Por que a redução de tickets com IA voltou ao topo da agenda de CX
Os líderes de suporte não estão recebendo orçamentos maiores. Mas estão recebendo filas muito maiores. 53% dos profissionais de atendimento ao cliente em 2025 citaram "gerenciar o volume de tickets sem aumentar a equipe" como seu principal desafio, segundo o Relatório de Benchmark de Clientes da Freshworks 2025, e 90% dos agentes em serviços empresariais dizem que o trabalho repetitivo os impede de atender tickets de alto valor.
O argumento econômico se constrói sozinho ao colocar dois números lado a lado. Um ticket atendido por humanos custa em média US$ 8 a US$ 12 entre os setores, segundo a Forrester, chegando a US$ 25 a US$ 35 em SaaS B2B. Um ticket atendido por IA — mesmo quando a IA consulta dados da conta e executa uma ação — custa em média US$ 0,50 a US$ 1,05. Isso é uma diferença de custo de 12× a 24× por interação, que se multiplica a cada ticket que você reduz.
É por isso que se projeta que a IA em atendimento ao cliente crescerá de US$ 12,06 bilhões em 2024 para US$ 47,82 bilhões até 2030, um CAGR de 25,8%. E é por isso que US$ 80 bilhões em economia global projetada de suporte até 2027 segundo a Gartner é a linha que os compradores tiram print.
Mas — e esta é a parte que a maioria dos artigos ignora — a razão pela qual 47% das empresas reportam custos estagnados ou crescentes após implantar IA não é a IA. É que conectaram a IA aos mesmos fluxos de trabalho quebrados e chamaram o resultado de "deflexão." Esse é o modo de falha que a próxima seção desmonta.
"Deflexão" e "redução" — as palavras importam
Muita confusão nesse espaço vem de pessoas usando esses termos de forma intercambiável. Eles não significam a mesma coisa.
- Deflexão é uma tática: o cliente obtém uma resposta (ou um caminho de autoatendimento que realmente o responde) antes de um ticket ser aberto.
- Redução é o resultado: menos tickets precisando de tempo humano. A redução inclui deflexão, mas também inclui triagem de IA que fecha tickets em segundos, rascunhos que um humano pode enviar com um clique, e correções proativas de produto/UX que impedem que a pergunta seja feita.
O motivo pelo qual isso importa: uma equipe que otimiza apenas para a taxa de deflexão vai silenciosamente dificultar o acesso dos clientes a um humano, como a análise da Corebee de mais de 50 threads de equipes de suporte documentou. Uma equipe que otimiza para redução olha para o funil inteiro — incluindo os tickets que ainda deveriam chegar a um humano, só que mais rápido e mais barato.
"Eu não acredito em deflexão de tickets. Acredito em tornar tickets desnecessários. Há uma diferença. A deflexão redireciona o cliente. Tornar tickets desnecessários corrige o que causou a pergunta."
Líder de suporte citado na síntese de discussão da Corebee.ai
Tenha essa distinção em mente pelo resto deste artigo. Quando dizemos "redução de tickets com IA", queremos dizer o funil inteiro — não apenas o número de deflexão no painel.
