Der Versuch, das richtige Large Language Model (LLM) für Ihr Unternehmen auszuwählen, kann sich anfühlen, als würden Sie auf eine Wand aus Spezifikationen, Benchmarks und Marketing-Jargon starren. Auf der einen Seite haben Sie GPT-4 Turbo von OpenAI, den großen Namen, den jeder für seine schiere Leistung kennt. Auf der anderen Seite haben Sie Mistral, einen beeindruckenden europäischen Herausforderer, der mit seiner Leistung und seinem viel freundlicheren Preis für Aufsehen sorgt.
Welches ist also tatsächlich besser für die Aufgaben, die Sie erledigen müssen, wie z. B. die Bearbeitung des Kundendienstes oder den Aufbau eines internen Helpdesks? Dieser Leitfaden durchbricht das Rauschen der Debatte GPT-4 Turbo vs. Mistral. Wir werden die rein technischen Dinge auslassen und uns auf das konzentrieren, was wirklich zählt: wie sie in der realen Welt abschneiden, wie viel sie kosten und was es tatsächlich braucht, um sie für Sie zum Laufen zu bringen. Wir werden uns ansehen, wo jedes Modell glänzt, und aufdecken, warum das von Ihnen gewählte Modell eigentlich nur die halbe Wahrheit ist.
Was ist GPT-4 Turbo?
GPT-4 Turbo ist das Topmodell von OpenAI, den Leuten hinter ChatGPT. Stellen Sie es sich als das fortschrittlichste Werkzeug in ihrem öffentlich zugänglichen Werkzeugkasten vor, das dafür entwickelt wurde, komplexe Probleme zu bewältigen, schwierige Situationen zu durchdenken und qualitativ hochwertigen Text zu schreiben, der sich anhört, als käme er von einer Person. Es ist ein Closed-Source-Modell, daher greifen Sie in der Regel über eine API von OpenAI oder Microsoft Azure darauf zu.
Unternehmen greifen normalerweise zu GPT-4 Turbo, wenn sie etwas mit hoher Genauigkeit und einem tiefen Verständnis für Nuancen erledigen müssen. Wir sprechen hier von Aufgaben wie dem Verfassen von dichten technischen Dokumenten, dem Durchsuchen von Daten nach Erkenntnissen oder dem Betreiben eines Chatbots, der komplizierte Gespräche führen kann. Seine Hauptstärken sind sein riesiger Pool an allgemeinem Wissen und sein Geschick, detaillierte, mehrstufige Anweisungen zu befolgen.
Was ist Mistral?
Mistral AI ist ein in Paris ansässiges Unternehmen, das auf der Bildfläche erschienen ist und sich schnell einen Namen gemacht hat. Während sie mit einigen großartigen Open-Weight-Modellen eine starke Open-Source-freundliche Stimmung haben, ist ihr leistungsstärkstes Modell, Mistral Large, ein direkter Konkurrent zu GPT-4 Turbo.
Mistrals großes Verkaufsargument ist, dass es erstklassige Leistung ohne den erstklassigen Preis bietet. Es verfügt über solide mehrsprachige Fähigkeiten und die Leute kommentieren oft, wie schnell es ist. Für Unternehmen ist Mistral eine wirklich überzeugende Alternative für alle möglichen Dinge, von der Erstellung von Inhalten bis zur Automatisierung des Kundensupports. Es findet ein Gleichgewicht zwischen Leistung und Preis, das die Branchenriesen aufhorchen lässt.
GPT-4 Turbo vs. Mistral: Ein direkter Vergleich
Okay, lassen Sie uns diese beiden KI-Schwergewichte in den Ring schicken und sehen, wie sie sich schlagen. Wir werden sie anhand von drei Gesichtspunkten vergleichen, die jedes Unternehmen berücksichtigen muss: Rohleistung, praktische Dinge wie Geschwindigkeit und Kosten sowie die Realität, sie zum Laufen zu bringen.
Leistung und Fähigkeiten
Beginnen wir mit der offensichtlichsten Frage: Welches Modell ist eigentlich "intelligenter"? Wenn Sie sich Benutzertests und formale Benchmarks ansehen, zeichnet sich ein ziemlich klares Bild ab.
