So what exactly is Cursor Origin?
Origin is Cursor's own Git forge: a from-scratch platform to host, review, and collaborate on code, going head-to-head with GitHub. Cursor's own one-liner from the launch post is about as plain as it gets:
We're launching code storage and git hosting. Origin gives teams and agents a place to host, review, and collaborate on code. Available this fall. Join the waitlist.
The tagline on the product page is "a Git forge for the agentic era," with one line of supporting copy: "Code is moving faster than any infrastructure was built to handle. Origin was designed for this moment." That's basically the entire public site today, a tagline and a waitlist button.
It was demoed on stage by Tomas Reimers, a co-founder of Graphite, the code-review startup Cursor acquired. That detail matters more than it sounds, and I'll come back to it. If you're new to Cursor itself, it's the AI-native code editor built on a VS Code fork, and Origin is its move from "where you write code" into "where your code lives."
Why build a whole new Git host?
This is the question worth sitting with, because "Cursor cloned GitHub" is the lazy read and it misses the point.
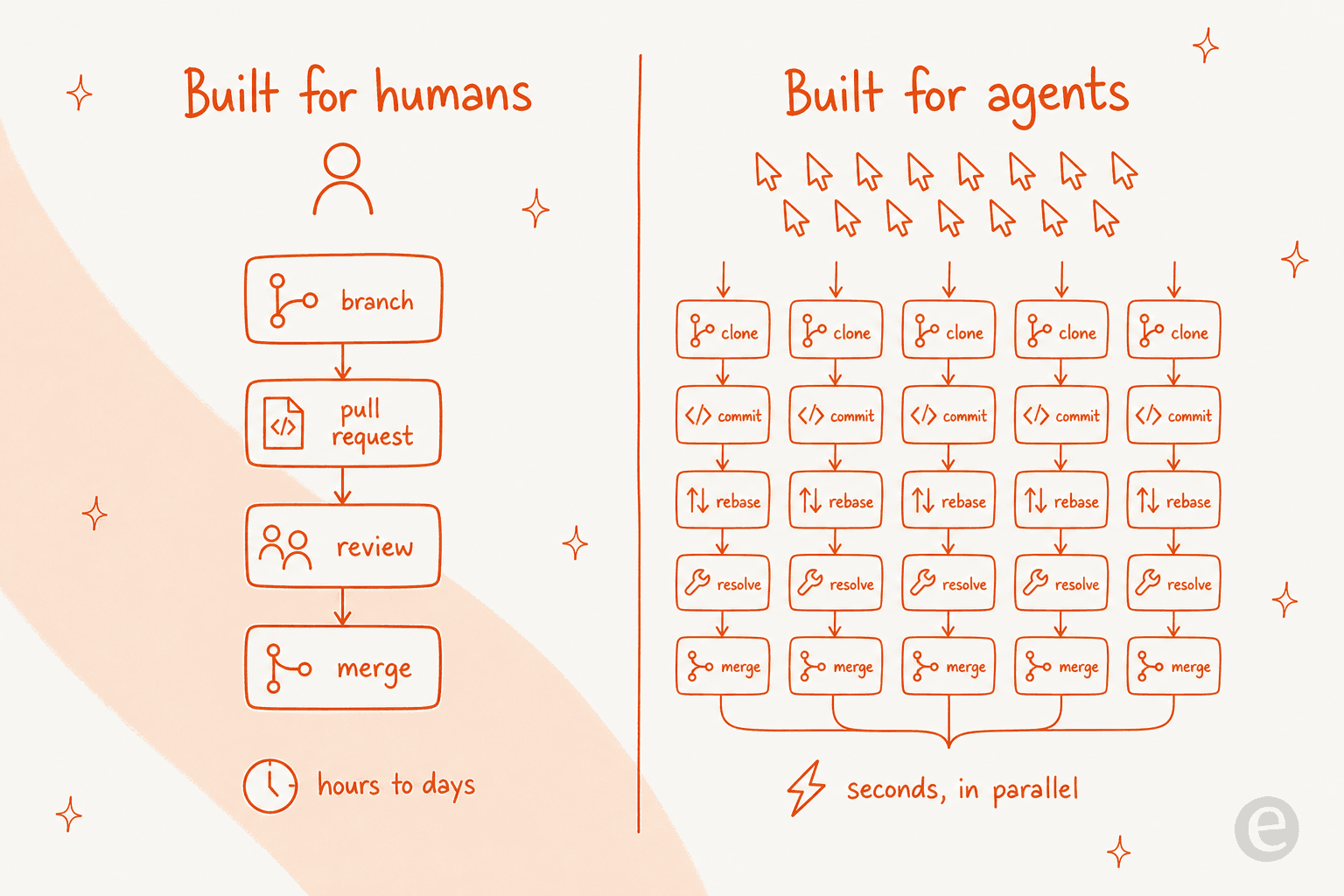
Git, and GitHub on top of it, was designed around human cadence. A developer opens a branch, writes code for a few hours, opens a pull request, waits for a teammate to review it, then merges. The whole rhythm is measured in hours and days, and that's fine, because a person can only type so fast.
