チームを拡大せずにカスタマーサポート(kasutamasapōto)を拡張することは、運用における最も困難な課題の1つです。エージェント(ējento)はすでにチケット(chiketto)の対応に追われており、新しい従業員を採用するたびに間接費が増加します。しかし、ナレッジベース(narejjibēsu)がチケット(chiketto)になる前に質問に答えることができたらどうでしょうか?
Jira AIナレッジベース(narejjibēsu)はまさにそれを行います。Jira Service ManagementとAtlassian Intelligence(アトラシアンインテリジェンス)を組み合わせることで、顧客はドキュメント(dokyumento)から直接取得した正確な回答を即座に得ることができます。コーディング(kōdingu)は不要です。複雑な設定も不要です。ナレッジベース(narejjibēsu)を接続し、AIにルーチン(rūtin)の質問を処理させます。
このガイド(gaido)では、Jira AIナレッジベース(narejjibēsu)のセットアップ(settoappu)と最適化について説明します。まず、Atlassianのネイティブ(neitibu)機能から始め、eesel AIのようなツール(tsūru)が、より柔軟性が必要な場合にこれらの機能をどのように拡張できるかを見ていきます。

Jira AIナレッジベース(narejjibēsu)とは?
Jira AIナレッジベース(narejjibēsu)は、ドキュメント(dokyumento)を読み取り、顧客の質問に自動的に回答するAI搭載システム(AI tōsai shisutemu)です。チケット(chiketto)を送信してエージェント(ējento)を待つ代わりに、顧客は既存のヘルプ記事に基づいて即座に応答を得られます。
仕組みは次のとおりです。バーチャルサービスエージェント(bācharu sābisu ējento)は、リンク(rinku)されたConfluenceスペース(supēsu)をスキャン(sukan)し、関連する記事を見つけ、生成AI(seisei AI)を使用して、会話形式で情報を要約します。顧客が「パスワード(pasuwādo)をリセット(risetto)するにはどうすればよいですか?」と質問すると、AIがパスワード(pasuwādo)リセット(risetto)の記事から回答を取得し、即座に配信します。
システム(shisutemu)には3つのコア(koa)コンポーネント(konpōnento)があります。
- バーチャルサービスエージェント(bācharu sābisu ējento) Slack、メール(mēru)、およびヘルプセンター(herupusentā)全体で顧客との会話を行うAIインターフェース(AI intāfēsu)
- AIによる回答 ナレッジベース(narejjibēsu)を検索して要約する生成機能
- Confluenceナレッジベース(narejjibēsu) AIに情報を提供するソースコンテンツ(sōsu kontentsu)(ただし、Jiraのネイティブ(neitibu)ナレッジベース(narejjibēsu)も使用できます)
メリット(meritto)は簡単です。顧客は24時間年中無休で即座に応答を得られます。チームは、一般的な質問に対するチケット(chiketto)の量を減らすことができます。また、AIは承認されたドキュメント(dokyumento)のみを使用するため、共有する情報を正確に制御できます。
この設定は、ITチーム(IT chīmu)、人事部、およびJira Service Managementを使用して、反復的な質問を処理するグループ(gurūpu)に最適です。パスワード(pasuwādo)のリセット(risetto)、ソフトウェア(sofutowea)アクセス要求、ポリシー(porishī)に関する質問など、エージェント(ējento)の時間を費やすものの、人間の判断を必要としないルーチン(rūtin)の作業に適しています。
AIによる回答のためにナレッジベース(narejjibēsu)をセットアップ(settoappu)する
すでにドキュメント(dokyumento)がある場合、開始には約30分かかります。手順は次のとおりです。
ステップ(suteppu)1:ConfluenceをJira Service Managementに接続する
