
Du hast wahrscheinlich schon das alte Tech-Mantra gehört: „Müll rein, Müll raus.“ Die Idee ist simpel: Schlechte Eingaben führen zu schlechten Ergebnissen. Und ehrlich gesagt war das noch nie so relevant wie bei der heutigen KI. Die Leistung eines KI-Support-Agenten hängt vollständig von den Daten ab, aus denen er lernt.
Dennoch haben viele Teams eine eher vage Vorstellung davon, was „gute Daten“ für eine KI überhaupt sind. Der Begriff „Anforderungen an Vortrainingsdaten“ klingt wie aus einem Ingenieurslehrbuch, aber im Grunde geht es nur darum, dein Haus in Ordnung zu bringen, bevor du eine KI zur Unterstützung hinzuziehst. Wenn deine KI nicht von Anfang an die richtigen Informationen hat, wird sie deinen Kunden keine große Hilfe sein.
In diesem Leitfaden werden wir den Fachjargon beiseitelassen und dich Schritt für Schritt anleiten, wie du das vorhandene Wissen deines Unternehmens vorbereiten kannst, um eine Support-KI zu entwickeln, die tatsächlich Probleme löst.
Was du zur Vorbereitung deiner Daten für eine Support-KI benötigst
Stellen wir eines klar: Du musst kein Programmierer sein oder ein Team von Datenwissenschaftlern einstellen, um dich auf eine Support-KI vorzubereiten. Es geht darum, sich die Informationen und Ressourcen anzusehen, die dein Team bereits täglich nutzt. Sieh es als eine Bestandsaufnahme deines Wissens.
Wahrscheinlich solltest du diese Dinge griffbereit haben:
-
Zugriff auf deinen Helpdesk: Hier finden die echten Kundengespräche statt, sei es in Zendesk, Freshdesk, [Intercom] oder einer anderen Plattform.
-
Deine offizielle Wissensdatenbank: Das öffentlich zugängliche Hilfe-Center oder die FAQ-Seiten, die deine Kunden sehen.
-
Interne Dokumentation: Alle Wikis, Anleitungen und Dokumente, auf die sich deine Agenten verlassen, wie Inhalte in Confluence, Google Docs, Notion oder sogar PDFs.
-
Ein Anfangsziel: Was ist das Erste, was die KI erledigen soll? Vielleicht geht es nur um das Zurücksetzen von Passwörtern oder häufige Fragen zur Preisgestaltung. Ein klares erstes Ziel hilft dabei, den Fokus zu behalten.
So bereitest du deine Daten für eine erstklassige Support-KI vor
Schritt 1: Verstehe die zwei Arten des KI-Trainings
Um ein echtes Gefühl für die Anforderungen an Vortrainingsdaten zu bekommen, hilft es, sich das Lernen einer KI in zwei Phasen vorzustellen, ähnlich wie bei einem neuen Teammitglied. Zuerst gibt es die allgemeine Ausbildung und dann das spezifische Training am Arbeitsplatz, das du ihm gibst.
Allgemeines Vortraining (Pre-Training)
Das sind die „Buchkenntnisse“ der KI. Große Sprachmodelle (LLMs) lernen die Grundlagen, indem sie einen riesigen Teil des Internets lesen, aus Quellen wie Common Crawl oder C4. Dadurch erhält das Modell einen massiven Wortschatz und ein allgemeines Verständnis dafür, wie Sprache funktioniert. So lernt die KI, einen zusammenhängenden Satz zu schreiben.
Das Problem ist, dass dieses allgemeine Wissen einige große blinde Flecken für den Kundensupport hat:
-
Die Informationen sind meist veraltet. Die Daten, auf denen diese Modelle trainiert werden, können Jahre alt sein. Eine Studie aus dem Jahr 2024, „A Pretrainer’s Guide to Training Data“, bestätigte, dass die Leistung sinkt, wenn zwischen den Daten und den Fragen eine Zeitlücke besteht. Eine KI, die auf dem Internet des letzten Jahres trainiert wurde, kennt dein neuestes Feature oder die neue Rückgaberichtlinie, die du gerade eingeführt hast, nicht.