AI agents break that assumption. As the AlphaSignal writeup put it, "dozens or hundreds of them can be cloning, branching, committing, and rebasing the same codebase simultaneously, in seconds," which is "a fundamentally different load profile than anything GitHub was architected to handle." Once you're running fleets of agentic coding tools, the bottleneck stops being how fast you can write code and becomes how fast you can host, review, and safely merge what the machines produce.
So Origin's bet is that the next piece of infrastructure to rebuild is the forge itself. Analyst Mark K framed it as "Cursor's attempt at an agent-native GitHub competitor," built around "coordinating, reviewing, and safely merging agent-generated code at massive scale." It's the same logic behind a lot of AI agent infrastructure right now: the tools we built for people start creaking the moment software, not a person, is the main user.
What's actually under the hood
Cursor hasn't shipped real docs yet, so the feature picture comes from the launch demo and the people who were in the room. Here's what's been shown or stated:
- Git compatibility, so it works with standard git tooling rather than forcing a new workflow.
- API and MCP extensibility, described by swyx as "extensible with api and mcp," so agents can drive the forge programmatically.
- Built-in merge-conflict resolution handled by agents, plus agentic resolution of CI/build failures ("built in merge conflicts and co failure agent resolution").
- A hybrid NVMe + S3 storage architecture that, per the Digg coverage, "supports infinite replicas."
- Stacked pull request heritage carried over from Graphite, for managing lots of dependent changes in parallel.
The numbers from the on-stage demo are the headline grabbers. Nick Dobos pulled from the slides that "cursor origin supports 22.6 commits a second (in a single repo)," and the demo reportedly pushed hundreds of thousands of clones per hour, the kind of load AlphaSignal noted "would stress any existing Git hosting infrastructure."

One quick honesty note: a widely-shared "296,000+ clones" figure floated around the coverage, but the unit and timeframe got truncated in the original source headline, so I'd treat it as a scale claim rather than a precise benchmark until Cursor publishes its own numbers.
Where Origin really clicks is as the last piece of a stack Cursor has been quietly assembling. Mark K described the full picture as an "AI software factory": write code in Cursor, run agents in parallel, review with Graphite-style stacked workflows, then host and merge on Origin. The Graphite acquisition is what makes that review-and-merge layer credible, and it's why I read Origin less as a GitHub clone and more as Cursor closing the loop on its own agentic coding workflow.
