Résumé
Automatiser le support client en 2026, ce n'est pas échanger des humains contre un bot — c'est décomposer le support en une pile de tâches (étiquetage, routage, recherche dans la base de connaissances, rédaction de réponses, résolution autonome, escalade) et confier chacune à un logiciel là où les économies en valent la peine. L'écart de coût est d'environ 12× à 24× par ticket entre le traitement par l'IA et le traitement humain, ce qui justifie l'ensemble de la démarche (Gartner & Forrester via theStacc, 2026).
Le piège, en une ligne : la plupart des équipes visent la déviation et finissent par supprimer des tickets au lieu de les résoudre. Les bonnes équipes visent la résolution, définissent un seuil de confiance, et laissent l'IA gérer uniquement ce qu'elle peut bien traiter. Déployez en cinq étapes — audit, correction de la KB, pilote sur tickets passés, calibrage, mise en production — et mesurez ce qui compte vraiment.
Nous parcourrons toute la pile ici, avec de vrais chiffres, de vraies citations clients et les pièges à anticiper dans le budget. Si vous préférez passer directement à un outil qui gère toute la pile par-dessus Zendesk, Freshdesk, Gorgias, ou votre propre boîte de réception, eesel est le prochain clic logique.
Ce que signifie vraiment automatiser le support client
L'expression couvre beaucoup de terrain. Pour un acheteur en 2026, « automatiser le support client » signifie généralement l'une de ces trois choses — et l'écart entre elles importe plus que la plupart des articles ne l'admettent.
La première interprétation est celle basée sur des règles : macros, déclencheurs, réponses automatiques, routage en round-robin. C'est ce que la plupart des helpdesks proposent depuis une décennie. C'est utile, mais fragile — chaque nouvelle intention nécessite une nouvelle règle, et les bibliothèques de règles se transforment en milliers de conditions qui se chevauchent et que personne dans l'équipe ne comprend vraiment. La deuxième est l'interprétation chatbot : un arbre de décision sur le site web qui capte les questions courantes avant qu'elles ne deviennent des tickets. Ceux-ci ont un vrai rôle, mais un bot à arbre de décision est une FAQ en libre-service avec des étapes supplémentaires.
La troisième — et celle dont parle principalement ce guide — est l'automatisation agentique : un logiciel qui lit chaque ticket entrant, décide quoi faire, et soit rédige une réponse qu'un humain approuve, prend l'action lui-même, soit escalade. Les systèmes modernes utilisent des grands modèles de langage (GPT-4, Claude, Gemini) comme colonne vertébrale de raisonnement plutôt que de vieux pipelines de classification d'intention seuls, ce qui leur permet de comprendre les paraphrases, l'ambiguïté et les questions en plusieurs étapes qui briseraient les systèmes basés sur des mots-clés (ClarityArc, 2026).
