
正直なところ、今日のほとんどの企業は膨大な量のデータを抱えています。顧客とのやり取り、売上高、ウェブサイトのクリック数、サポートチケットなど、その量は膨大です。難しいのは、そのすべての情報をただ集めることではなく、延々と待ったり、大金を費やしたりすることなく、それを理解することです。
まさにその問題を解決するために作られたのがAmazon Redshiftです。これは、分析のために大量のデータを処理するように設計されたクラウドデータウェアハウスです。この記事では、2025年版のRedshiftの完全な概要を説明します。そのアーキテクチャ、得意なこと、料金体系、そして制限事項について掘り下げ、あなたにとって最適な選択肢かどうかを判断できるようにします。
Amazon Redshiftとは?
では、Amazon Redshiftとは一体何なのでしょうか? これは、AWSが提供する大規模なクラウドベースのデータウェアハウスです。一つの仕事、つまり巨大なデータセットの分析(専門家が言うところのオンライン分析処理、またはOLAP)のために特別に構築されたデータベースだと考えてください。ビジネスインテリジェンス、レポート作成、データ掘り下げに必要な複雑なクエリを実行するのに最適です。
そのルーツはPostgreSQLにありますが、Redshiftは分析の速度を上げるために大幅に改良されています。顧客の注文を1件処理するような、メインのアプリケーションデータベースが処理する日常的な短期トランザクション向けには設計されていません。その目的は、従来のオンプレミス設定よりもはるかに安価で、ビッグデータに対する高速でスケーラブルな分析を提供することにあります。
Redshiftのコアアーキテクチャ
Redshiftの速さは魔法ではありません。並列処理のために設計された巧妙なアーキテクチャに基づいています。その仕組みを詳しく見ていきましょう。
リーダーノードとコンピューティングノード
すべてのRedshiftのセットアップ、つまり「クラスター」には、2つの主要な部分があります。まず、リーダーノードです。これはプロジェクトマネージャーのようなものだと考えることができます。アプリケーションがクエリを送信すると、リーダーノードがそれを受け取り、実行するための最善の計画を立て、その後、コンピューティングノードのチームに作業を委任します。
