Por qué la reducción de tickets con IA vuelve a estar en la cima de la agenda CX
Los líderes de soporte no están recibiendo presupuestos más grandes. Sin embargo, están recibiendo colas mucho más grandes. El 53% de los profesionales del servicio al cliente en 2025 identificó "gestionar el volumen de tickets sin aumentar la plantilla" como su principal desafío, según el Freshworks Customer Benchmark Report 2025, y el 90% de los agentes en servicios empresariales dice que el trabajo repetitivo les impide atender los tickets de mayor valor.
El argumento económico se escribe solo cuando pones dos números uno junto al otro. Un ticket gestionado por humanos promedia $8–$12 en todas las industrias, según Forrester, y sube hasta $25–$35 en SaaS B2B. Un ticket gestionado por IA, incluso uno en el que la IA busca datos de la cuenta y toma una acción, promedia $0,50–$1,05. Eso es una diferencia de costo de 12× a 24× por interacción, y se multiplica con cada ticket que reduces.
Por eso se proyecta que la IA en el servicio al cliente crecerá de $12.060 millones en 2024 a $47.820 millones para 2030, un CAGR del 25,8%. Y por eso $80.000 millones en ahorros globales de soporte proyectados para 2027 según Gartner es la cifra que los compradores capturan en pantalla.
Pero, y esta es la parte que la mayoría de los artículos omiten, la razón por la que el 47% de las empresas reporta costos estables o en aumento después de desplegar IA no es la IA. Es que la conectaron a los mismos flujos de trabajo rotos y llamaron al resultado "deflexión". Ese es el modo de fallo que la siguiente sección analiza.
"Deflexión" y "reducción": las palabras importan
Mucha confusión en este espacio surge de que la gente usa estos términos de forma intercambiable. No son lo mismo.
- Deflexión es una táctica: el cliente obtiene una respuesta (o una ruta de autoservicio que realmente le responde) antes de que se abra un ticket.
- Reducción es el resultado: menos tickets que necesitan tiempo humano. La reducción incluye la deflexión, pero también incluye el triaje con IA que cierra tickets en segundos, borradores que un humano puede enviar con un clic, y correcciones proactivas de producto/UX que evitan que se haga la pregunta en absoluto.
La razón por la que esto importa: un equipo que optimiza únicamente para la tasa de deflexión pondrá silenciosamente más obstáculos para que los clientes lleguen a un humano, como documentó el análisis de Corebee de más de 50 hilos de equipos de soporte. Un equipo que optimiza para la reducción observa todo el embudo, incluidos los tickets que deberían seguir llegando a un humano, solo que más rápido y más económico.