-
Es ist komplett allgemein. Ein allgemeines LLM kann dir die Hauptstadt von Frankreich nennen, aber es weiß absolut nichts über deine Produkte, deine Kunden oder die Tonalität deines Unternehmens. Es hat null Kontext, um eine hilfreiche, genaue Antwort zu geben.
-
Es kann ein gewisses Risiko darstellen. Diese riesigen Datensätze können voller Vorurteile, toxischer Inhalte oder privater Informationen sein. Studien haben auf die Datenschutz- und Rechtsrisiken hingewiesen, denn du möchtest nicht, dass dein Bot seltsame, voreingenommene oder einfach falsche Informationen von sich gibt, die er aus irgendeiner vergessenen Ecke des Webs aufgeschnappt hat.
Unternehmensspezifisches Training (Fine-Tuning)
Das ist das Training „am Arbeitsplatz“ und ehrlich gesagt ist es der Teil, der für eine Support-KI wirklich zählt. Hier lernt das Modell die Besonderheiten deines Unternehmens. Eine KI, die diesen Schritt überspringt, ist wie ein neuer Mitarbeiter, den du ohne Einarbeitung ans Telefon setzt – er mag selbstbewusst klingen, aber er kann nichts wirklich lösen.
Genau hier machen Tools, die speziell für den Support entwickelt wurden, wie eesel AI, den entscheidenden Unterschied. Es ist darauf ausgelegt, sich direkt mit deinen einzigartigen Wissensquellen, vergangenen Tickets, Hilfeartikeln und internen Anleitungen zu verbinden, um zum Experten für dein Unternehmen zu werden, nicht nur ein allgemeiner Chatbot.
Schritt 2: Überprüfe deine vorhandenen Wissensquellen
Okay, das spezifische Wissen deines Unternehmens ist also entscheidend. Der nächste logische Schritt ist herauszufinden, wo sich all dieses Wissen befindet. Denk nur einen Moment an dein eigenes Team: Wohin gehen sie, wenn sie eine Antwort brauchen?
Beginne damit, eine kurze Liste zu erstellen. Du wirst die offensichtlichen Dinge wie deinen Helpdesk und deine Wissensdatenbank haben, aber vergiss nicht die versteckten Schätze. Denk an geteilte Google-Drive-Ordner, diesen einen wirklich hilfreichen Slack-Kanal oder die Produktdokumentationen, die in Confluence vergraben sind.
Versuche dabei auch, die „Quelle der Wahrheit“ für verschiedene Themen zu identifizieren. Du wirst wahrscheinlich einige widersprüchliche Informationen finden, und das ist in Ordnung. Sie zu finden, ist der erste Schritt, um sie zu korrigieren.
Wenn das nach viel Arbeit klingt, liegst du nicht falsch. Deshalb ist es so mühsam, all diese Informationen manuell an einem Ort zusammenzuführen. Ein viel einfacherer Weg ist die Verwendung eines Tools, das sich mit allem dort verbindet, wo es bereits vorhanden ist. Zum Beispiel hat eesel AI Ein-Klick-Integrationen, die all diese Quellen zusammenführen und so ein einheitliches Gehirn für deine KI schaffen, ohne dass du ein riesiges Projekt zur Inhaltsmigration durchführen musst.

Schritt 3: Bewerte die Qualität und Abdeckung deiner Daten
Sobald du eine Übersicht über dein Wissen hast, ist es Zeit für eine Qualitätsprüfung. Es stellt sich heraus, dass hochwertige, vielfältige Informationen für eine KI weitaus wichtiger sind, als nur eine riesige Menge davon zu haben. Die Studie „Pretrainer's Guide“ fand sogar heraus, dass eine Mischung aus verschiedenen Quellen, wie Webseiten und strukturierte Dokumente, zu einem intelligenteren Modell führt.
