à chaque donnée d'une table. Par exemple, vous voulez peut-être simplement trouver la somme totale des ventes à partir d'une immense table de transactions qui contient 50 colonnes différentes. Avec le stockage en colonnes, Redshift n'a besoin de lire que les données de la seule colonne « ventes », ignorant complètement les 49 autres. Cela réduit considérablement la quantité de données à analyser, ce qui accélère énormément l'exécution de vos requêtes.
Fonctionnalités clés et cas d'usage courants
Maintenant que vous avez une idée du « comment », parlons du « quoi ». À quoi sert réellement Redshift ?
Business Intelligence et reporting
C'est la tâche principale de Redshift. Il agit comme le moteur puissant derrière les outils de business intelligence (BI) comme Tableau, Microsoft Power BI et Amazon QuickSight. Les entreprises connectent ces outils à Redshift pour créer des tableaux de bord qui leur permettent de suivre à peu près tout, des chiffres de vente quotidiens et des performances des campagnes marketing à l'efficacité de la chaîne de production.
Analyse en temps réel sur de grands jeux de données
Redshift est également assez robuste pour gérer et analyser des flux de données en temps réel. En le connectant à des services comme Amazon Kinesis, les entreprises peuvent alimenter des systèmes de détection de fraude en direct, des classements en temps réel pour les jeux vidéo ou des tableaux de bord qui analysent les données provenant de capteurs IoT.
Agrégation de sources de données multiples
L'une des choses les plus intéressantes que Redshift peut faire est de rassembler des données de différents systèmes. Il dispose d'une fonctionnalité appelée Redshift Spectrum qui vous permet d'exécuter des requêtes sur des données se trouvant dans vos bases de données habituelles et sur des fichiers semi-structurés (comme JSON) qui sont simplement stockés dans un lac de données sur Amazon S3.
