Essayer de choisir le bon grand modèle de langage (LLM) pour votre entreprise peut donner l'impression d'être face à un mur de spécifications, de benchmarks et de jargon marketing. D'un côté, il y a GPT-4 Turbo d'OpenAI, le grand nom que tout le monde connaît pour sa puissance brute. De l'autre, il y a Mistral, un concurrent européen sérieusement impressionnant qui fait tourner les têtes avec ses performances et son tarif bien plus avantageux.
Alors, lequel est réellement le meilleur pour les tâches que vous devez accomplir, comme gérer le service client ou créer un service d'assistance interne ? Ce guide fait le tri dans le débat GPT-4 Turbo vs Mistral. Nous allons laisser de côté les aspects purement techniques pour nous concentrer sur ce qui compte vraiment : leurs performances dans le monde réel, leur coût et ce qu'il faut réellement pour les mettre en œuvre. Nous examinerons les points forts de chaque modèle et découvrirons pourquoi le modèle que vous choisissez ne représente en réalité que la moitié du chemin.
Qu'est-ce que GPT-4 Turbo ?
GPT-4 Turbo est le modèle haut de gamme d'OpenAI, les créateurs de ChatGPT. Considérez-le comme l'outil le plus avancé de leur boîte à outils accessible au public, conçu pour s'attaquer à des problèmes complexes, analyser des situations délicates et rédiger des textes de haute qualité qui semblent écrits par un humain. C'est un modèle à code source fermé, auquel vous accédez généralement via une API d'OpenAI ou de Microsoft Azure.
Les entreprises se tournent généralement vers GPT-4 Turbo lorsqu'elles ont besoin d'une tâche réalisée avec une grande précision et une compréhension profonde des nuances. Nous parlons de tâches comme la rédaction de documents techniques denses, l'exploration de données pour en extraire des informations, ou l'alimentation d'un chatbot capable de gérer des conversations complexes. Ses principales forces sont sa vaste base de connaissances générales et sa capacité à suivre des instructions détaillées en plusieurs étapes.
Qu'est-ce que Mistral ?
Mistral AI est une entreprise parisienne qui a fait une entrée remarquée sur la scène et s'est rapidement fait un nom. Bien qu'ils aient une approche favorable à l'open source avec d'excellents modèles aux poids ouverts (open-weight), leur modèle le plus puissant, Mistral Large, est un concurrent direct de GPT-4 Turbo.
Le grand argument de Mistral est d'offrir des performances de premier plan sans le prix qui va avec. Il possède de solides compétences multilingues et les gens commentent souvent sa rapidité. Pour les entreprises, Mistral est une alternative très attractive pour toutes sortes de tâches, de la création de contenu à l'automatisation du support client. Il atteint un équilibre entre puissance et prix qui pousse les géants du secteur à y prêter attention.
GPT-4 Turbo vs Mistral : Une comparaison directe
Très bien, mettons ces deux poids lourds de l'IA sur le ring pour voir comment ils se comparent. Nous les comparerons sur trois aspects que toute entreprise doit prendre en compte : les performances brutes, les aspects pratiques comme la vitesse et le coût, et la réalité de leur mise en œuvre.
Performances et capacités
Commençons par la question la plus évidente : quel modèle est réellement le plus « intelligent » ? Lorsqu'on examine les tests utilisateurs et les benchmarks formels, une image assez claire commence à se dessiner.
Raisonnement et résolution de problèmes
Lorsqu'on leur soumet des casse-têtes logiques complexes ou des problèmes nécessitant plusieurs étapes, GPT-4 Turbo s'en sort généralement mieux. Une comparaison utilisateur très détaillée a révélé que GPT-4 obtenait de meilleurs résultats que Mistral Medium aux tests de raisonnement, parvenant à résoudre des scénarios complexes qui ont mis en difficulté d'autres modèles. Pour les tâches qui exigent une réflexion analytique approfondie, GPT-4 Turbo reste la référence.
Connaissances et précision
Les deux modèles en savent énormément sur, eh bien, tout. Mais GPT-4 Turbo a tendance à être légèrement plus précis et est un peu moins susceptible d'avoir des « hallucinations » (le terme technique pour désigner le fait d'inventer des informations). Dans ce même test Reddit, GPT-4 a obtenu un score de 9/10 sur des questions de culture générale, tandis que Mistral Medium a obtenu 8/10. Cela peut sembler une petite différence, mais elle peut être cruciale lorsque l'exactitude des faits n'est pas négociable.
