
テクノロジー業界の古い格言、「Garbage In, Garbage Out(ゴミを入れれば、ゴミが出てくる)」という言葉を耳にしたことがあるでしょう。これは、質の悪いインプットは質の悪いアウトプットにつながるというシンプルな考え方です。正直なところ、今日のAIほどこの言葉が当てはまるものはありません。AIサポートエージェントのパフォーマンスは、学習するデータに完全に依存します。
それでもなお、多くのチームはAIにとっての「良いデータ」がどのようなものか、少し曖昧に捉えています。「事前学習データの要件」という言葉は、まるで技術系の教科書から飛び出してきたように聞こえますが、実際にはAIを導入してサポートを任せる前に、社内の情報を整理整頓しておく、というだけの話です。AIが最初に適切な情報を持っていなければ、顧客にとって大して役には立たないでしょう。
このガイドでは、専門用語を避け、実際に問題を解決できるサポートAIを構築するために、企業の既存ナレッジをどのように準備すればよいかを順を追って説明します。
サポートAIのためのデータ準備に必要なもの
まず一つはっきりさせておきましょう。サポートAIの導入準備のために、プログラマーである必要も、データサイエンティストのチームを雇う必要もありません。これは、あなたのチームがすでに毎日使っている情報やリソースを見直すことに尽きます。知識の棚卸しチェックだと考えてください。
おそらく、以下のものを手元に用意しておくとよいでしょう:
-
ヘルプデスクへのアクセス:Zendesk、Freshdeskなど、プラットフォームを問わず、顧客との実際の会話が行われる場所です。
-
公式ナレッジベース:顧客が目にする、一般公開されているヘルプセンターやFAQページです。
-
社内ドキュメント:エージェントが頼りにしている、ConfluenceやGoogle Docs、Notion、あるいはPDFなどのWiki、ガイド、ドキュメントすべてです。
-
最初の目標:AIに最初に何を処理させたいですか?もしかしたら、パスワードリセットやよくある料金に関する質問だけかもしれません。明確な最初の目標を持つことで、焦点を絞り続けられます。
世界トップクラスのサポートAIのためのデータ準備方法
ステップ1:AIトレーニングの2つのタイプを理解する
事前学習データの要件を本当の意味で理解するためには、AIがどのように学習するかを2つの段階で考えると分かりやすいでしょう。これは、新しいチームメンバーに似ています。まず、一般的な教育があり、その次にあなたが提供する具体的な実務研修があります。
これはAIの「机上の知識」です。大規模言語モデル(LLM)は、Common CrawlやC4などのソースからインターネットの膨大な情報を読み込むことで基礎を学びます。これにより、モデルは広範な語彙と、言語がどのように機能するかの一般的な理解を得ます。AIが理路整然とした文章を書けるようになるのはこのおかげです。
問題は、この一般的な知識にはカスタマーサポートにおいて大きな弱点があることです:
-
情報はたいてい古い。 これらのモデルが学習するデータは、何年も前のものの可能性があります。2024年の研究「A Pretrainer’s Guide to Training Data」では、データと質問の間に時間的な隔たりがあるとパフォーマンスが低下することが確認されています。昨年のインターネットで学習したAIは、あなたの最新機能や、つい最近導入した新しい返品ポリシーについては知りません。
-
完全に一般的である。 一般的なLLMはフランスの首都を答えることはできますが、あなたの製品、顧客、あるいは会社のトーンについては全く何も知りません。役立つ、正確な回答を提供するためのコンテキストを一切持っていません。
-
ややリスクを伴う可能性がある。 これらの巨大なデータセットには、偏見、有害なコンテンツ、あるいは個人情報が含まれていることがあります。プライバシーや法的なリスクを指摘する研究もあります。なぜなら、あなたのボットに、ウェブの忘れ去られた片隅から拾ってきた奇妙で偏った、あるいは単に間違った情報を口走ってほしくないからです。
企業独自のトレーニング(ファインチューニング)
これが「実務研修」であり、率直に言って、サポートAIにとって本当に重要な部分です。ここでモデルは、あなたのビジネスの隅々までを学びます。このステップを飛ばしたAIは、何の研修も受けずに電話対応に放り込まれた新人と同じです。自信ありげに聞こえるかもしれませんが、実際には何も解決できません。
ここで、eesel AIのような、サポートに特化して作られたツールが真価を発揮します。eesel AIは、あなたの独自のナレッジソース、過去のチケット、ヘルプ記事、社内ガイドに直接接続し、一般的なチャットボットではなく、あなたのビジネスのエキスパートになるように設計されています。
ステップ2:既存のナレッジソースを棚卸しする
さて、あなたの会社独自の知識が重要であることは分かりました。次に論理的なステップは、そのすべてがどこにあるかを把握することです。少しの間、あなた自身のチームについて考えてみてください。彼らは答えが必要なとき、どこに行きますか?