コンピューティングノードは、重労働を行う部分です。データを保存し、割り当てられたクエリの一部を実際に実行する働き手です。作業が完了すると、結果をリーダーノードに送り返し、リーダーノードがすべてをまとめて最終的な答えをあなたに渡します。
超並列処理(MPP)
Redshiftをこれほど高速にしている秘訣は、超並列処理(MPP)と呼ばれるものです。MPPは、巨大で複雑なクエリを1台の強力なマシンで解決しようとする代わりに、より小さく管理しやすい部分に分割します。これらの部分は、すべての異なるコンピューティングノードで同時に(並列で)実行されます。
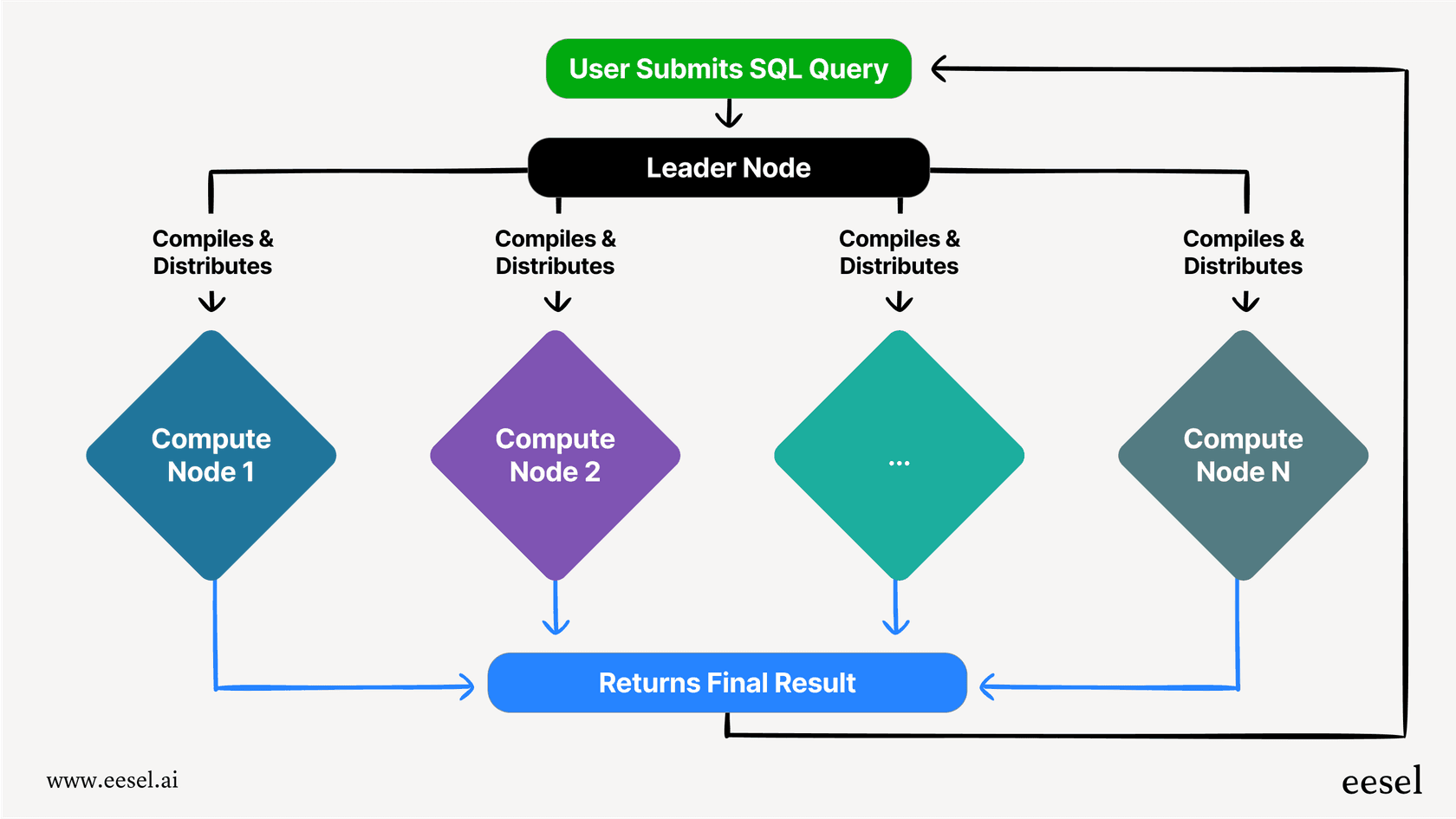
大量の投票用紙を数えるようなものだと考えてみてください。一人でやれば一年中かかるでしょう。しかし、100人の別々の人に小さな束を渡せば、全員が同時に自分の山を数えることができ、はるかに速く終わります。これが、Redshiftがクエリに取り組む際の基本的な考え方です。
カラムナストレージ(列指向ストレージ)
あなたが使い慣れているほとんどのデータベースは、おそらく行ベースのストレージを使用しています。これは、1つのレコード(例えば、1人の顧客の名前、住所、購入履歴など)のすべての情報が1つの行にまとめて保存されることを意味します。Redshiftはこれを逆転させ、1つの列のすべてのデータをまとめてグループ化する**カラムナストレージ**を使用します。
これは些細な技術的詳細のように聞こえるかもしれませんが、分析にとっては大きな違いを生みます。レポートを実行するとき、通常はテーブル内のすべてのデータではなく、いくつかの列にしか関心がありません。たとえば、50の異なる列を持つ巨大なトランザクションテーブルから売上の合計だけを見つけたいとします。カラムナストレージを使えば、Redshiftは「売上」列のデータだけを読み取る必要があり、他の49列は完全に無視します。これにより、スキャンしなければならないデータ量が大幅に削減され、クエリの実行がはるかに高速になります。
主な機能と一般的なユースケース
「どのように」動くかがわかったところで、次は「何に」使うかについて話しましょう。人々は実際にRedshiftを何のために使っているのでしょうか?