Quand nous disons « automatiser le support client » dans cet article, nous parlons de la troisième interprétation — mais la réalité pratique est que la plupart des déploiements en production sont une pile des trois, avec les règles gérant les éléments déterministes et le LLM gérant le jugement.
Pourquoi les équipes s'y mettent maintenant
Trois chiffres résument toute l'histoire.
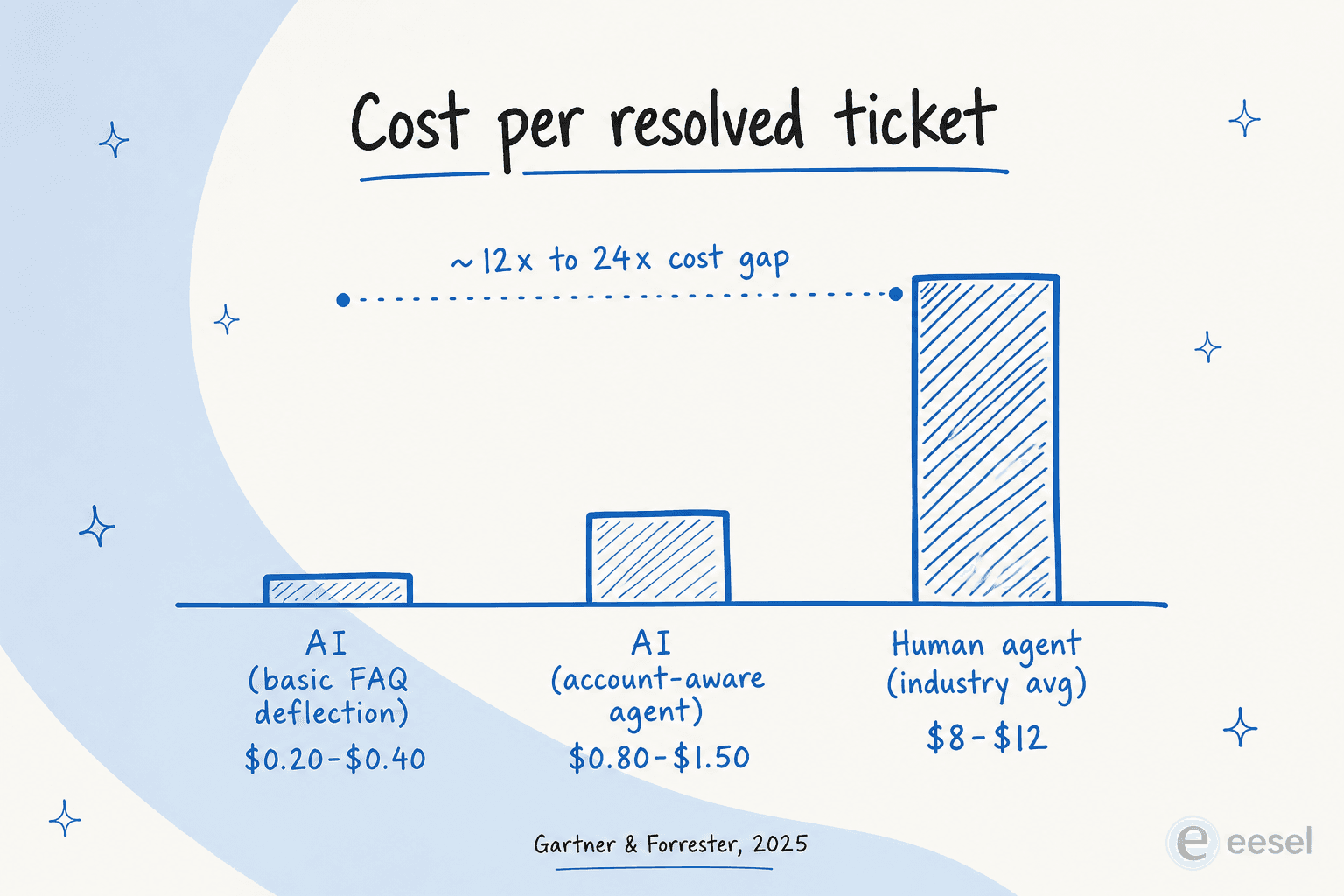
Premièrement : le coût. Un ticket de support traité par un humain coûte en moyenne 8 à 12 $ dans l'industrie, avec le SaaS B2B à 25 à 35 $ (SaaS Capital 2024 B2B Support Spending Report, via theStacc) ; la moyenne de l'échantillon McKinsey se situe à 7,40 $ (McKinsey AI in Customer Service 2026). Un ticket traité par l'IA coûte 0,20 $ à 0,40 $ pour la déviation FAQ basique, 0,80 $ à 1,50 $ pour les agents avec accès aux données de compte, avec la moyenne de l'échantillon McKinsey à 0,62 $ (Gartner, 2025). C'est l'écart qui pousse chaque directeur financier du support à demander une démo fournisseur.
Deuxièmement : les résultats. Les entreprises qui ont déployé l'IA dans le service client en 2025 ont réduit les coûts de support de 30% en moyenne, avec le quartile supérieur reportant des réductions de 53% (IBM, 2025, via theStacc). Le retour sur investissement s'étale sur 6 à 9 mois (Deloitte, 2025), et le ROI moyen atteint 3,50 $ par dollar investi, avec un ROI en année 1 de 41% (benchmarks Lorikeet CX). La prévision Gartner pour les économies mondiales totales générées par l'IA dans le service client est de 80 milliards de dollars d'ici 2027 (Gartner, 2024).
Troisièmement — et celui-ci est le signal humain le plus intéressant — le problème de volume ne s'améliore pas. Les équipes se noient dans des tickets répétitifs, et les personnes qui nous écrivent à ce sujet ressemblent exactement à ceci :
En tant que startup en croissance rapide avec une petite équipe, nos clients sont bien plus nombreux que nos employés. Il est crucial que nous disposions de solutions robustes en libre-service ainsi que d'outils pour décupler l'efficacité de nos équipes en contact avec les clients.
- Jon Miron, Directeur du Support & des Opérations, Yellowdig
Le calcul des coûts est ce qui fait approuver le budget. La réalité du volume est ce qui fait que le projet aboutit réellement.
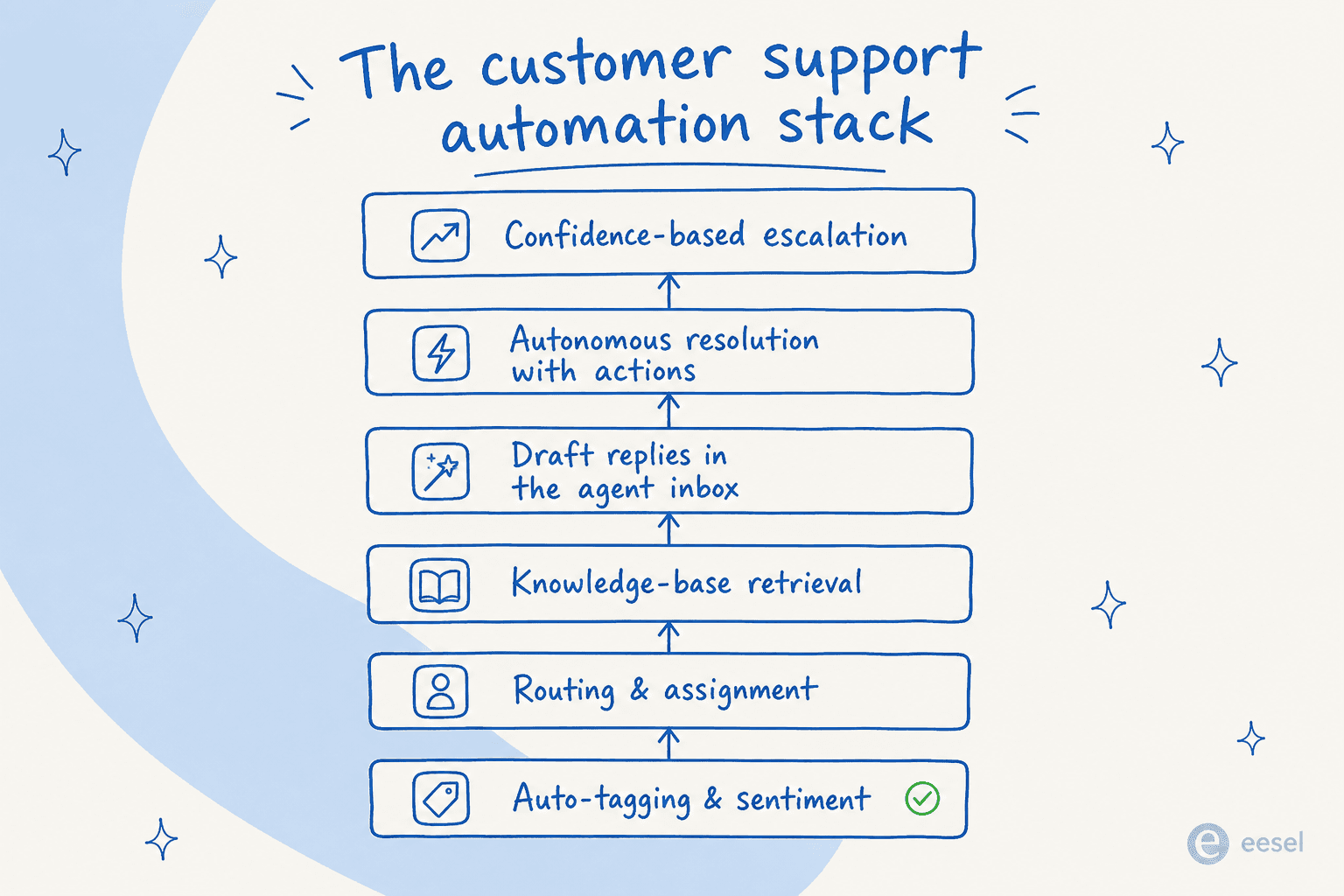
Les six couches de la pile d'automatisation du support client
Quand les acheteurs imaginent « automatiser le support », ils ont tendance à imaginer la version la plus spectaculaire — une IA qui lit les tickets et répond sans humain dans la boucle. C'est le sommet de la pile. Tout ce qui est en dessous fait aussi du vrai travail, et dans la plupart des équipes, c'est là que se trouvent les gains les plus sûrs et les plus rapides.
Couche 1 — Étiquetage automatique et sentiment
