
You've probably heard the old tech mantra: "Garbage In, Garbage Out." It’s a simple idea, bad inputs lead to bad outputs. And honestly, it’s never been more relevant than with today's AI. The performance of an AI support agent depends entirely on the data it learns from.
Still, a lot of teams are a bit fuzzy on what "good data" even looks like for an AI. The phrase pretraining data requirements sounds like something straight out of an engineering textbook, but it's really just about getting your house in order before you bring in an AI to help out. If your AI doesn’t have the right information to start with, it’s not going to be much help to your customers.
In this guide, we'll cut through the jargon and walk you through how to prepare your company's existing knowledge to build a support AI that actually solves problems.
What you'll need to prepare your data for a support AI
Let's get one thing straight: you don't need to be a coder or hire a team of data scientists to get ready for a support AI. This is all about looking at the information and resources your team already uses every day. Think of it as a knowledge inventory check.
You'll probably want to have these things handy:
-
Access to your helpdesk: This is where the real customer conversations happen, whether it’s in Zendesk, Freshdesk, Intercom, or another platform.
-
Your official knowledge base: The public-facing help center or FAQ pages your customers see.
-
Internal documentation: All the wikis, guides, and docs your agents rely on, like content in Confluence, Google Docs, Notion, or even PDFs.
-
A starting goal: What's the first thing you want the AI to handle? Maybe it's just password resets or common pricing questions. Having a clear first goal keeps things focused.
How to prepare your data for a world-class support AI
Step 1: Understand the two types of AI training
To get a real feel for pretraining data requirements, it helps to think of how an AI learns in two stages, kind of like a new team member. First, there's their general education, and then there's the specific on-the-job training you give them.
This is the AI’s "book smarts." Large language models (LLMs) learn the basics by reading a huge chunk of the internet, from sources like Common Crawl or C4. This gives the model a massive vocabulary and a general grasp of how language works. It’s how the AI learns to write a coherent sentence.
The problem is, this general knowledge has some big blind spots for customer support:
-
The information is usually old news. The data these models are trained on can be years out of date. A 2024 study, "A Pretrainer’s Guide to Training Data," confirmed that performance drops when there's a time gap between the data and the questions. An AI trained on last year's internet won't know about your latest feature or that new return policy you just rolled out.
-
It's completely generic. A general LLM can tell you the capital of France, but it knows absolutely nothing about your products, your customers, or your company's voice. It has zero context to give a helpful, accurate answer.
-
It can be a bit of a liability. These giant datasets can be full of biases, toxic content, or private information. Studies have pointed out the privacy and legal risks because you don't want your bot spouting weird, biased, or just plain wrong information it picked up from some forgotten corner of the web.
Company-specific training (fine-tuning)
This is the "on-the-job" training, and frankly, it's the part that really matters for a support AI. This is where the model learns the ins and outs of your business. An AI that skips this step is like a new hire you've thrown onto the phones without any onboarding, they might sound confident, but they can't actually solve anything.
This is where tools built specifically for support, like eesel AI, really make a difference. It's designed to connect directly to your unique knowledge sources, past tickets, help articles, internal guides, to become an expert on your business, not just a generic chatbot.
Step 2: Audit your existing knowledge sources
Okay, so your company's specific knowledge is key. The next logical step is to figure out where it all is. Just think about your own team for a minute: where do they go when they need an answer?
Start making a quick list. You’ll have the obvious stuff like your helpdesk and knowledge base, but don’t forget the hidden gems. Think about shared Google Drive folders, that one really helpful Slack channel, or the product docs buried in Confluence.
While you're at it, try to pinpoint the "source of truth" for different topics. You'll probably find some contradictory info, and that's okay. Finding it is the first step to fixing it.
If this sounds like a lot of work, you're not wrong. It's why trying to manually herd all this information into one place is such a headache. A much easier way is to use a tool that connects to everything where it already lives. For instance, eesel AI has one-click integrations that pull all these sources together, creating a unified brain for your AI without you having to run a massive content migration project.

Step 3: Evaluate your data quality and coverage
Once you have a map of your knowledge, it's time for a quality check. It turns out that having high-quality, varied information is way more important for an AI than just having a ton of it. The "Pretrainer's Guide" study even found that a mix of different sources, like web pages and structured docs, makes for a smarter model.