Hier sind ein paar Fragen, die du dir zu deinen eigenen Daten stellen solltest:
-
Sind sie aktuell? Oder setzen deine Hilfeartikel digitalen Staub an? Veraltete Informationen sind einer der Hauptgründe, warum KIs schlechte Antworten geben.
-
Decken sie die Grundlagen ab? Beantwortet deine Dokumentation tatsächlich die häufigsten Fragen deiner Kunden? Oder ist ein Großteil dieser Informationen nur „Stammeswissen“, das in den Köpfen deiner Agenten existiert?
-
Ist sie konsistent? Sagen deine Helpdesk-Makros dasselbe wie deine internen Anleitungen? Wenn nicht, wirst du deine KI genauso verwirren wie einen neuen Agenten.
-
Ist sie sauber? Denk an deine vergangenen Support-Tickets. Sind sie eine Goldgrube klarer Lösungen oder voller Hin- und Her-Gerede und falscher Abzweigungen?
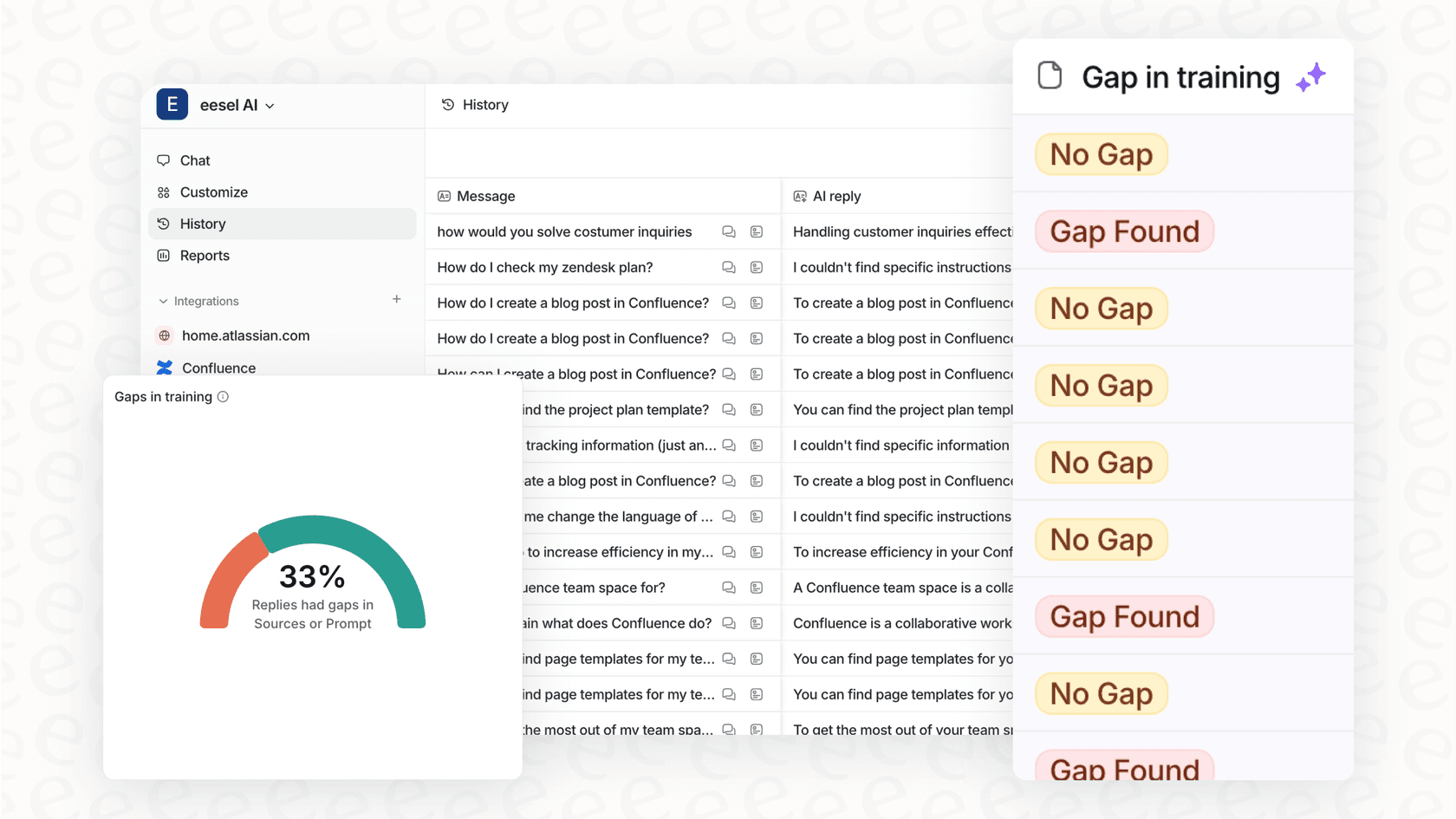
Schritt 4: Teste und simuliere vor dem Live-Gang
Du würdest niemals ein neues Feature live schalten, ohne es zu testen, oder? Dieselbe Logik gilt für deine Support-KI. Du musst wissen, dass sie einen guten Job machen wird, bevor du sie mit einem einzigen Kunden sprechen lässt.
