Intentar elegir el modelo de lenguaje grande (LLM, por sus siglas en inglés) adecuado para tu negocio puede sentirse como si estuvieras mirando una pared de especificaciones, puntos de referencia y jerga de marketing. Por un lado, tienes GPT-4 Turbo de OpenAI, el gran nombre que todos conocen por su puro poder. Por otro lado, tienes a Mistral, un retador europeo seriamente impresionante que está llamando la atención con su rendimiento y un precio mucho más amigable.
Entonces, ¿cuál es realmente mejor para las cosas que necesitas hacer, como manejar el servicio al cliente o construir un centro de ayuda interno? Esta guía corta el ruido del debate GPT-4 Turbo vs Mistral. Vamos a omitir las cosas puramente técnicas y nos centraremos en lo que realmente importa: cómo se desempeñan en el mundo real, cuánto cuestan y lo que realmente se necesita para ponerlos a trabajar para ti. Analizaremos dónde brilla cada modelo y descubriremos por qué el modelo que elijas es realmente solo la mitad de la historia.
¿Qué es GPT-4 Turbo?
GPT-4 Turbo es el modelo de gama alta de OpenAI, la gente detrás de ChatGPT. Piensa en él como la herramienta más avanzada en su caja de herramientas disponible públicamente, construido para masticar problemas complejos, pensar en situaciones difíciles y escribir texto de alta calidad que suena como si viniera de una persona. Es un modelo de código cerrado, por lo que normalmente accedes a él a través de una API (Application Programming Interface) de OpenAI o Microsoft Azure.
Las empresas suelen recurrir a GPT-4 Turbo cuando necesitan que se haga algo con alta precisión y una comprensión profunda de los matices. Estamos hablando de tareas como redactar documentos técnicos densos, buscar información en los datos o impulsar un chatbot que pueda manejar conversaciones complicadas. Sus principales fortalezas son su enorme conjunto de conocimientos generales y su habilidad para seguir instrucciones detalladas de varios pasos.
¿Qué es Mistral?
Mistral AI es una empresa con sede en París que saltó a la escena y rápidamente se hizo un nombre. Si bien tienen un ambiente amigable con el código abierto con algunos modelos de código abierto geniales, su modelo más poderoso, Mistral Large, es un competidor directo de GPT-4 Turbo.
El gran argumento de Mistral es que ofrece un rendimiento de primer nivel sin el precio de primer nivel. Tiene sólidas habilidades multilingües y la gente a menudo comenta lo rápido que es. Para las empresas, Mistral es una alternativa realmente convincente para todo tipo de cosas, desde crear contenido hasta automatizar la atención al cliente. Logra un equilibrio entre potencia y precio que está haciendo que los gigantes de la industria presten atención.
GPT-4 Turbo vs Mistral: Una comparación directa
Bien, pongamos a estos dos pesos pesados de la IA en el ring y veamos cómo se comparan. Los compararemos en tres frentes que toda empresa debe considerar: rendimiento bruto, cosas prácticas como la velocidad y el costo, y la realidad de ponerlos en marcha.
Rendimiento y capacidades
Comencemos con la pregunta más obvia: ¿qué modelo es realmente "más inteligente"? Cuando observas las pruebas de usuario y los puntos de referencia formales, comienza a formarse una imagen bastante clara.
Razonamiento y resolución de problemas
Cuando les lanzas rompecabezas de lógica complejos o problemas que requieren varios pasos, GPT-4 Turbo generalmente sale victorioso. Una comparación de usuario realmente detallada encontró que GPT-4 lo hizo mejor que Mistral Medium en las pruebas de razonamiento, descubriendo escenarios difíciles que desconcertaron a otros modelos. Para tareas que necesitan un pensamiento analítico profundo, GPT-4 Turbo sigue siendo el mejor.
Conocimiento y precisión
Ambos modelos saben mucho sobre, bueno, todo. Pero GPT-4 Turbo tiende a ser ligeramente más preciso y es un poco menos probable que tenga "alucinaciones" (que es el término técnico para inventar cosas). En esa misma prueba de Reddit, GPT-4 obtuvo una puntuación de 9/10 en preguntas de conocimiento general, mientras que Mistral Medium obtuvo un 8/10. Eso puede parecer una pequeña diferencia, pero puede ser un gran problema cuando obtener los datos correctos es innegociable.