"No creo en la deflexión de tickets. Creo en hacer los tickets innecesarios. Hay una diferencia. La deflexión redirige al cliente. Hacer los tickets innecesarios soluciona lo que causó la pregunta."
Líder de soporte citado en la síntesis de debate de Corebee.ai
Ten en cuenta esa distinción durante el resto de este artículo. Cuando decimos "reducción de tickets con IA", nos referimos a todo el embudo, no solo al número de deflexión titular en un panel.
El problema del 14%: lo que la mayoría de los paneles de deflexión no te están diciendo
Este es el número más importante de todo este artículo, y es el que casi nadie cita:
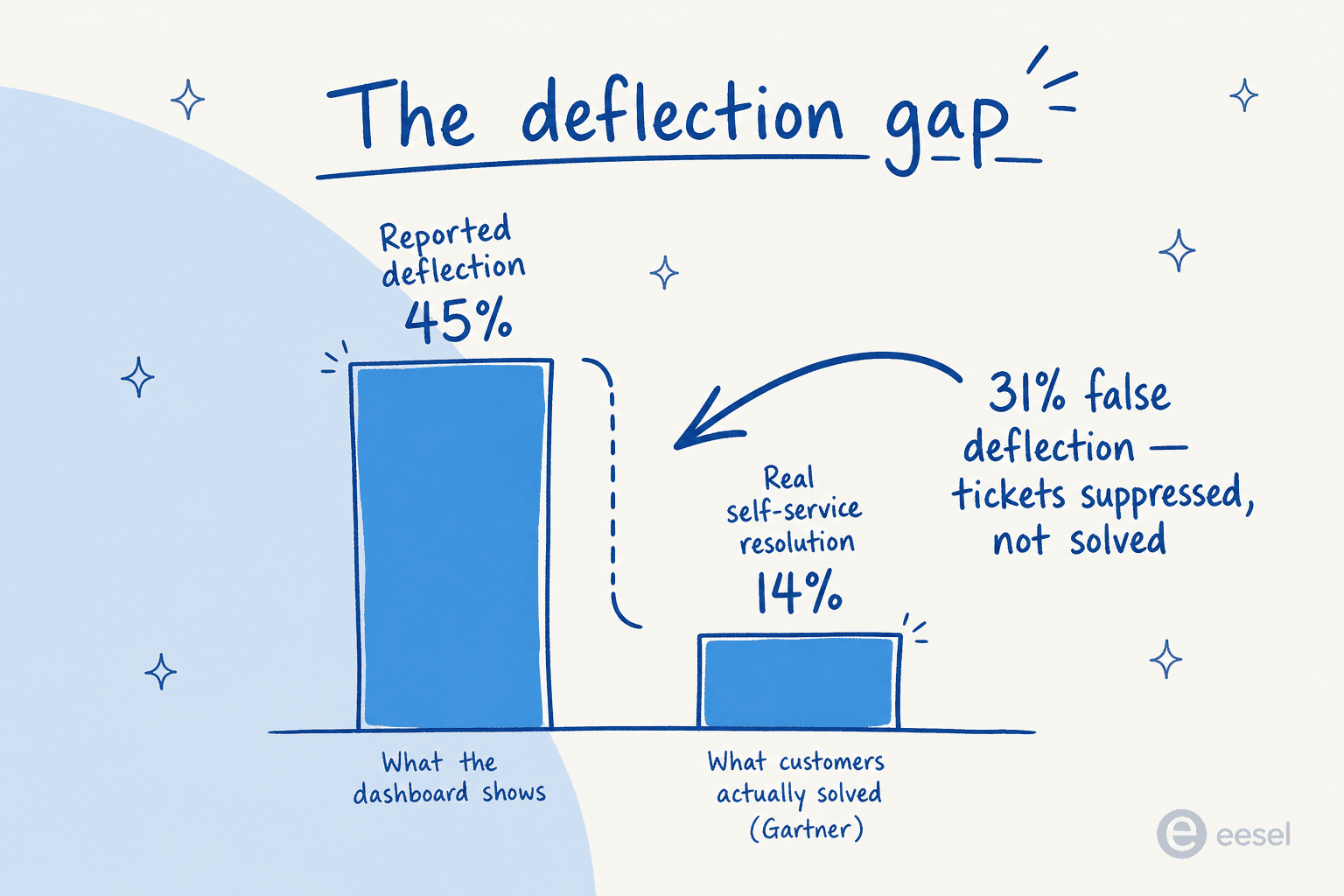
Gartner encuentra que la IA desvía más del 45% de las consultas de los clientes, pero solo alrededor del 14% llega a una resolución de autoservicio completa. Los ~31 puntos porcentuales restantes son lo que el sector denomina deflexión falsa: el ticket nunca se abrió en tu plataforma, pero el cliente no obtuvo ayuda. Fue a otro lado: teléfono, correo electrónico, redes sociales, o un competidor.
Un estudio de 100.050 interacciones de soporte citado por Corebee.ai identificó el mecanismo del fallo: los bots de IA tienen un 37% más de probabilidades de alejar los problemas de la resolución que los humanos cuando se configuran para optimizar la tasa de deflexión como KPI. El trabajo del bot se convierte en "cerrar la conversación", no en "resolver el problema".
Puedes ver la brecha con más claridad cuando los equipos aplican la fórmula ajustada:
Tasa de deflexión real = (resoluciones de autoservicio − re-contactos en 48h) ÷ total de intentos de búsqueda de ayuda
La mayoría de los equipos que se molestan en calcular esto descubren que su tasa de deflexión real es un 15-25% más baja que la reportada. Un panel que muestra el 80% de deflexión puede significar una resolución real del 55-65%. Un panel que muestra el 50% puede significar el 35-40%. Conocer tu número real es el requisito previo para moverlo de verdad.
La conclusión: no conviertas la tasa de deflexión en un KPI aislado. Rastréala junto con el CSAT en conversaciones resueltas por el bot, la tasa de re-contacto en 48 horas y la tasa de cambio de canal. Los equipos que obtienen resultados honestos hacen esto; los que obtienen métricas suprimidas no lo hacen.