Here are a few questions to ask about your own data:
-
Is it up-to-date? Or are your help articles collecting digital dust? Outdated info is a top reason why AIs give bad answers.
-
Does it cover the basics? Does your documentation actually answer your customers' most common questions? Or is a lot of that info just "tribal knowledge" that lives in your agents' heads?
-
Is it consistent? Do your helpdesk macros say the same thing as your internal guides? If not, you're going to confuse your AI just as much as you'd confuse a new agent.
-
Is it clean? Think about your past support tickets. Are they a goldmine of clear solutions, or are they full of back-and-forth chatter and wrong turns?
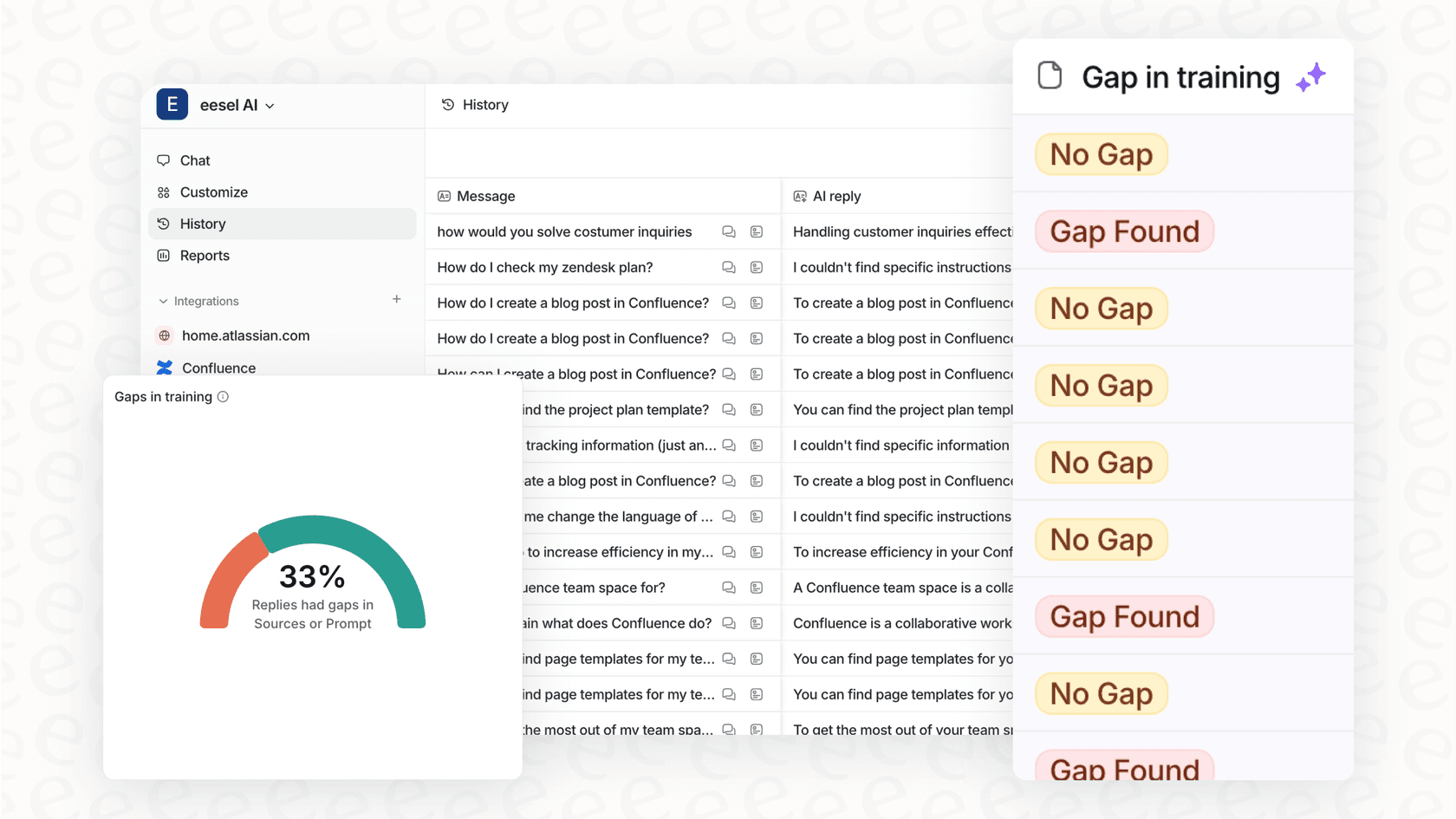
Step 4: Test and simulate before going live
You’d never push a new feature live without testing it, right? The same logic applies to your support AI. You need to know it’s going to do a good job before you let it talk to a single customer.