Par exemple, une entreprise pourrait combiner les données de tickets de support d'une plateforme comme Zendesk, les données de vente de son CRM et les données d'utilisation des produits de ses journaux d'application. En regroupant tout cela dans Redshift, elle peut enfin obtenir une vue unique et complète de l'ensemble du parcours client.
Tarification d'Amazon Redshift en 2025
Personne n'aime les factures surprises, il est donc très important de choisir le bon modèle de tarification pour Redshift. AWS vous propose deux principales façons de payer, et chacune est mieux adaptée à des situations différentes.
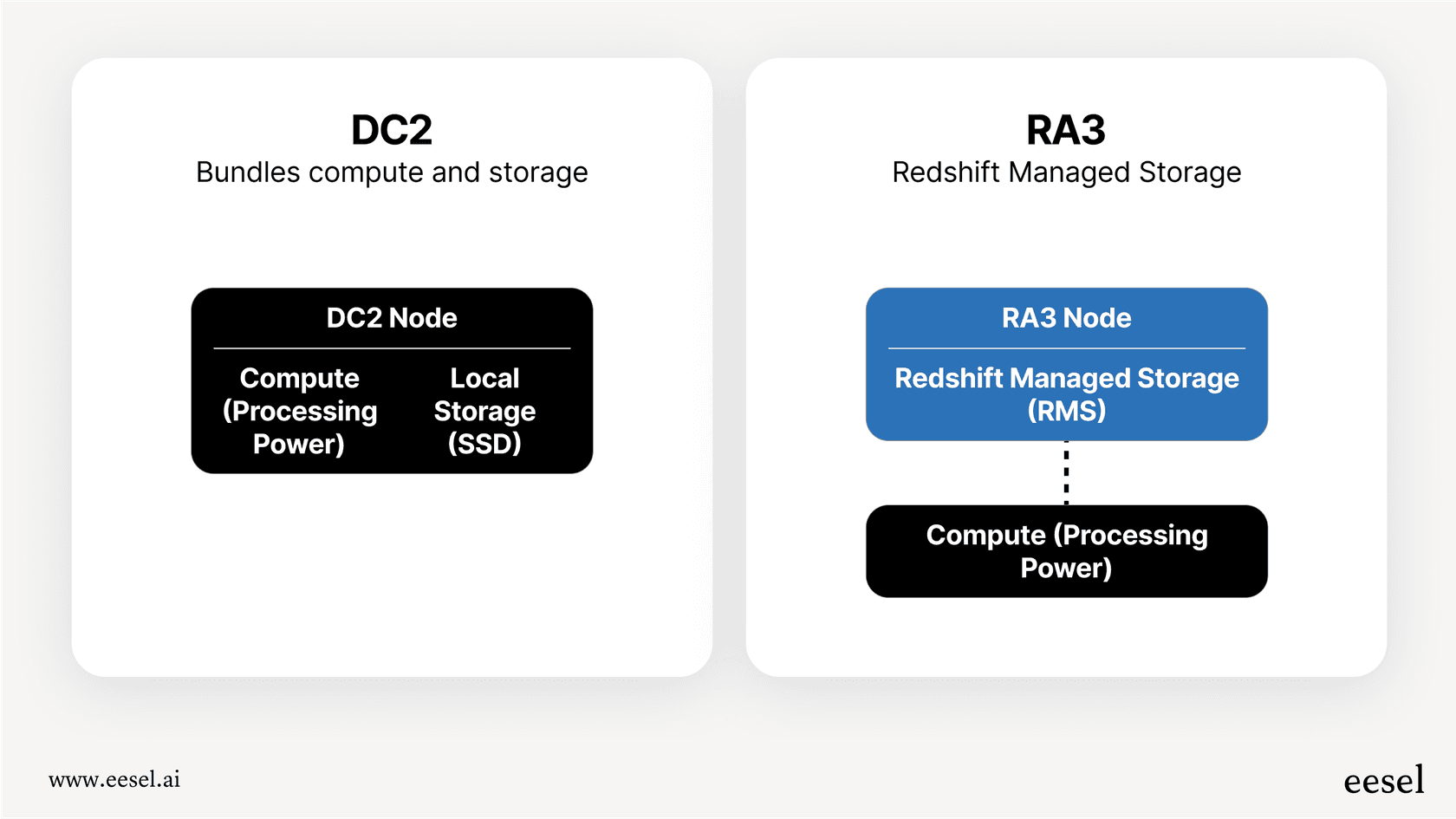
Clusters provisionnés
C'est l'approche classique. Vous choisissez le type et le nombre de serveurs (qu'AWS appelle des nœuds) que vous souhaitez, et vous les payez à l'heure. L'option la plus courante de nos jours est le type de nœud RA3, qui sépare intelligemment la puissance de calcul du stockage. Cela signifie que vous pouvez augmenter votre puissance de traitement sans avoir à payer pour plus de stockage, et vice versa. Ce modèle fonctionne bien si votre charge de travail est stable et prévisible. Si vous savez que vous en aurez besoin pendant un certain temps, vous pouvez également obtenir d'importantes réductions en vous engageant pour un ou trois ans avec des instances réservées.
Redshift sans serveur (Serverless)
C'est l'option la plus récente et la plus simple. Avec Redshift Serverless, vous n'avez plus à vous soucier des clusters ou des nœuds. AWS gère tout en coulisses, allouant automatiquement les ressources lorsque vous en avez besoin et les arrêtant lorsque vous n'en avez plus. Vous ne payez que pour le temps de calcul que vous utilisez réellement, mesuré en Unités de Traitement Redshift (RPU) par heure. C'est un excellent choix pour les charges de travail qui sont irrégulières, imprévisibles ou qui ne fonctionnent tout simplement pas 24h/24 et 7j/7.