Lo que la reducción de tickets con IA realmente hace internamente
Una vez que sabes qué medir, la siguiente pregunta es qué está haciendo realmente la IA cuando reduce un ticket. La mayoría de los artículos lo simplifican con "la IA usa NLP y machine learning". Así es como luce la arquitectura en 2026:
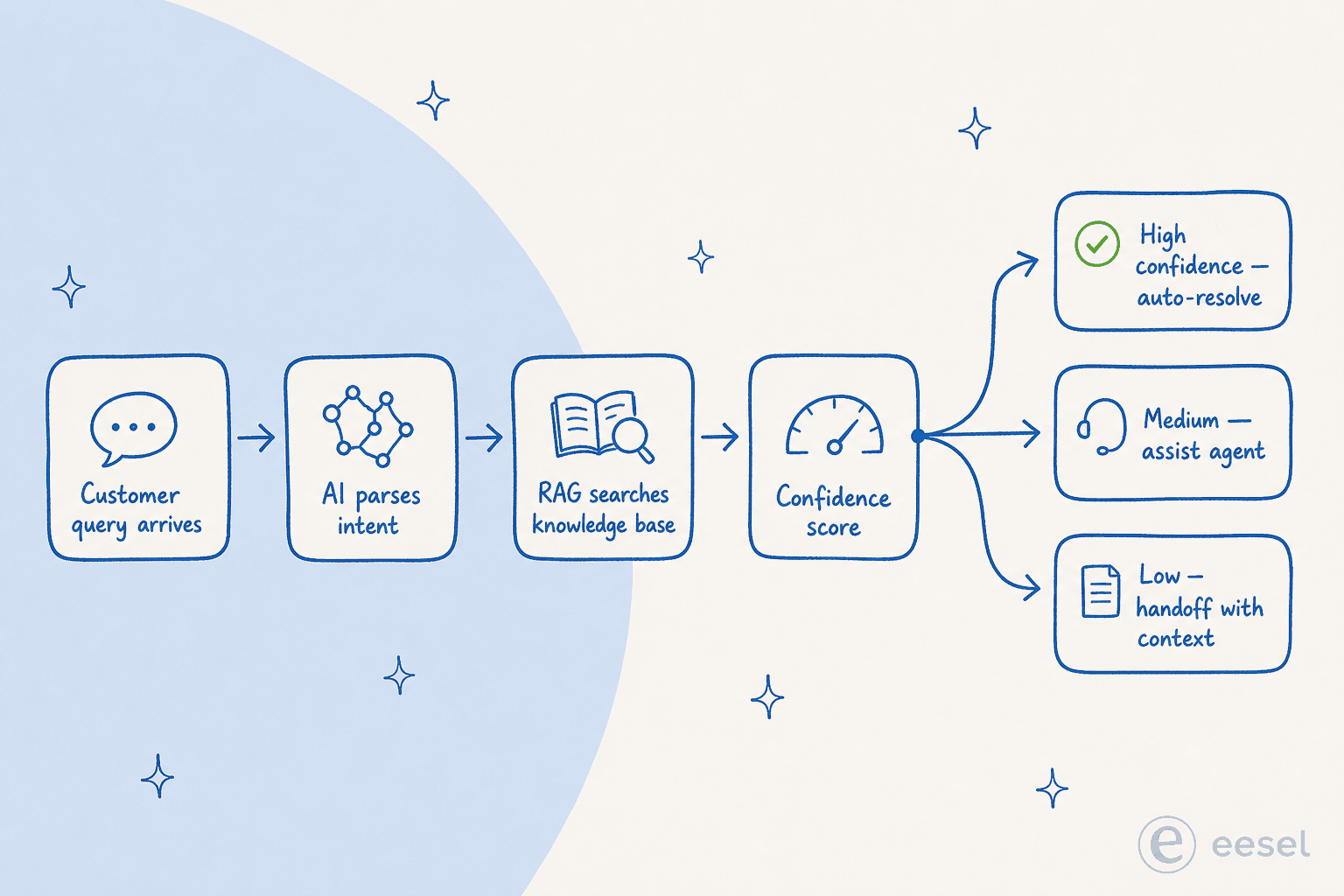
- Análisis de intención. Un LLM (de clase GPT-4, Claude, Gemini) lee la consulta entrante y extrae intención, urgencia, sentimiento y las entidades relevantes (número de pedido, nivel de cuenta, código de error). Esta es la capa que reemplazó a los chatbots de coincidencia de palabras clave de 2018, y es lo que permite al sistema manejar paráfrasis y ambigüedad: "mi cosa no funciona" se enruta igual que "no puedo iniciar sesión".