Argumentation und Problemlösung
Wenn Sie ihnen komplexe Logikrätsel oder Probleme zuwerfen, die mehrere Schritte erfordern, geht GPT-4 Turbo normalerweise als Sieger hervor. Ein wirklich detaillierter Benutzervergleich ergab, dass GPT-4 in Argumentationstests besser abschnitt als Mistral Medium und knifflige Szenarien herausfand, die andere Modelle verblüfften. Für Aufgaben, die ein tiefes, analytisches Denken erfordern, ist GPT-4 Turbo immer noch unschlagbar.
Wissen und Genauigkeit
Beide Modelle wissen eine Menge über, nun ja, alles. Aber GPT-4 Turbo ist tendenziell etwas genauer und es ist etwas weniger wahrscheinlich, dass es "Halluzinationen" hat (was der Fachbegriff für das Erfinden von Dingen ist). In demselben Reddit-Test erzielte GPT-4 9/10 Punkten bei allgemeinen Wissensfragen, während Mistral Medium 8/10 Punkten erzielte. Das mag wie ein kleiner Unterschied erscheinen, aber es kann ein großer Unterschied sein, wenn es darauf ankommt, die Fakten richtig zu machen.
Befolgung von Anweisungen und strukturierte Ausgabe
Für viele geschäftliche Anwendungen benötigen Sie eine KI, die strukturierte Daten ausspucken kann, wie z. B. sauberen JSON-Code. In Tests, in denen dies verglichen wurde, ist GPT-4 Turbo zuverlässiger und liefert fast immer ein gültiges Format. Mistral hingegen kann hier manchmal ins Straucheln geraten.
Aber ehrlich gesagt ist es ein bisschen riskant, sich darauf zu verlassen, dass ein Rohmodell jedes Mal perfekt strukturierte Daten liefert. Hier macht die von Ihnen verwendete Plattform einen großen Unterschied. Eine spezielle KI-Plattform wie eesel AI fügt eine Workflow-Engine über dem LLM hinzu. Diese zusätzliche Ebene stellt sicher, dass die Ausgabe der KI korrekt formatiert ist und bestimmte Aktionen auslösen kann, z. B. das Hinzufügen eines Tags zu einem Support-Ticket oder die Eskalation an einen menschlichen Agenten. Sie erhalten eine Ebene der Zuverlässigkeit, unabhängig davon, welches Modell unter der Haube läuft.
Hier ist eine kurze Tabelle, die die Kernkompetenzen zusammenfasst:
| Feature | GPT-4 Turbo | Mistral Large | Gewinner |
|---|---|---|---|
| Fortgeschrittene Argumentation | Ausgezeichnet | Sehr gut | GPT-4 Turbo |
| Allgemeinwissen | Ausgezeichnet | Sehr gut | GPT-4 Turbo |
| Reduzierung von Halluzinationen | Sehr gut | Gut | GPT-4 Turbo |
| Strukturierte Ausgabe (JSON) | Sehr zuverlässig | Weniger zuverlässig | GPT-4 Turbo |
| Mehrsprachige Unterstützung | Stark | Stark (Nativ) | Unentschieden |
Praktische geschäftliche Faktoren
Der Klügste zu sein ist nicht alles. Für ein Unternehmen sind praktische Dinge wie Geschwindigkeit, Speicher (sein "Kontextfenster") und insbesondere der Preis genauso wichtig, wenn nicht sogar noch wichtiger.
Geschwindigkeit und Latenz
Bei so etwas wie einem Live-Chat mit einem Kunden fühlt sich jede Sekunde Verzögerung wie eine Ewigkeit an. Mistral-Modelle sind im Allgemeinen dafür bekannt, schneller zu sein als ihre GPT-4-Pendants. Während die genaue Geschwindigkeit variieren kann, kann dies zu einer viel reibungsloseren und natürlicheren Erfahrung für Ihre Benutzer führen.
Kontextfenster
Sowohl GPT-4 Turbo als auch Mistral Large haben große Kontextfenster (128.000 Token für GPT-4 Turbo, 32.000 für Mistral Large). Ein großes Kontextfenster ist im Grunde das Kurzzeitgedächtnis der KI. Je größer es ist, desto mehr Informationen kann es aus einem einzigen Gespräch oder Dokument aufnehmen und darauf zurückgreifen. Dies ist super wichtig für Aufgaben wie das Zusammenfassen einer langen Support-E-Mail-Kette oder das Beantworten von Fragen zu einem dichten technischen Handbuch.