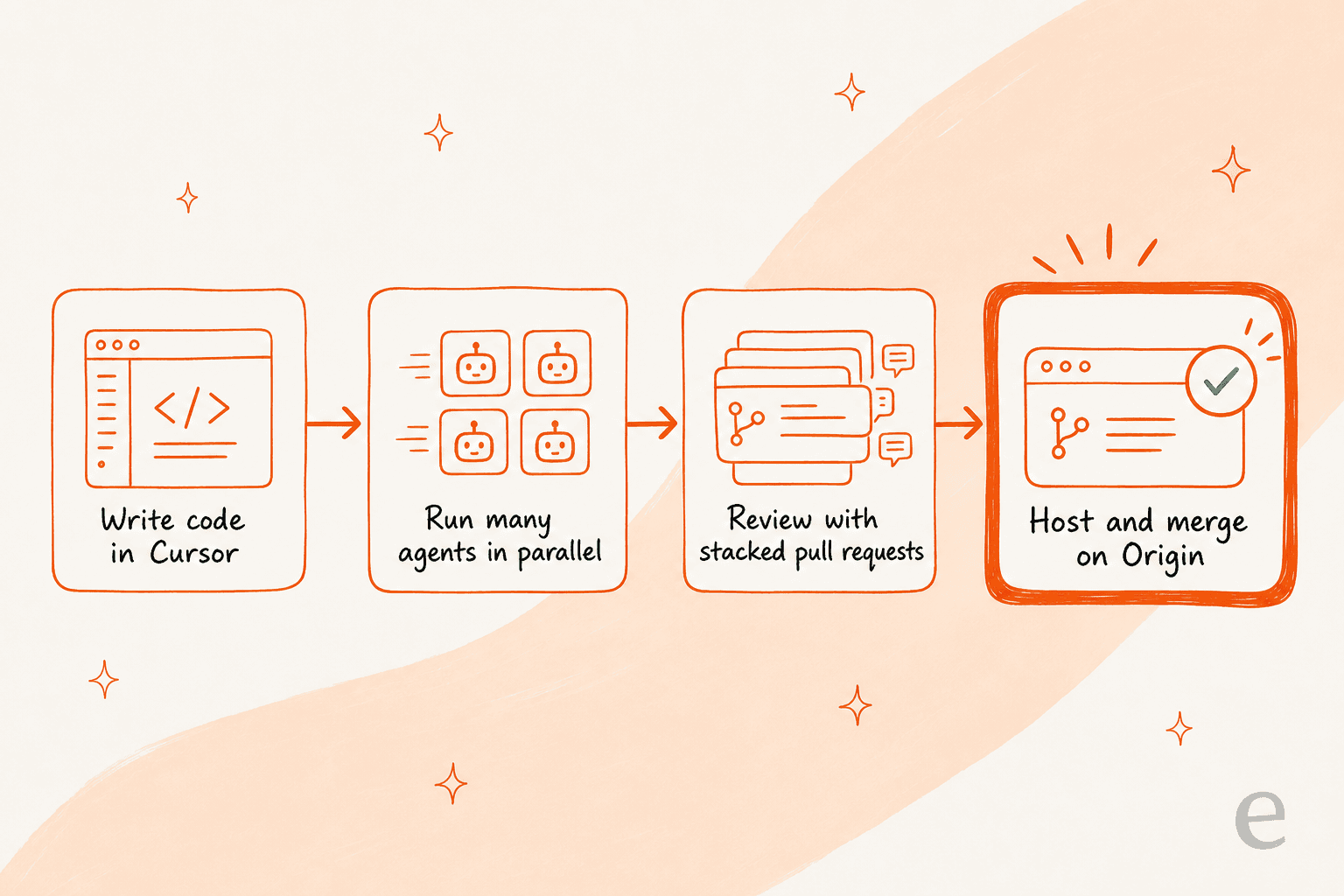
The catch: a thin launch and a real trust problem
Here's where I'd pump the brakes. The launch was loud, the official post drew over 3 million views, but the actual product surface is a tagline and a sign-up form. Hacker News didn't let that slide: "I've never seen a waitlist for such little information," one commenter wrote. The waitlist itself reportedly buckled under the load at launch, which is either a bad sign or a fitting one for a product about throughput.
