
Seien wir ehrlich, die meisten Unternehmen sitzen heute auf einem Berg von Daten. Da gibt es Kundeninteraktionen, Verkaufszahlen, Website-Klicks, Support-Tickets ... es ist eine ganze Menge. Die eigentliche Herausforderung ist nicht nur, all diese Informationen zu sammeln, sondern sie auch sinnvoll auszuwerten, ohne ewig zu warten oder ein Vermögen auszugeben.
Genau dieses Problem wurde mit Amazon Redshift gelöst. Es ist ein Cloud-Data-Warehouse, das darauf ausgelegt ist, riesige Datenmengen für Analysen zu verarbeiten. Dieser Beitrag bietet einen vollständigen Überblick über Redshift für das Jahr 2025. Wir werden uns seine Architektur ansehen, seine Stärken, wie die Preisgestaltung funktioniert und welche Einschränkungen es gibt, damit Sie entscheiden können, ob es das Richtige für Sie ist.
Was ist Amazon Redshift?
Also, was ist Amazon Redshift wirklich? Es ist die Antwort von AWS auf ein massives, Cloud-basiertes Data Warehouse. Stellen Sie sich eine Datenbank vor, die speziell für eine Aufgabe entwickelt wurde: die Analyse riesiger Datenmengen (was die Profis Online Analytical Processing oder OLAP nennen). Es ist perfekt für die komplexen Abfragen, die Sie für Business Intelligence, Berichterstattung und die tiefgehende Analyse Ihrer Daten benötigen.
Obwohl seine Wurzeln in PostgreSQL liegen, wurde Redshift stark für analytische Geschwindigkeit optimiert. Es ist nicht für die schnellen, alltäglichen Transaktionen konzipiert, die Ihre Hauptanwendungsdatenbank verarbeitet, wie zum Beispiel die Bearbeitung einer einzelnen Kundenbestellung. Stattdessen besteht sein ganzer Zweck darin, Ihnen schnelle, skalierbare Analysen von Big Data zu ermöglichen – und das für deutlich weniger Geld, als Sie für eine herkömmliche On-Premise-Lösung bezahlen würden.
Die Kernarchitektur von Redshift
Die Geschwindigkeit von Redshift ist keine Magie; sie beruht auf einer cleveren Architektur, die für die Parallelverarbeitung entwickelt wurde. Werfen wir einen Blick hinter die Kulissen und sehen wir uns an, wie es funktioniert.
Der Leader-Knoten und die Compute-Knoten
Jedes Redshift-Setup, oder „Cluster“, besteht aus zwei Hauptteilen. Zuerst gibt es den Leader-Knoten. Sie können ihn sich als Projektmanager vorstellen. Wenn Ihre Anwendung eine Abfrage sendet, empfängt der Leader-Knoten sie, ermittelt den besten Ausführungsplan und delegiert die Arbeit dann an ein Team von Compute-Knoten.
Die Compute-Knoten sind diejenigen, die die schwere Arbeit erledigen. Sie sind die Arbeiter, die Ihre Daten speichern und die ihnen zugewiesenen Teile der Abfrage tatsächlich ausführen. Sobald sie ihren Teil erledigt haben, senden sie die Ergebnisse an den Leader-Knoten zurück, der alles zusammensetzt und Ihnen das Endergebnis liefert.
Massively Parallel Processing (MPP)
Das Geheimnis, das Redshift so schnell macht, ist etwas, das sich Massively Parallel Processing (MPP) nennt. Anstatt zu versuchen, eine riesige, komplizierte Abfrage mit einer einzigen leistungsstarken Maschine zu lösen, zerlegt MPP sie in kleinere, überschaubarere Teile. Diese Teile werden dann gleichzeitig (parallel) über alle verschiedenen Compute-Knoten hinweg ausgeführt.
