
Provavelmente já ouviu o velho mantra da tecnologia: "Lixo Entra, Lixo Sai." É uma ideia simples: dados de entrada maus levam a resultados maus. E, honestamente, nunca foi tão relevante como com a IA de hoje. O desempenho de um agente de suporte de IA depende inteiramente dos dados com que aprende.
No entanto, muitas equipas ainda não têm bem a certeza do que são "bons dados" para uma IA. A expressão "requisitos de dados de pré-treino" soa a algo saído de um manual de engenharia, mas na verdade, trata-se apenas de arrumar a casa antes de trazer uma IA para ajudar. Se a sua IA não tiver a informação certa para começar, não será de grande ajuda para os seus clientes.
Neste guia, vamos simplificar a terminologia e mostrar-lhe como preparar o conhecimento existente da sua empresa para construir uma IA de suporte que realmente resolve problemas.
O que vai precisar para preparar os seus dados para uma IA de suporte
Vamos esclarecer uma coisa: não precisa de ser um programador ou de contratar uma equipa de cientistas de dados para se preparar para uma IA de suporte. Trata-se de analisar a informação e os recursos que a sua equipa já utiliza todos os dias. Pense nisto como uma verificação do inventário de conhecimento.
Provavelmente vai querer ter estas coisas à mão:
-
Acesso ao seu helpdesk: É aqui que acontecem as verdadeiras conversas com os clientes, seja no Zendesk, Freshdesk ou outra plataforma.
-
A sua base de conhecimento oficial: O centro de ajuda público ou as páginas de FAQ que os seus clientes veem.
-
Documentação interna: Todos os wikis, guias e documentos nos quais os seus agentes confiam, como conteúdo no Confluence, Google Docs, Notion ou até PDFs.
-
Um objetivo inicial: Qual é a primeira coisa que quer que a IA trate? Talvez seja apenas a reposição de palavras-passe ou perguntas comuns sobre preços. Ter um primeiro objetivo claro mantém as coisas focadas.
Como preparar os seus dados para uma IA de suporte de classe mundial
Passo 1: Compreender os dois tipos de treino de IA
Para ter uma ideia real dos requisitos de dados de pré-treino, ajuda pensar em como uma IA aprende em duas fases, um pouco como um novo membro da equipa. Primeiro, há a sua educação geral, e depois há o treino específico no trabalho que lhe dá.
Este é o "conhecimento teórico" da IA. Os grandes modelos de linguagem (LLMs) aprendem o básico lendo uma grande parte da internet, de fontes como Common Crawl ou C4. Isto dá ao modelo um vocabulário massivo e uma compreensão geral de como a linguagem funciona. É assim que a IA aprende a escrever uma frase coerente.
O problema é que este conhecimento geral tem alguns grandes pontos cegos para o suporte ao cliente:
-
A informação é geralmente notícia velha. Os dados com que estes modelos são treinados podem estar desatualizados há anos. Um estudo de 2024, "A Pretrainer’s Guide to Training Data," confirmou que o desempenho cai quando há um desfasamento temporal entre os dados e as perguntas. Uma IA treinada na internet do ano passado não saberá sobre a sua funcionalidade mais recente ou a nova política de devoluções que acabou de lançar.
-
É completamente genérico. Um LLM geral pode dizer-lhe a capital de França, mas não sabe absolutamente nada sobre os seus produtos, os seus clientes ou a voz da sua empresa. Não tem qualquer contexto para dar uma resposta útil e precisa.
-
Pode ser um risco. Estes conjuntos de dados gigantes podem estar cheios de preconceitos, conteúdo tóxico ou informação privada. Estudos têm apontado para os riscos de privacidade e legais porque não quer que o seu bot diga informações estranhas, tendenciosas ou simplesmente erradas que apanhou de algum canto esquecido da web.
Treino específico da empresa (fine-tuning)
Este é o treino "no trabalho", e francamente, é a parte que realmente importa para uma IA de suporte. É aqui que o modelo aprende os detalhes do seu negócio. Uma IA que salta este passo é como um novo funcionário que atirou para os telefones sem qualquer formação; podem parecer confiantes, mas na verdade não conseguem resolver nada.