O problema dos 14%: o que a maioria dos painéis de deflexão não está te dizendo
Aqui está o único número mais importante neste artigo inteiro, e é o que quase ninguém cita:
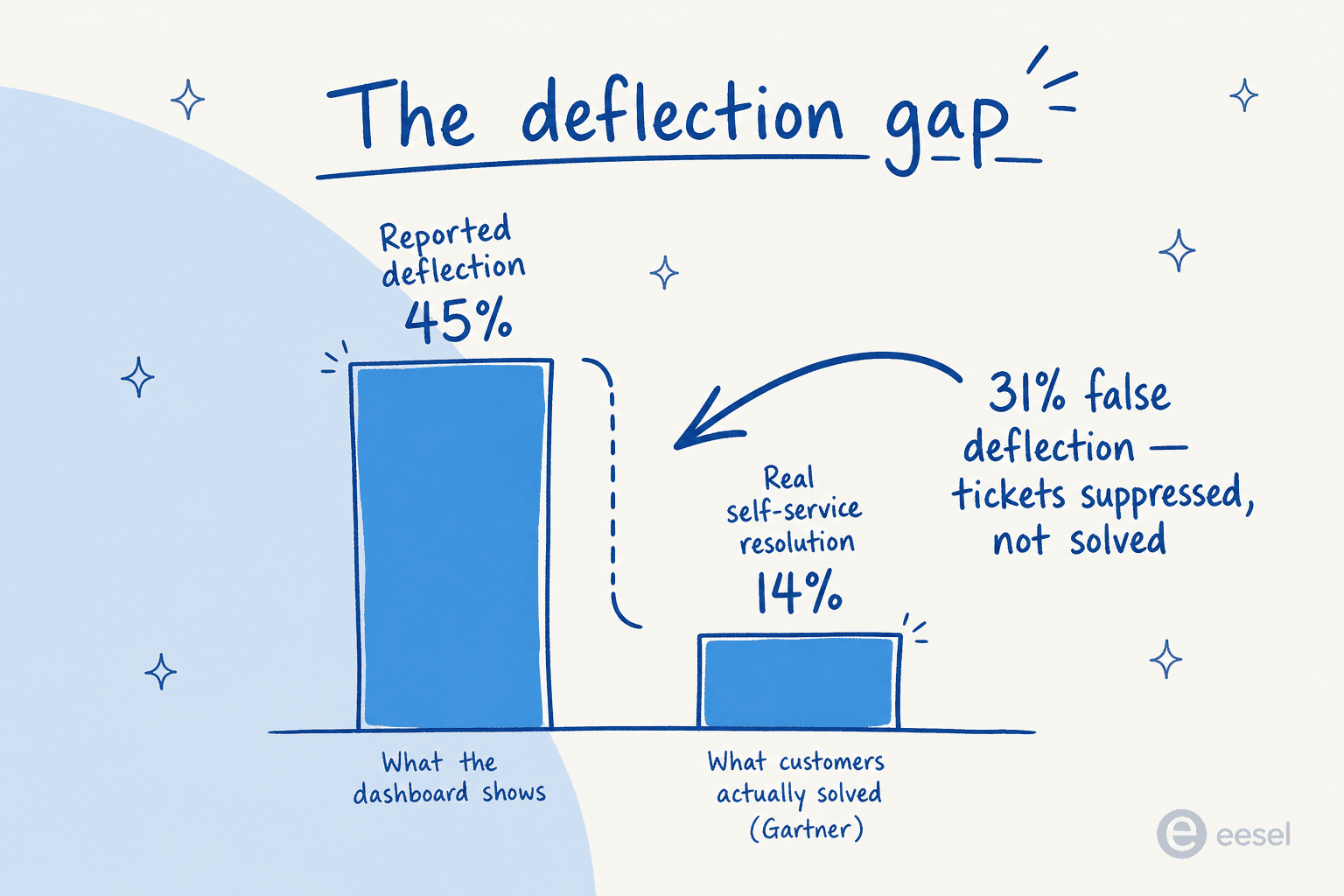
A Gartner constata que a IA desvia mais de 45% das consultas de clientes — mas apenas cerca de 14% chegam a uma resolução completa de autoatendimento. Os ~31 pontos percentuais restantes são o que o setor chama de deflexão falsa: o ticket nunca foi aberto na sua plataforma, mas o cliente não recebeu ajuda. Ele foi para outro lugar — telefone, e-mail, redes sociais, um concorrente.
Um estudo de 100.050 interações de suporte citado pela Corebee.ai descobriu o mecanismo de falha: bots de IA têm 37% mais probabilidade de afastar os problemas da resolução do que os humanos quando configurados para otimizar a taxa de deflexão como KPI. O objetivo do bot se torna "encerrar a conversa", não "resolver o problema."
Você pode ver a lacuna mais claramente quando as equipes executam a fórmula ajustada:
Taxa de deflexão real = (resoluções de autoatendimento − recontatos em 48h) ÷ total de tentativas de busca de ajuda
A maioria das equipes que se dá ao trabalho de calcular isso descobre que sua taxa de deflexão real é 15-25% menor do que a reportada. Um painel mostrando 80% de deflexão pode significar 55-65% de resolução real. Um painel mostrando 50% pode significar 35-40%. Saber seu número real é o pré-requisito para realmente movê-lo.
A conclusão: não faça da taxa de deflexão um KPI isolado. Acompanhe-a junto com o CSAT em conversas resolvidas pelo bot, taxa de recontato em 48 horas e taxa de mudança de canal. As equipes obtendo resultados honestos fazem isso; as que obtêm métricas suprimidas não fazem.