Tableau comparatif des tarifs
Voici une comparaison rapide pour vous aider à voir la différence. Pour les chiffres les plus récents, vous devriez toujours consulter la page officielle de tarification d'AWS Redshift.
| Caractéristique | Clusters Provisionnés | Redshift Serverless |
|---|---|---|
| Modèle de coût | Paiement à l'heure par nœud (ex: 0,543 $/heure et plus) | Paiement par RPU-heure de calcul utilisé (ex: 1,50 $/heure et plus) |
| Idéal pour | Charges de travail stables, prévisibles et à fort volume | Charges de travail variables, imprévisibles ou intermittentes |
| Gestion | Vous devez planifier la capacité et gérer le cluster | Zéro administration, AWS s'occupe de tout |
| Mise à l'échelle | Mise à l'échelle manuelle ou planifiée (peut causer une brève interruption) | S'adapte automatiquement et de manière transparente à la hausse comme à la baisse |
N'oubliez pas qu'il peut y avoir d'autres coûts, comme des frais pour le stockage géré ou pour l'utilisation de Redshift Spectrum pour interroger des données dans S3.
Forces et limites de Redshift
Comme toute technologie, Redshift est excellent pour certaines choses et moins bon pour d'autres. Il est bon de connaître les deux côtés de la médaille avant de vous lancer.
Avantages : Bénéfices clés
-
Vitesse à grande échelle : Sa conception fondamentale lui permet d'exécuter des requêtes sur d'énormes ensembles de données à une vitesse incroyable.
-
Rentabilité : Il est généralement beaucoup moins cher que d'acheter et de gérer votre propre matériel d'entrepôt de données.
-
Intégration profonde avec AWS : Il fonctionne parfaitement avec toute la suite de services AWS, comme S3 pour le stockage, Glue pour la préparation des données et Kinesis pour les données en streaming.
-
Évolutivité : Vous pouvez commencer petit et faire évoluer votre entrepôt jusqu'à des pétaoctets de données à mesure que votre entreprise se développe.
Inconvénients : Pièges courants et limites
-
Conçu pour l'analyse, pas pour les transactions : Redshift est conçu pour des requêtes volumineuses et complexes. Il est en fait assez lent pour gérer de nombreuses petites mises à jour, insertions ou suppressions.
-
Il y a une courbe d'apprentissage : La version « provisionnée » n'est pas exactement prête à l'emploi. Pour en avoir pour votre argent, vous devrez vous familiariser avec des termes comme les « clés de distribution » et les « clés de tri » et savoir quand effectuer un peu de maintenance.
-
Les coûts peuvent grimper insidieusement : Si vous n'êtes pas prudent, des requêtes inefficaces ou un cluster mal configuré sur un modèle de paiement à l'usage peuvent entraîner une facture plus élevée que prévu.
-
Dépendance vis-à-vis du fournisseur : Comme il s'agit d'un service natif d'AWS, déplacer toutes vos données et processus vers un autre fournisseur de cloud plus tard pourrait s'avérer un casse-tête majeur et coûteux.
Des insights des données à l'action automatisée
Redshift est un outil incroyable pour l'analyse. Il vous aide à repérer les tendances et à trouver des informations enfouies dans vos données. Par exemple, après avoir examiné un million de tickets de support, vous pourriez découvrir qu'un quart de toutes les questions des clients concernent votre politique de retour.
Ok, vous avez trouvé cette excellente information. Et maintenant ? Habituellement, cela déclenche un tas de travail manuel. Quelqu'un doit mettre à jour la base de connaissances, rédiger de nouvelles réponses préenregistrées pour l'équipe de support, et peut-être même organiser une session de formation. C'est lent, et vous êtes toujours en train de rattraper votre retard. C'est là que vous avez besoin de quelque chose qui peut agir sur vos découvertes.
C'est là qu'un agent de support IA entre en jeu. Un outil comme eesel AI peut se connecter directement à votre service d'assistance et à toutes vos sources de connaissances. Vous pouvez l'entraîner sur les mêmes tickets de support que ceux que vous avez analysés dans Redshift, afin qu'il comprenne immédiatement votre entreprise, votre ton de marque et les bonnes réponses aux questions courantes. Au lieu de simplement rédiger un rapport qui dit « les gens posent beaucoup de questions sur les retours », vous pouvez créer un agent IA qui traite simplement ces questions instantanément.