La partie la plus petite et à moindre risque. Le système lit chaque ticket entrant, le classe (intention, priorité, sentiment, domaine produit) et inscrit ces étiquettes dans le helpdesk avant qu'un humain ne l'ouvre. Les avantages en aval sont immédiats : les règles de routage deviennent précises, les rapports deviennent pertinents, et votre équipe arrête de ré-étiqueter les tickets manuellement. Guide pratique : travailler avec les étiquettes de tickets et classification de tickets par IA.
Couche 2 — Routage et affectation
Une fois les étiquettes en place, le routage suit. L'IA affecte chaque ticket à la bonne file d'attente, au bon agent ou au bon groupe de compétences en fonction de l'intention, de la langue, du niveau client ou du SLA. Bien fait, cela élimine le schéma « ticket qui circule dans l'équipe » qui ajoute des heures au temps de première réponse sans rien résoudre. Le guide de routage automatique des tickets Zendesk est le guide de référence ici, et la même logique s'applique proprement à Freshdesk et à Jira Service Management.
Couche 3 — Recherche dans la base de connaissances
C'est la couche que la plupart des articles survolent, et c'est celle qui détermine secrètement si le reste de la pile fonctionne. La déviation de tickets par IA est, à la base, un système de recherche documentaire avec une interface conversationnelle — son plafond de qualité est la qualité de la base de connaissances depuis laquelle il récupère les informations. L'analyse de Pylon a révélé qu'une documentation bien structurée augmente la résolution réelle de 15 à 25%, et EBI.ai a rapporté des taux de succès de 96% sur les requêtes dans le périmètre lorsque les docs étaient complets (SupportBench).
Si votre base de connaissances est lacunaire, corrigez-la avant d'activer quoi que ce soit d'autre. Un LLM augmenté par récupération entraîné sur de mauvais docs inventera des réponses avec confiance — et un client qui a reçu une réponse fausse mais confiante se désabonne plus vite qu'un client qui a reçu « laissez-moi vérifier avec l'équipe ».
Couche 4 — Rédaction de réponses dans la boîte de réception des agents
La couche « copilote ». L'IA lit le ticket, récupère les docs pertinents et rédige une réponse suggérée complète sous forme de note interne (ou de brouillon dans la fenêtre de réponse) qu'un agent humain examine, modifie et envoie. C'est le point de départ à plus fort levier pour la plupart des équipes : les agents avancent plus vite, l'humain reste responsable du ton et de l'exactitude, et l'équipe gagne en confiance sur la précision du modèle avant que quoi que ce soit ne devienne autonome.
Le guide classique est de configurer l'IA comme « premier répondant » — elle se déclenche sur les tickets entrants, laisse une réponse suggérée, effectue parfois une recherche documentaire dans les PDF et les articles de KB avant de rédiger :
Nous l'utilisons comme premier répondant à nos tickets Helpdesk dans Jira. Il agit essentiellement comme un agent le ferait.
