
Sejamos realistas, a maioria das empresas hoje em dia está sentada numa montanha de dados. Tem interações com clientes, números de vendas, cliques no website, tickets de suporte... é muita coisa. A parte difícil não é apenas recolher toda essa informação; é fazer sentido dela sem esperar uma eternidade ou gastar uma fortuna.
Foi exatamente para resolver esse problema que o Amazon Redshift foi criado. É um data warehouse na nuvem concebido para processar quantidades massivas de dados para análise. Este artigo é uma visão geral completa do Redshift para 2025. Vamos abordar a sua arquitetura, para que serve, como funciona o preço e as suas limitações, para que possa decidir se é a escolha certa para si.
O que é o Amazon Redshift?
Então, o que é realmente o Amazon Redshift? É a versão da AWS de um data warehouse massivo, baseado na nuvem. Pense numa base de dados que foi construída especificamente para uma tarefa: analisar enormes conjuntos de dados (o que os profissionais chamam de Processamento Analítico Online, ou OLAP). É perfeito para executar as consultas complexas de que precisa para business intelligence, relatórios e explorar os seus dados.
Embora as suas raízes estejam no PostgreSQL, o Redshift foi fortemente otimizado para a velocidade analítica. Não foi concebido para as transações rápidas e diárias que a base de dados principal da sua aplicação lida, como processar um único pedido de cliente. Em vez disso, o seu propósito é dar-lhe análises rápidas e escaláveis sobre grandes volumes de dados, por muito menos do que pagaria por uma configuração tradicional on-premise.
A arquitetura central do Redshift
A velocidade do Redshift não é mágica; resulta de uma arquitetura inteligente concebida para processamento paralelo. Vamos levantar o véu e ver como funciona.
O nó líder e os nós de computação
Cada configuração do Redshift, ou "cluster", tem duas partes principais. Primeiro, há o nó líder. Pode pensar nele como o gestor do projeto. Quando a sua aplicação envia uma consulta, o nó líder recebe-a, descobre o melhor plano para a executar e depois delega o trabalho a uma equipa de nós de computação.
Os nós de computação são os que fazem o trabalho pesado. São os trabalhadores que armazenam os seus dados e executam efetivamente as partes da consulta que lhes são atribuídas. Assim que terminam a sua parte, enviam os resultados de volta para o nó líder, que junta tudo e lhe entrega a resposta final.
Processamento massivamente paralelo (MPP)