O que a redução de tickets com IA realmente faz por baixo dos panos
Uma vez que você sabe o que medir, a próxima pergunta é o que a IA realmente está fazendo quando reduz um ticket. A maioria dos artigos trata isso vagamente com "a IA usa PLN e aprendizado de máquina." Veja como a arquitetura parece em 2026:
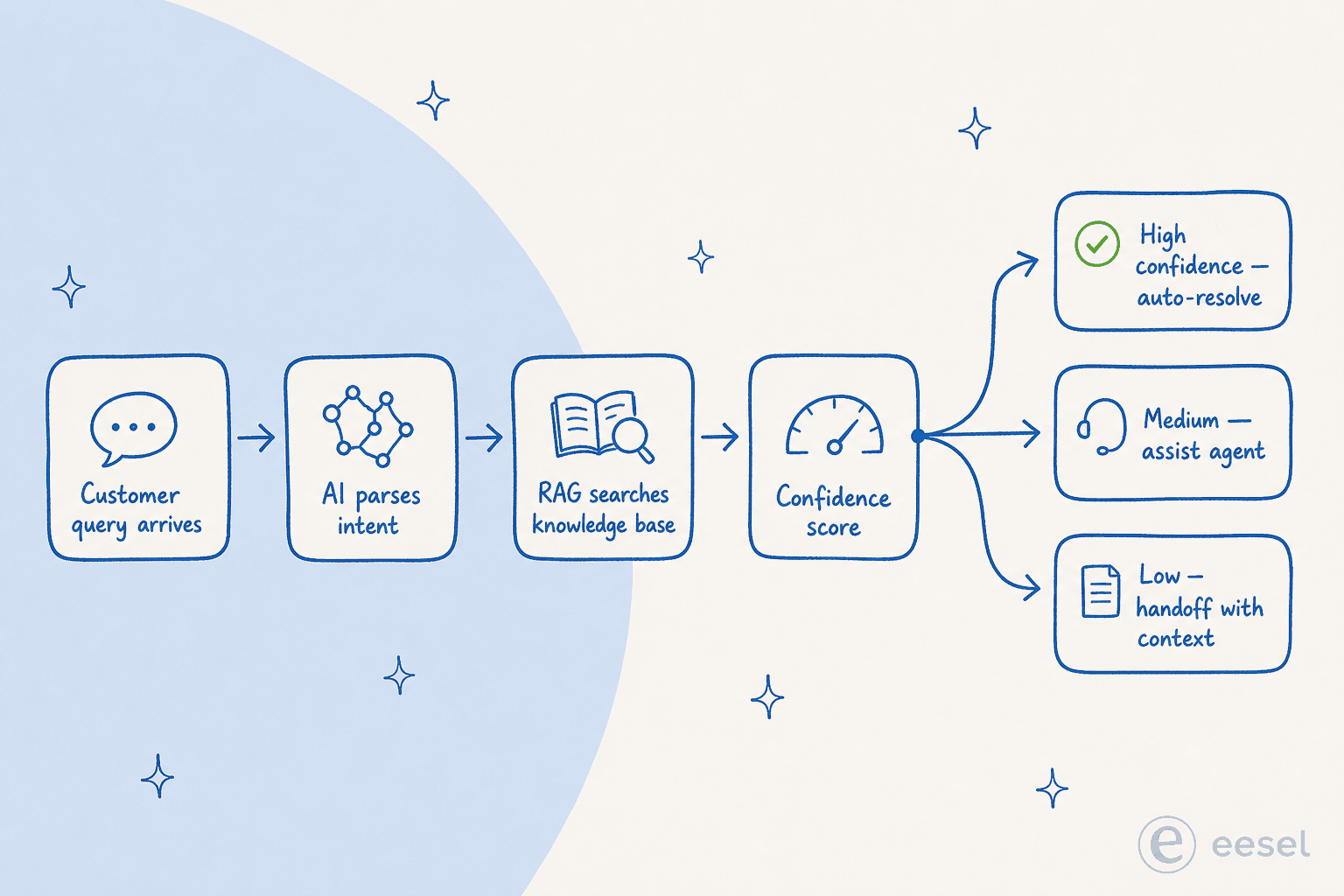
- Análise de intenção. Um LLM (classe GPT-4, Claude, Gemini) lê a consulta recebida e extrai intenção, urgência, sentimento e as entidades relevantes (número do pedido, nível da conta, código de erro). Esta é a camada que substituiu os chatbots de correspondência de palavras-chave de 2018, e é o que permite ao sistema lidar com paráfrases e ambiguidade — "minha coisa não está funcionando" é roteado da mesma forma que "não consigo fazer login."