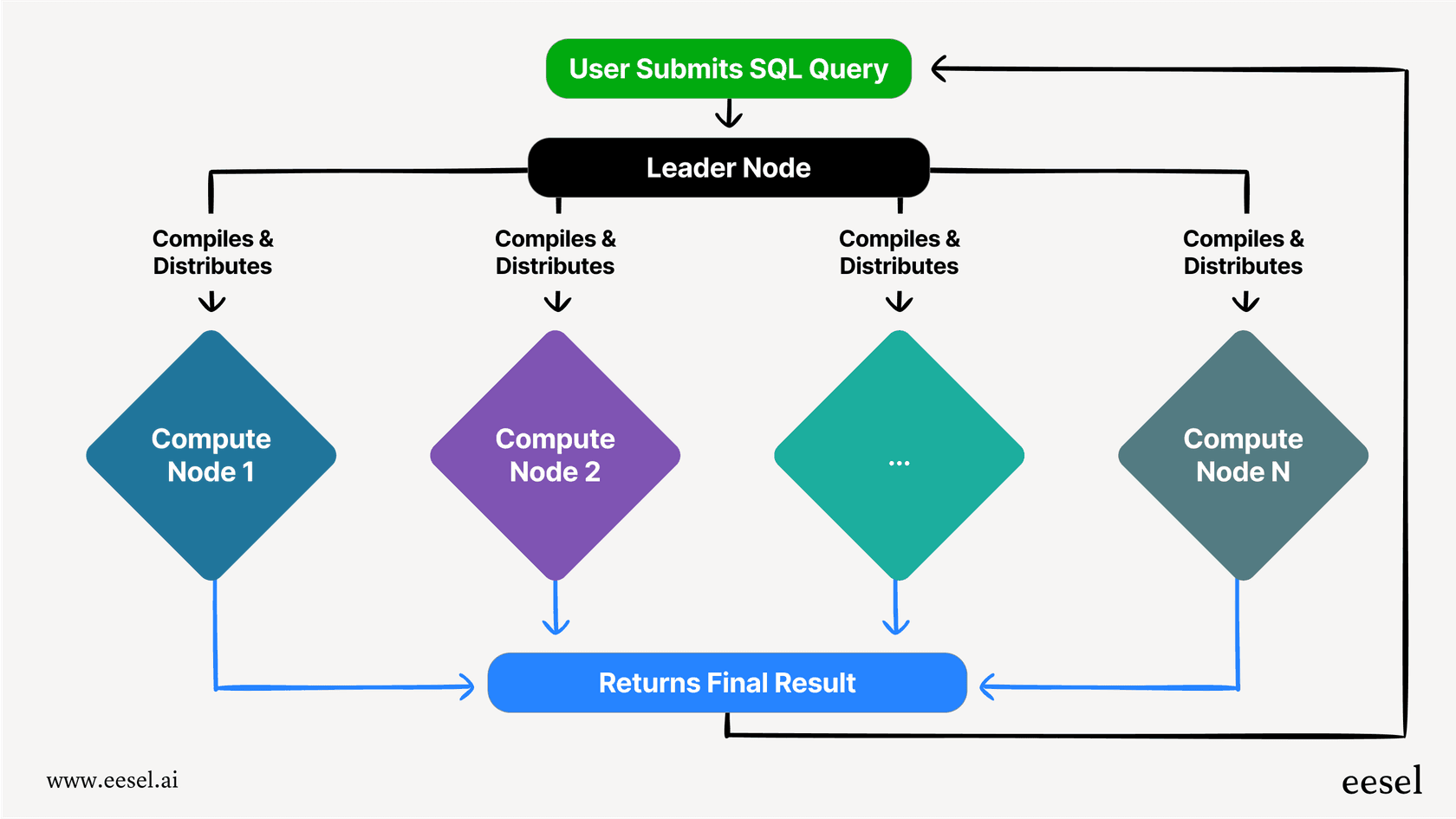
Stellen Sie es sich so vor, als würden Sie einen riesigen Stapel Stimmzettel zählen. Eine Person allein würde dafür ein ganzes Jahr brauchen. Aber wenn Sie hundert verschiedenen Leuten einen kleinen Stapel geben, können sie alle ihren Stapel gleichzeitig zählen und sind viel schneller fertig. Das ist die Kernidee, wie Redshift Ihre Abfragen angeht.
Spaltenbasierte Speicherung
Die meisten Datenbanken, die Sie kennen, verwenden wahrscheinlich eine zeilenbasierte Speicherung. Das bedeutet, alle Informationen für einen einzelnen Datensatz (wie Name, Adresse und Kaufhistorie eines Kunden) werden zusammen in einer Zeile gespeichert. Redshift stellt dies auf den Kopf und verwendet eine spaltenbasierte Speicherung, bei der alle Daten aus einer einzigen Spalte zusammengefasst werden.