- Jason Loyola, Responsable IT, étude de cas InDebted
Cette équipe utilise la couche de rédaction de réponses pour passer la déviation de 15% à 55% sur un service IT interne sur Jira Service Management. Le même schéma fonctionne sur les desks orientés clients : rédiger des réponses dans Zendesk, automatisations Gorgias, et automatisation Freshdesk supportent tous ce schéma nativement ou via un fournisseur par-dessus.
Couche 5 — Résolution autonome avec actions
La couche spectaculaire. L'IA lit le ticket, décide d'une action, l'exécute (remboursement, changement d'abonnement, mise à jour d'adresse, consultation du statut de commande) et répond au client — sans humain dans la boucle. C'est là que viennent les chiffres accrocheurs : l'IA de Klarna gère les deux tiers de tout le service client — l'équivalent de 700 agents à temps plein (SaaStr). Bilt Rewards gère 70% de 60 000 tickets mensuels de façon autonome (SaaStr citant Decagon). Le déploiement de Grammarly a atteint 87% de déviation en 10 jours avec un CSAT à 4,2/5 (étude de cas Forethought).
Le bémol est que cette couche ne fonctionne que si les quatre précédentes sont solides. Essayer de passer directement à la résolution autonome sans avoir fait le nettoyage de la KB et la phase de rédaction de réponses est la façon dont les équipes finissent avec le mode d'échec décrit dans la prochaine section.
Couche 6 — Escalade basée sur la confiance
La porte de sortie, et sans doute la couche la plus importante de toutes. L'IA génère une réponse candidate, évalue sa propre confiance (à l'aide de la couverture de récupération, du succès historique sur l'intention, et des signaux d'incertitude dans la réponse générée), et n'envoie de façon autonome que lorsque le score dépasse un seuil. En dessous du seuil, elle escalade avec le contexte complet à un humain.
Le seuil de confiance est l'une des décisions de conception les plus critiques dans tout système de déviation — et doit être calibré par le test, non supposé (ClarityArc, 2026). Ne faites pas confiance non plus aux scores de confiance bruts des LLM : ils mesurent la probabilité des tokens, pas l'exactitude factuelle. Un modèle peut être « confiant » à 95% concernant une réponse hallucinée (DEV Community). Associez les scores de confiance à des signaux de couverture de la base de connaissances et à des règles de périmètre thématique.
Le piège de la déviation — et pourquoi « résolution » est la meilleure métrique
C'est là que la plupart des équipes se trompent, et c'est la chose sur laquelle nous pousserions en retour le plus fort si un ami nous demandait conseil sur son plan de déploiement.
Le taux de déviation est la métrique la plus courante pour l'automatisation du support — et c'est une métrique maudite. Optimiser pour la déviation signifie optimiser pour moins de tickets, pas pour de meilleurs résultats. Le KPI s'améliore ; l'expérience client se détériore. Deux modes d'échec, tous deux bien documentés :
Mode d'échec un — le bot comme videur. Le taux de déviation atteint 75%, le tableau de bord brille en vert, les meilleurs clients partent silencieusement. D'après l'analyse de Corebee.ai portant sur plus de 50 discussions d'équipes de support :
Un fondateur SaaS a décrit cela exactement : « Optimiser le taux de déviation de tickets avec l'IA a failli ruiner notre taux de désabonnement. Arrêtez d'utiliser des bots comme videurs. » Leur taux de déviation a atteint 75%. Leurs clients à forte valeur vie se sont désabonnés parce qu'ils se sentaient bloqués pour atteindre un humain.
Mode d'échec deux — la réponse confiante mais fausse. Le bot répond quand il n'aurait pas dû. Le client lui fait confiance. La simple question devient une crise de confiance. Corebee a trouvé ce schéma dans sept fils de discussion distincts, et la cause profonde est constante : les bots optimisés pour le taux de déviation tentent de répondre à des requêtes qu'ils devraient escalader.
La solution est double. Premièrement, changez la métrique. Optimisez pour le taux de résolution — la part des tickets que l'IA a clôturés sans que le client ne recontacte dans les 48 heures, sans baisser le CSAT, sans escalader auprès d'un responsable. Gartner a constaté que l'IA dévie plus de 45% des requêtes clients en général, mais seulement environ 14% atteignent une véritable résolution en libre-service (Gartner via Fini Labs) — cet écart de qualité de 31 points est exactement le piège de la fausse déviation.
Deuxièmement, intégrez le routage basé sur la confiance dès le premier jour. L'énoncé le plus clair de cela que nous ayons en archive provient d'un responsable CX d'une marque de compléments alimentaires DTC gérant environ 7 000 tickets Gorgias/mois :
L'IA ne pourra jamais répondre à 100% des questions. J'ai besoin d'une IA qui ne gère que les tickets dont elle est sûre et laisse tous les autres tranquilles.
- anonymisé en tant que responsable CX d'une marque de compléments alimentaires DTC sur Gorgias + Shopify (~7K tickets/mois), d'après les entretiens clients eesel
Cette phrase est toute la thèse. Ne visez pas une IA qui répond à chaque ticket ; visez une IA qui sait lesquels elle ne devrait pas toucher.
Comment les vraies équipes l'utilisent
Les cas d'usage ci-dessous sont là où nous constatons le meilleur ROI avec les vrais clients eesel — mais les schémas se généralisent à tout fournisseur moderne d'automatisation du support.