- Recuperação de base de conhecimento (RAG). O sistema incorpora a consulta e sua base de conhecimento no mesmo espaço vetorial, encontra artigos semanticamente correspondentes e resoluções anteriores, e sintetiza uma resposta fundamentada no conteúdo recuperado em vez de gerar do zero. A ClarityArc coloca de forma direta: "um agente de deflexão de tickets é um sistema de recuperação de conhecimento com uma interface conversacional — seu teto de qualidade é determinado pela qualidade da base de conhecimento da qual ele recupera."
- Pontuação de confiança e roteamento. O sistema atribui uma pontuação de confiança e decide o que fazer: alta confiança → responder e fechar; média → apresentar a resposta com um caminho proeminente para um humano; baixa → escalonar imediatamente com contexto completo.
- Ações específicas de conta. O grande avanço da IA agêntica: em vez de apenas recuperar um artigo, o agente lê o CRM/sistema de faturamento/pedidos e executa a ação. Consultar um pedido, emitir um reembolso, atualizar uma assinatura. A profundidade de integração adiciona 20-30% à qualidade da deflexão além da qualidade da KB, porque a maioria das perguntas reais precisa de contexto de conta, não de conteúdo genérico.
- Escalonamento com contexto. Quando a IA não consegue lidar, ela não devolve o cliente ao início. Ela passa ao agente humano um resumo completo da conversa, o estado relevante da conta e o motivo do escalonamento. Esta é a diferença entre "a IA tentou e falhou" e "a IA fez a triagem para que o humano possa resolver em 90 segundos."
Dois alertas que valem a pena destacar, pois derrubam toda a estrutura quando ignorados:
- Confiança de LLM não é confiança factual. Um LLM pode ter 95% de confiança em uma resposta alucinada — as pontuações de confiança medem probabilidade de token, não verdade. Nunca use confiança bruta como único critério. Combine-a com sinais de cobertura da KB e regras de escopo de tópico (post-mortem HITL da DEV Community).
- A KB é seu teto, não o modelo. Trocar GPT-4 por Claude não vai corrigir uma taxa de deflexão presa em 35%. Atualizar sua base de conhecimento e estreitar o escopo vai.
O que se reduz bem — e o que não se reduz