まず、AIが検索するナレッジベース(narejjibēsu)が必要です。すでにConfluenceを使用している場合は、既存のスペース(supēsu)をリンク(rinku)できます。そうでない場合は、作成します。
Jira Service Managementプロジェクト(purojekuto)に移動し、サイドバー(saido bā)から[プロジェクト設定]を選択します。メニュー(menyū)で[ナレッジベース(narejjibēsu)]を見つけます。そこから、新しいConfluenceスペース(supēsu)を作成するか、既存のスペース(supēsu)をリンク(rinku)できます。セットアップ(settoappu)はほとんどワンクリック(wan kurikku)です。Atlassianが2つの製品間の接続を処理します。
1つの重要な設定:リンク(rinku)されたナレッジベース(narejjibēsu)スペース(supēsu)が、[表示できるユーザー]で[ログインしているすべてのユーザー]に設定されていることを確認してください。権限が厳しすぎる場合、AIは記事を読めません。Atlassianのドキュメント(dokyumento)で、ナレッジベース(narejjibēsu)の権限の管理について詳しく学ぶことができます。
ステップ(suteppu)2:ナレッジベース(narejjibēsu)の記事を構造化する
AIによる回答の質は、ソースマテリアル(sōsu materiāru)の質に完全に依存します。Atlassianは、AIが効果的に解析できるコンテンツ(kontentsu)を構造化するための具体的なガイドライン(gaidorain)を提供しています。
顧客が実際に検索するものと一致する、明確で説明的なタイトル(taitoru)を使用します。太字のテキスト(tekisuto)だけでなく、適切な見出し(H1、H2、H3)を使用して記事を整理します。顧客が使用する語彙を含めます。たとえば、「ラップトップ(raputoppu)」を要求する場合は、ハードウェア(hādo wea)要求の記事で「ポータブル(pōtaburu)コンピューティングデバイス(konpyūtingu debaisu)」だけでなく、その単語を使用します。
重複を避けるために、トピック(topikku)ごとに1つの記事にしてください。同じVPN設定プロセス(settei purosesu)を説明する2つの記事がある場合、AIは古い記事から取得する可能性があります。別の記事の手順を参照する必要がある場合は、コンテンツ(kontentsu)をコピー(kopī)するのではなく、リンク(rinku)します。
注意すべき技術的な制限事項が1つあります。AIによる回答は、テーブル(tēburu)、展開パネル(tenkai paneru)、および情報パネル(jōhō paneru)から情報を読み取ることができますが、テーブル(tēburu)内に配置されたパネル(paneru)からは読み取ることができません。それに応じてコンテンツ(kontentsu)を構造化します。
ステップ(suteppu)3:バーチャルサービスエージェント(bācharu sābisu ējento)でAIによる回答をアクティブ(akutibu)にする
ナレッジベース(narejjibēsu)が接続され、入力されると、AIをオン(on)にする時が来ました。
サービスプロジェクト(sābisu purojekuto)から、[プロジェクト設定]を選択し、[チャネル(chaneru)とセルフサービス(serufusābisu)]の下にある左側のパネル(paneru)で[バーチャルサービスエージェント(bācharu sābisu ējento)]を見つけます。[AIによる回答]タブ(tabu)を選択し、トグル(toguru)をオン(on)にして、[アクティブ(akutibu)]を選択します。AIは、接続されているすべてのチャネル(chaneru)ですぐに動作を開始します。
Slackを使用している場合は、すべてのリクエストチャネル(ri kuesuto chaneru)ではなく、特定のリクエストチャネル(ri kuesuto chaneru)に対してAIによる回答をアクティブ(akutibu)にできます。[設定]で[リクエストチャネル(ri kuesuto chaneru)]に移動し、有効にするチャネル(chaneru)の横にある[AIによる回答]の下にあるトグル(toguru)をオン(on)にします。