まずは簡単なリストを作ってみましょう。ヘルプデスクやナレッジベースといった分かりやすいものから始めますが、隠れた宝物も忘れないでください。共有されたGoogleドライブのフォルダ、あの本当に役立つSlackチャンネル、あるいはConfluenceに埋もれている製品ドキュメントなどを考えてみてください。
その過程で、さまざまなトピックに関する「信頼できる唯一の情報源(source of truth)」を特定するように努めましょう。矛盾した情報が見つかるかもしれませんが、それで大丈夫です。それを見つけることが、修正への第一歩です。
これが大変な作業に聞こえるなら、その通りです。だからこそ、これらすべての情報を手作業で一箇所に集めようとすることは、これほど頭の痛い問題なのです。もっと簡単な方法は、情報がすでに存在する場所ですべてに接続するツールを使うことです。例えば、eesel AIには、ワンクリックでこれらのソースをすべて統合する機能があり、大規模なコンテンツ移行プロジェクトを実行することなく、AIのための一元化された頭脳を作り出します。

ステップ3:データの品質と網羅性を評価する
ナレッジの全体像を把握したら、次は品質チェックの時間です。質の高い、多様な情報を持つことが、AIにとっては単に大量の情報を持つことよりもはるかに重要であることが分かっています。「Pretrainer's Guide」の研究では、ウェブページや構造化されたドキュメントなど、さまざまなソースを組み合わせることで、より賢いモデルが作られることが示されています。
あなた自身のデータについて、いくつか問いかけるべき質問があります:
-
最新の状態ですか? それとも、ヘルプ記事はデジタルなホコリをかぶっていませんか?古い情報は、AIが間違った答えを出す主な原因の一つです。
-
基本的な内容を網羅していますか? あなたのドキュメントは、顧客の最も一般的な質問に実際に答えていますか?それとも、その情報の多くはエージェントの頭の中にしかない「暗黙知」ですか?
-
一貫性はありますか? ヘルプデスクのマクロは、社内ガイドと同じことを言っていますか?もしそうでなければ、新人のエージェントを混乱させるのと同じくらい、AIも混乱させてしまいます。
-
クリーンですか? 過去のサポートチケットを考えてみてください。それらは明確な解決策の宝庫ですか?それとも、無駄なやり取りや誤った情報で溢れていますか?
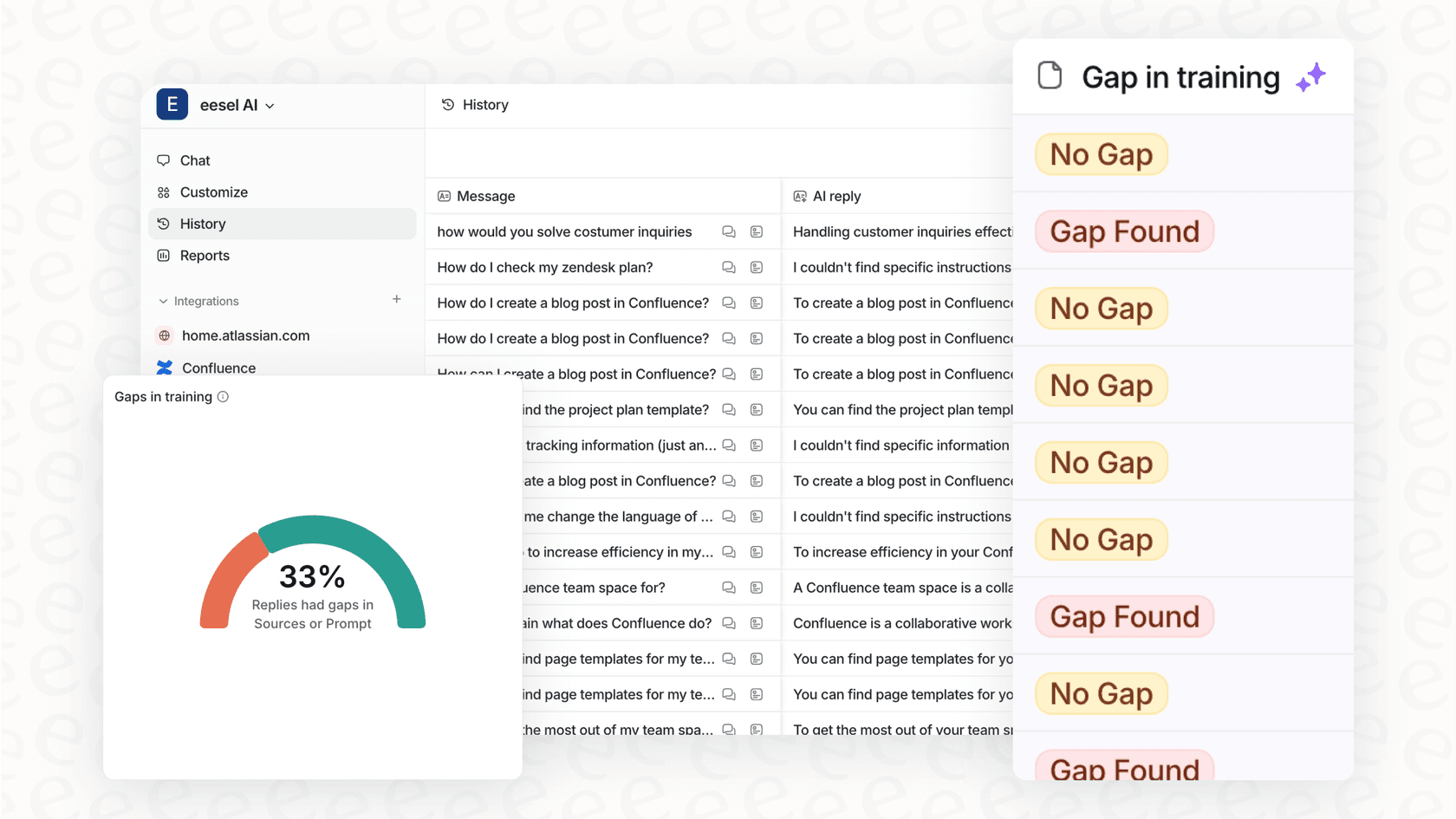
ステップ4:本番稼働前にテストとシミュレーションを行う
新しい機能をテストせずに本番環境にリリースすることはないですよね?サポートAIにも同じ理屈が当てはまる事です。一人でも顧客と対話させる前に、AIがきちんと仕事をしてくれるかを知る必要があります。
そこでシミュレーションの出番です。良いシミュレーションとは、単なる簡単なデモではありません。AIを何千もの実際の過去のサポートチケットに対して実行する、本格的なストレステストです。これにより、以下の点が正確にわかります:
-