O ingrediente secreto que torna o Redshift tão rápido é algo chamado Processamento Massivamente Paralelo (MPP). Em vez de tentar resolver uma consulta gigante e complicada com uma única máquina poderosa, o MPP divide-a em pedaços mais pequenos e manejáveis. Estes pedaços são então executados ao mesmo tempo (em paralelo) por todos os diferentes nós de computação.
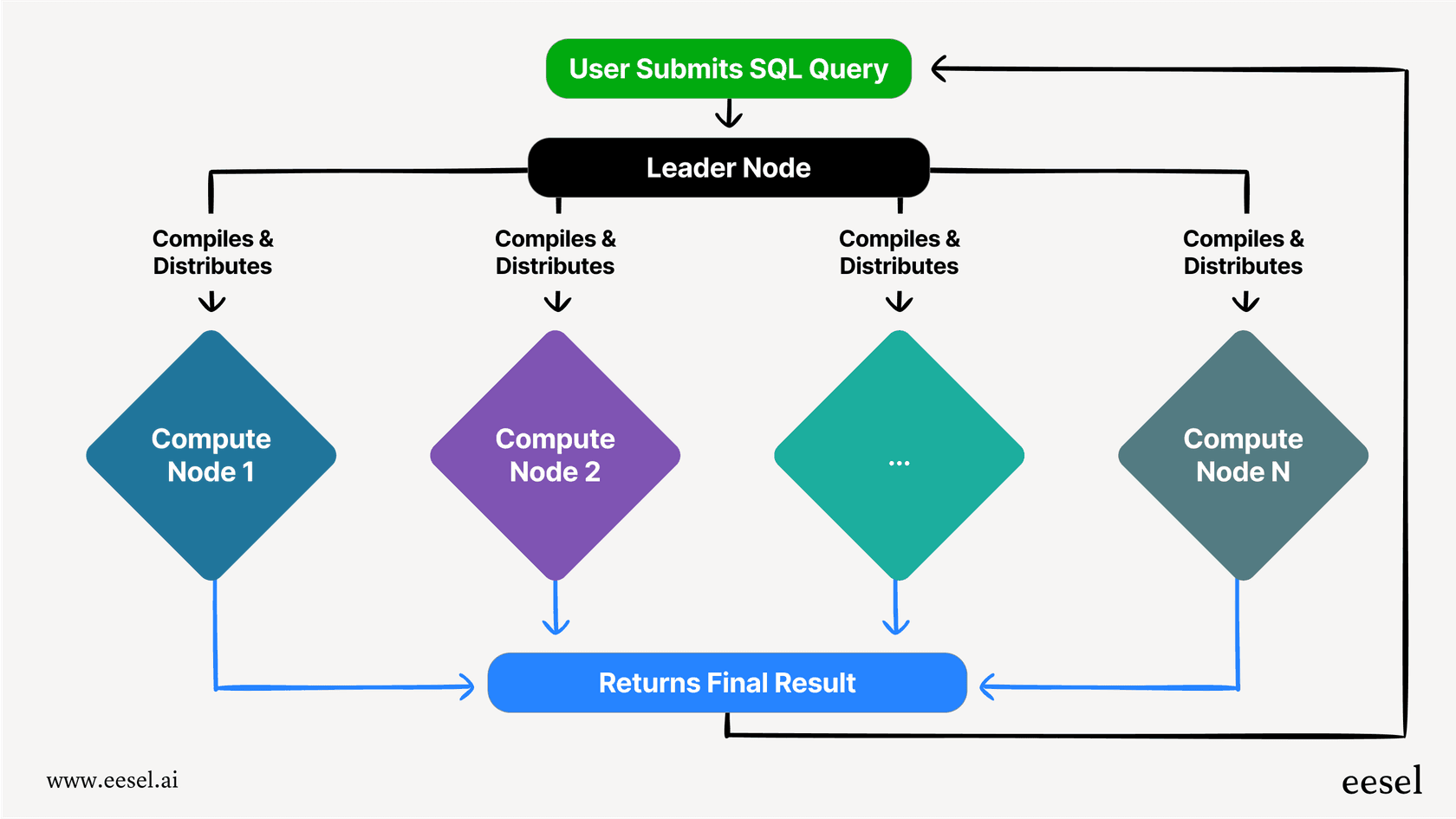
Pense nisto como tentar contar uma pilha enorme de boletins de voto. Uma pessoa a fazê-lo sozinha levaria o ano todo. Mas se der uma pequena pilha a cem pessoas diferentes, todas podem contar a sua pilha ao mesmo tempo e terminar muito mais depressa. Essa é a ideia central por trás de como o Redshift aborda as suas consultas.
Armazenamento colunar
A maioria das bases de dados a que está habituado provavelmente usa armazenamento baseado em linhas. Isto significa que toda a informação de um único registo (como o nome, morada e histórico de compras de um cliente) é armazenada junta numa linha. O Redshift vira isto do avesso e usa armazenamento colunar, que agrupa todos os dados de uma única coluna.
Isto pode parecer um pequeno detalhe técnico, mas faz uma enorme diferença para a análise. Quando está a executar um relatório, geralmente só se interessa por algumas colunas, não por todos os dados de uma tabela. Por exemplo, talvez queira apenas encontrar a soma total das vendas de uma enorme tabela de transações que tem 50 colunas diferentes. Com o armazenamento colunar, o Redshift só precisa de ler os dados da única coluna "vendas", ignorando completamente as outras 49. Isto reduz massivamente a quantidade de dados que tem de analisar, o que faz com que as suas consultas corram muito mais depressa.
Funcionalidades principais e casos de uso comuns
Agora que tem uma ideia do "como", vamos falar sobre o "o quê". Para que é que as pessoas realmente usam o Redshift?
Business intelligence e relatórios
Este é o trabalho principal do Redshift. Atua como o motor potente por trás de ferramentas de business intelligence (BI) como o Tableau, Microsoft Power BI e Amazon QuickSight. As empresas ligam estas ferramentas ao Redshift para construir dashboards que lhes permitem acompanhar quase tudo, desde números de vendas diários e desempenho de campanhas de marketing até à eficiência da produção numa fábrica.
Análise em tempo real de grandes conjuntos de dados
O Redshift também é robusto o suficiente para lidar e analisar fluxos de dados à medida que chegam. Ao ligá-lo a serviços como o Amazon Kinesis, as empresas podem alimentar sistemas de deteção de fraude em tempo real, tabelas de liderança ao vivo para videojogos ou dashboards que analisam dados provenientes de sensores IoT.