Seguimiento de instrucciones y salida estructurada
Para muchos usos empresariales, necesitas una IA que pueda escupir datos estructurados, como código JSON limpio. En las pruebas que comparan esto, GPT-4 Turbo es más confiable, casi siempre dándote un formato válido. Mistral, por otro lado, a veces puede tropezar aquí.
Pero, honestamente, confiar en cualquier modelo sin procesar para que te dé datos perfectamente estructurados cada vez es un poco arriesgado. Aquí es donde la plataforma que utilizas marca una gran diferencia. Una plataforma de IA dedicada como eesel AI añade un motor de flujo de trabajo en la parte superior del LLM. Esta capa adicional se asegura de que la salida de la IA esté formateada correctamente y pueda desencadenar acciones específicas, como añadir una etiqueta a un ticket de soporte o escalarlo a un agente humano. Te da una capa de fiabilidad, sin importar qué modelo esté funcionando bajo el capó.
Aquí tienes una tabla rápida para resumir sus habilidades principales:
| Característica | GPT-4 Turbo | Mistral Large | Ganador |
|---|---|---|---|
| Razonamiento avanzado | Excelente | Muy bueno | GPT-4 Turbo |
| Conocimiento general | Excelente | Muy bueno | GPT-4 Turbo |
| Reducir las alucinaciones | Muy bueno | Bueno | GPT-4 Turbo |
| Salida estructurada (JSON) | Altamente confiable | Menos confiable | GPT-4 Turbo |
| Soporte multilingüe | Fuerte | Fuerte (nativamente) | Empate |
Factores empresariales prácticos
Ser el más inteligente no lo es todo. Para una empresa, las cosas prácticas como la velocidad, la memoria (su "ventana de contexto") y, especialmente, el precio son igual de importantes, si no más.
Velocidad y latencia
En algo así como un chat en vivo con un cliente, cada segundo de retraso se siente como una eternidad. Los modelos Mistral son generalmente conocidos por ser más rápidos que sus contrapartes GPT-4. Si bien la velocidad exacta puede variar, esto puede hacer que la experiencia sea mucho más fluida y natural para tus usuarios.
Ventana de contexto
Tanto GPT-4 Turbo como Mistral Large tienen grandes ventanas de contexto (128k tokens para GPT-4 Turbo, 32k para Mistral Large). Una ventana de contexto grande es básicamente la memoria a corto plazo de la IA. Cuanto más grande sea, más información puede contener y a la que puede remitirse desde una sola conversación o documento. Esto es súper importante para tareas como resumir una larga cadena de correos electrónicos de soporte o responder preguntas sobre un manual técnico denso.
Precios
Aquí es donde Mistral realmente brilla. Es mucho más barato que GPT-4 Turbo, lo que lo convierte en una opción fantástica para las empresas que quieren utilizar la IA a escala sin que su presupuesto se salga de control.
Veamos los precios reales de la API para ambos.
| Modelo | Proveedor | Precio de entrada (por 1 millón de tokens) | Precio de salida (por 1 millón de tokens) |
|---|---|---|---|
| GPT-4 Turbo | OpenAI | 10,00 $ | 30,00 $ |
| Mistral Large | Mistral AI | 8,00 $ | 8,00 $ |
Como puedes ver, Mistral Large no es solo un poco más barato al entrar, es drásticamente más barato para el texto que genera. Para cualquier cosa de gran volumen, como un agente de atención al cliente de IA, esa diferencia de costo se acumula rápidamente y puede cambiar por completo la economía de tu proyecto.
Implementación para tu negocio
Elegir un modelo es solo el primer paso. El verdadero trabajo comienza cuando intentas conectarlo a tus operaciones diarias y conectarlo a todo el conocimiento de tu empresa. El simple uso de la API sin procesar requiere un montón de trabajo de ingeniería continuo para construir y mantener todos los sistemas que lo rodean.
Esta es la "pieza que falta" donde una plataforma real cambia el juego. Por ejemplo, lanzar un agente de IA para la atención al cliente es mucho más que hacer una llamada a la API. Necesitas:
-
Reunir todo tu conocimiento: La IA necesita acceder a todo, no solo a lo que está en Internet público. Esto significa tu centro de ayuda, tus tickets de soporte anteriores, wikis internos en Confluence o Google Docs, e incluso conversaciones de Slack.