AIが実際の顧客の問題にどう答えたか。
-
AIが単独で解決できたチケットの数。
-
AIが人間のエージェントに正しくエスカレーションしたであろう問題。
このプロセス全体が当て推量をなくし、何かを決定する前に現実的なROIを把握させてくれます。
これは私たちがeesel AIで特に重視した点です。多くのツールは限定的なデモを提供し、あとは祈るような気持ちで本番稼働に踏み切るしかありません。私たちは、あなたのデータを使って、あなたの環境でAIがどのように機能するかを正確に確認できるシミュレーションモードを構築しました。安全なサンドボックス環境で設定を調整したり、ナレッジソースを追加・削除したりして、最適な状態に仕上げることができるため、準備万端でAIをローンチできます。

避けるべきよくある間違い
事前学習データの要件を把握することは、さまざまなAIツールを検討する際に潜在的な危険信号を見つけるのにも役立ちます。注意すべきよくある落とし穴をいくつか紹介します。
| 間違い | なぜ問題なのか | より良いアプローチ |
|---|---|---|
| 汎用AIに依存する | あなたのビジネスについて何も知らないAIを導入することになります。間違った、ブランドイメージにそぐわない、あるいは危険な回答をする可能性が高くなります。 | 最初からあなたの特定のヘルプデスクチケットやドキュメントでトレーニングするように作られたプラットフォームを選びましょう。 |
| 「リプレース(総入れ替え)」の罠に陥る | AI機能を利用するためだけにヘルプデスクを切り替えなければならないのは、チームにとって大規模でコストのかかる頭痛の種です。 | 現在のワークフローにスムーズに組み込めるツールを探しましょう。eesel AIは、ZendeskやFreshdeskなどのプラットフォームにワンクリックで統合できます。 |
| コントロールを放棄する | あなたの監督なしに物事を自動化する「ブラックボックス」なAIは、大惨事のもとです。その応答を制御できないため、非常に悪い顧客体験につながる可能性があります。 | コントロールを維持することを強く求めましょう。eesel AIでは、どのチケットを自動化するかを正確に決定し、AIの個性、アクション、そして知ることを許可される内容を微調整できます。 |
なぜ事前学習データが優れたサポートAIの基盤なのか
つまり、AIのためにデータを準備することは、データサイエンティストにしかできない複雑な技術的タスクではありません。それは、あなたがすでに持っている知識を取り出し、整理することに他なりません。
AIの一般的な「机上の知識」と、特定の「実務研修」の違いを理解すれば、本当に重要なことに集中できます。それは、あなたのナレッジを棚卸しし、あなたの独自のビジネスから学ぶツールを選ぶことです。結局のところ、最高のサポートAIとは、あなたの会社のエキスパートであるAIなのです。そして、その専門知識は、あなたのデータから生まれなければなりません。
あなたから学ぶAIを始めよう