AIのためにKB記事を最適化するためのベストプラクティス(besuto purakutisu)
AIのセットアップ(settoappu)は、戦いの半分にすぎません。良い結果を得るには、AIがどのように読み取り、解釈するかに合わせてコンテンツ(kontentsu)を最適化する必要があります。
顧客の語彙で書く
これは、チームが犯す最も一般的な間違いです。内部用語を使用して記事を作成しますが、顧客は独自の言葉を使用して検索します。
新しいハードウェア(hādo wea)を要求する記事がある場合は、「ハードウェア(hādo wea)調達ワークフロー(chōtatsu wāku furō)」というタイトル(taitoru)だけにしないでください。記事本文に「新しいラップトップ(raputoppu)が必要です」や「キーボード(kībōdo)を要求する」などのフレーズ(furēzu)を含めます。人々が実際に会話でどのように助けを求めているかを考え、それらの正確なフレーズ(furēzu)を含めます。
AIは、顧客のクエリ(kueri)を記事のコンテンツ(kontentsu)と照合します。単語が一致しない場合、AIは適切な記事を見つけられません。
コンテンツ(kontentsu)を最新の状態に保ち、正確にする
AIによる回答が正しくない最も一般的な理由は、古いソースマテリアル(sōsu materiāru)です。パスワード(pasuwādo)のリセット(risetto)プロセス(purosesu)が3か月前に変更されたのに、記事がまだ古い方法を説明している場合、AIは自信を持って顧客に間違った指示を与えます。
最もアクセスされた記事を四半期ごとに確認するためのカレンダー(karendā)リマインダー(rimaindā)を設定します。あいまいまたは矛盾する情報を削除します。ポリシー(porishī)が変更された場合は、すぐに記事を更新します。次の定期的なレビュー(rebyū)を待たないでください。
読みやすさとAI解析のために構造化する
組織は、書式設定の才能よりも重要です。すべてを1つの長いページに詰め込むのではなく、異なるトピック(topikku)には異なる記事を使用します。Mac、Windows、およびAndroid用のVPN設定手順がある場合は、それぞれに個別の記事を作成するか、デバイス(debaisu)ごとに手順を区切る明確な見出しを使用します。
トピック(topikku)ごとに完全な手順を記述します。記事間でリンク(rinku)している場合を除き、手順を複数の記事に分割しないでください。AIは、1か所で完全な回答を見つけることができる場合に最適に機能します。
もう1つの技術的な注意点:画像は人間の読者にとっては役立ちますが、AIによる回答は現在、画像から情報を抽出していません。重要な情報をテキスト(tekisuto)で入力し、スクリーンショット(sukurīn shotto)では入力しないでください。
Confluence AI連携は、ネイティブ(neitibu)機能を超えてこれらの機能を拡張したいチームを支援できます。
AIによる回答を超えるネイティブ(neitibu)AI機能
Atlassianは、バーチャルサービスエージェント(bācharu sābisu ējento)を超えて、いくつかのAI機能をJira Service Managementに組み込んでいます。これらの機能は、より良いコンテンツ(kontentsu)を作成し、ナレッジベース(narejjibēsu)をより効果的に管理するのに役立ちます。
ナレッジベース(narejjibēsu)の記事のAI編集
サポートチケット(sapōto chiketto)を解決すると、その解決策はキャプチャ(kyapucha)する必要がある貴重な知識になります。AI編集機能を使用すると、Jiraの問題から直接記事を作成できます。
任意のチケット(chiketto)から、AIを使用して新しい記事のコンテンツ(kontentsu)をブレインストーミング(bureinsutōmingu)したり、文章の質を向上させたり、スペル(superu)や文法を修正したり、トーン(tōn)を変更したりできます。使用可能なトーン(tōn)には、カジュアル(kajuaru)、教育的、共感的、中立的、および専門的が含まれます。これにより、特定のチケット(chiketto)の解決策を、チームの声に合った洗練されたヘルプ記事にすばやく変換できます。