Das mag wie ein kleines technisches Detail klingen, macht aber für Analysen einen riesigen Unterschied. Wenn Sie einen Bericht ausführen, interessieren Sie sich normalerweise nur für einige wenige Spalten, nicht für jedes einzelne Datenelement in einer Tabelle. Vielleicht möchten Sie zum Beispiel nur die Gesamtsumme der Verkäufe aus einer riesigen Transaktionstabelle mit 50 verschiedenen Spalten ermitteln. Mit der spaltenbasierten Speicherung muss Redshift nur die Daten in der einzelnen „Verkaufs“-Spalte lesen und ignoriert die anderen 49 vollständig. Dies reduziert die zu scannende Datenmenge massiv, wodurch Ihre Abfragen viel schneller laufen.
Schlüsselfunktionen und häufige Anwendungsfälle
Nachdem Sie nun eine Vorstellung vom „Wie“ haben, sprechen wir über das „Was“. Wofür verwenden die Leute Redshift eigentlich?
Business Intelligence und Reporting
Das ist die Hauptaufgabe von Redshift. Es fungiert als leistungsstarker Motor hinter Business Intelligence (BI)-Tools wie Tableau, Microsoft Power BI und Amazon QuickSight. Unternehmen verbinden diese Tools mit Redshift, um Dashboards zu erstellen, mit denen sie so gut wie alles verfolgen können, von täglichen Verkaufszahlen und der Leistung von Marketingkampagnen bis hin zur Effizienz in der Fabrikhalle.
Echtzeitanalysen großer Datenmengen
Redshift ist auch leistungsstark genug, um Datenströme zu verarbeiten und zu analysieren, während sie eingehen. Durch die Anbindung an Dienste wie Amazon Kinesis können Unternehmen Dinge wie Live-Betrugserkennungssysteme, Echtzeit-Ranglisten für Videospiele oder Dashboards betreiben, die Daten von IoT-Sensoren analysieren.
Zusammenführung mehrerer Datenquellen
Eine der coolsten Funktionen von Redshift ist die Fähigkeit, Daten aus verschiedenen Systemen zusammenzuführen. Es verfügt über eine Funktion namens Redshift Spectrum, mit der Sie Abfragen auf Daten ausführen können, die in Ihren regulären Datenbanken und in semistrukturierten Dateien (wie JSON) liegen, die sich einfach in einem Data Lake in Amazon S3 befinden.
Ein Unternehmen könnte zum Beispiel Support-Ticket-Daten von einer Plattform wie Zendesk, Verkaufsdaten aus seinem CRM und Produktnutzungsdaten aus seinen App-Protokollen kombinieren. Indem sie all das in Redshift zusammenführen, können sie endlich ein einziges, vollständiges Bild der gesamten Customer Journey erhalten.
Amazon Redshift Preise 2025
Niemand mag überraschende Rechnungen, daher ist die Wahl des richtigen Preismodells für Redshift ziemlich wichtig. AWS bietet Ihnen zwei Hauptzahlungsmöglichkeiten, und jede ist für unterschiedliche Situationen besser geeignet.