ビジネスインテリジェンスとレポート作成
これがRedshiftの主な仕事です。Tableau、Microsoft Power BI、Amazon QuickSightなどのビジネスインテリジェンス(BI)ツールの背後にある強力なエンジンとして機能します。企業はこれらのツールをRedshiftに接続して、日々の売上数やマーケティングキャンペーンのパフォーマンスから工場の生産効率まで、ほぼすべてのことを追跡できるダッシュボードを構築します。
大規模データセットに対するリアルタイム分析
Redshiftは、入ってくるデータストリームを処理し分析するのに十分な性能も持っています。Amazon Kinesisのようなサービスに接続することで、企業はリアルタイムの不正検出システム、ビデオゲームのライブリーダーボード、IoTセンサーから流れ込むデータを分析するダッシュボードなどを動かすことができます。
複数のデータソースの集約
Redshiftができる最もクールなことの1つは、異なるシステムからデータを集約できることです。Redshift Spectrumという機能があり、これにより通常のデータベースにあるデータや、Amazon S3のデータレイクに置かれている半構造化ファイル(JSONなど)に対してクエリを実行できます。
たとえば、ある企業はZendeskのようなプラットフォームからのサポートチケットデータ、CRMからの販売データ、アプリのログからの製品利用データを組み合わせることができます。これらすべてをRedshiftに取り込むことで、顧客の全行程を単一の完全なビューで把握することができるようになります。
2025年のAmazon Redshift料金体系
予期せぬ請求書を好む人はいませんから、Redshiftに適した料金モデルを選ぶことは非常に重要です。AWSは主に2つの支払い方法を提供しており、それぞれ異なる状況に適しています。
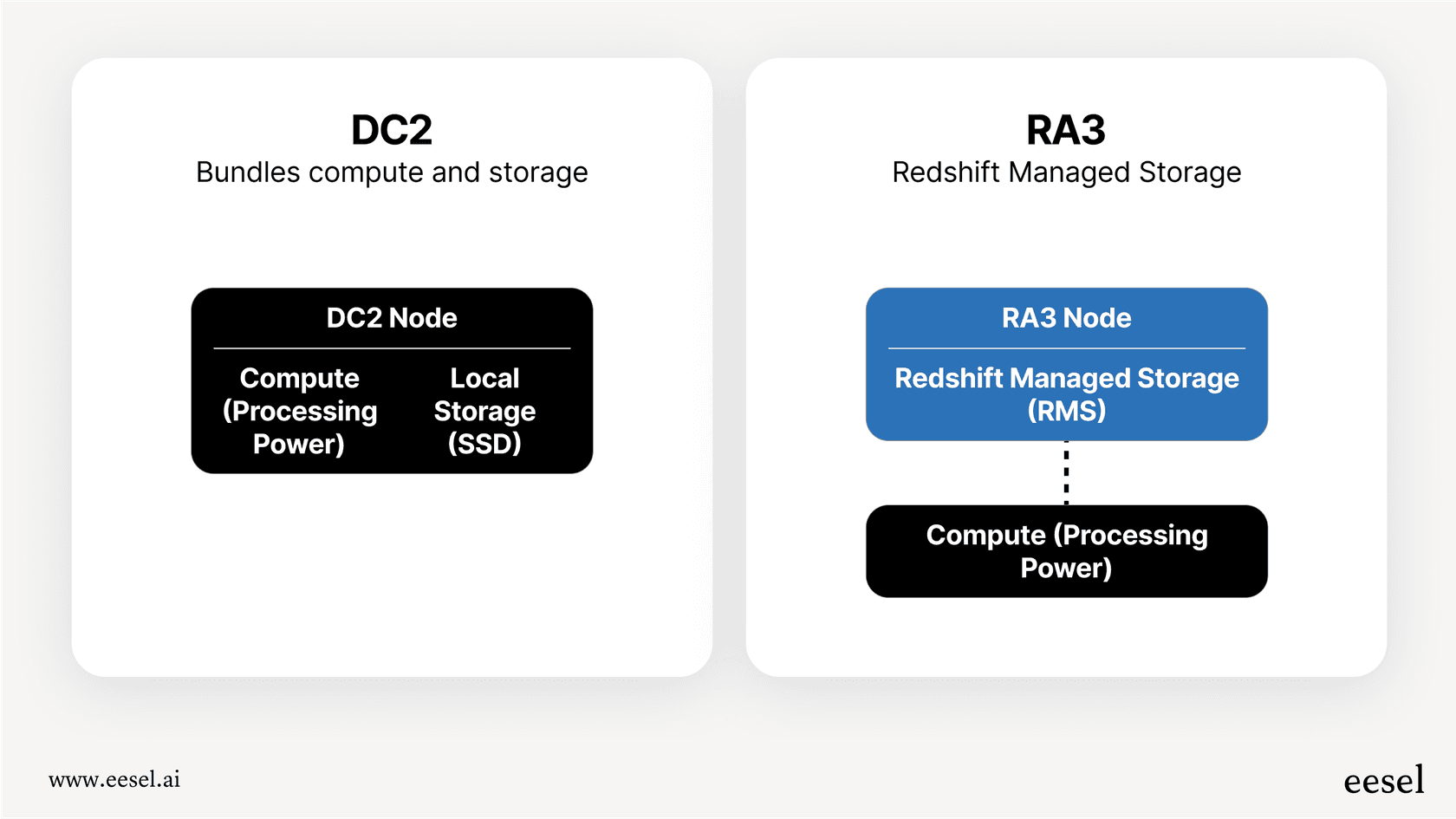
プロビジョンドクラスター
これは従来のアプローチです。特定のタイプと数のサーバー(AWSではノードと呼びます)を選択し、時間単位で料金を支払います。最近最も一般的な選択肢は**RA3ノードタイプ**で、これは計算能力とストレージを巧みに分離しています。これにより、ストレージを追加料金なしで計算能力をスケールアップしたり、その逆も可能になります。このモデルは、ワークロードが安定していて予測可能な場合にうまく機能します。長期間使用することがわかっている場合は、リザーブドインスタンスで1年または3年の契約をすることで大幅な割引を受けることもできます。
Redshiftサーバーレス
これはより新しく、手間のかからない選択肢です。Redshiftサーバーレスでは、クラスターやノードについて一切考える必要がありません。AWSが裏側ですべてを管理し、必要なときにリソースを自動的に起動し、不要になったらシャットダウンします。実際に使用した計算時間に対してのみ、Redshift処理ユニット(RPU)/時間単位で支払います。これは、ワークロードが急増したり、予測不可能だったり、あるいは24時間365日実行されない場合に最適な選択肢です。
料金比較表
違いを理解するのに役立つ簡単な比較表です。最新の数値については、常に公式のAWS Redshift料金ページを確認してください。
| 特徴 | プロビジョンドクラスター | Redshiftサーバーレス |
|---|---|---|
| コストモデル | ノードごとの時間単位支払い(例:$0.543/時間~) | 使用したコンピューティングに対するRPU時間単位支払い(例:$1.50/時間~) |