- Recuperación de base de conocimiento (RAG). El sistema incrusta la consulta y tu base de conocimiento en el mismo espacio vectorial, encuentra artículos semánticamente coincidentes y resoluciones anteriores, y sintetiza una respuesta fundamentada en el contenido recuperado en lugar de generarla desde cero. ClarityArc lo dice claramente: "un agente de deflexión de tickets es un sistema de recuperación de conocimiento con una interfaz conversacional; su techo de calidad está determinado por la calidad de la base de conocimiento de la que recupera."
- Puntuación de confianza y enrutamiento. El sistema asigna una puntuación de confianza y decide qué hacer: alta confianza → responder y cerrar; media → presentar la respuesta con una ruta prominente hacia un humano; baja → escalar inmediatamente con contexto completo.
- Acciones específicas por cuenta. El gran avance en la IA agéntica: en lugar de solo recuperar un artículo, el agente lee el CRM/facturación/sistema de pedidos y toma la acción. Busca un pedido, emite un reembolso, actualiza una suscripción. La profundidad de integración añade un 20-30% a la calidad de deflexión por encima de la calidad de la KB, porque la mayoría de las preguntas reales necesitan contexto de cuenta, no contenido genérico.
- Escalada con contexto. Cuando la IA no puede manejarlo, no devuelve al cliente al principio. Le entrega al agente humano un resumen completo de la conversación, el estado relevante de la cuenta y la razón por la que escaló. Esta es la diferencia entre "la IA lo intentó y falló" y "la IA hizo el triaje para que el humano pueda resolver en 90 segundos."
Dos advertencias que vale la pena mencionar, porque hacen colapsar todo el sistema cuando se ignoran:
- La confianza del LLM no es confianza factual. Un LLM puede tener un 95% de confianza sobre una respuesta alucinada: las puntuaciones de confianza miden la probabilidad de tokens, no la verdad. Nunca uses la confianza bruta como única barrera. Combínala con señales de cobertura de KB y reglas de alcance de tema (post-mortem de DEV Community sobre HITL).
- La KB es tu techo, no el modelo. Cambiar GPT-4 por Claude no arreglará una tasa de deflexión atascada en el 35%. Actualizar tu base de conocimiento y ajustar el alcance sí lo hará.
Lo que se reduce bien y lo que no