Suivi des instructions et sortie structurée
Pour de nombreuses utilisations professionnelles, vous avez besoin d'une IA capable de générer des données structurées, comme du code JSON propre. Dans les tests comparant cette capacité, GPT-4 Turbo est plus fiable, fournissant presque toujours un format valide. Mistral, en revanche, peut parfois rencontrer des difficultés sur ce point.
Mais honnêtement, compter sur un modèle brut pour obtenir des données parfaitement structurées à chaque fois est un peu un pari risqué. C'est là que la plateforme que vous utilisez fait une énorme différence. Une plateforme d'IA dédiée comme eesel AI ajoute un moteur de workflow par-dessus le LLM. Cette couche supplémentaire garantit que la sortie de l'IA est correctement formatée et peut déclencher des actions spécifiques, comme l'ajout d'une étiquette à un ticket de support ou sa transmission à un agent humain. Cela vous offre une couche de fiabilité, quel que soit le modèle qui tourne en arrière-plan.
Voici un tableau rapide pour résumer leurs compétences clés :
| Fonctionnalité | GPT-4 Turbo | Mistral Large | Gagnant |
|---|---|---|---|
| Raisonnement avancé | Excellent | Très bon | GPT-4 Turbo |
| Connaissances générales | Excellent | Très bon | GPT-4 Turbo |
| Réduction des hallucinations | Très bon | Bon | GPT-4 Turbo |
| Sortie structurée (JSON) | Très fiable | Moins fiable | GPT-4 Turbo |
| Support multilingue | Solide | Solide (Natif) | Égalité |
Facteurs commerciaux pratiques
Être le plus intelligent ne fait pas tout. Pour une entreprise, des aspects pratiques comme la vitesse, la mémoire (sa « fenêtre de contexte »), et surtout le prix sont tout aussi, sinon plus, importants.
Vitesse et latence
Dans une situation comme un chat en direct avec un client, chaque seconde de retard semble une éternité. Les modèles Mistral sont généralement réputés pour être plus rapides que leurs homologues GPT-4. Bien que la vitesse exacte puisse varier, cela peut offrir une expérience beaucoup plus fluide et naturelle à vos utilisateurs.
Fenêtre de contexte
GPT-4 Turbo et Mistral Large ont tous deux de grandes fenêtres de contexte (128k tokens pour GPT-4 Turbo, 32k pour Mistral Large). Une grande fenêtre de contexte est essentiellement la mémoire à court terme de l'IA. Plus elle est grande, plus elle peut contenir d'informations et s'y référer à partir d'une seule conversation ou d'un seul document. C'est extrêmement important pour des tâches comme résumer un long fil d'e-mails de support ou répondre à des questions sur un manuel technique dense.
Tarifs
C'est sur ce point que Mistral brille vraiment. Il est beaucoup moins cher que GPT-4 Turbo, ce qui en fait une option fantastique pour les entreprises qui veulent utiliser l'IA à grande échelle sans voir leur budget exploser.
Examinons les tarifs réels de l'API pour les deux.
| Modèle | Fournisseur | Prix d'entrée (par million de tokens) | Prix de sortie (par million de tokens) |
|---|---|---|---|
| GPT-4 Turbo | OpenAI | 10,00 $ | 30,00 $ |
| Mistral Large | Mistral AI | 8,00 $ | 8,00 $ |
Comme vous pouvez le voir, Mistral Large n'est pas seulement un peu moins cher en entrée, il est radicalement moins cher pour le texte qu'il génère. Pour toute application à haut volume, comme un agent de support client IA, cette différence de coût s'accumule rapidement et peut complètement changer l'économie de votre projet.
Mise en œuvre pour votre entreprise
Choisir un modèle n'est que la première étape. Le vrai travail commence lorsque vous essayez de l'intégrer dans vos opérations quotidiennes et de le connecter à toutes les connaissances de votre entreprise. Utiliser simplement l'API brute nécessite un énorme travail d'ingénierie continu pour construire et maintenir tous les systèmes qui l'entourent.
C'est la « pièce manquante » où une véritable plateforme change la donne. Par exemple, lancer un agent IA pour le support client, c'est bien plus que faire un simple appel API. Vous devez :
-
Rassembler toutes vos connaissances : L'IA a besoin d'accéder à tout, pas seulement à ce qui se trouve sur l'Internet public. Cela inclut votre centre d'aide, vos anciens tickets de support, vos wikis internes sur Confluence ou Google Docs, et même les conversations de Slack.