Agregação de múltiplas fontes de dados
Uma das coisas mais interessantes que o Redshift pode fazer é reunir dados de diferentes sistemas. Tem uma funcionalidade chamada Redshift Spectrum que lhe permite executar consultas sobre dados que estão nas suas bases de dados normais e em ficheiros semiestruturados (como JSON) que estão simplesmente num data lake no Amazon S3.
Por exemplo, uma empresa poderia combinar dados de tickets de suporte de uma plataforma como o Zendesk, dados de vendas do seu CRM e dados de utilização do produto dos registos da sua aplicação. Ao trazer tudo isso para o Redshift, podem finalmente obter uma imagem única e completa de toda a jornada de um cliente.
Preços do Amazon Redshift em 2025
Ninguém gosta de uma fatura surpresa, por isso, escolher o modelo de preços certo para o Redshift é bastante importante. A AWS oferece duas formas principais de pagamento, e cada uma é melhor para situações diferentes.
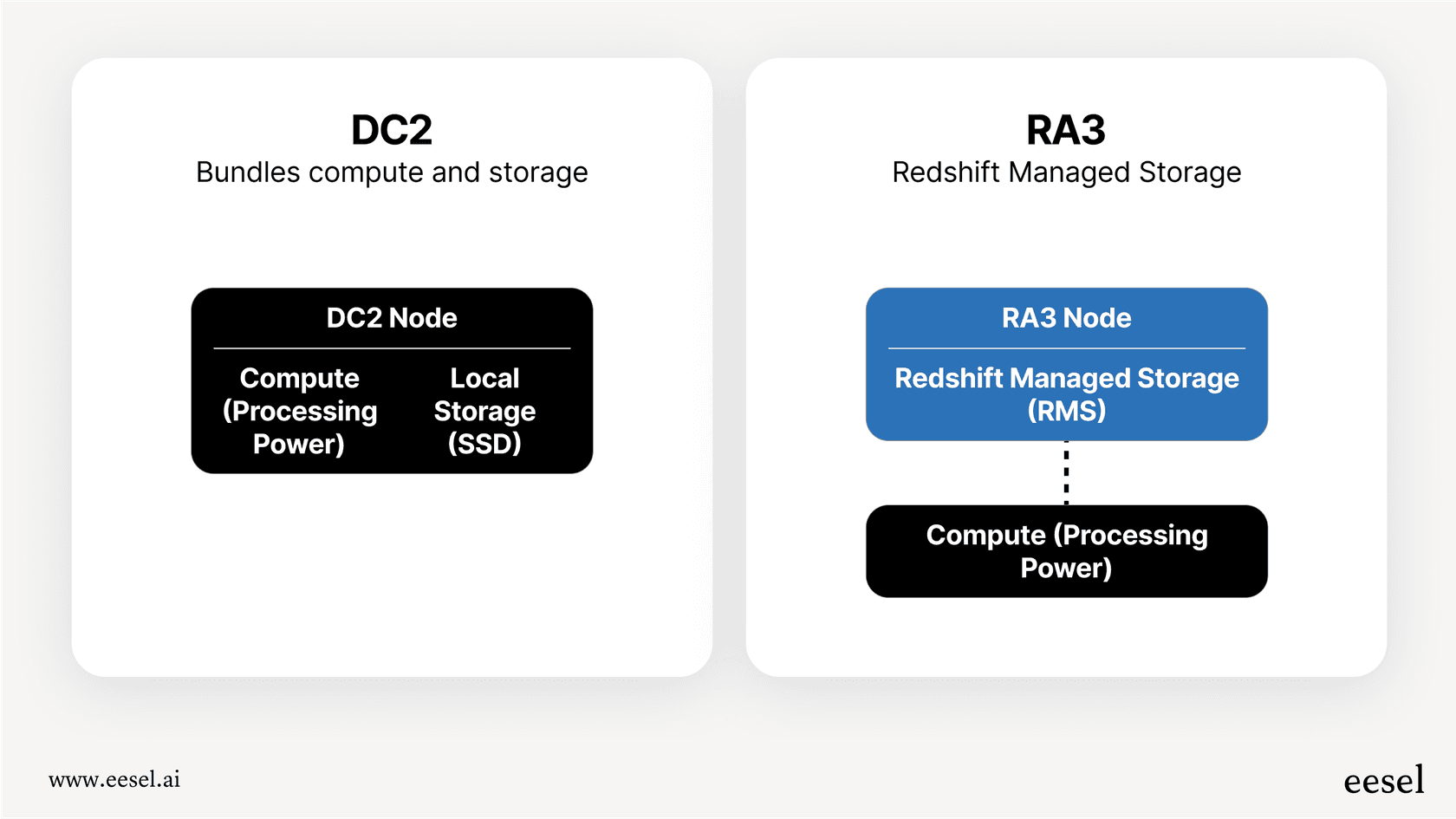
Clusters provisionados
Esta é a abordagem clássica. Você escolhe o tipo e o número específicos de servidores (que a AWS chama de nós) que deseja e paga por eles à hora. A opção mais comum hoje em dia é o tipo de nó RA3, que separa inteligentemente o poder de computação do armazenamento. Isto significa que pode aumentar a sua capacidade de processamento sem ter de pagar por mais armazenamento, e vice-versa. Este modelo funciona bem se a sua carga de trabalho for estável e previsível. Se sabe que vai precisar dele por um tempo, também pode obter grandes descontos ao comprometer-se com um período de um ou três anos com Instâncias Reservadas.