O outro número que a maioria das coberturas passa por alto: a redução de tickets com IA não é uniforme entre os tipos de consulta. O mesmo agente, na mesma KB, com o mesmo modelo, vai te dar números completamente diferentes dependendo do que você aponta para ele.
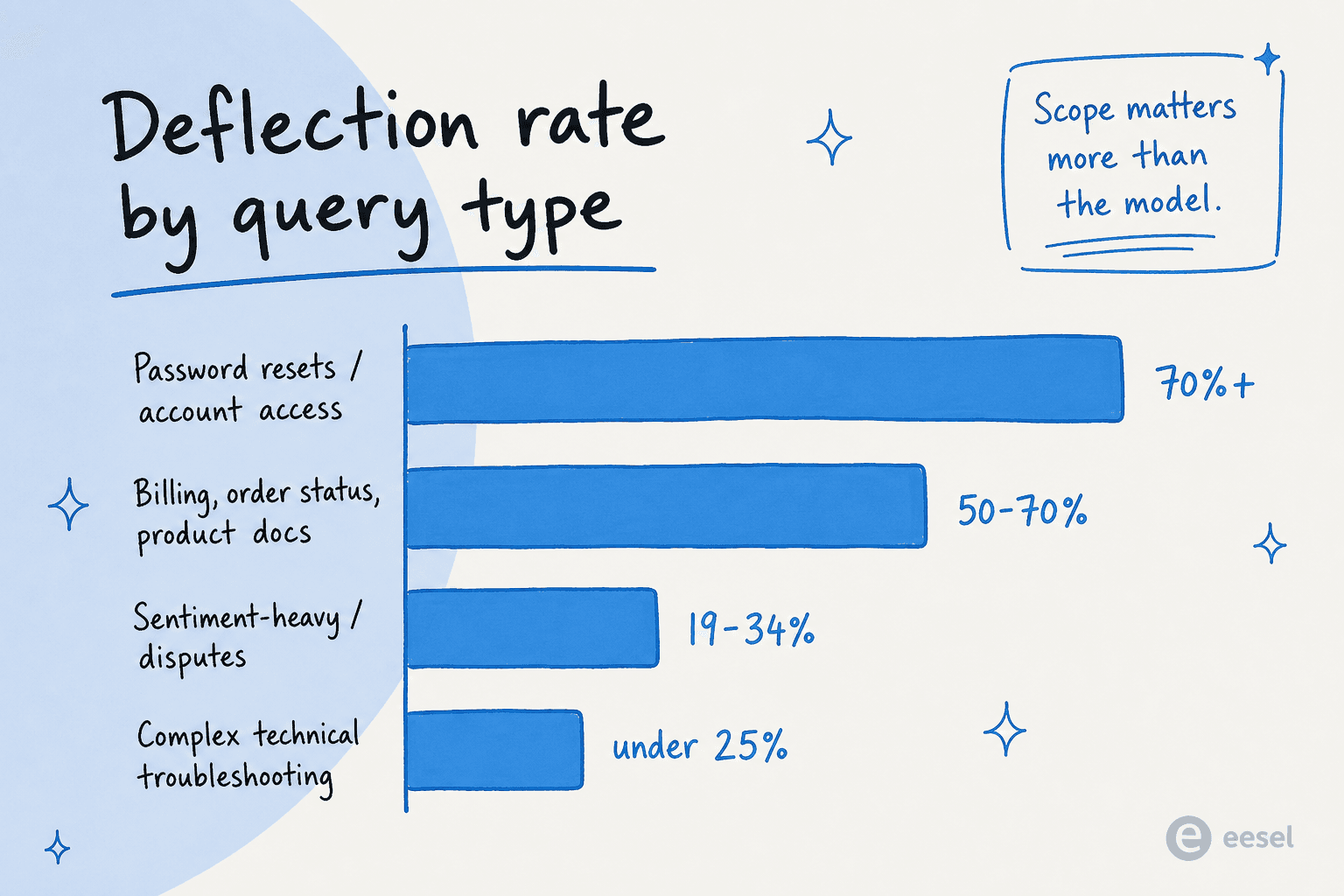
Segundo os benchmarks de 2026 da ClarityArc e o guia de deflexão da Pylon:
| Tipo de consulta | Taxa de deflexão típica | Por quê |
|---|---|---|
| Redefinições de senha / acesso a contas | 70%+ | Alto volume, determinístico, resposta no sistema de registro |
| Status de pedido / WISMO | 50-70% | Consulta de backend quando as integrações estão conectadas |
| Reembolsos e devoluções (política padrão) | 50-70% | KB clara + ação agêntica disponível |
| Produto padrão / documentação how-to | 50-70% | Vinculado à KB, bem trilhado |
| Solução técnica complexa | Abaixo de 25% | Cada caso é novo; precisa de raciocínio humano |
| Carga emocional / estilo de disputa | 19-34% | Contexto emocional, não apenas informacional |
| Regulado / sensível a conformidade | Abaixo de 20% | Risco e revisão superam velocidade |
É por isso que a decisão de maior alavancagem em qualquer projeto de redução de tickets com IA é o escopo, não a seleção de fornecedor. Escolha dois ou três tipos de consulta que estão na metade superior dessa tabela, leve-os a 60-70% de deflexão real, e então expanda. Escolha "tudo" no primeiro dia e a média cai tanto que o projeto é cancelado.
Nossa opinião: se sua equipe está começando agora, faça redefinições de senha e WISMO primeiro. Eles têm alto volume, são determinísticos, e reduzem a fila de forma notável o suficiente para que o resto da equipe apoie o projeto. Tentar desviar tickets de reclamações no primeiro dia é como projetos de IA perdem credibilidade interna.
Números reais de equipes reais (e o que tinham em comum)
Os destaques de estudos de caso são reais — mas a conclusão não é "nós também deveríamos atingir 86%." É "olhe o quão estreitamente delimitado era cada um desses."
- Grammarly passou de 60% para 87% de deflexão em 10 dias com a plataforma agêntica da Forethought, com o CSAT melhorando para 4,2/5. A adição de integrações de sistemas contribuiu mais 5-10%.