AIドラフト(dorafuto)と推奨トピック(topikku)
次にどのような記事を書くかを推測するのではなく、AIに教えてもらいましょう。推奨トピック(topikku)機能は、最近の顧客のリクエスト(ri kuesuto)を分析し、ナレッジベース(narejjibēsu)のギャップ(gyappu)を特定します。
サービスプロジェクト(sābisu purojekuto)から、[ナレッジベース(narejjibēsu)]に移動し、[推奨トピック(topikku)]を選択します。対応する記事がないリクエストトピック(ri kuesuto topikku)のリスト(risuto)と、それぞれに関連するリクエスト(ri kuesuto)の数が表示されます。これにより、仮定ではなく、実際の顧客のニーズ(nīzu)に基づいてコンテンツ(kontentsu)の作成を優先順位付けできます。
Smarts対応ヘルプセンター(herupusentā)検索
顧客がAIエージェント(ējento)とやり取りする前でも、機械学習(kikai gakushū)がバックグラウンド(bakkuguraundo)で動作しています。ヘルプセンター(herupusentā)検索では、データ(dēta)駆動型アルゴリズム(arugorizumu)を使用して、顧客が入力するときに関連する記事を推奨します。
システム(shisutemu)は、時間の経過とともにユーザー(yūzā)の行動から学習し、以前のユーザー(yūzā)が役立つと判断したことに基づいて予測を改善します。これは、検索が顧客の使用量が多いほどスマート(sumāto)になり、顧客が質問の入力を完了する前に適切な記事を表示することを意味します。
ネイティブ(neitibu)AIを超える拡張を検討する時期
Atlassianのネイティブ(neitibu)AI機能は多くのチームでうまく機能しますが、制限があります。これらの境界を理解することで、ネイティブ(neitibu)機能を使用するか、サードパーティ(sādo pāti)のオプション(opushon)を検討するかを決定するのに役立ちます。
バーチャルサービスエージェント(bācharu sābisu ējento)は、Confluenceナレッジベース(narejjibēsu)を中心に設計されています。Googleドキュメント(dokyumento)、Notion、SharePoint、またはチームが使用する可能性のある他のプラットフォーム(purattofōmu)に保存されている情報にアクセスできません。また、過去のチケット(chiketto)のコンテキスト(kontekusuto)から学習することもありません。現在のドキュメント(dokyumento)にあるものだけを認識します。
次の場合、ネイティブ(neitibu)AI以上のものが必要になる可能性があります。
- 知識がConfluenceだけでなく、複数のプラットフォーム(purattofōmu)に分散している
- AIに質問に答えるだけでなく、アクション(akushon)(チケット(chiketto)のタグ付けやAPI呼び出しなど)を実行させたい
- 顧客とライブ(raibu)になる前に、過去のチケット(chiketto)でAIのパフォーマンス(pafōmansu)をテスト(tesuto)する必要がある
- AIに公開された記事だけでなく、過去のチケット(chiketto)の解決策から学習させたい
Jira Service Management AI連携は、これらの制限に達しているチーム向けに構築されています。
eesel AIがJiraのAIナレッジベース(narejjibēsu)機能をどのように拡張するか
ネイティブ(neitibu)のAtlassian AIでできることを最大限に活用したら、eesel AIは、既存のセットアップ(settoappu)を置き換えるのではなく、それを基に構築する道を提供します。

コア(koa)の違いは範囲です。AtlassianのAIはAtlassianエコシステム(ekoshisutemu)内で動作しますが、eeselはすべてに接続します。Confluence、Googleドキュメント(dokyumento)、Notion、SharePoint、過去のサポートチケット(sapōto chiketto)、Slackでの会話など、eeselは知識がどこにあっても統合します。これは、チームがさまざまなツール(tsūru)にドキュメント(dokyumento)を分散させている場合に重要です。これは、ほとんどの組織の現実です。