-
Construir flujos de trabajo personalizados: Necesitas tener el control de lo que hace la IA. ¿Cuándo debería intentar responder? ¿Cuándo debería pasar la conversación a un humano? ¿Qué acciones puede tomar, como etiquetar un ticket en Zendesk o buscar el historial de pedidos de un cliente?
-
Pruébalo con confianza: ¿Cómo lanzas un agente de IA sin molestar a tus clientes? Necesitas una forma de probarlo con tus datos reales para ver cómo funciona antes de que hable con una sola persona.
Este es exactamente el problema que eesel AI fue construido para resolver. Es una plataforma que proporciona esa capa de aplicación crucial en la parte superior de los LLM potentes, lo que te permite ponerte en marcha en minutos en lugar de meses. Con eesel AI, puedes:
-
Conectar todas tus herramientas al instante: Tiene integraciones de un solo clic con tu mesa de ayuda, wikis y otras aplicaciones.
-
Entrenar a la IA en tu historia: eesel AI aprende de tus miles de conversaciones de soporte pasadas para entender el tono de voz de tu empresa y los problemas comunes que resuelves.
-
Simular antes de activar: Puedes probar tu agente de IA en tus tickets antiguos para ver exactamente cómo habría respondido. Esto te da un cálculo claro del ROI y te permite afinar todo en un entorno completamente libre de riesgos, que es algo que simplemente no puedes hacer con una API sin procesar.
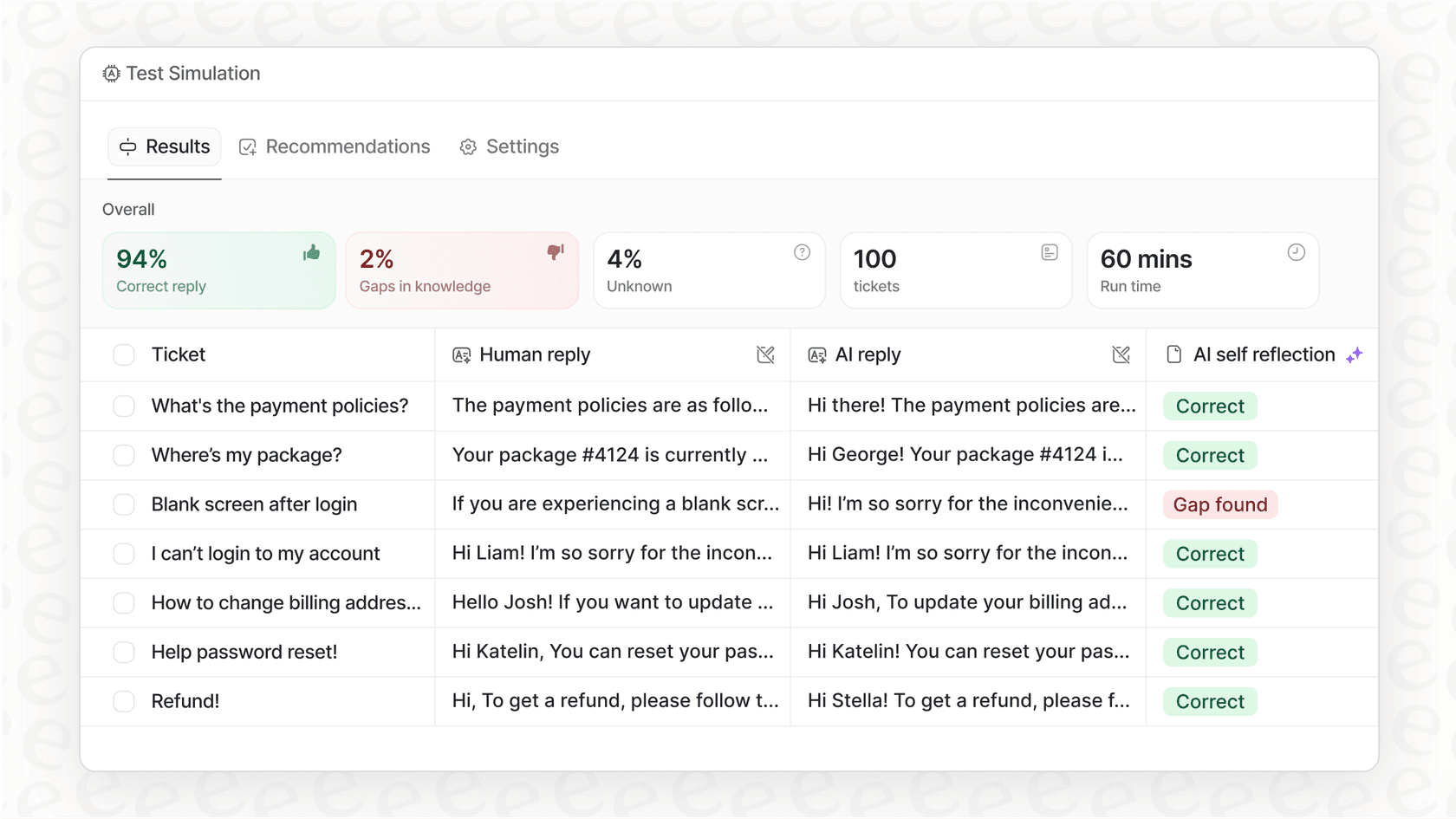
Al final del día, la plataforma que utilizas para implementar tu IA es a menudo más importante que el modelo específico que elijas.