Provisionierte Cluster
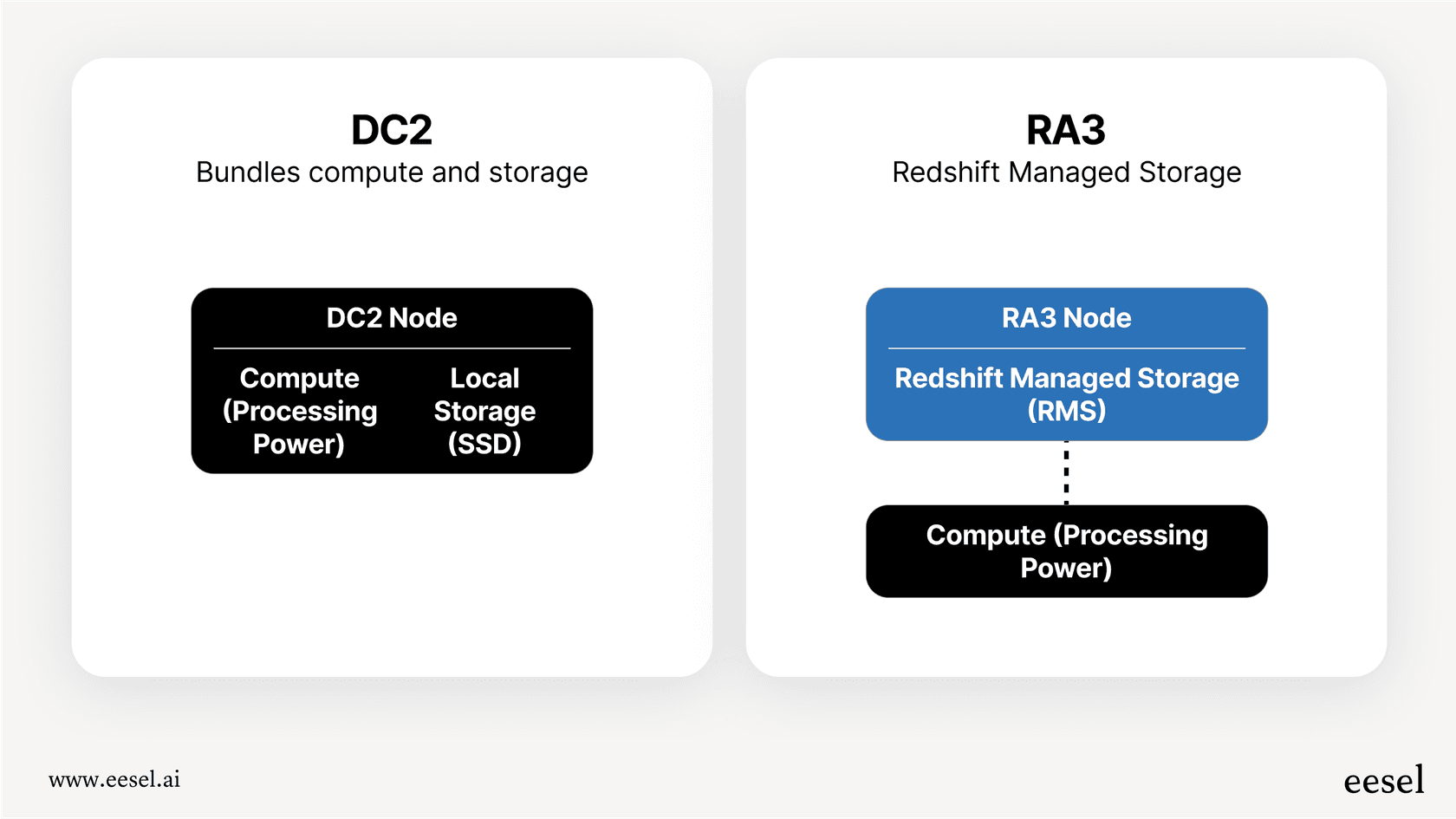
Dies ist der klassische Ansatz. Sie wählen den spezifischen Typ und die Anzahl der Server (die AWS als Knoten bezeichnet), die Sie möchten, und bezahlen diese pro Stunde. Die heutzutage gebräuchlichste Option ist der RA3-Knotentyp, der Rechenleistung geschickt vom Speicher trennt. Das bedeutet, Sie können Ihre Rechenleistung erhöhen, ohne für mehr Speicher bezahlen zu müssen, und umgekehrt. Dieses Modell funktioniert gut, wenn Ihre Arbeitslast stabil und vorhersehbar ist. Wenn Sie wissen, dass Sie es für eine Weile benötigen, können Sie auch große Rabatte erhalten, indem Sie sich mit Reserved Instances für eine Laufzeit von einem oder drei Jahren verpflichten.
Redshift Serverless
Dies ist die neuere, unkompliziertere Option. Mit Redshift Serverless müssen Sie sich überhaupt nicht um Cluster oder Knoten kümmern. AWS verwaltet alles hinter den Kulissen, stellt Ressourcen automatisch bereit, wenn Sie sie benötigen, und fährt sie herunter, wenn Sie sie nicht mehr brauchen. Sie zahlen nur für die tatsächlich genutzte Rechenzeit, gemessen in Redshift Processing Units (RPUs) pro Stunde. Dies ist eine gute Wahl für Workloads, die sprunghaft, unvorhersehbar oder einfach nicht rund um die Uhr laufen.