| 最適な用途 | 安定、予測可能、大容量のワークロード | 変動、予測不可能、断続的なワークロード |
| 管理 | 容量計画とクラスター管理が必要 | 管理不要、AWSがすべて対応 |
| スケーリング | 手動またはスケジュールによるスケーリング(短時間ダウンタイムの可能性あり) | 自動的かつシームレスにスケールアップ・ダウン |
マネージドストレージの料金や、Redshift Spectrumを使用してS3のデータにクエリを実行する際の料金など、他のコストが発生する可能性があることを忘れないでください。
Redshiftの長所と短所
どんなテクノロジーにも言えることですが、Redshiftは得意なこともあれば、そうでないこともあります。飛び込む前に、両方の側面を知っておくことが大切です。
長所:主なメリット
-
大規模での高速性: そのコア設計により、巨大なデータセットに対するクエリを驚くほど高速に実行できます。
-
費用対効果: 一般的に、自社でデータウェアハウスのハードウェアを購入・管理するよりもはるかに安価です。
-
AWSとの緊密な連携: S3(ストレージ)、Glue(データ準備)、Kinesis(ストリーミングデータ)など、AWSのサービススイート全体とスムーズに連携します。
-
スケーラビリティ: 小さく始めて、会社の成長に合わせてウェアハウスをペタバイト規模のデータまで拡張できます。
短所:一般的な落とし穴と制限
-
分析向けであり、トランザクション向けではない: Redshiftは大規模で複雑なクエリ向けに設計されています。実際には、多数の小さな更新、挿入、削除の処理はかなり遅いです。
-
学習曲線がある: 「プロビジョンド」バージョンは、まさにプラグアンドプレイというわけではありません。コストに見合う価値を得るためには、「分散キー」や「ソートキー」といった用語に慣れ、いつメンテナンスを行うべきかを知る必要があります。
-
コストが忍び寄る可能性がある: 注意しないと、非効率なクエリや不適切に設定されたクラスターが従量課金モデルで予想以上の請求につながることがあります。
-
ベンダーロックイン: AWSネイティブのサービスであるため、後で全てのデータとプロセスを別のクラウドプロバイダーに移行するのは、大規模でコストのかかる頭痛の種になる可能性があります。
データの洞察から自動化されたアクションへ
Redshiftは分析のための素晴らしいツールです。データに埋もれたトレンドを発見し、洞察を見つけるのに役立ちます。たとえば、100万件のサポートチケットを調べた後、顧客からの質問の4分の1が返品ポリシーに関するものであることがわかるかもしれません。
さて、この素晴らしい洞察を得ました。次は何をしますか? 通常、ここから多くの手作業が始まります。ナレッジベースを更新し、サポートチームのために新しい定型返信を作成し、場合によってはトレーニングセッションを企画する必要があるかもしれません。これは時間がかかり、常に後手に回ることになります。ここで必要なのは、あなたの発見に基づいて行動できる何かです。
ここで登場するのがAIサポートエージェントです。eesel AIのようなツールは、ヘルプデスクやすべてのナレッジソースに直接接続できます。Redshiftで分析したのと同じサポートチケットでトレーニングできるため、あなたのビジネス、ブランドの声、そして一般的な質問に対する正しい答えをすぐに理解します。「返品に関する問い合わせが多い」というレポートを書くだけでなく、それらの質問を即座に処理するAIエージェントを構築できるのです。