GPT-4 Turbo vs Mistral: Elegir el modelo correcto es solo la mitad de la batalla
Entonces, ¿cuál es la decisión final en el enfrentamiento GPT-4 Turbo vs Mistral?
-
GPT-4 Turbo sigue siendo el campeón de la inteligencia bruta. Si tu proyecto requiere absolutamente el más alto nivel de precisión y resolución de problemas complejos, es la opción más segura.
-
Mistral es un retador muy poderoso y mucho más asequible. Su velocidad y su precio significativamente más bajo lo convierten en una opción brillante para ampliar el uso de la IA, especialmente si puedes vivir con una pequeña compensación en el poder de razonamiento.
Pero la mayor conclusión aquí es que el modelo en sí es solo un ingrediente. Para la mayoría de las empresas, la jugada ganadora no es elegir un "mejor" modelo para todo. Es elegir una plataforma que te permita utilizar estas increíbles tecnologías de forma fácil, segura y de una manera que realmente ayude a tu negocio. Una plataforma como eesel AI maneja toda la complejidad del backend, para que puedas concentrarte en resolver problemas en lugar de construir infraestructura.
¿Listo para poner la IA a trabajar?
En lugar de perderte en la documentación de la API, podrías ver lo rápido que puedes automatizar tu soporte. Con eesel AI, puedes conectar tu base de conocimientos, construir un agente de IA personalizado y ver cómo funciona en una simulación, todo en solo unos minutos.
Preguntas frecuentes
GPT-4 Turbo generalmente sobresale en razonamiento avanzado y resolución de problemas complejos, lo que lo convierte en la opción más sólida para tareas que demandan un pensamiento analítico profundo y una lógica de varios pasos. Mistral es muy capaz, pero GPT-4 Turbo suele ser el mejor para estos desafíos específicos.
Mistral es significativamente más rentable, especialmente para los tokens de salida, lo que lo convierte en una opción muy atractiva para aplicaciones de alto volumen donde el presupuesto es una preocupación principal. GPT-4 Turbo es considerablemente más caro por token, lo que puede acumularse rápidamente a escala.
Los modelos Mistral son generalmente conocidos por ser más rápidos y tener una latencia más baja que sus contrapartes GPT-4, lo que puede resultar en una experiencia de usuario en tiempo real más fluida y natural. Esta diferencia es crucial para las aplicaciones donde las respuestas inmediatas son vitales.
GPT-4 Turbo tiende a ser ligeramente más preciso y tiene una menor propensión a las "alucinaciones" en comparación con Mistral. Si bien ambos tienen un gran conocimiento, GPT-4 Turbo ofrece una ligera ventaja cuando la corrección fáctica no es negociable.
No, la necesidad de una plataforma de IA sigue siendo crucial independientemente de tu elección entre GPT-4 Turbo vs Mistral. Dichas plataformas manejan las complejidades de integrar el modelo con tus datos, construir flujos de trabajo y garantizar una salida confiable y estructurada, lo que las API sin procesar no pueden hacer por sí solas.
GPT-4 Turbo es generalmente más confiable para producir una salida de datos estructurada altamente confiable, como JSON limpio. Si bien Mistral puede realizar esta tarea, a veces puede tropezar, lo que hace que una capa de plataforma adicional sea aún más valiosa para un formato consistente.
Share this article

Article by
Kenneth Pangan
Writer and marketer for over ten years, Kenneth Pangan splits his time between history, politics, and art with plenty of interruptions from his dogs demanding attention.