-
Créer des workflows personnalisés : Vous devez contrôler ce que fait l'IA. Quand doit-elle essayer de répondre ? Quand doit-elle passer la conversation à un humain ? Quelles actions peut-elle entreprendre, comme étiqueter un ticket dans Zendesk ou consulter l'historique de commande d'un client ?
-
Le tester en toute confiance : Comment lancer un agent IA sans irriter vos clients ? Vous avez besoin d'un moyen de le tester sur vos données réelles pour voir ses performances avant même qu'il ne parle à qui que ce soit.
C'est exactement le problème pour lequel eesel AI a été conçu. C'est une plateforme qui fournit cette couche applicative cruciale par-dessus les puissants LLM, vous permettant d'être opérationnel en quelques minutes au lieu de plusieurs mois. Avec eesel AI, vous pouvez :
-
Connecter tous vos outils instantanément : Elle propose des intégrations en un clic avec votre service d'assistance, vos wikis et d'autres applications.
-
Entraîner l'IA sur votre historique : eesel AI apprend de vos milliers de conversations de support passées pour comprendre le ton de votre entreprise et les problèmes courants que vous résolvez.
-
Simuler avant d'activer : Vous pouvez tester votre agent IA sur vos anciens tickets pour voir exactement comment il aurait répondu. Cela vous donne un calcul clair du retour sur investissement et vous permet de tout affiner dans un environnement totalement sans risque, ce que vous ne pouvez tout simplement pas faire avec une API brute.
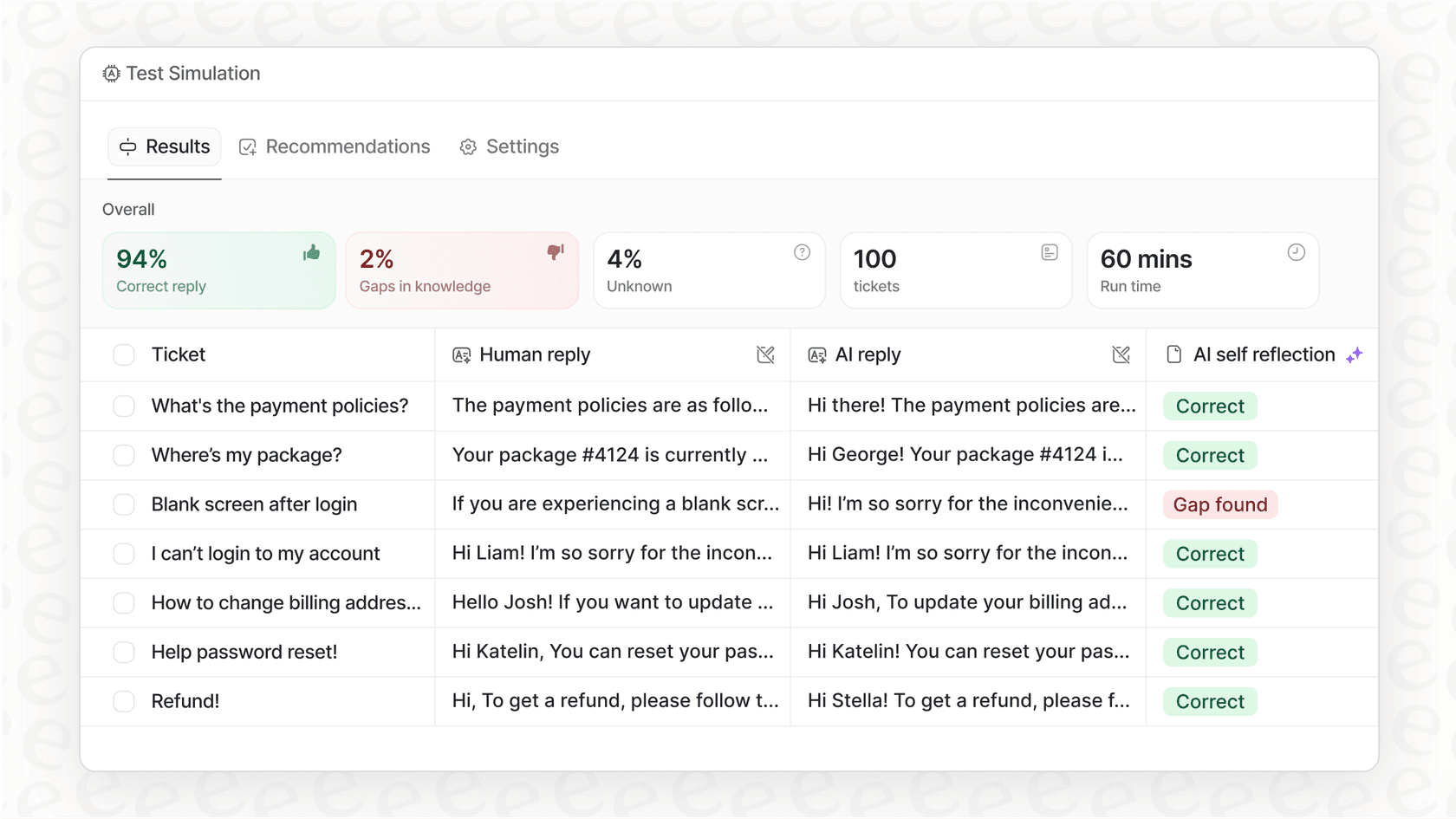
La plateforme que vous utilisez pour déployer votre IA est souvent plus importante que le modèle spécifique que vous choisissez.