Preisgestaltung
Hier glänzt Mistral wirklich. Es ist um einiges billiger als GPT-4 Turbo, was es zu einer fantastischen Option für Unternehmen macht, die KI in großem Umfang einsetzen wollen, ohne dass ihr Budget außer Kontrolle gerät.
Werfen wir einen Blick auf die tatsächlichen API-Preise für beide.
| Modell | Anbieter | Eingabepreis (pro 1 Mio. Token) | Ausgabepreis (pro 1 Mio. Token) |
|---|---|---|---|
| GPT-4 Turbo | OpenAI | 10,00 $ | 30,00 $ |
| Mistral Large | Mistral AI | 8,00 $ | 8,00 $ |
Wie Sie sehen können, ist Mistral Large nicht nur ein bisschen billiger auf dem Weg hinein, sondern auch drastisch billiger für den Text, den es generiert. Für alles mit hohem Volumen, wie z. B. ein KI-Kundendienstmitarbeiter, summiert sich dieser Kostenunterschied schnell und kann die Wirtschaftlichkeit Ihres Projekts komplett verändern.
Implementierung für Ihr Unternehmen
Die Auswahl eines Modells ist nur der erste Schritt. Die eigentliche Arbeit beginnt, wenn Sie versuchen, es in Ihre täglichen Abläufe zu integrieren und es mit dem gesamten Wissen Ihres Unternehmens zu verbinden. Allein die Verwendung der Roh-API erfordert eine Menge laufender technischer Arbeit, um alle Systeme darum herum aufzubauen und zu warten.
Dies ist das "fehlende Teil", bei dem eine echte Plattform das Spiel verändert. Zum Beispiel ist die Einführung eines KI-Agenten für den Kundensupport so viel mehr als nur ein API-Aufruf. Sie müssen:
-
Ihr gesamtes Wissen zusammenbringen: Die KI benötigt Zugriff auf alles, nicht nur auf das, was im öffentlichen Internet steht. Das bedeutet Ihr Hilfecenter, Ihre vergangenen Support-Tickets, interne Wikis auf Confluence oder Google Docs und sogar Gespräche von Slack.
-
Benutzerdefinierte Workflows erstellen: Sie müssen die Kontrolle darüber haben, was die KI tut. Wann soll sie versuchen, zu antworten? Wann soll sie das Gespräch an einen Menschen weiterleiten? Welche Aktionen kann sie ausführen, wie z. B. das Taggen eines Tickets in Zendesk oder das Nachschlagen der Bestellhistorie eines Kunden?
-
Mit Zuversicht testen: Wie führen Sie einen KI-Agenten ein, ohne Ihre Kunden zu verärgern? Sie brauchen eine Möglichkeit, ihn mit Ihren tatsächlichen Daten zu testen, um zu sehen, wie er abschneidet, bevor er überhaupt mit einer einzigen Person spricht.
Genau dieses Problem wurde mit eesel AI gelöst. Es ist eine Plattform, die diese entscheidende Anwendungsschicht über leistungsstarke LLMs bereitstellt, sodass Sie in wenigen Minuten anstelle von Monaten live gehen können. Mit eesel AI können Sie:
-
Verbinden Sie alle Ihre Tools sofort: Es verfügt über One-Click-Integrationen mit Ihrem Helpdesk, Wikis und anderen Apps.
-
Trainieren Sie die KI mit Ihrer Historie: eesel AI lernt aus Ihren Tausenden von vergangenen Support-Gesprächen, um den Tonfall Ihres Unternehmens und die häufigsten Probleme, die Sie lösen, zu verstehen.
-
Simulieren, bevor Sie aktivieren: Sie können Ihren KI-Agenten mit Ihren alten Tickets testen, um genau zu sehen, wie er reagiert hätte. Dies gibt Ihnen eine klare ROI-Berechnung und ermöglicht es Ihnen, alles in einer völlig risikofreien Umgebung zu optimieren, was mit einer Roh-API einfach nicht möglich ist.