- Bilt Rewards lida com 70% de 60.000 tickets mensais com agentes de IA.
- Duolingo opera acima de 80% de deflexão com Decagon.
- A IA da Klarna lida com dois terços de todo o atendimento ao cliente — equivalente a 700 agentes em tempo integral.
- Clientes do varejo da Freshworks veem o Freddy AI resolver 53% de todas as consultas recebidas.
- Clientes de eCommerce da Gorgias rotineiramente atingem 60% de deflexão mesmo com tempo mínimo de treinamento.
O fio condutor não é a plataforma. É o modelo operacional: escopo estreito no primeiro dia, integrações profundas de CRM/pedidos/faturamento, um limite de confiança calibrado, um caminho de escalonamento limpo, e o hábito de usar cada escalonamento como uma atualização da base de conhecimento. Os fornecedores variam; a disciplina não.
Os próprios benchmarks de clientes da eesel refletem o mesmo padrão. Uma empresa de análise de dados para motoristas da economia gig no Zendesk Business resolveu 73% das solicitações de nível 1 em seu primeiro mês após um teste de 7 dias. Um helpdesk interno de TI no Jira Service Management está em 15% de deflexão com uma meta de 55% à medida que sua KB e o escopo do agente se expandem. O número que se move não é o modelo — são os inputs.
As cinco coisas que as equipes que realmente movem o número acertam
Entre o dossiê de mais de 50 implementações em produção analisadas pela Corebee.ai, o guia de deflexão da Pylon, e o guia de produção da ClarityArc, as mesmas cinco variáveis aparecem em cada equipe que chega a uma redução honesta de 60%+.
1. Qualidade da base de conhecimento primeiro, IA depois
Esta é a alavanca de maior impacto em todo o sistema. Documentação bem estruturada aumenta a resolução genuína em 15-25% — antes de você tocar em qualquer configuração de modelo. O motivo pelo qual a maioria dos pilotos estagna: as equipes apontam a IA para a KB que têm, não para a KB de que precisam. A KB que têm foi escrita para agentes humanos que já conhecem o produto, não para uma IA que precisa responder do zero.
A correção é mecânica: escolha as duas ou três intenções que você vai delimitar, audite os artigos correspondentes da KB, reescreva-os para perguntas em linguagem natural em vez de jargão interno, e incorpore os tickets resolvidos recentes na KB como exemplos práticos. Então implante.
Se você está começando com uma KB esparsa, nossos guias para criar um chatbot de base de conhecimento com IA e escolher as ferramentas de base de conhecimento com IA certas cobrem o encanamento de dados.
2. Delimite o escopo com precisão. Depois ainda mais estreito.
O modo de falha mais consistente na análise de discussões é equipes tentando cobrir "tudo" no primeiro dia. Comece com 2-3 tipos de consulta onde a KB está genuinamente completa. Cubra-os bem — meça honestamente, corrija as lacunas, empurre além de 60% de deflexão real — e só então expanda.
O que é excluído do escopo do primeiro dia:
- Qualquer coisa com forte carga emocional (disputas de reembolso, reclamações, escalonamentos de contas nomeadas)
- Qualquer coisa regulamentada ou sensível a conformidade
- Qualquer coisa que exija leitura de contexto fora da KB (bugs de engenharia, status do sistema durante incidentes)
- Tickets de suas contas de nível superior — VIPs vão para humanos na primeira mensagem, sem exceção
3. Integre fundo o suficiente para a IA agir, não apenas descrever
Se a IA só puder recuperar artigos da KB, ela vai estagnar em torno de 35-40% de deflexão. As implementações de 60-90% todas têm integração com CRM, faturamento e sistema de pedidos que permite ao agente executar a ação real — consultar o pedido, processar a devolução, alterar o plano.
Os dados da ClarityArc mostram que a profundidade de integração contribui com 20-30% além da deflexão apenas com KB. A citação mais forte dos profissionais sobre isso:
"O verdadeiro avanço é quando a IA pode realmente resolver o problema de ponta a ponta em seus sistemas, não apenas sugerir o que dizer."
É também por isso que chatbots baseados em regras adicionados posteriormente tendem a falhar. Eles recuperam, mas não agem. Os clientes fazem uma pergunta que precisa de dados da conta, o bot falha, os números de deflexão sobem enquanto o CSAT cai. Plataformas nativas de IA — as que leem seu helpdesk, seu CRM e seu sistema de pedidos em um único tempo de execução — fecham esse loop.