Preisvergleichstabelle
Hier ist ein kurzer Vergleich, um Ihnen den Unterschied zu verdeutlichen. Für die neuesten Zahlen sollten Sie immer die offizielle AWS Redshift-Preisseite prüfen.
| Merkmal | Provisionierte Cluster | Redshift Serverless |
|---|---|---|
| Kostenmodell | Zahlung pro Stunde für Knoten (z. B. ab 0,543 $/Stunde) | Zahlung pro RPU-Stunde für genutzte Rechenleistung (z. B. ab 1,50 $/Stunde) |
| Am besten geeignet für | Stabile, vorhersehbare und hochvolumige Workloads | Variable, unvorhersehbare oder intermittierende Workloads |
| Verwaltung | Sie müssen Kapazitäten planen und den Cluster verwalten | Keine Administration, AWS kümmert sich um alles |
| Skalierung | Manuelle oder geplante Skalierung (kann zu kurzen Ausfallzeiten führen) | Skaliert automatisch und nahtlos nach oben und unten |
Denken Sie daran, dass weitere Kosten anfallen können, wie z. B. Gebühren für verwalteten Speicher oder für die Nutzung von Redshift Spectrum zur Abfrage von Daten in S3.
Stärken und Schwächen von Redshift
Wie jede Technologie ist Redshift in manchen Dingen großartig und in anderen nicht so sehr. Es ist gut, beide Seiten der Medaille zu kennen, bevor man sich darauf einlässt.
Vorteile: Die wichtigsten Stärken
-
Geschwindigkeit bei Skalierung: Sein Kerndesign ermöglicht es, Abfragen auf riesigen Datensätzen unglaublich schnell auszuführen.
-
Kosteneffektiv: Es ist in der Regel viel günstiger als der Kauf und die Verwaltung Ihrer eigenen Data-Warehouse-Hardware.
-
Tiefe AWS-Integration: Es arbeitet nahtlos mit der gesamten Palette von AWS-Services zusammen, wie S3 für Speicher, Glue für die Datenaufbereitung und Kinesis für Streaming-Daten.
-
Skalierbarkeit: Sie können klein anfangen und Ihr Warehouse auf Petabytes an Daten erweitern, während Ihr Unternehmen wächst.
Nachteile: Häufige Fallstricke und Einschränkungen
-
Es ist für Analysen, nicht für Transaktionen: Redshift ist für große, komplexe Abfragen konzipiert. Es ist tatsächlich ziemlich langsam bei der Verarbeitung vieler kleiner Updates, Einfügungen oder Löschungen.
-
Es gibt eine Lernkurve: Die „provisionierte“ Version ist nicht gerade Plug-and-Play. Um das Beste aus Ihrem Geld herauszuholen, müssen Sie sich mit Begriffen wie „Distribution Keys“ und „Sort Keys“ vertraut machen und wissen, wann eine kleine Wartung erforderlich ist.
-
Kosten können schleichend steigen: Wenn Sie nicht aufpassen, können ineffiziente Abfragen oder ein schlecht konfigurierter Cluster bei einem Pay-as-you-go-Modell zu einer höheren Rechnung führen als erwartet.
-
Anbieterabhängigkeit (Vendor Lock-in): Da es sich um einen nativen AWS-Dienst handelt, könnte der spätere Umzug all Ihrer Daten und Prozesse zu einem anderen Cloud-Anbieter ein großes, teures Kopfzerbrechen bereiten.
Von Dateneinblicken zu automatisierten Aktionen
Redshift ist ein erstaunliches Werkzeug für die Analyse. Es hilft Ihnen, Trends zu erkennen und Einblicke zu finden, die in Ihren Daten vergraben sind. Nachdem Sie zum Beispiel eine Million Support-Tickets analysiert haben, könnten Sie feststellen, dass ein Viertel aller Kundenfragen Ihre Rückgaberichtlinien betreffen.
Okay, Sie haben also diese großartige Erkenntnis gewonnen. Und jetzt? Normalerweise löst dies eine Menge manueller Arbeit aus. Jemand muss die Wissensdatenbank aktualisieren, neue gespeicherte Antworten für das Support-Team schreiben und vielleicht sogar eine Schulung organisieren. Das ist langsam, und Sie hinken immer hinterher. Hier brauchen Sie etwas, das auf Ihre Erkenntnisse reagieren kann.