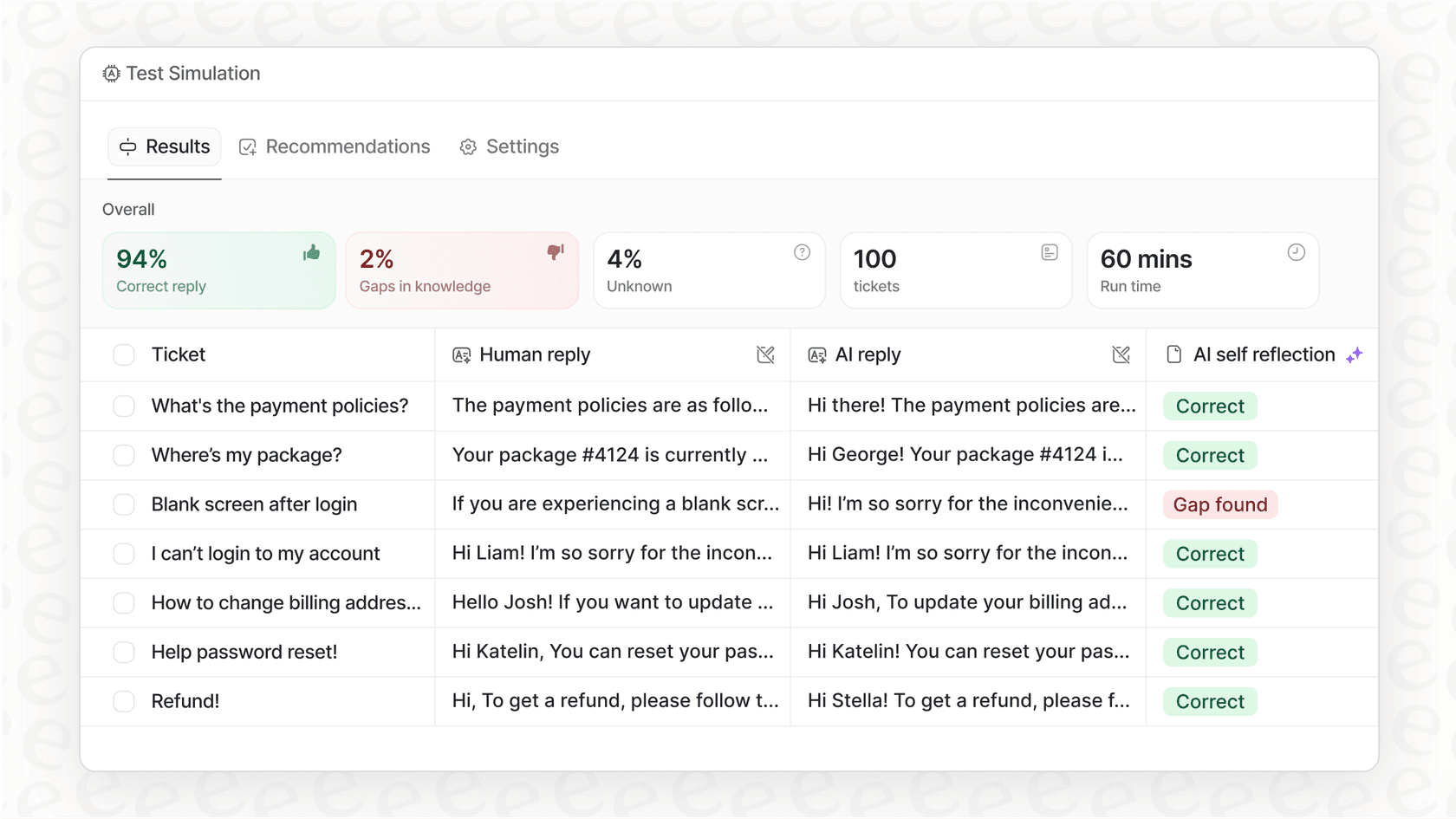
Letztendlich ist die Plattform, die Sie verwenden, um Ihre KI einzuführen, oft wichtiger als das spezifische Modell, das Sie wählen.