Genau hier kommt die Simulation ins Spiel. Eine gute Simulation ist nicht nur eine schnelle Demo. Es ist ein umfassender Stresstest, bei dem die KI gegen Tausende deiner tatsächlichen vergangenen Support-Tickets antreten muss. Das zeigt dir genau:
-
Wie die KI auf echte Kundenprobleme geantwortet hätte.
-
Wie viele Tickets sie eigenständig hätte lösen können.
-
Welche Probleme sie korrekterweise für einen menschlichen Agenten markiert hätte.
Dieser ganze Prozess nimmt das Rätselraten aus der Gleichung und gibt dir eine realistische Vorstellung vom ROI, bevor du dich zu irgendetwas verpflichtest.
Darauf haben wir uns bei eesel AI besonders konzentriert. Viele Tools geben dir eine begrenzte Demo, und dann musst du die Daumen drücken und live gehen. Wir haben einen Simulationsmodus entwickelt, mit dem du genau sehen kannst, wie die KI mit deinen Daten in deiner Umgebung performen wird. Du kannst mit den Einstellungen spielen, Wissensquellen hinzufügen oder entfernen und alles in einer sicheren Sandbox perfektionieren, sodass du sie mit dem Wissen starten kannst, dass sie einsatzbereit ist.

Häufige Fehler, die du vermeiden solltest
Wenn du die Anforderungen an Vortrainingsdaten verstehst, hilft dir das auch, potenzielle Warnsignale zu erkennen, wenn du dir verschiedene KI-Tools ansiehst. Hier sind ein paar häufige Fallen, auf die du achten solltest.
| Fehler | Warum es ein Problem ist | Der bessere Ansatz |
|---|---|---|
| Sich auf eine allgemeine KI verlassen | Du bekommst eine KI, die nichts über dein Unternehmen weiß. Es ist wahrscheinlicher, dass sie falsche, markenfremde oder sogar unsichere Antworten gibt. | Wähle eine Plattform, die von Anfang an darauf ausgelegt ist, auf deinen spezifischen Helpdesk-Tickets und Dokumenten zu trainieren. |
| Auf ein „Rip and Replace“ hereinfallen | Gezwungen zu sein, den Helpdesk zu wechseln, nur um eine KI-Funktion zu erhalten, ist ein massiver, teurer Albtraum für dein Team. | Suche nach einem Tool, das sich nahtlos in deinen aktuellen Arbeitsablauf einfügt. eesel AI bietet Ein-Klick-Integrationen für Plattformen wie Zendesk und Freshdesk. |
| Die Kontrolle abgeben | Eine „Blackbox“-KI, die Dinge ohne deine Aufsicht automatisiert, ist ein Rezept für eine Katastrophe. Du kannst ihre Antworten nicht kontrollieren, was zu wirklich schlechten Kundenerlebnissen führen kann. | Bestehe darauf, die Kontrolle zu haben. Mit eesel AI entscheidest du genau, welche Tickets automatisiert werden, und kannst die Persönlichkeit, die Aktionen und das Wissen der KI feinabstimmen. |
Warum Vortrainingsdaten die Grundlage für eine großartige Support-KI sind
Deine Daten für eine KI vorzubereiten ist also keine komplexe technische Aufgabe, die nur Datenwissenschaftlern vorbehalten ist. Es geht eigentlich darum, das Wissen, das du bereits hast, zu nehmen und zu organisieren.