GPT-4 Turbo vs Mistral : Choisir le bon modèle ne représente que la moitié du combat
Alors, quel est le verdict final dans l'affrontement GPT-4 Turbo vs Mistral ?
-
GPT-4 Turbo reste le champion de l'intelligence brute. Si votre projet exige absolument le plus haut niveau de précision et la résolution de problèmes complexes, c'est le choix le plus sûr.
-
Mistral est un concurrent très puissant et bien plus abordable. Sa vitesse et son prix nettement inférieur en font une excellente option pour développer votre utilisation de l'IA, surtout si vous pouvez accepter un petit compromis sur la capacité de raisonnement.
Mais la principale conclusion ici est que le modèle lui-même n'est qu'un ingrédient. Pour la plupart des entreprises, la stratégie gagnante n'est pas de choisir un « meilleur » modèle pour tout. Il s'agit de choisir une plateforme qui vous permet d'utiliser ces technologies incroyables facilement, en toute sécurité, et d'une manière qui aide réellement votre entreprise. Une plateforme comme eesel AI gère toute la complexité technique, vous permettant de vous concentrer sur la résolution de problèmes plutôt que sur la construction d'infrastructures.
Prêt à mettre l'IA au travail ?
Au lieu de vous perdre dans la documentation des API, vous pourriez voir à quelle vitesse vous pouvez automatiser votre support. Avec eesel AI, vous pouvez connecter votre base de connaissances, créer un agent IA personnalisé et voir ses performances en simulation, le tout en quelques minutes seulement.
Foire aux questions
GPT-4 Turbo excelle généralement dans le raisonnement avancé et la résolution de problèmes complexes, ce qui en fait le meilleur choix pour les tâches exigeant une réflexion analytique approfondie et une logique en plusieurs étapes. Mistral est très performant, mais GPT-4 Turbo l'emporte généralement pour ces défis spécifiques.
Mistral est nettement plus rentable, en particulier pour les tokens de sortie, ce qui en fait une option très intéressante pour les applications à grand volume où le budget est une préoccupation majeure. GPT-4 Turbo est considérablement plus cher par token, ce qui peut rapidement faire grimper la facture à grande échelle.
Les modèles Mistral sont généralement connus pour être plus rapides et avoir une latence plus faible que leurs homologues GPT-4, ce qui peut se traduire par une expérience utilisateur en temps réel plus fluide et plus naturelle. Cette différence est cruciale pour les applications où des réponses immédiates sont essentielles.
GPT-4 Turbo a tendance à être légèrement plus précis et a une plus faible propension aux « hallucinations » par rapport à Mistral. Bien que les deux soient très compétents, GPT-4 Turbo offre un léger avantage lorsque l'exactitude des faits n'est pas négociable.
No, le besoin d'une plateforme d'IA reste crucial quel que soit votre choix entre GPT-4 Turbo et Mistral. De telles plateformes gèrent les complexités de l'intégration du modèle avec vos données, la création de workflows et la garantie d'une sortie fiable et structurée, ce que les API brutes ne peuvent pas faire seules.
GPT-4 Turbo est généralement plus fiable pour produire des sorties de données structurées très fiables, comme du JSON propre. Bien que Mistral puisse accomplir cette tâche, il peut parfois échouer, ce qui rend une couche de plateforme supplémentaire encore plus précieuse pour garantir un formatage cohérent.
Share this article

Article by
Kenneth Pangan
Writer and marketer for over ten years, Kenneth Pangan splits his time between history, politics, and art with plenty of interruptions from his dogs demanding attention.