The deeper objection is the one I find most interesting, because it's the same one I hear constantly in support. If agents are committing 22.6 times a second, who is actually reviewing all of it? From the HN thread:
How is this different from Github... how this deals with the AI code generation at machine speed? Does human still in the loop of reviewing the AI slop?
That's the whole ballgame. Speeding up how fast machines can write and merge code does nothing for you if nobody can vouch for whether the code is correct. "Agent resolves the merge conflict automatically" sounds great right up until the agent resolves it wrong and ships it at machine speed.
And then there's trust in Cursor itself. A vocal slice of the r/cursor reaction was less about features and more about handing over a codebase:
Yo I will use Cursor to build my own damn Git server and host it in AWS before I give my code to a repository hosted by X
That comment (the "X" reference is the commenter's own read on who's behind Cursor, per the thread, not something Cursor has confirmed) rhymes with a broader worry that surfaced repeatedly: that the real product is your code as training data. Until Cursor publishes Origin's data-handling terms, I'd file the privacy question under "still open," not "fine."
What Origin really tells us about the agentic era
Step back from the Git plumbing and Origin is a tell. The infrastructure built for humans gets rebuilt the moment agents become the primary users. That's not a Cursor-specific insight, it's a pattern, and I say that because I've lived the support-side version of it for the last few years building eesel AI.
The helpdesk had the exact same problem before Git did. Tools like Zendesk and Freshdesk were designed around a human agent picking up one ticket at a time. Drop an AI agent into that world and the same questions Hacker News is asking about Origin show up word for word: who reviews the output, what happens when it's confidently wrong, and is my data being used to train someone's model. We've watched a confident-sounding bot quietly give wrong answers, which is why we now make every team simulate a rollout against their own historical tickets before a single live reply goes out, and why low-confidence answers get drafted for a human rather than sent. The throughput was never the hard part. The trust was.
It's also why the build-versus-buy instinct that Origin triggers ("I'll just host my own Git server in AWS") is worth a second look. We hear it from technical teams all the time on the support side, and the ones who actually try it usually arrive at the same place one of our customers did:
We could try to write our own LLM application but we didn't want to invest our time into that. We wanted something that we would not have to maintain.
That's an engineering lead at a Bitcoin-ATM company who chose buy over build, from a case study. Origin is Cursor making the opposite bet at the infrastructure layer, betting that hosting agent-scale code is a hard enough problem that teams will pay someone else to run it. Whether that's true depends entirely on whether they solve the review-and-trust problem, not the commits-per-second one.
So, should you care about Cursor Origin? If you run a serious engineering org leaning hard into Cursor's agents, get on the waitlist and watch closely, especially the data terms. If you're a support, IT, or ops team wondering whether this changes anything for you, it doesn't, at least not directly. You don't need a new Git host to put AI agents to work. You need agents that already plug into the tools you have, and the guardrails to trust them.
Try eesel AI
Cursor Origin is rebuilding code infrastructure for the agentic era. On the support side, eesel AI has been doing the equivalent for a while: an AI agent that lives inside the helpdesk, Slack, and docs you already use, learns from your past tickets on day one, and handles tier-1 work without you migrating anything.
The difference from a waitlist is that you can actually run it. Gridwise had eesel resolving 73% of their tier-1 requests in the first month, with results landing during a 7-day trial, and every rollout starts in a simulation against your real ticket history so you see coverage and accuracy before anything goes live. That's the part the agentic era actually turns on, not the commits per second.

If you want AI agents you can put to work today rather than wait for fall, Try eesel.
Frequently Asked Questions
What is Cursor Origin?
When will Cursor Origin be available?
Is Cursor Origin a GitHub competitor?
Is my code safe on Cursor Origin?
Do I need Cursor Origin to use AI agents at work?

Article by
Alicia Kirana Utomo
Kira is a writer at eesel AI with a Computer Science background and over a year of hands-on experience evaluating AI-powered customer service tools. She focuses on breaking down how helpdesk platforms and AI agents actually work so that support teams can make better buying decisions.