Sobald du den Unterschied zwischen den allgemeinen „Buchkenntnissen“ einer KI und ihrem spezifischen „Job-Training“ verstanden hast, kannst du dich auf das Wesentliche konzentrieren: dein Wissen zu überprüfen und ein Tool auszuwählen, das von deinem einzigartigen Unternehmen lernt. Am Ende des Tages ist die beste Support-KI die, die ein Experte für dein Unternehmen ist. Und diese Expertise muss aus deinen Daten stammen.
Starte mit einer KI, die von dir lernt
Bereit zu sehen, was eine KI, die auf deinem eigenen Wissen trainiert wurde, tatsächlich leisten kann? eesel AI verbindet sich in wenigen Minuten mit deinem Helpdesk und anderen Tools.
Du kannst sofort eine Simulation mit deinen vergangenen Tickets durchführen, um zu sehen, wie sie abgeschnitten hätte – ohne Wartezeit und ohne Verpflichtung.
Melde dich für eine kostenlose Testversion an und überzeuge dich selbst.
Häufig gestellte Fragen
[Anforderungen an Vortrainingsdaten](https://openai.com/research/requirements-for-pretraining-data) beziehen sich auf die notwendigen Informationen und Kenntnisse, die eine Support-KI lernen muss, bevor sie Kunden effektiv unterstützen kann. Es geht darum, die vorhandenen Wissensquellen deines Unternehmens zu organisieren, um der KI das grundlegende Verständnis für dein Geschäft zu vermitteln.
Ja, Support-Teams spielen eine entscheidende Rolle beim Verständnis dieser Anforderungen, da sie die Experten für Kundeninteraktionen und Unternehmenswissen sind. Du musst kein Programmierer sein; es geht vielmehr darum, die Daten zu identifizieren und zu organisieren, die dein Team bereits täglich verwendet.
Du solltest Daten aus deinem Helpdesk, der offiziellen Wissensdatenbank und interner Dokumentation wie Wikis oder geteilten Laufwerken sammeln. Diese Quellen liefern die realen Kundeninteraktionen und unternehmensspezifischen Informationen, die die KI benötigt.
Die Überprüfung stellt sicher, dass du alle vorhandenen Wissensquellen erfasst, während die Qualitätsbewertung prüft, ob die Daten aktuell und konsistent sind und häufige Fragen abdecken. [Hochwertige, vielfältige Informationen sind wichtiger](https://docs.aws.amazon.com/bedrock/latest/userguide/model-customization-prepare.html) für die Leistung der KI als nur ein großes Datenvolumen.
Vermeide es, dich ausschließlich auf generische KI-Modelle zu verlassen, denen der unternehmensspezifische Kontext fehlt. Meide außerdem Tools, die einen kompletten Austausch deines bestehenden Helpdesks erzwingen oder dir keine Kontrolle über die Antworten der KI geben.
Obwohl ideale Daten aktuell und sauber sind, können [moderne KI-Tools](https://www.eesel.ai/de/blog/ai-assistant-capabilities) dabei helfen, Lücken zu identifizieren und Verbesserungen vorzuschlagen. Der Überprüfungsprozess hilft dabei, veraltete oder inkonsistente Informationen aufzuspüren, sodass du Aktualisierungen priorisieren oder Tools verwenden kannst, die vielfältige Daten intelligent verarbeiten können.
Share this article

Article by
Kenneth Pangan
Writer and marketer for over ten years, Kenneth Pangan splits his time between history, politics, and art with plenty of interruptions from his dogs demanding attention.