El otro número que la mayoría de las coberturas pasa por alto: la reducción de tickets con IA no es uniforme en todos los tipos de consulta. El mismo agente, en la misma KB, con el mismo modelo, te dará números completamente diferentes según lo que le apuntes.
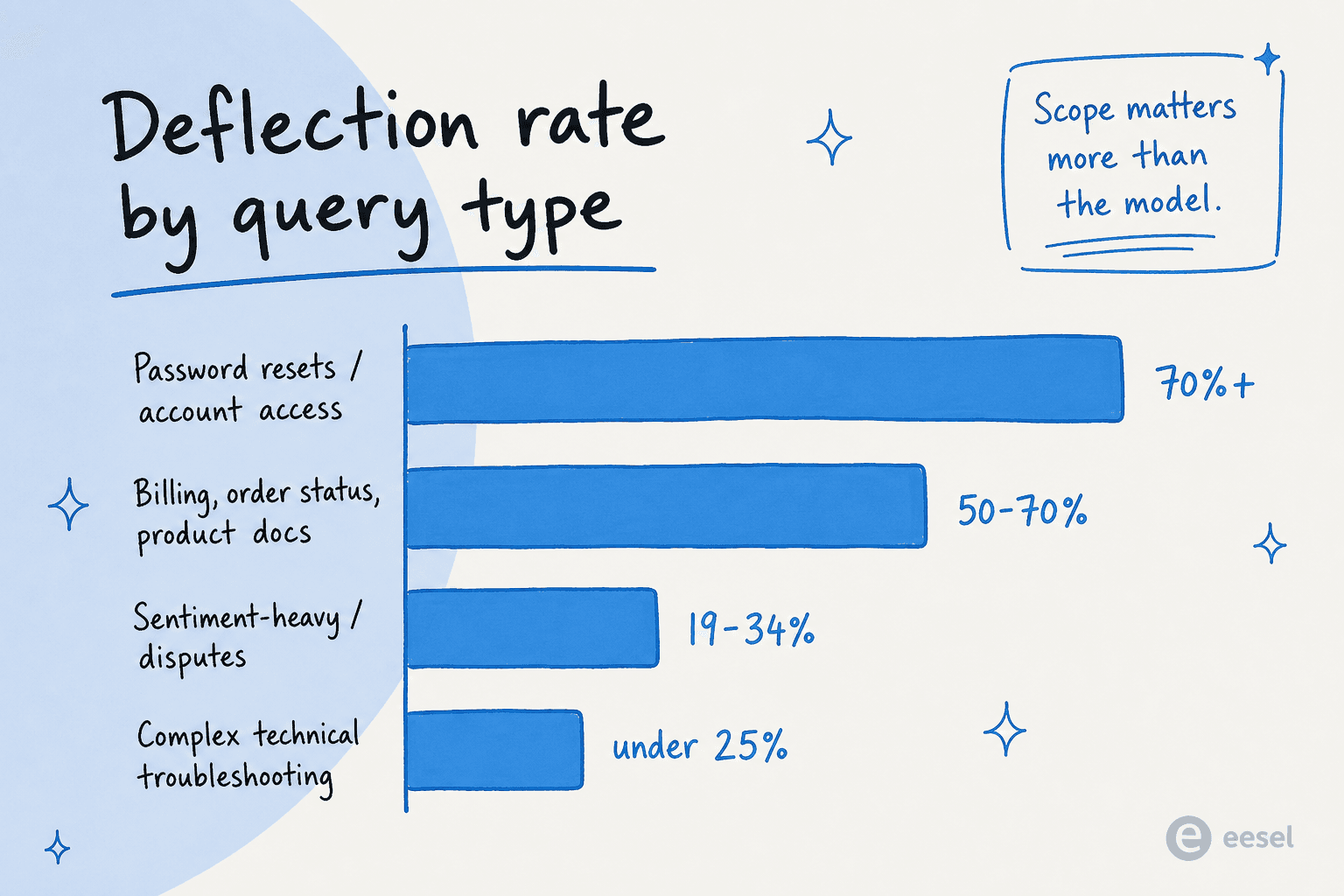
Según los benchmarks 2026 de ClarityArc y la guía de deflexión de Pylon:
| Tipo de consulta | Tasa de deflexión típica | Por qué |
|---|---|---|
| Restablecimiento de contraseña / acceso a cuenta | 70%+ | Alto volumen, determinista, respuesta desde sistema de registro |
| Estado de pedido / WISMO | 50-70% | Búsqueda en backend una vez que las integraciones están conectadas |
| Reembolsos y devoluciones (política estándar) | 50-70% | KB clara + acción agéntica disponible |
| Producto estándar / documentación de uso | 50-70% | Ligado a la KB, bien documentado |
| Resolución técnica compleja | Menos del 25% | Cada caso es nuevo; requiere razonamiento humano |
| Con carga emocional / estilo disputa | 19-34% | Contexto emocional, no solo informacional |
| Regulado / sensible a cumplimiento | Menos del 20% | El riesgo y la revisión superan a la velocidad |
Por eso la decisión de mayor apalancamiento en cualquier proyecto de reducción de tickets con IA es el alcance, no la selección del proveedor. Elige los dos o tres tipos de consulta que estén en la mitad superior de esa tabla, consigue que lleguen al 60-70% de deflexión real, y solo entonces amplía. Eligir "todo" el primer día hace que el promedio caiga tan fuerte que el proyecto se cancela.
Nuestra opinión: si tu equipo está empezando, haz primero los restablecimientos de contraseña y el WISMO. Son de alto volumen, deterministas, y reducen la cola de manera notable para que el resto del equipo apoye el proyecto. Intentar desviar tickets de reclamaciones el primer día es como los proyectos de IA pierden credibilidad interna.
Números reales de equipos reales (y lo que tenían en común)
El resumen destacado de casos de estudio es real, pero la conclusión no es "también nosotros deberíamos conseguir el 86%." Es "mira cuán estrechamente delimitado estaba cada uno de estos."
- Grammarly pasó de 60% a 87% de deflexión en 10 días con la plataforma agéntica de Forethought, con el CSAT mejorando a 4,2/5. Agregar integraciones de sistema contribuyó otro 5-10%.
- Bilt Rewards gestiona el 70% de 60.000 tickets mensuales con agentes de IA.