eesel AIを使えば、これは6ヶ月かかるようなプロジェクトではありません。数分で本番稼働できるセルフサービスプラットフォームです。過去のチケットでシミュレーションを実行して、どれだけの問題を自動で解決できたかを正確に確認することもでき、顧客向けに稼働させる前にその影響を明確に把握できます。
最後の考察
Amazon Redshiftは、BIダッシュボードの構築や詳細な分析を行う際、膨大なデータセットから洞察を引き出すのに役立つ非常に強力なデータウェアハウスです。予測可能なコストのプロビジョンドクラスターを選ぶことも、驚くべき柔軟性を持つサーバーレスオプションを選ぶこともできます。
しかし、洞察を見つけることは仕事の半分に過ぎません。本当の魔法は、その分析をアクションに結びつけたときに起こります。発見したパターンへの対応を自動化することこそが、真に効率的でデータ駆動型の企業を築く方法です。
サポートデータから得た洞察を自動化されたアクションに変える準備はできましたか? eesel AIを無料でお試しいただき、どれだけ迅速にカスタマーサポートを自動化できるかをご覧ください。
よくある質問
Amazon Redshiftは、大規模データセットに対するオンライン分析処理(OLAP)に最適化されたクラウドベースのデータウェアハウスです。ビジネスインテリジェンス、レポート作成、詳細なデータ分析のための複雑なクエリを処理するために構築されており、トランザクションデータベースとは大きく異なります。
Redshiftは、リーダーノードとコンピューティングノード間での超並列処理(MPP)と、カラムナストレージ(列指向ストレージ)の使用によって高速性を実現しています。MPPはクエリを小さな部分に分割して同時に実行し、カラムナストレージは分析のためにスキャンするデータを効率的に削減します。
Redshiftは、ビジネスインテリジェンスとレポート作成に優れており、ダッシュボードや分析ツールを支えています。また、大規模なデータストリームに対するリアルタイム分析や、様々なソースからのデータを単一の包括的なビューに集約するためにも効果的に使用されます。
Redshiftは、安定したワークロードに最適な固定リソースに対して時間単位で支払うプロビジョンドクラスターと、変動の激しいタスクや予測不可能なタスクに最適な自動スケーリングされるリソースに対してコンピューティング時間単位で支払うサーバーレスを提供しています。
長所には、大規模での高速性、費用対効果、AWSとの緊密な連携が含まれます。短所としては、トランザクションワークロードには不向きであること、最適な設定には学習曲線があること、潜在的なコストの増大、そしてベンダーロックインが挙げられます。
プロビジョンドバージョンでは最適なパフォーマンスを得るために分散キーやソートキーなどの概念を理解する必要がありますが、Redshiftサーバーレスは管理上のオーバーヘッドを大幅に削減します。これにより、新規ユーザーは深い技術的専門知識がなくてもはるかに簡単に始めることができます。
Share this article

Article by
Kenneth Pangan
Writer and marketer for over ten years, Kenneth Pangan splits his time between history, politics, and art with plenty of interruptions from his dogs demanding attention.