É aqui que ferramentas construídas especificamente para suporte, como a eesel AI, realmente fazem a diferença. Foi projetada para se conectar diretamente às suas fontes de conhecimento únicas, tickets passados, artigos de ajuda, guias internos, para se tornar um especialista no seu negócio, não apenas um chatbot genérico.
Passo 2: Audite as suas fontes de conhecimento existentes
Ok, então o conhecimento específico da sua empresa é fundamental. O próximo passo lógico é descobrir onde está tudo. Pense na sua própria equipa por um minuto: onde vão quando precisam de uma resposta?
Comece a fazer uma lista rápida. Terá as coisas óbvias como o seu helpdesk e a base de conhecimento, mas não se esqueça dos tesouros escondidos. Pense em pastas partilhadas do Google Drive, naquele canal do Slack realmente útil, ou nos documentos de produto enterrados no Confluence.
Enquanto faz isso, tente identificar a "fonte da verdade" para diferentes tópicos. Provavelmente encontrará algumas informações contraditórias, e tudo bem. Encontrá-las é o primeiro passo para as corrigir.
Se isto parece muito trabalho, não está errado. É por isso que tentar reunir manualmente toda esta informação num só lugar é uma grande dor de cabeça. Uma maneira muito mais fácil é usar uma ferramenta que se conecta a tudo onde já existe. Por exemplo, a eesel AI tem integrações de um clique que reúnem todas estas fontes, criando um cérebro unificado para a sua IA sem que tenha de executar um projeto massivo de migração de conteúdo.

Passo 3: Avalie a qualidade e a cobertura dos seus dados
Assim que tiver um mapa do seu conhecimento, é hora de uma verificação de qualidade. Acontece que ter informação de alta qualidade e variada é muito mais importante para uma IA do que apenas ter uma tonelada dela. O estudo "Pretrainer's Guide" até descobriu que uma mistura de diferentes fontes, como páginas web e documentos estruturados, resulta num modelo mais inteligente.
Aqui estão algumas perguntas a fazer sobre os seus próprios dados:
-
Estão atualizados? Ou os seus artigos de ajuda estão a acumular poeira digital? Informação desatualizada é uma das principais razões pelas quais as IAs dão más respostas.
-
Cobre o básico? A sua documentação responde realmente às perguntas mais comuns dos seus clientes? Ou muita dessa informação é apenas "conhecimento tribal" que vive na cabeça dos seus agentes?
-
É consistente? As suas macros do helpdesk dizem o mesmo que os seus guias internos? Se não, vai confundir a sua IA tanto quanto confundiria um novo agente.
-
Está limpo? Pense nos seus tickets de suporte passados. São uma mina de ouro de soluções claras, ou estão cheios de conversas de um lado para o outro e becos sem saída?
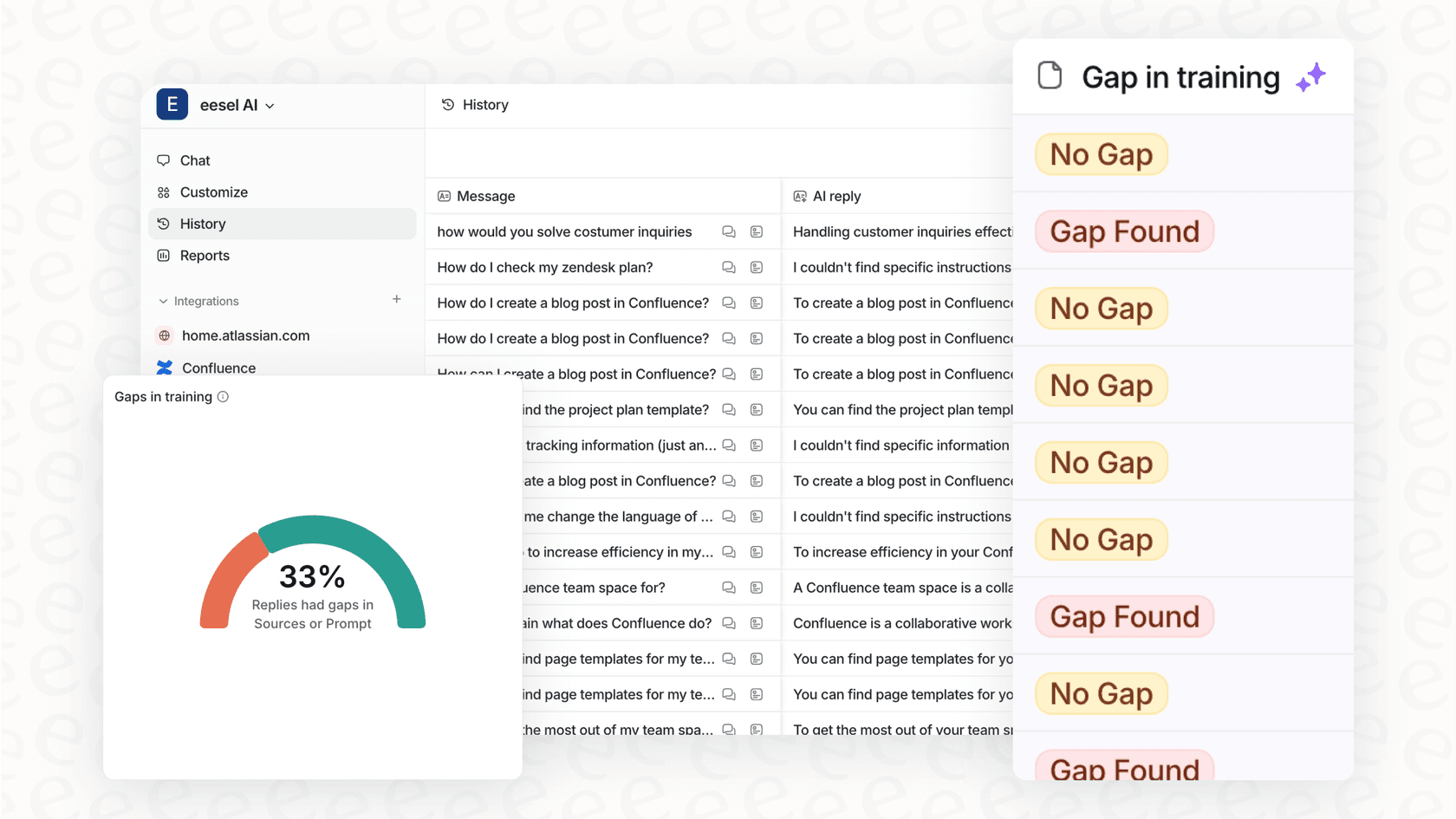
Passo 4: Teste e simule antes de entrar em produção
Nunca lançaria uma nova funcionalidade sem a testar, certo? A mesma lógica aplica-se à sua IA de suporte. Precisa de saber que vai fazer um bom trabalho antes de a deixar falar com um único cliente.
É aí que entra a simulação. Uma boa simulação não é apenas uma demonstração rápida. É um teste de stress completo onde a IA é executada contra milhares dos seus tickets de suporte reais passados. Isto mostra-lhe exatamente:
-
Como a IA teria respondido a problemas reais de clientes.
-
Quantos tickets poderia ter resolvido sozinha.
-
Quais questões teria sinalizado corretamente para um agente humano.
Todo este processo elimina as suposições e dá-lhe uma ideia realista do ROI antes de se comprometer com qualquer coisa.
Isto é algo em que realmente nos focámos na eesel AI. Muitas ferramentas dão-lhe uma demonstração limitada e depois tem de cruzar os dedos e entrar em produção. Nós construímos um modo de simulação que lhe permite ver precisamente como a IA se vai comportar com os seus dados, no seu ambiente. Pode brincar com as configurações, adicionar ou remover fontes de conhecimento, e afiná-la num ambiente seguro, para que possa lançá-la sabendo que está pronta para começar.