Couverture première ligne, avec handover propre. L'IA gère les questions de première ligne quand les humains ne sont pas disponibles, et s'efface dès que le problème nécessite un jugement. D'après un avis client autorisé :
eesel agit comme notre support de première ligne jusqu'à ce qu'un contact humain soit nécessaire — répondant aux questions rapides quand l'équipe n'est pas disponible et nous laissant gérer les problèmes que seuls nous pouvons résoudre.
- Kellen Brown, Textla (avis G2 autorisé, eesel sur G2)
Triage avec rédaction de notes internes. L'agent se déclenche sur chaque ticket entrant, le classe, effectue des recherches documentaires dans la KB (et les PDF produit si nécessaire), et laisse une réponse suggérée complète sous forme de note interne. L'humain examine et soit envoie soit réécrit. Nous avons vu cela fonctionner sur des questions de passerelles de paiement roumaines, sur le dépannage technique EtherCAT chez des fournisseurs d'automatisation industrielle, et sur la reconnaissance de spam (l'agent compare les tickets entrants de type « pitch commercial » aux exemples passés et rédige un refus poli). Le schéma est le même ; les données varient énormément.
Étiquetage, routage et maintien à chaud. Au-delà des brouillons, l'IA étiquette automatiquement, remplit les champs personnalisés et route vers la bonne file d'attente. Certaines équipes utilisent cette même couche d'automatisation pour maintenir les tickets escaladés « à chaud » avec des messages de réassurance pendant que l'équipe attend les partenaires de paiement tiers — pas besoin de KB, juste des instructions. (D'après un entretien client fintech anonymisé en archive, ~7 000 tickets escaladés/mois.)
Capturer la connaissance tribale avant qu'elle ne parte. C'est le cas d'usage que nous entendons le plus souvent des organisations de support plus anciennes : les agents seniors avec une connaissance approfondie du produit partent, et l'équipe veut que leurs réponses soient « dans l'IA » avant leur départ. Une entreprise française de services IT B2B supportant le dépannage ERP pour le secteur public (~3 000 tickets/mois sur Freshdesk) l'a formulé explicitement — le travail de l'IA n'était pas de remplacer les agents seniors, mais de garder leurs réponses disponibles après leur départ.
Le point est que « automatiser le support client » n'a pas besoin de signifier résolution autonome pour être une victoire. Les couches 1 à 4 (étiquetage, routage, recherche KB, rédaction de réponses) génèrent généralement plus de ROI total que la couche 5 ne le fait jamais, et elles se déploient en semaines plutôt qu'en trimestres.
Un déploiement pratique en 5 étapes
La plupart des projets d'automatisation du support échoués que nous entendons ont sauté une étape ici. L'ordre compte.
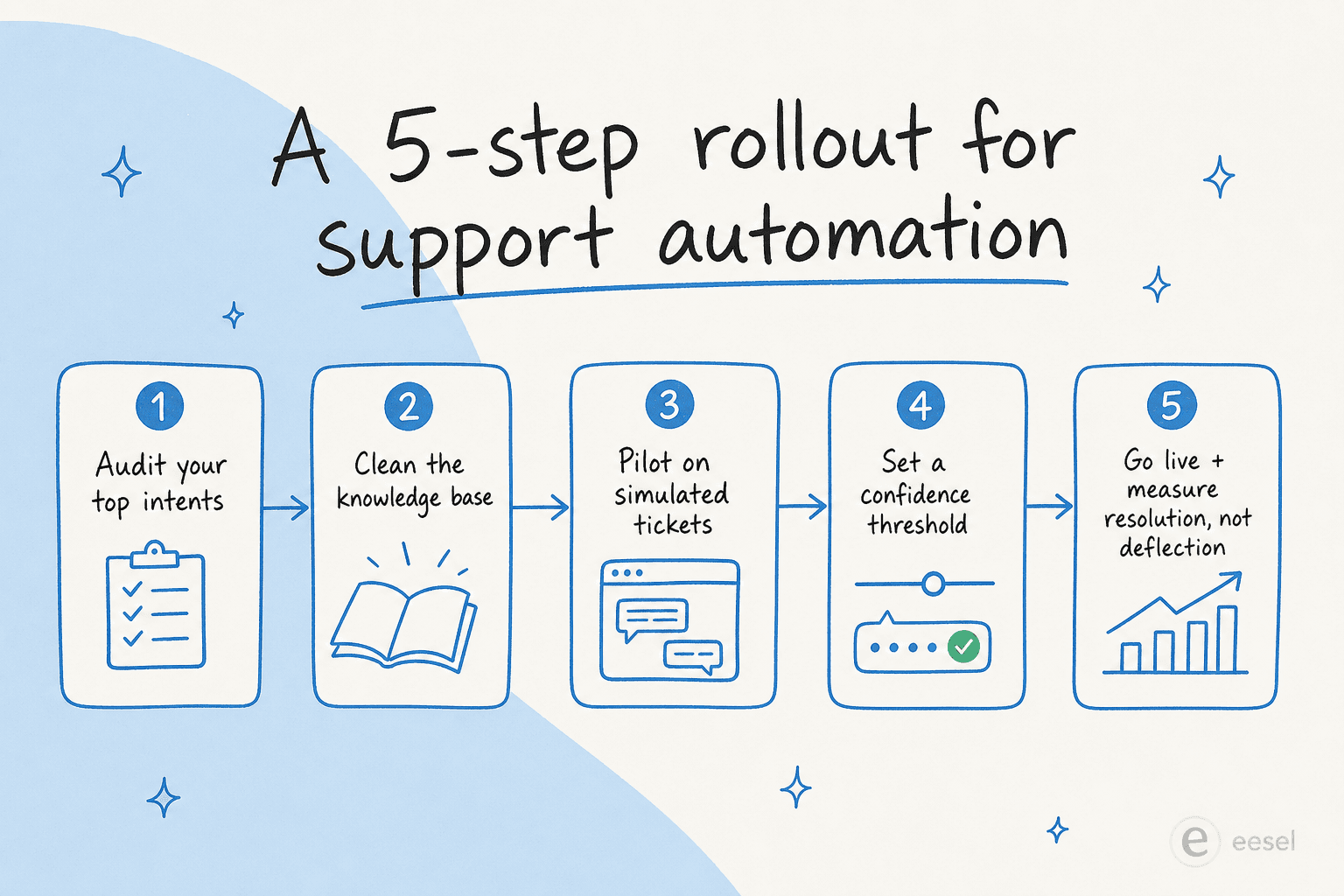
Étape 1 — Auditez vos principales intentions
Extrayez les 30 derniers jours de tickets et regroupez-les par intention. Vous cherchez les 10 premiers groupes qui représentent 70 à 80% du volume total. Ce sont les cibles — l'automatisation rapporte le plus vite sur les intentions à haute fréquence et faible complexité. Les intentions chargées en sentiment ou de type litige dépassent rarement 25% de déviation même dans les meilleurs déploiements (ClarityArc 2026), donc laissez-les hors du périmètre initial.