- Duolingo opera por encima del 80% de deflexión con Decagon.
- La IA de Klarna gestiona dos tercios de todo el servicio al cliente, equivalente a 700 agentes a tiempo completo.
- Los clientes minoristas de Freshworks ven que Freddy AI resuelve el 53% de todas las consultas entrantes.
- Los clientes de eCommerce de Gorgias alcanzan rutinariamente el 60% de deflexión incluso con un tiempo mínimo de entrenamiento.
El hilo común no es la plataforma. Es el modelo operativo: alcance ajustado el primer día, integraciones profundas con CRM/pedidos/facturación, un umbral de confianza calibrado, una ruta de escalada limpia y el hábito de usar cada escalada como una actualización de la base de conocimiento. Los proveedores varían; la disciplina no.
Los propios benchmarks de clientes de Eesel reflejan el mismo patrón. Una empresa de análisis de conductores de la economía gig en Zendesk Business resolvió el 73% de las solicitudes de nivel 1 en su primer mes tras una prueba de 7 días. Un helpdesk de IT interno en Jira Service Management está al 15% de deflexión con un objetivo del 55% a medida que su KB y el alcance del agente se amplían. El número que se mueve no es el modelo: son los insumos.
Las cinco cosas que los equipos que realmente mueven el número hacen bien
En el dossier de más de 50 despliegues en producción analizados por Corebee.ai, la guía de deflexión de Pylon y el manual de producción de ClarityArc, las mismas cinco variables aparecen en cada equipo que llega a una reducción honesta del 60%+.
1. Calidad de la base de conocimiento primero, IA después
Este es el palanca de mayor impacto en todo el sistema. La documentación bien estructurada aumenta la resolución genuina en un 15-25% antes de que toques ninguna configuración del modelo. La razón por la que la mayoría de los pilotos se estancan: los equipos apuntan la IA a la KB que tienen, no a la KB que necesitan. La KB que tienen fue escrita para agentes humanos que ya conocen el producto, no para una IA que tiene que responder en frío.
La solución es mecánica: elige las dos o tres intenciones que vas a delimitar, audita los artículos de KB correspondientes, reescríbelos para preguntas en lenguaje natural en lugar de jerga interna, y añade tickets resueltos recientes a la KB como ejemplos trabajados. Luego despliega.
Si estás empezando desde una KB escasa, nuestras guías para construir un chatbot de base de conocimiento con IA y elegir las herramientas de base de conocimiento con IA correctas cubren la infraestructura de datos.
2. Delimita con precisión. Y luego aún más estrecho.
El modo de fallo más consistente en el análisis de debates es los equipos que intentan cubrir "todo" el primer día. Comienza con 2-3 tipos de consulta donde la KB esté genuinamente completa. Cúbrelos bien: mide honestamente, corrige las brechas, supera el 60% de deflexión real, y solo entonces amplía.
Lo que se excluye del alcance del primer día:
- Todo lo que tenga carga emocional (disputas de reembolso, reclamaciones, escaladas de cuentas nombradas)
- Todo lo que esté regulado o sea sensible al cumplimiento
- Todo lo que requiera leer contexto fuera de la KB (bugs de ingeniería, estado del sistema durante incidentes)
- Tickets de tus cuentas de nivel superior: los VIPs van a humanos en el primer mensaje, sin excepciones
3. Integra suficientemente en profundidad para que la IA actúe, no solo describa
Si la IA solo puede recuperar artículos de KB, se estancará alrededor del 35-40% de deflexión. Los despliegues del 60-90% tienen integración con CRM, facturación y sistemas de pedidos que permiten al agente tomar la acción real: buscar el pedido, procesar la devolución, cambiar el plan.
Los datos de ClarityArc muestran que la profundidad de integración contribuye un 20-30% por encima de la deflexión solo con KB. La cita del practicante más contundente sobre esto:
"El verdadero avance es cuando la IA puede realmente resolver el problema de extremo a extremo en tus sistemas, no solo sugerir qué decir."
Esto también explica por qué los chatbots basados en reglas añadidos como complementos tienden a fallar. Recuperan, pero no actúan. Los clientes hacen una pregunta que necesita datos de la cuenta, el bot falla, los números de deflexión suben mientras el CSAT baja. Las plataformas nativas de IA, las que leen tu helpdesk, tu CRM y tu sistema de pedidos en un solo entorno de ejecución, cierran ese ciclo.