Erros comuns a evitar
Compreender os requisitos de dados de pré-treino também o ajuda a identificar potenciais sinais de alerta quando está a analisar diferentes ferramentas de IA. Aqui estão algumas armadilhas comuns a ter em atenção.
| Erro | Porque é um problema | A abordagem melhor |
|---|---|---|
| Confiar numa IA genérica | Fica com uma IA que não sabe nada sobre o seu negócio. É mais provável que dê respostas erradas, desalinhadas com a marca ou até mesmo perigosas. | Escolha uma plataforma que seja construída para treinar com os seus tickets e documentos específicos do helpdesk desde o início. |
| Cair num "arrancar e substituir" | Ser forçado a mudar de helpdesk apenas para ter uma funcionalidade de IA é uma dor de cabeça massiva e cara para a sua equipa. | Procure uma ferramenta que se encaixe diretamente no seu fluxo de trabalho atual. A eesel AI oferece integrações de um clique para plataformas como Zendesk e Freshdesk. |
| Abdicar do controlo | Uma IA de "caixa-preta" que automatiza coisas sem a sua supervisão é uma receita para o desastre. Não consegue controlar as suas respostas, o que pode levar a experiências de cliente muito más. | Insista em ter controlo. Com a eesel AI, você decide exatamente quais tickets são automatizados e pode afinar a personalidade da IA, as suas ações e o que lhe é permitido saber. |
Recurso 1: [screenshot] , Uma captura de ecrã do painel da eesel AI mostrando as regras de personalização para o agente de IA, destacando o controlo do utilizador.
Porque os dados de pré-treino são a base para uma excelente IA de suporte
Então, preparar os seus dados para uma IA não é uma tarefa técnica complexa reservada a cientistas de dados. Trata-se, na verdade, de pegar no conhecimento que já tem e organizá-lo.
Assim que compreender a diferença entre o "conhecimento teórico" geral de uma IA e o seu "treino de trabalho" específico, pode focar-se no que importa: auditar o seu conhecimento e escolher uma ferramenta que aprenda com o seu negócio único. No final do dia, a melhor IA de suporte é aquela que é especialista na sua empresa. E essa especialização tem de vir dos seus dados.
Comece com uma IA que aprende consigo
Pronto para ver o que uma IA treinada no seu próprio conhecimento pode realmente fazer? A eesel AI conecta-se ao seu helpdesk e outras ferramentas em minutos.
Pode executar uma simulação nos seus tickets passados imediatamente para ver como se teria comportado, sem esperas e sem compromisso.
Inscreva-se para um teste gratuito e veja por si mesmo.
Perguntas frequentes
Os [requisitos de dados de pré-treino](https://openai.com/research/requirements-for-pretraining-data) referem-se à informação e conhecimento necessários que uma IA de suporte precisa de aprender antes de poder assistir eficazmente os clientes. Trata-se de organizar as fontes de conhecimento existentes da sua empresa para fornecer à IA a compreensão fundamental do seu negócio.
Sim, as equipas de suporte desempenham um papel crucial na compreensão destes requisitos porque são os especialistas nas interações com os clientes e no conhecimento da empresa. Não precisa de ser um programador; trata-se mais de identificar e organizar os dados que a sua equipa já usa diariamente.
Deve recolher dados do seu helpdesk, da base de conhecimento oficial e da documentação interna, como wikis ou unidades partilhadas. Estas fontes fornecem as interações reais com clientes e a informação específica da empresa de que a IA necessita.
A auditoria garante que mapeia todas as fontes de conhecimento existentes, enquanto a avaliação da qualidade verifica se os dados estão atualizados, são consistentes e cobrem as perguntas comuns. [Informação variada e de alta qualidade é mais importante](https://docs.aws.amazon.com/bedrock/latest/userguide/model-customization-prepare.html) para o desempenho da IA do que apenas um grande volume de dados.
Evite depender apenas de modelos de IA genéricos, que não têm contexto específico da empresa. Além disso, evite ferramentas que forcem a "substituição total" do seu helpdesk existente, ou aquelas que não lhe dão controlo sobre as respostas da IA.
Embora os dados ideais sejam atualizados e limpos, as [ferramentas de IA modernas](https://www.eesel.ai/pt/blog/ai-assistant-capabilities) podem ajudar a identificar lacunas e sugerir melhorias. O processo de auditoria ajuda a identificar informações desatualizadas ou inconsistentes, permitindo-lhe priorizar atualizações ou usar ferramentas que podem processar dados variados de forma inteligente.
Share this article

Article by
Kenneth Pangan
Writer and marketer for over ten years, Kenneth Pangan splits his time between history, politics, and art with plenty of interruptions from his dogs demanding attention.