Cadrage concret : si les réinitialisations de mot de passe, les questions de facturation et le statut de commande représentent 60% de votre volume, ces trois groupes constituent votre première phase. N'essayez pas de « tout faire » en v1.
Étape 2 — Nettoyez la base de connaissances
Pour chacune des principales intentions, trouvez l'article qui devrait y répondre. S'il n'existe pas, écrivez-le. S'il existe mais est obsolète ou dans la mauvaise voix, réécrivez-le. C'est l'étape peu glamour qui détermine si le reste du déploiement fonctionne. Le guide du chatbot IA pour la base de connaissances approfondit ce à quoi ressemble un « bon » article — réponses courtes en haut, titres structurés, exemples, pas de formulations hésitantes.
Un test utile : lisez l'article et demandez-vous « si un nouvel employé ne lisait que ça, pourrait-il répondre correctement à la question ? » Si non, l'IA ne le peut pas non plus.
Étape 3 — Pilotez sur des tickets simulés, pas sur des clients
Avant qu'un client ne voie la production de l'IA, faites-la tourner sur les 90 derniers jours de vrais tickets en mode simulation. Comparez les brouillons de l'IA à ce que l'agent humain a réellement envoyé. Où divergent-ils ? Où l'IA aurait-elle escaladé ? Où l'IA a-t-elle rédigé une réponse confiante qui s'est avérée fausse ? C'est la seule façon honnête de définir les attentes avec l'équipe avant la mise en production, et c'est là que vous trouverez les modes d'échec qui ne figurent dans aucune démo fournisseur.
Cherchez des équipes dont le fournisseur offre cette capacité de simulation nativement — c'est un filtre tranchant entre les fournisseurs qui ont mis en production et ceux qui ne l'ont pas fait.
Étape 4 — Définissez un seuil de confiance (et une liste interdite)
Avant d'activer quoi que ce soit pour de vrais clients, deux décisions :
- Le seuil de confiance pour la réponse autonome. La plupart des équipes commencent de façon conservatrice (seuil élevé, faible volume de réponses autonomes, haute précision) et l'assouplissent au fil du temps. Commencer de façon permissive et resserrer est bien plus difficile car la confiance de l'équipe est brûlée dès le premier jour.
- La liste interdite. Les types de tickets que l'IA ne résoudra jamais de façon autonome — comme les annulations, les remboursements au-dessus d'un seuil en dollars, tout ce qui est étiqueté « juridique » ou « litige de facturation », tout ce qui provient d'un niveau client VIP. D'après une vraie citation client : « Il y a certains tickets que je ne veux pas faire passer par l'IA. »
Étape 5 — Mettez en production, mesurez la résolution (pas la déviation)
Activez-le pour un canal, un cluster d'intentions. Surveillez le taux de résolution, le delta CSAT, le taux de recontact dans les 48 heures et la précision de l'escalade. Ne regardez pas uniquement le taux de déviation — il vous dira que le bot se porte très bien quand l'expérience client s'effondre en dessous.
Un cocktail KPI utile à présenter à la direction :
| Métrique | Ce qu'elle vous dit |
|---|---|
| Taux de résolution | % de tickets clôturés sans recontact dans les 48h |
| Delta CSAT vs. base de référence humaine uniquement | Si les tickets de l'IA se terminent mieux que les humains |
| Précision de l'escalade | % des tickets escaladés qui étaient la bonne décision |
| Temps de première réponse (médiane) | La baisse ici est généralement la plus grande victoire visible |
| Coût par résolution | Le levier ROI économique |
Ce cocktail récompense « répond à moins de tickets mais y répond correctement » plutôt que « répond à tout mal ». Faites-le tourner mensuellement ; resserrez le seuil selon ce qu'il montre.
Les pièges à anticiper dans le budget
Six modes d'échec à analyser avant le lancement, tous documentés dans des déploiements en production :
- La réponse confiante et fausse. Les scores de confiance des LLM mesurent la probabilité des tokens, pas l'exactitude factuelle (DEV Community). Associez la confiance à des signaux de couverture de KB.