あなた自身のナレッジでトレーニングされたAIが実際に何ができるか、見てみませんか?eesel AIは、あなたのヘルプデスクや他のツールに数分で接続します。
過去のチケットでシミュレーションをすぐに実行し、AIがどのように機能したかを確認できます。待つ必要も、契約の必要もありません。
**無料トライアルにサインアップ**して、ご自身でお確かめください。
よくある質問
[事前学習データの要件](https://openai.com/research/requirements-for-pretraining-data)とは、サポートAIが顧客を効果的に支援できるようになる前に学習する必要がある情報や知識のことです。これは、AIにあなたのビジネスに関する基礎的な理解を提供するために、会社の既存のナレッジソースを整理することを指します。
はい、サポートチームは顧客とのやり取りや会社のナレッジに関する専門家であるため、これらの要件を理解する上で重要な役割を果たします。プログラマーである必要はありません。むしろ、チームがすでに日常的に使用しているデータを特定し、整理することが中心となります。
ヘルプデスク、公式ナレッジベース、そしてWikiや共有ドライブのような社内ドキュメントからデータを収集すべきです。これらのソースは、AIが必要とする実際の顧客とのやり取りや会社固有の情報を提供します。
棚卸しによって既存のすべてのナレッジソースを把握でき、品質評価によってデータが最新で一貫性があり、一般的な質問を網羅しているかを確認できます。AIのパフォーマンスにとっては、単に大量のデータよりも[質の高い、多様な情報の方が重要](https://docs.aws.amazon.com/bedrock/latest/userguide/model-customization-prepare.html)です。
会社固有のコンテキストに欠ける汎用AIモデルだけに依存することは避けてください。また、既存のヘルプデスクの「リプレース(総入れ替え)」を強制するツールや、AIの応答に対するコントロールを一切与えないツールも避けるべきです。
理想的なデータは最新でクリーンですが、[最新のAIツール](https://www.eesel.ai/ja/blog/ai-assistant-capabilities)はギャップを特定し、改善点を提案するのに役立ちます。棚卸しのプロセスは、古い情報や一貫性のない情報を特定するのに役立つ、更新の優先順位をつけたり、多様なデータを賢く処理できるツールを活用したりすることを可能にします。
Share this article

Article by
Stevia Putri
Stevia Putri is a marketing generalist at eesel AI, where she helps turn powerful AI tools into stories that resonate. She’s driven by curiosity, clarity, and the human side of technology.