4. Calibra el enrutamiento por confianza y deja que la IA diga "no sé"
Esta fue la objeción decisiva en nuestro propio dossier de llamadas con clientes:
"La IA nunca podrá responder el 100% de las preguntas, pero si lo intenta y simplemente responde 'lo siento, no sé esto', no puedo ir a revisar mis 7.000 tickets para ver si la IA realmente dio una buena respuesta. Necesito una IA que solo maneje los tickets que tiene confianza en manejar y que todos los demás los deje solos."
Un responsable de CX en una marca de suplementos DTC en Gorgias + Shopify (~7K tickets/mes), dossier de clientes de eesel (anonimizado con consentimiento)
Esa es toda la tesis sobre el enrutamiento por confianza en una sola cita. Una IA que responde todo es peor que una IA que responde la mitad y escala claramente el resto. Ajusta tus umbrales de alto/medio/bajo a través de pruebas con tráfico real, no por intuición, y recalíbralos cada trimestre a medida que la KB evoluciona.
Si quieres una lectura más profunda sobre esto, nuestro análisis del umbral de confianza de intención del agente de IA de Zendesk explica cómo un helpdesk real lo implementa.
5. Trata cada escalada como una señal de aprendizaje
Cada vez que la IA escala, te está diciendo una de tres cosas: la KB tiene una brecha, el alcance era incorrecto para esta intención, o el umbral de confianza necesita ajuste. Los equipos que logran las tasas de deflexión más altas hacen una revisión semanal de 20-30 conversaciones escaladas y convierten los patrones en actualizaciones de KB, cambios de alcance o reglas de enrutamiento.
Lo contrario, las escaladas acumulándose sin leer, el bot respondiendo incorrectamente en silencio, nadie auditando, es cómo una tasa de deflexión del 65% se convierte silenciosamente en una tasa de supresión del 65% y un pico de churn seis meses después.
Cómo falla la reducción de tickets con IA (los modos de fallo que hay que diseñar para evitar)
Los mismos patrones reaparecen en los más de 50 hilos de equipos de soporte que Corebee analizó, los post-mortems de DEV Community y las conversaciones de profesionales en el análisis de SaaStr de junio de 2025. Si estás implementando esto, diseña para evitar estos fallos desde el primer día:
- La tasa de deflexión se convierte en un KPI. Una vez que es un número por el que se paga a la gente, el sistema se diseña para alcanzar el número, incluso a costa de la experiencia del cliente. Rastréalo como señal junto con el CSAT y la tasa de re-contacto, no como objetivo.
- Los VIPs llegan al bot. El modo de fallo más costoso es que tus cuentas de nivel superior se encuentren con un muro de IA mientras un cliente de $40/mes recibe un humano. Enruta los VIPs directamente a humanos en el primer mensaje. Siempre.
- Respuestas incorrectas con confianza. El bot responde una consulta que debería haber escalado, el cliente confía en él, y una pregunta simple se convierte en una crisis de confianza. La solución son los controles de alcance de tema (el bot tiene permiso para responder sobre X, no tiene permiso sobre Y), no solo un umbral de confianza.
- Bucles del bot sin escalada. Un botón de "hablar con un humano" enterrado a cuatro clics de profundidad, una ruta de escalada que vuelve a hacer las mismas preguntas que el bot ya hizo, o ninguna ruta humana en absoluto. Los clientes abandonan silenciosamente cuando esta es la experiencia.
- Aumento de re-contactos a través de otros canales. Tu tasa de deflexión en la plataforma sube, tu cola de teléfono sube aún más. Siempre verifica los volúmenes de canal antes de celebrar un logro de deflexión.
Un post-mortem de DEV Community de un equipo que procesa más de 12.000 tareas de agente al día hace el argumento con claridad. Antes de añadir controles de humano en el bucle en tareas de alto riesgo, su tasa de error crítico estaba al 23,4%. El agente cerró automáticamente 34 tickets que deberían haber ido a ingeniería, incluidos tres incidentes activos de producción. Un cliente perdió seis horas de datos.
"Ese incidente nos costó un contrato anual de $280K y un post-mortem muy incómodo."
Después de añadir HITL en las tareas correctas (no una revisión exhaustiva de todo), la tasa de error crítico bajó al 5,1%, una reducción del 78%, y la carga de revisión humana cayó un 62%. La lección que el equipo resumió: "La parte difícil no es construir el agente, es decidir cuándo confiar en él."