That's where simulation comes in. A good simulation isn't just a quick demo. It's a full-on stress test where the AI is run against thousands of your actual past support tickets. This shows you exactly:
-
How the AI would have answered real customer problems.
-
How many tickets it could have solved on its own.
-
Which issues it would have correctly flagged for a human agent.
This whole process takes the guesswork out of it and gives you a realistic idea of the ROI before you commit to anything.
This is something we really focused on at eesel AI. Many tools give you a limited demo and then you have to cross your fingers and go live. We built a simulation mode that lets you see precisely how the AI will perform with your data, in your environment. You can play with the settings, add or remove knowledge sources, and get it just right in a safe sandbox, so you can launch it knowing it's ready to go.

Common mistakes to avoid
Getting a handle on pretraining data requirements also helps you spot potential red flags when you're looking at different AI tools. Here are a few common traps to watch out for.
| Mistake | Why it's a problem | The better approach |
|---|---|---|
| Relying on a generic AI | You get an AI that knows nothing about your business. It's more likely to give wrong, off-brand, or even unsafe answers. | Go with a platform that is built to train on your specific helpdesk tickets and documents from the very beginning. |
| Falling for a "rip and replace" | Being forced to switch helpdesks just to get an AI feature is a massive, expensive headache for your team. | Look for a tool that slots right into your current workflow. eesel AI offers one-click integrations for platforms like Zendesk and Freshdesk. |
| Giving up control | A "black box" AI that automates things without your oversight is a recipe for disaster. You can't control its responses, which can lead to some really bad customer experiences. | Insist on having control. With eesel AI, you decide exactly which tickets get automated and can fine-tune the AI's personality, actions, and what it's allowed to know. |
Why pretraining data is the foundation for great support AI
So, getting your data ready for an AI isn't some complex technical task reserved for data scientists. It's really about taking the knowledge you already have and getting it organized.
Once you understand the difference between an AI's general "book smarts" and its specific "job training," you can focus on what matters: auditing your knowledge and picking a tool that learns from your unique business. At the end of the day, the best support AI is one that's an expert on your company. And that expertise has to come from your data.
Get started with an AI that learns from you
Ready to see what an AI trained on your own knowledge can actually do? eesel AI connects to your helpdesk and other tools in minutes.
You can run a simulation on your past tickets right away to see how it would have performed, no waiting around, and no commitment required.
Sign up for a free trial and see for yourself.
Frequently asked questions
[Pretraining data requirements](https://openai.com/research/requirements-for-pretraining-data) refer to the necessary information and knowledge a support AI needs to learn before it can effectively assist customers. It's about organizing your company's existing knowledge sources to provide the AI with the foundational understanding of your business.
Yes, support teams play a crucial role in understanding these requirements because they are the experts on customer interactions and company knowledge. You don't need to be a coder; it's more about identifying and organizing the data your team already uses daily.
You should gather data from your helpdesk, official knowledge base, and internal documentation like wikis or shared drives. These sources provide the real-world customer interactions and company-specific information the AI needs.
Auditing ensures you map out all existing knowledge sources, while evaluating quality checks if the data is up-to-date, consistent, and covers common questions. [High-quality, varied information is more important](https://docs.aws.amazon.com/bedrock/latest/userguide/model-customization-prepare.html) for AI performance than just a large volume of data.
Avoid relying solely on generic AI models, which lack company-specific context. Also, steer clear of tools that force a "rip and replace" of your existing helpdesk, or those that give you no control over the AI's responses.
While ideal data is up-to-date and clean, [modern AI tools](https://www.eesel.ai/blog/ai-assistant-capabilities) can help identify gaps and suggest improvements. The auditing process helps pinpoint outdated or inconsistent information, allowing you to prioritize updates or use tools that can intelligently process varied data.
Share this article

Article by
Kenneth Pangan
Writer and marketer for over ten years, Kenneth Pangan splits his time between history, politics, and art with plenty of interruptions from his dogs demanding attention.