Redshift sem servidor (Serverless)
Esta é a opção mais recente e mais automatizada. Com o Redshift Serverless, não precisa de pensar em clusters ou nós. A AWS gere tudo nos bastidores, ativando recursos automaticamente quando precisa deles e desativando-os quando não precisa. Paga apenas pelo tempo de computação que realmente utiliza, medido em Unidades de Processamento Redshift (RPUs) por hora. Esta é uma ótima escolha para cargas de trabalho que são irregulares, imprevisíveis ou que simplesmente não funcionam 24/7.
Tabela de comparação de preços
Aqui está uma comparação rápida para o ajudar a ver a diferença. Para os números mais recentes, deve sempre consultar a página oficial de preços do AWS Redshift.
| Funcionalidade | Clusters Provisionados | Redshift Serverless |
|---|---|---|
| Modelo de Custo | Pagamento por hora por nós (ex: 0,543 $/hora e superior) | Pagamento por RPU-hora pela computação utilizada (ex: 1,50 $/hora e superior) |
| Ideal Para | Cargas de trabalho estáveis, previsíveis e de alto volume | Cargas de trabalho variáveis, imprevisíveis ou intermitentes |
| Gestão | Precisa de planear a capacidade e gerir o cluster | Administração zero, a AWS trata de tudo |
| Escalabilidade | Escalabilidade manual ou agendada (pode causar breves períodos de inatividade) | Aumenta e diminui a escala de forma automática e transparente |
Lembre-se apenas de que pode haver outros custos, como taxas para armazenamento gerido ou para usar o Redshift Spectrum para consultar dados no S3.
Pontos fortes e limitações do Redshift
Como qualquer tecnologia, o Redshift é ótimo em algumas coisas e não tão bom noutras. É bom conhecer os dois lados da história antes de mergulhar de cabeça.
Prós: Principais benefícios
-
Velocidade em Escala: O seu design central permite-lhe executar consultas em enormes conjuntos de dados de forma incrivelmente rápida.
-
Custo-Benefício: Geralmente, é muito mais barato do que comprar e gerir o seu próprio hardware de data warehouse.
-
Integração Profunda com a AWS: Funciona bem com todo o conjunto de serviços da AWS, como o S3 para armazenamento, o Glue para preparação de dados e o Kinesis para streaming de dados.
-
Escalabilidade: Pode começar pequeno e fazer o seu data warehouse crescer para petabytes de dados à medida que a sua empresa cresce.
Contras: Armadilhas e limitações comuns
-
É para análise, não para transações: O Redshift foi concebido para consultas grandes e complexas. Na verdade, é bastante lento a lidar com muitas pequenas atualizações, inserções ou eliminações.
-
Existe uma curva de aprendizagem: A versão 'provisionada' não é exatamente plug-and-play. Para tirar o máximo proveito do seu investimento, terá de se familiarizar com termos como 'chaves de distribuição' e 'chaves de ordenação' e saber quando fazer um pouco de manutenção.
-
Os custos podem aumentar inesperadamente: Se não tiver cuidado, consultas ineficientes ou um cluster mal configurado num modelo de pagamento por utilização podem levar a uma fatura maior do que o esperado.