Un plan de implementación que no destruye la confianza
Reuniendo todo esto en algo que puedes hacer en los próximos 90 días:
Semanas 1-2 - Diagnóstico. Descarga tus últimos 1.000 tickets. Etiquétalos por intención. Encuentra las tres principales intenciones por volumen y por completitud de la KB. No elijas solo por volumen: una intención de alto volumen con una KB escasa es un proyecto, no una victoria rápida.
Semanas 3-4 - Preparar la KB. Para cada intención preseleccionada, reescribe o actualiza los artículos de KB. Añade 5-10 ejemplos trabajados de tickets reales resueltos. Elimina la jerga interna. Prueba pidiendo a un agente junior que responda en frío desde la KB; si no puede, tu IA tampoco.
Semanas 5-6 - Conectar integraciones. Conecta el helpdesk, el CRM y el sistema de pedidos/facturación. El agente necesita acceso de lectura al estado de la cuenta y acceso de escritura en las acciones que realmente quieres que tome.
Semanas 7-8 - Piloto en modo copiloto. Ejecuta la IA como copiloto: redactando respuestas, nunca enviándolas de forma autónoma. Mide con qué frecuencia los agentes humanos envían el borrador sin cambios, lo editan ligeramente o reescriben desde cero. Si la tasa de "enviar sin cambios" llega al 60%+ en tus intenciones delimitadas, estás listo para el modo autónomo.
Semanas 9-12 - Graduarse a autónomo en la intención más segura primero. Comienza con una intención. Umbral de confianza alto. Valores predeterminados de escalada agresivos. Auditorías semanales de conversaciones. Baja el umbral solo cuando los datos lo respalden.
Esta es la disciplina operativa, no la tecnología, la que separa a los equipos que reportan una reducción honesta del 60%+ de los equipos que tienen una tasa de deflexión del 35% disfrazada para parecer el 80%. Para un análisis más completo, consulta nuestra guía práctica para reducir tickets de soporte con IA.
Prueba eesel
Si estás implementando la reducción de tickets con IA y quieres una plataforma diseñada para el plan anterior en lugar de en contra de él, con enrutamiento basado en confianza, integraciones profundas con Zendesk, Freshdesk, Gorgias y más de 100 otros, control de alcance por tipo de ticket y precios que no te penalizan por hacer pruebas, eso es exactamente para lo que se construyó eesel.
Los agentes de Eesel viven dentro de tu helpdesk existente (sin reemplazar la plataforma), aprenden de tu historial de tickets y KB existentes desde el primer día, y te permiten instruirlos en lenguaje natural: "gestiona la cola de WISMO, escala cualquier cosa con más de $500 en reembolsos, deja solos los tickets de enojo." El precio es por tarea, no por puesto o por resolución, así que solo pagas por los tickets que la IA realmente toca.
Los clientes reales han avanzado rápido. Una empresa de análisis de conductores de la economía gig en Zendesk Business resolvió el 73% de las solicitudes de nivel 1 en su primer mes tras una prueba de 7 días. Un equipo de soporte del Reino Unido impulsó 56 tareas resueltas con solo 9 macros sincronizadas. El nivel gratuito ($50 de crédito, sin tarjeta de crédito requerida) es suficiente para hacer un piloto real con tus propios datos.
Prueba eesel gratis → - o reserva una demo de 30 minutos si prefieres que revisemos tu stack contigo.
Preguntas frecuentes
¿Qué es la reducción de tickets con IA?
¿Cuánto puede desviar de forma realista la reducción de tickets con IA?
¿Cuál es la diferencia entre reducción de tickets con IA y deflexión de tickets con IA?
¿Cuánto tiempo tarda en amortizarse la reducción de tickets con IA?
¿Qué tickets de soporte son más fáciles de reducir con IA?
¿Cómo mido la reducción de tickets con IA de forma honesta?
¿La reducción de tickets con IA reemplazará a mis agentes de soporte?
¿Cuál es la mejor herramienta de reducción de tickets con IA para Zendesk, Freshdesk o Gorgias?

Article by
Riellvriany Indriawan
Riell is a designer and writer at eesel AI with about two years of experience researching CX platforms, AI chatbots, and helpdesk software. She combines her design background with a sharp eye for how these tools actually look and feel in practice — making her comparisons unusually visual and user-focused.