4. Calibre o roteamento por confiança — e deixe a IA dizer "não sei"
Esta foi a objeção decisiva no nosso próprio dossiê de chamadas com clientes:
"A IA nunca será capaz de responder 100% das perguntas, mas se ela tentar e apenas responder 'desculpe, não sei isso', não posso ir verificar todos os meus 7.000 tickets para ver se a IA realmente deu uma boa resposta. Preciso de uma IA que lide apenas com os tickets nos quais está confiante, e todos os outros, que deixe em paz."
um líder de CX em uma marca de suplementos DTC no Gorgias + Shopify (~7K tickets/mês), dossiê de clientes da eesel (anonimizado por consentimento)
Essa é toda a tese sobre roteamento por confiança em uma única citação. Uma IA que responde tudo é pior do que uma IA que responde metade e claramente escala o resto. Ajuste seus limites alto/médio/baixo testando com tráfego real, não por intuição — e recalibre-os a cada trimestre à medida que a KB evolui.
Se quiser uma leitura mais aprofundada sobre isso, nosso guia sobre o limiar de confiança de intenção do agente de IA do Zendesk explica como um helpdesk real o implementa.
5. Trate cada escalonamento como um sinal de aprendizado
Toda vez que a IA escala, ela está te dizendo uma de três coisas: a KB tem uma lacuna, o escopo estava errado para essa intenção, ou o limite de confiança precisa de ajuste. As equipes que publicam as maiores taxas de deflexão fazem uma revisão semanal de 20-30 conversas escalonadas e transformam os padrões em atualizações de KB, mudanças de escopo ou regras de roteamento.
O oposto — escalonamentos se acumulando sem serem lidos, o bot respondendo silenciosamente de forma errada, ninguém auditando — é como uma taxa de deflexão de 65% silenciosamente se torna uma taxa de supressão de 65% e um pico de churn seis meses depois.
Como a redução de tickets com IA dá errado (os modos de falha para projetar ao redor)
Os mesmos padrões recorrem nas mais de 50 threads de equipes de suporte que a Corebee analisou, nos post-mortems da DEV Community, e nas conversas com profissionais na análise de junho de 2025 da SaaStr. Se você está implementando isso, projete ao redor destes desde o primeiro dia:
- A taxa de deflexão se torna um KPI. Uma vez que é um número pelo qual as pessoas são remuneradas, o sistema é projetado para atingir o número — mesmo ao custo da experiência do cliente. Acompanhe-a como um sinal junto com CSAT e taxa de recontato, não como uma meta.
- VIPs encontram o bot. O modo de falha mais caro é suas contas de nível superior encontrando uma barreira de IA enquanto um cliente de US$ 40/mês recebe um humano. Roteie VIPs diretamente para humanos na mensagem um. Sempre.
- Respostas confiantes mas erradas. O bot responde a uma consulta que deveria ter escalonado, o cliente confia nela, e uma pergunta simples se torna uma crise de confiança. A correção são guardrails de escopo de tópico (o bot tem permissão para responder sobre X, não tem permissão sobre Y), não apenas um limite de confiança.
- Loops do bot sem escalonamento. Um botão "falar com um humano" enterrado quatro cliques abaixo, um caminho de escalonamento que refaz as mesmas perguntas que o bot já fez, ou nenhum caminho humano. Os clientes fazem churn silenciosamente quando essa é a experiência.
- Onda de recontatos por outros canais. Sua taxa de deflexão na plataforma sobe, sua fila telefônica sobe ainda mais. Sempre verifique os volumes dos canais antes de comemorar uma vitória de deflexão.
Um post-mortem da DEV Community de uma equipe processando mais de 12.000 tarefas de agente por dia apresenta o caso de forma nítida. Antes de adicionarem verificações humanas no loop para tarefas de alto risco, sua taxa de erros críticos estava em 23,4%. O agente fechou automaticamente 34 tickets que deveriam ter ido para engenharia, incluindo três incidentes ativos de produção. Um cliente perdeu seis horas de dados.
"Esse incidente nos custou um contrato anual de US$ 280K e um post-mortem muito desconfortável."