- La recontact déguisée en déviation. Les clients recontactent via d'autres canaux (téléphone, e-mail, réseaux sociaux). Le tableau de bord de la plateforme montre 80% de déviation ; la vraie déviation ajustée pour la recontact de 48h est plus proche de 55-65% (ClarityArc 2026).
- Optimiser le KPI, pas le résultat. Faites de la déviation le KPI et l'équipe rendra les tickets plus difficiles à ouvrir — le bot tourne en boucle, le bouton de contact est enterré, le CSAT chute. Passez au taux de résolution.
- Le piège des 47% de coût fixe. Les entreprises qui n'ont pas repensé leurs flux de travail autour de l'IA : 47% ont rapporté des coûts stables ou en hausse (theStacc 2026). L'IA en tant qu'ajout sans refonte des processus ajoute simplement des coûts de licence en plus de la masse salariale existante.
- Le biais de l'IA à tenter des réponses. Une étude de 100 050 interactions a révélé que les bots IA sont 37% plus susceptibles d'éloigner les problèmes de la résolution que les humains lorsqu'ils sont configurés pour optimiser la déviation (étude citée par Corebee). Interdisez les intentions que l'IA ne devrait pas toucher.
- Sauter le pilote. « On va juste l'activer et l'ajuster en direct » est la façon dont les fournisseurs perdent des clients en semaine deux.
Ce qu'il faut chercher chez un fournisseur
Après avoir observé des dizaines de ces déploiements, les fonctionnalités qui comptent vraiment (et dont la plupart des fournisseurs ne parlent pas assez) sont :
- Intégration native avec le helpdesk existant. Ne migrez pas. L'IA doit s'asseoir à l'intérieur de Zendesk, Freshdesk, Gorgias, ou là où l'équipe vit déjà. Un remplacement complet double le risque du projet sans avantage.
- Mode simulation sur les tickets passés. Voir ci-dessus. C'est le filtre fournisseur le plus tranchant.
- Routage basé sur la confiance comme fonctionnalité de premier ordre, pas un ajout. Granulaire : par intention, par type de ticket, par niveau client.
- Listes d'exclusion de types de tickets. « Il y a certains tickets que je ne veux pas faire passer par l'IA » — c'est une vraie citation client, et la bonne réponse est un contrôle dans l'interface, pas un message Slack au CSM du fournisseur.
- Tarification à l'usage, pas par siège. La tarification par siège vous pénalise pour avoir ajouté des humains à l'équipe de support — ce que vous voudrez faire exactement lorsque le volume de tickets croît en termes absolus (il tend à le faire, même lorsque la part de l'IA augmente). La tarification d'eesel est de 0,40 $ par ticket sans frais de siège comme exemple concret.
- Gestion multilingue sans babysitting de prompt. Si votre base clients couvre plus d'une langue, c'est plus important que ce que la démo vous laissera apprécier.
- Une mesure honnête de la résolution, pas seulement de la déviation, visible dans le tableau de bord. Bonus si cela vous montre les tickets que l'IA a mal traités, pas seulement ceux qu'elle a bien traités.
Pour une comparaison directe des vraies options, notre sélection meilleure IA pour l'automatisation du support client et les meilleurs outils IA pour automatiser le support client couvrent le marché ; meilleure IA pour le support client Shopify et meilleur chatbot IA pour le service client se concentrent sur des niches spécifiques.
Ce qu'atteignent vraiment les bons déploiements
Un tableau réaliste de ce vers quoi les chiffres tendent, tiré de vraies données de production plutôt que de présentations commerciales de fournisseurs :
| Résultat | Plage observée en production | Source |
|---|---|---|
| Déviation tier-1 (médiane) | 41% | ClarityArc 2026 |
| Déviation tier-1 (quartile supérieur) | 58,7% | ClarityArc 2026 |
| Meilleure déviation agentique | 70-92% sur les intentions routinières | Forrester Wave 2025 |
| Réduction des coûts (moy. première année) | 30% | IBM 2025 |
| Réduction des coûts (quartile supérieur) | 53% | IBM 2025 |
| Amélioration du temps de première réponse | 37% plus rapide | G2 AI in Customer Service |
| Amélioration du temps de résolution | 52% plus rapide | G2 AI in Customer Service |
| Débit des agents augmentés par l'IA | 13,8% de requêtes supplémentaires/heure | G2 AI in Customer Service |
| Période de retour sur investissement | 6-9 mois | Deloitte 2025 |
| ROI moyen | 3,50 $ par dollar investi | Lorikeet CX |
Quelques exemples réels de production pour ancrer ces plages dans des équipes nommées : l'IA de Klarna gère les deux tiers du service client (équivalent de 700 ETP) ; Bilt Rewards gère 70% de 60 000 tickets mensuels ; Grammarly a atteint 87% de déviation en 10 jours, avec un CSAT à 4,2/5 et un boost supplémentaire de 5-10% grâce aux intégrations système ; Forma (13 800 utilisateurs sur Forethought Solve) est passé de 30% à 39% de déviation entre octobre 2024 et mars 2025 grâce à un ajustement continu ; les équipes retail sur Freshworks Freddy résolvent 53% des requêtes entrantes avec l'IA, selon le Freshworks Customer Benchmark Report 2025. La synthèse de SaaStr est la source unique la plus propre pour ces chiffres.