-
Dependência do fornecedor (Vendor Lock-in): Sendo um serviço nativo da AWS, mover todos os seus dados e processos para outro fornecedor de nuvem mais tarde pode ser uma dor de cabeça grande e cara.
De insights de dados à ação automatizada
O Redshift é uma ferramenta incrível para análise. Ajuda-o a identificar tendências e a encontrar insights escondidos nos seus dados. Por exemplo, depois de analisar um milhão de tickets de suporte, pode descobrir que um quarto de todas as perguntas dos clientes são sobre a sua política de devoluções.
Ok, então encontrou este ótimo insight. E agora? Geralmente, isto dá início a um monte de trabalho manual. Alguém tem de atualizar a base de conhecimento, escrever novas respostas guardadas para a equipa de suporte e talvez até organizar uma sessão de formação. É lento, e está sempre a correr atrás do prejuízo. É aqui que precisa de algo que possa agir com base nas suas descobertas.
É aqui que um agente de suporte de IA entra em cena. Uma ferramenta como o eesel AI pode ligar-se diretamente ao seu helpdesk e a todas as suas fontes de conhecimento. Pode treiná-lo com os mesmos tickets de suporte que analisou no Redshift, para que ele compreenda o seu negócio, a voz da sua marca e as respostas certas a perguntas comuns de imediato. Em vez de apenas escrever um relatório a dizer "as pessoas perguntam muito sobre devoluções", pode construir um agente de IA que simplesmente lida com essas perguntas instantaneamente.
Com o eesel AI, isto não é um projeto de seis meses. É uma plataforma self-service que lhe permite entrar em funcionamento em minutos. Pode até executar uma simulação nos seus tickets passados para ver exatamente quantos problemas poderia ter resolvido automaticamente, dando-lhe uma imagem clara do seu impacto antes mesmo de o ativar para os clientes.
Considerações finais
O Amazon Redshift é um data warehouse muito poderoso que pode ajudá-lo a extrair insights de enormes conjuntos de dados, quer esteja a construir dashboards de BI ou a fazer análises aprofundadas. Pode escolher um cluster Provisionado pelos seus custos previsíveis ou optar pela opção Serverless pela sua incrível flexibilidade.
Mas encontrar um insight é apenas metade do trabalho. A verdadeira magia acontece quando se liga essa análise a uma ação. Automatizar a resposta aos padrões que descobre é como se constrói uma empresa verdadeiramente eficiente e orientada por dados.
Pronto para transformar os dados do seu suporte de insights em ações automatizadas? Experimente o eesel AI gratuitamente e veja quão rapidamente pode começar a automatizar o seu suporte ao cliente.
Perguntas frequentes
O Amazon Redshift é um data warehouse baseado na nuvem, otimizado para processamento analítico online (OLAP) em conjuntos de dados massivos. Foi criado para lidar com consultas complexas para business intelligence, relatórios e análise profunda de dados, diferindo significativamente das bases de dados transacionais.
O Redshift alcança velocidade através do Processamento Massivamente Paralelo (MPP) entre o nó líder e os nós de computação, e através do uso de armazenamento colunar. O MPP divide as consultas em partes menores executadas simultaneamente, enquanto o armazenamento colunar reduz eficientemente os dados lidos para análise.
O Redshift destaca-se em business intelligence e relatórios, alimentando dashboards e ferramentas de análise. Também é eficazmente utilizado para análise em tempo real de grandes fluxos de dados e para agregar dados de várias fontes numa única visão abrangente.
O Redshift oferece clusters provisionados, onde paga por hora por recursos fixos, ideal para cargas de trabalho estáveis, e serverless, onde paga por hora de computação por recursos escalados automaticamente, o que é perfeito para tarefas variáveis ou imprevisíveis.
Os pontos fortes incluem velocidade em escala, custo-benefício e integração profunda com a AWS. As limitações envolvem a sua inadequação para cargas de trabalho transacionais, uma curva de aprendizagem para a configuração ideal, potencial aumento de custos e dependência do fornecedor.
Embora a versão provisionada exija a compreensão de conceitos como chaves de distribuição e de ordenação para um desempenho ideal, o Redshift Serverless reduz significativamente a sobrecarga administrativa. Isto torna muito mais fácil para novos utilizadores começarem sem necessitarem de conhecimentos técnicos aprofundados.
Share this article

Article by
Kenneth Pangan
Writer and marketer for over ten years, Kenneth Pangan splits his time between history, politics, and art with plenty of interruptions from his dogs demanding attention.