GPT-4 Turbo vs. Mistral: Die Wahl des richtigen Modells ist nur die halbe Miete
Was ist also das endgültige Urteil im Duell GPT-4 Turbo vs. Mistral?
-
GPT-4 Turbo ist immer noch der Champion der reinen Intelligenz. Wenn Ihr Projekt unbedingt das höchste Maß an Genauigkeit und komplexer Problemlösung erfordert, ist es die sicherste Wahl.
-
Mistral ist ein sehr leistungsstarker und viel günstigerer Herausforderer. Seine Geschwindigkeit und sein deutlich niedrigerer Preis machen ihn zu einer hervorragenden Option, um Ihre KI-Nutzung zu skalieren, insbesondere wenn Sie mit einem kleinen Kompromiss in der Argumentationskraft leben können.
Aber die wichtigste Erkenntnis hier ist, dass das Modell selbst nur eine Zutat ist. Für die meisten Unternehmen ist der Gewinn nicht die Wahl eines "besten" Modells für alles. Es geht darum, eine Plattform zu wählen, mit der Sie diese erstaunlichen Technologien einfach, sicher und auf eine Weise nutzen können, die Ihrem Unternehmen wirklich hilft. Eine Plattform wie eesel AI kümmert sich um die gesamte Backend-Komplexität, sodass Sie sich auf die Lösung von Problemen konzentrieren können, anstatt Infrastruktur aufzubauen.
Sind Sie bereit, KI einzusetzen?
Anstatt sich in der API-Dokumentation zu verlieren, könnten Sie sehen, wie schnell Sie Ihren Support automatisieren können. Mit eesel AI können Sie Ihre Wissensdatenbank verbinden, einen benutzerdefinierten KI-Agenten erstellen und in nur wenigen Minuten in einer Simulation sehen, wie er abschneidet.
Häufig gestellte Fragen
GPT-4 Turbo zeichnet sich im Allgemeinen durch fortgeschrittene Argumentation und komplexe Problemlösung aus, was es zur besseren Wahl für Aufgaben macht, die tiefes analytisches Denken und mehrstufige Logik erfordern. Mistral ist sehr leistungsfähig, aber GPT-4 Turbo ist in der Regel bei diesen spezifischen Herausforderungen die bessere Wahl.
Mistral ist deutlich kostengünstiger, insbesondere bei Ausgabetokens, was es zu einer äußerst attraktiven Option für Anwendungen mit hohem Volumen macht, bei denen das Budget eine vorrangige Rolle spielt. GPT-4 Turbo ist pro Token erheblich teurer, was sich in großem Maßstab schnell summieren kann.
Mistral-Modelle sind im Allgemeinen dafür bekannt, schneller zu sein und eine geringere Latenz zu haben als ihre GPT-4-Pendants, was zu einer flüssigeren und natürlicheren Echtzeit-Benutzererfahrung führen kann. Dieser Unterschied ist entscheidend für Anwendungen, bei denen sofortige Antworten von entscheidender Bedeutung sind.
GPT-4 Turbo ist tendenziell etwas genauer und hat eine geringere Neigung zu "Halluzinationen" als Mistral. Obwohl beide sehr kenntnisreich sind, bietet GPT-4 Turbo einen leichten Vorteil, wenn die faktische Korrektheit nicht verhandelbar ist.
Nein, der Bedarf an einer KI-Plattform bleibt unabhängig von Ihrer Wahl zwischen GPT-4 Turbo und Mistral bestehen. Solche Plattformen bewältigen die Komplexität der Integration des Modells in Ihre Daten, des Aufbaus von Workflows und der Sicherstellung einer zuverlässigen, strukturierten Ausgabe, was rohe APIs allein nicht leisten können.
GPT-4 Turbo ist im Allgemeinen zuverlässiger, wenn es darum geht, eine sehr zuverlässige, strukturierte Datenausgabe zu erzeugen, wie z. B. sauberes JSON. Mistral kann diese Aufgabe zwar erfüllen, kann aber manchmal ins Straucheln geraten, wodurch eine zusätzliche Plattformebene für eine konsistente Formatierung noch wertvoller wird.
Share this article

Article by
Kenneth Pangan
Writer and marketer for over ten years, Kenneth Pangan splits his time between history, politics, and art with plenty of interruptions from his dogs demanding attention.