De notre côté, nous avons vu jusqu'à 80% d'économies de temps sur les réponses rapides et l'onboarding grâce au déploiement Confluence de Global Pay (voir cas d'usage IA avec Confluence), et le responsable CX de Gridwise rapportant « 73% de nos requêtes tier 1... résolues rapidement lors de notre essai de 7 jours ». Ce sont tous deux des témoignages clients autorisés.
Essayez eesel
eesel est la couche d'automatisation du support que nous choisirions si vous êtes déjà sur Zendesk, Freshdesk, Gorgias, Jira Service Management ou Slack — et que vous ne voulez pas migrer pour que l'automatisation fonctionne. L'agent lit chaque ticket entrant, effectue des recherches documentaires dans votre KB et vos tickets historiques, rédige la réponse (ou l'envoie de façon autonome lorsqu'il est confiant), et escalade le reste avec le contexte complet. Le routage par confiance, l'exclusion de types de tickets, le mode simulation sur les tickets passés et les garde-fous par intention sont tous des fonctionnalités de premier ordre, pas des éléments de roadmap.

La tarification est de 0,40 $ par ticket résolu, sans frais de siège, sans frais de plateforme en libre-service, et un crédit d'essai de 50 $ à l'inscription. Le tableau complet se trouve sur la page de tarification, et la sélection meilleure IA pour l'automatisation du support client la met en contexte face-à-face avec le reste du marché. Essayez eesel si l'un des points ci-dessus ressemble au déploiement que vous essayez de planifier.
Questions fréquemment posées
Qu'est-ce que cela signifie concrètement d'automatiser le support client ?
Automatiser le support client, c'est déléguer des fragments du flux de travail — étiquetage, routage, recherche dans la base de connaissances, rédaction de réponses, résolution autonome, escalade — à un logiciel qui s'exécute sur chaque ticket entrant. Ce n'est pas un seul interrupteur ; c'est une pile de tâches, chacune pouvant être automatisée indépendamment. Le bon équilibre dépend du volume de tickets, de la maturité de la base de connaissances et du niveau de risque que votre équipe est prête à assumer sur les réponses autonomes.
Combien coûte l'automatisation du support client ?
L'économie par ticket est le chiffre clé. Les tickets traités par un humain coûtent en moyenne 8 à 12 $, et jusqu'à 25 à 35 $ pour le SaaS B2B, tandis que les tickets traités par l'IA se situent entre 0,20 $ et 1,50 $ selon que l'agent lit uniquement les docs ou accède aussi aux données de compte (Gartner & Forrester via theStacc, 2026). Les tarifs des plateformes varient énormément — les agents à l'usage comme eesel à 0,40 $ par ticket se trouvent à un extrême, les contrats d'entreprise par siège à l'autre. Le tableau complet est dans notre analyse des économies de coûts.
Quel est un taux de déviation réaliste lorsqu'on automatise le support client ?
Les médianes sectorielles se situent à ~41% de déviation tier-1, avec un quartile supérieur autour de 58,7% (ClarityArc, 2026). Les systèmes agentiques avec intégrations backend poussent cela à 70 à 92% sur les intentions routinières. Mais la déviation n'est pas la même chose que la résolution — Gartner a constaté que seulement ~14% des requêtes déviées atteignent une véritable résolution en libre-service, un écart de qualité de 31 points. Optimisez pour la résolution, pas pour la déviation.
L'IA va-t-elle remplacer les agents de support humains ?
Non, et les équipes qui le formulent ainsi ont tendance à perdre leurs clients. L'assistant IA de Klarna gère l'équivalent de 700 agents à temps plein, mais les humains restent propriétaires des cas difficiles. Les données montrent aussi que les agents augmentés par l'IA traitent 13,8% de requêtes supplémentaires par heure. Le bon modèle est l'IA pour le volume, les humains pour le jugement — pas l'un ou l'autre.
Par où commencer si ma base de connaissances est dans un état désastreux ?
Commencez par là. L'analyse de Pylon a révélé qu'une documentation bien structurée augmente la résolution réelle de 15 à 25%, et ClarityArc le dit sans détour : « un agent de déviation de tickets est un système de recherche documentaire avec une interface conversationnelle. » Auditez vos 10 principales intentions de tickets, rédigez ou réécrivez les docs qui y répondent, et seulement ensuite activez l'agent. Un chatbot IA basé sur une base de connaissances construit sur une KB pauvre va halluciner ; construit sur une KB complète, EBI.ai rapporte 96% de succès sur les requêtes dans le périmètre.
Quelle est la façon la plus rapide d'automatiser le support client sur Zendesk, Freshdesk ou Gorgias ?
Posez la couche d'automatisation par-dessus votre helpdesk existant plutôt que de le remplacer. La plupart des équipes commencent par les réponses rédigées dans la boîte de réception des agents (risque faible, économies élevées), puis activent l'étiquetage et le routage automatiques, puis passent à la résolution autonome pour les intentions les plus fiables. Guides pratiques par plateforme : automatiser les tickets Zendesk, automatiser Freshdesk, et le guide Gorgias pour les équipes e-commerce.

Article by
Rama Adi Nugraha
Rama is a software engineer at eesel AI with two years of experience writing about B2B SaaS, AI tools, and customer support technology. Based in Bali, Indonesia, he brings a developer's perspective to product comparisons — cutting through marketing copy to what the integrations and APIs actually do.