An dieser Stelle kommt ein KI-Support-Agent ins Spiel. Ein Tool wie eesel AI kann sich direkt mit Ihrem Helpdesk und all Ihren Wissensquellen verbinden. Sie können es mit denselben Support-Tickets trainieren, die Sie in Redshift analysiert haben, sodass es Ihr Unternehmen, Ihre Markenstimme und die richtigen Antworten auf häufige Fragen sofort versteht. Anstatt nur einen Bericht zu schreiben, der besagt, „die Leute fragen oft nach Rücksendungen“, können Sie einen KI-Agenten erstellen, der diese Fragen einfach sofort bearbeitet.
Mit eesel AI ist dies kein Sechs-Monats-Projekt. Es ist eine Self-Service-Plattform, mit der Sie in wenigen Minuten live gehen können. Sie können sogar eine Simulation mit Ihren vergangenen Tickets durchführen, um genau zu sehen, wie viele Probleme es automatisch hätte lösen können, und erhalten so ein klares Bild seiner Wirkung, bevor Sie es überhaupt für Kunden aktivieren.
Abschließende Gedanken
Amazon Redshift ist ein äußerst leistungsstarkes Data Warehouse, das Ihnen helfen kann, Erkenntnisse aus riesigen Datensätzen zu gewinnen, egal ob Sie BI-Dashboards erstellen oder tiefgehende Analysen durchführen. Sie können einen provisionierten Cluster für seine vorhersehbaren Kosten wählen oder sich für die Serverless-Option wegen ihrer erstaunlichen Flexibilität entscheiden.
Aber eine Erkenntnis zu gewinnen, ist nur die halbe Miete. Die wahre Magie entsteht, wenn Sie diese Analyse mit einer Aktion verbinden. Die Automatisierung der Reaktion auf die von Ihnen aufgedeckten Muster ist der Weg, ein wirklich effizientes, datengesteuertes Unternehmen aufzubauen.
Bereit, Ihre Support-Daten von Erkenntnissen in automatisierte Aktionen umzuwandeln? Testen Sie eesel AI kostenlos und sehen Sie, wie schnell Sie Ihren Kundensupport automatisieren können.
Häufig gestellte Fragen
Amazon Redshift ist ein Cloud-basiertes Data Warehouse, das für Online Analytical Processing (OLAP) auf riesigen Datenmengen optimiert ist. Es wurde für komplexe Abfragen in den Bereichen Business Intelligence, Reporting und tiefgehende Datenanalyse entwickelt und unterscheidet sich damit deutlich von transaktionalen Datenbanken.
Redshift erreicht seine Geschwindigkeit durch Massively Parallel Processing (MPP) über Leader- und Compute-Knoten sowie durch die Verwendung von spaltenbasierter Speicherung. MPP zerlegt Abfragen in kleinere Teile, die gleichzeitig ausgeführt werden, während die spaltenbasierte Speicherung die für Analysen zu scannende Datenmenge effizient reduziert.
Redshift brilliert in den Bereichen Business Intelligence und Reporting und dient als Motor für Dashboards und Analysetools. Es wird auch effektiv für Echtzeitanalysen großer Datenströme und zur Zusammenführung von Daten aus verschiedenen Quellen in einer einzigen, umfassenden Ansicht eingesetzt.
Redshift bietet provisionierte Cluster, bei denen Sie stundenweise für feste Ressourcen bezahlen – ideal für stabile Workloads – und ein Serverless-Modell, bei dem Sie pro Rechenstunde für automatisch skalierte Ressourcen zahlen, was perfekt für variable oder unvorhersehbare Aufgaben ist.
Zu den Stärken gehören Geschwindigkeit bei Skalierung, Kosteneffizienz und eine tiefe AWS-Integration. Zu den Einschränkungen gehören die mangelnde Eignung für transaktionale Workloads, eine Lernkurve für die optimale Konfiguration, potenzielle Kostensteigerungen und die Abhängigkeit vom Anbieter (Vendor Lock-in).
Während die provisionierte Version für eine optimale Leistung das Verständnis von Konzepten wie Verteilungs- und Sortierschlüsseln erfordert, reduziert Redshift Serverless den administrativen Aufwand erheblich. Dies macht es neuen Benutzern wesentlich einfacher, ohne tiefes technisches Fachwissen einzusteigen.
Share this article

Article by
Kenneth Pangan
Writer and marketer for over ten years, Kenneth Pangan splits his time between history, politics, and art with plenty of interruptions from his dogs demanding attention.