Avec eesel AI, ce n'est pas un projet de six mois. C'est une plateforme en libre-service qui vous permet de vous lancer en quelques minutes. Vous pouvez même exécuter une simulation sur vos tickets passés pour voir exactement combien de problèmes il aurait pu résoudre automatiquement, vous donnant une image claire de son impact avant même de l'activer pour les clients.
Réflexions finales
Amazon Redshift est un entrepôt de données très puissant qui peut vous aider à extraire des informations de vastes ensembles de données, que vous construisiez des tableaux de bord de BI ou que vous fassiez des analyses approfondies. Vous pouvez choisir un cluster Provisionné pour ses coûts prévisibles ou opter pour l'option Serverless pour sa flexibilité incroyable.
Mais trouver une information ne représente que la moitié du travail. La vraie magie opère lorsque vous connectez cette analyse à une action. Automatiser la réponse aux tendances que vous découvrez est la clé pour bâtir une entreprise véritablement efficace et axée sur les données.
Prêt à transformer les données de votre support client en actions automatisées ? Essayez eesel AI gratuitement et découvrez à quelle vitesse vous pouvez commencer à automatiser votre support client.
Foire aux questions
Pouvez-vous donner un aperçu de Redshift, en expliquant ce que c'est et quel type de problèmes il est conçu pour résoudre ?
Amazon Redshift est un entrepôt de données basé sur le cloud, optimisé pour le traitement analytique en ligne (OLAP) sur des jeux de données massifs. Il est conçu pour gérer des requêtes complexes pour la business intelligence, le reporting et l'analyse approfondie des données, ce qui le différencie considérablement des bases de données transactionnelles.
Pourriez-vous donner un aperçu de l'architecture de Redshift, en particulier comment il atteint des performances de requête aussi rapides ?
Redshift atteint sa vitesse grâce au Traitement Massivement Parallèle (MPP) réparti entre un nœud principal et des nœuds de calcul, et en utilisant le stockage en colonnes. Le MPP divise les requêtes en plus petites parties exécutées simultanément, tandis que le stockage en colonnes réduit efficacement les données à analyser pour l'analytique.
Quelles sont les principales applications métiers où un aperçu de Redshift met en évidence son efficacité ?
Redshift excelle dans la business intelligence et le reporting, alimentant des tableaux de bord et des outils d'analyse. Il est également utilisé efficacement pour l'analyse en temps réel sur de grands flux de données et pour agréger des données de diverses sources en une seule vue complète.
Du point de vue d'un aperçu de Redshift, comment fonctionne sa structure tarifaire, et quelles sont les principales différences entre les clusters provisionnés et le mode sans serveur ?
Redshift propose des clusters provisionnés, où vous payez à l'heure pour des ressources fixes, idéales pour des charges de travail stables, et un mode sans serveur, où vous payez par heure de calcul pour des ressources mises à l'échelle automatiquement, ce qui est parfait pour les tâches variables ou imprévisibles.
Quelles sont les principales forces et limites à prendre en compte lors de l'examen d'un aperçu de Redshift pour ses besoins en données ?
Les forces incluent la vitesse à grande échelle, la rentabilité et une intégration profonde avec AWS. Les limites concernent son inadéquation pour les charges de travail transactionnelles, une courbe d'apprentissage pour une configuration optimale, une dérive potentielle des coûts et la dépendance vis-à-vis du fournisseur.
La gestion de Redshift nécessite-t-elle beaucoup de connaissances spécialisées, ou existe-t-il un aperçu simple de Redshift pour aider les nouveaux utilisateurs à démarrer ?
Bien que la version provisionnée nécessite de comprendre des concepts comme les clés de distribution et de tri pour des performances optimales, Redshift Serverless réduit considérablement la charge administrative. Il est donc beaucoup plus facile pour les nouveaux utilisateurs de démarrer sans avoir besoin d'une expertise technique approfondie.