Após o HITL nas tarefas certas (não revisão em massa de tudo), a taxa de erros críticos caiu para 5,1% — uma redução de 78% — e a sobrecarga de revisão humana caiu 62%. A lição que a equipe resumiu: "A parte difícil não é construir o agente — é decidir quando confiar nele."
Um guia de implementação que não destrói a confiança
Reunindo tudo isso em algo que você pode realmente fazer nos próximos 90 dias:
Semanas 1-2 - Diagnóstico. Puxe seus últimos 1.000 tickets. Categorize-os por intenção. Encontre as três principais intenções por volume e por completude da KB. Não escolha apenas por volume — uma intenção de alto volume com uma KB esparsa é um projeto, não uma vitória rápida.
Semanas 3-4 - Prepare a KB. Para cada intenção selecionada, reescreva ou atualize os artigos da KB. Adicione 5-10 exemplos práticos de tickets resolvidos reais. Remova o jargão interno. Teste pedindo a um agente júnior que responda do zero a partir da KB; se ele não conseguir, sua IA também não vai.
Semanas 5-6 - Conecte as integrações. Conecte o helpdesk, o CRM e o sistema de pedidos/faturamento. O agente precisa de acesso de leitura ao estado da conta e acesso de escrita nas ações que você realmente quer que ele execute.
Semanas 7-8 - Piloto em modo copiloto. Execute a IA como copiloto — redigindo respostas, nunca enviando autonomamente. Meça com que frequência os agentes humanos enviam o rascunho sem alterações, editam levemente ou reescrevem do zero. Se a taxa de "enviar sem alterações" atingir 60%+ em suas intenções delimitadas, você está pronto para o autônomo.
Semanas 9-12 - Avance para autônomo na intenção mais segura primeiro. Comece com uma intenção. Alto limite de confiança. Padrões agressivos de escalonamento. Auditorias semanais de conversas. Mova o limite para baixo apenas quando os dados suportarem.
Esta é a disciplina operacional, não a tecnologia, que separa equipes que reportam redução honesta de 60%+ de equipes executando uma taxa de deflexão de 35% disfarçada de 80%. Para um guia mais completo, veja nosso guia prático para reduzir tickets de suporte com IA.
Try eesel
Se você está implementando a redução de tickets com IA e quer uma plataforma que esteja alinhada com o guia acima em vez de contra ele — roteamento baseado em confiança, integrações profundas com Zendesk, Freshdesk, Gorgias e mais de 100 outros, controle de escopo por tipo de ticket e precificação que não te penaliza por testar — é exatamente para isso que o eesel foi criado.
Os agentes eesel vivem dentro do seu helpdesk existente (sem substituição de plataforma), aprendem com seu histórico de tickets e KB existentes no primeiro dia, e permitem que você os instrua em linguagem natural — "lide com a fila de WISMO, escale qualquer coisa acima de US$ 500 em reembolsos, deixe os tickets irritados em paz." O preço é por tarefa, não por assento ou por resolução, então você só paga pelos tickets que a IA realmente toca.
Clientes reais avançaram rápido. Uma empresa de análise de dados para motoristas da economia gig no Zendesk Business resolveu 73% das solicitações de nível 1 em seu primeiro mês após um teste de 7 dias. Uma equipe de suporte no Reino Unido gerou 56 tarefas resolvidas com apenas 9 macros sincronizadas. O nível gratuito (US$ 50 de crédito, sem cartão necessário) é suficiente para fazer um piloto real com seus próprios dados.
Experimente o eesel gratuitamente → — ou agende uma demonstração de 30 minutos se preferir que a gente percorra sua stack com você.
Perguntas Frequentes
O que é redução de tickets com IA?
Quanto a redução de tickets com IA pode realisticamente desviar?
Qual é a diferença entre redução de tickets com IA e deflexão de tickets com IA?
Quanto tempo leva para a redução de tickets com IA ter retorno?
Quais tickets de suporte são mais fáceis de reduzir com IA?
Como medir a redução de tickets com IA de forma honesta?
A redução de tickets com IA vai substituir meus agentes de suporte?
Qual é a melhor ferramenta de redução de tickets com IA para Zendesk, Freshdesk ou Gorgias?

Article by
Riellvriany Indriawan
Riell is a designer and writer at eesel AI with about two years of experience researching CX platforms, AI chatbots, and helpdesk software. She combines her design background with a sharp eye for how these tools actually look and feel in practice — making her comparisons unusually visual and user-focused.