Eeselはまた、ネイティブ(neitibu)AIが提供しないシミュレーション(shimyurēshon)モード(mōdo)を提供します。顧客に展開する前に、過去の数千枚のチケット(chiketto)に対してAIエージェント(ējento)を実行して、どのように応答したかを正確に確認できます。これにより、知識のギャップ(gyappu)を特定し、顧客に影響を与えることなく動作を調整できます。顧客に公開する前に、eeselがどのように機能するかを確認できます。
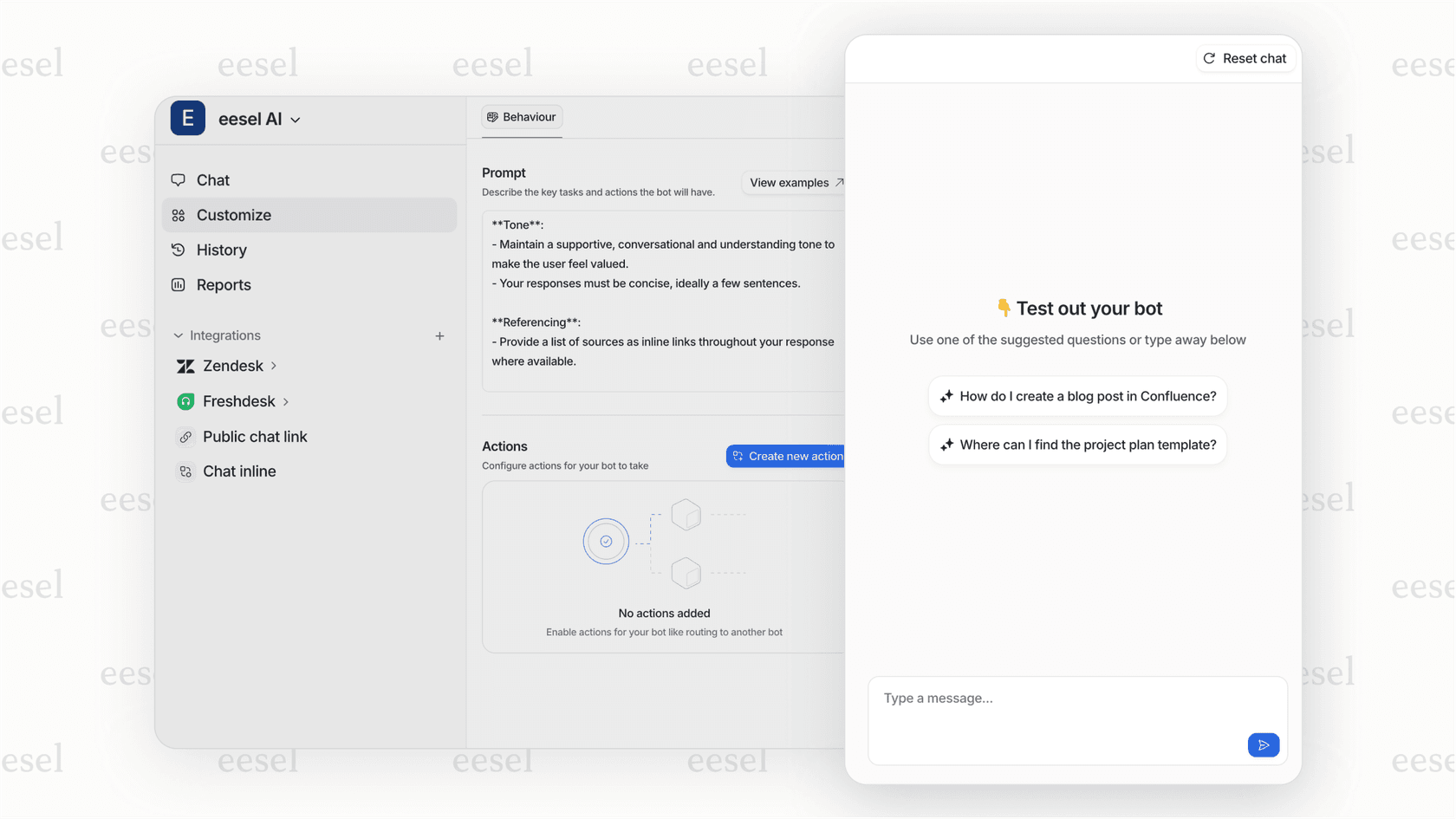
カスタマイズ(kasutamaizu)は、コード(kōdo)ではなく、わかりやすい英語で行われます。自然言語の指示を使用して、エスカレーション(esukarēshon)ルール(rūru)、応答トーン(ōtōn)、および許可されるアクション(akushon)を定義します。「払い戻し要求が30日を超える場合は、丁寧に拒否し、ストアクレジット(sutoa kurejitto)を提供します。」構成ウィザード(kōsei wizādo)も、決定木もありません。
ロールアウト(rōru auto)は、オールオアナッシング(ōru oa nasshingu)ではなく、段階的です。まず、eeselがエージェント(ējento)がレビュー(rebyū)するための返信を作成することから始めます。品質に自信がついたら、特定のチケット(chiketto)タイプ(taipu)の自律的な処理に拡張します。最終的に、eeselは、定義したエッジケース(ejji kēsu)のみをエスカレーション(esukarēshon)して、完全なフロントライン(furonto rain)サポート(sapōto)を管理できます。
質問に答えるだけでなく、eeselは実際のアクション(akushon)を実行します。チケット(chiketto)のタグ付け、フィールド(fīrudo)の更新、他のシステム(shisutemu)へのAPI呼び出し、顧客データの検索を行います。Zendesk、Freshdesk、Gorgiasなどのプラットフォーム(purattofōmu)と統合して、Jiraを超えて拡張する必要がある場合に備えます。
AIエージェント(ējento)機能の詳細については、ITチーム向けのAIサービスデスク(sābisu desuku)ソリューション(soryūshon)をご覧ください。
Jira AIナレッジベース(narejjibēsu)を使い始める
最良のアプローチ(apurōchi)は、簡単に始めて、結果に基づいて拡張することです。
Atlassianのネイティブ(neitibu)AI機能から始めます。Confluenceナレッジベース(narejjibēsu)を接続し、AIによる回答をアクティブ(akutibu)にし、最初のドキュメント(dokyumento)の取り組みを最も一般的な5〜10個のサポートトピック(sapōto topikku)に集中させます。これらは通常、パスワード(pasuwādo)のリセット(risetto)、ソフトウェア(sofutowea)アクセス要求、および基本的なポリシー(porishī)に関する質問です。
偏向率と顧客からのフィードバック(fīdobakku)を監視します。顧客は必要な回答を見つけていますか?どこで行き詰まっていますか?このデータ(dēta)を使用して、次に改善または作成する記事の優先順位を付けます。
ナレッジベース(narejjibēsu)が成熟し、ネイティブ(neitibu)AIの制限に達したら、サードパーティ(sādo pāti)のソリューション(soryūshon)を評価する価値があります。目標は、Atlassianのセットアップ(settoappu)を置き換えることではありません。Atlassianがネイティブ(neitibu)に提供するもの以上の機能が必要な場合に、それを拡張することです。
AIナレッジベース(narejjibēsu)から最大の価値を得るチームは、それらを生きたシステム(shisutemu)として扱います。セットアップ(settoappu)して忘れるだけではありません。実際の使用状況データ(dēta)に基づいて継続的に改善し、実際に質問される質問の範囲を拡大します。





