ほとんどのサポートチームは、口に出さない問題を抱えています。それは、ナレッジベースが時代遅れのアーティクルの墓場と化し、優秀なエージェントが、すでに存在するドキュメントで答えられるはずの反復的な質問に溺れていることです。
ナレッジベースでAI(人工知能)をトレーニングすることで、その状況が変わります。顧客が人間によるコピー&ペーストを何時間も待つ代わりに、AIナレッジベースは、既存のコンテンツから得られた正確な回答を即座に提供します。Zendesk(ゼンデスク)の調査によると、69%の顧客は、サポートに連絡するよりも自分で問題を解決することを好みます。問題は、彼らが自分で解決したくないということではありません。従来型のナレッジベースでは、人間(サポート担当者)に質問するよりも回答を見つけるのが難しいということです。
このガイドでは、既存のコンテンツの監査から、顧客の質問を実際に理解するAIのデプロイまで、ナレッジベースでAIをトレーニングする方法を説明します。データサイエンスチームや数ヶ月のセットアップは必要ありません。適切なアプローチを使用すれば、数時間以内にナレッジベースでトレーニングされたAIを導入し、クエリを処理できます。
必要なもの
ナレッジベースでAIのトレーニングを開始する前に、次のものを用意してください。
- 既存のナレッジベースコンテンツ:ヘルプ記事、FAQ(よくある質問)、SOP(標準作業手順書)、製品ドキュメント、その他すでに作成済みのサポートコンテンツ
- 過去のサポートチケットへのアクセス(オプションですが、強く推奨):これにより、AIにチームが実際に顧客とどのように対話するかを教えます
- AIナレッジベースプラットフォーム:ステップ2で選択方法について説明します
- 初期セットアップに1〜2時間:ほとんどはソースの接続とAIの応答の確認です
- コンテンツのメンテナンスに対する継続的な取り組み:AIは「設定して放置」ではありません。製品の進化に合わせて、ナレッジベースを定期的に更新する必要があります
ステップ1:ナレッジベースコンテンツの監査と準備
AIの品質は、トレーニングするコンテンツの品質に直接関係します。AIプラットフォームに接続する前に、時間をかけて整理整頓しましょう。
まず、既存のコンテンツをすべて収集します。これには、ヘルプセンターの記事、PDF、SOP(標準作業手順書)、定型応答、マクロ、およびチームが使用する内部ドキュメントが含まれます。ほとんどの企業は、必要なものの60〜70%をすでに作成しています。それらは、Googleドライブ、Confluence(コンフルエンス)、Notion(ノー ション)、およびさまざまなヘルプデスクシステムに分散しているだけです。
次に、不要なものを削除します。もはや存在しない機能を参照する古い記事を削除します。重複するコンテンツを統合します。5人の異なるエージェントが同じ回避策を5つの異なる方法で文書化した場合、最適なバージョンを保持し、残りをアーカイブします。機密性の高い顧客データや、一般公開を意図していない内部メモをすべて削除します。
残ったものを論理的に整理します。関連するトピックをグループ化します(すべての請求に関する質問を1つの領域に、すべての技術的なセットアップを別の領域に)。人々が実際に質問する方法に一致する明確なタイトルを使用します。「払い戻しをリクエストする方法」は、「払い戻しポリシーのドキュメントv3.2」よりも効果的です。関連する記事間の接続を作成して、AIがコンテキストを理解できるようにします。返品に関する記事は、払い戻しのタイミングに関する記事を参照する必要があります。
ソース資料がよりクリーンで整理されているほど、AIはより速く、より正確に回答を見つけることができます。図書館の整理を考えてみてください。AIはどちらの方法でもすべての本を読むことができます。本が論理的に棚上げされている場合、適切な情報を見つけるのがはるかに速くなります。
ステップ2:AIナレッジベースプラットフォームの選択
すべてのAIナレッジベースプラットフォームが同じように機能するわけではありません。一部は広範な構成と技術的なセットアップが必要です。他のものは既存のツールに接続し、すぐに学習を開始します。Gartner(ガートナー)のカスタマーサービスにおけるAIに関する調査によると、AIナレッジベースを実装する組織は、解決時間と顧客満足度の大幅な改善が見られます。以下に注目すべき点を示します。
プラットフォームを選択するための重要な基準:
- セットアップの容易さ:エンジニアリングリソースなしで、既存のヘルプデスクとナレッジソースを接続できますか?
- 統合機能:すでに使用しているツール(Zendesk(ゼンデスク)、Freshdesk(フレッシュデスク)、Slack(スラック)、Confluence(コンフルエンス)など)と連携しますか?
- 価格の透明性:コストは予測可能ですか、それとも後で驚くような方法でスケールしますか?
- 継続的な学習:AIは、手動で再トレーニングしなくても、修正や新しいコンテンツから改善できますか?
主要なプラットフォームの比較を以下に示します。
| プラットフォーム | 開始価格 | 最適な用途 | 主な制限事項 |
|---|---|---|---|
| eesel AI | 月額299ドル(チーム) | プログレッシブなロールアウトで迅速なセットアップを希望するチーム | チームプランでは月間1,000インタラクション |
| Zendesk AI | エージェントあたり月額55ドル | すでにZendesk(ゼンデスク)エコシステムに組み込まれているチーム | シートごとの価格設定はすぐに高額になる |
| Guru(グル) | ユーザーあたり月額25ドル | 内部知識検索 | 顧客向けのAIエージェントはなし |
| Slite(スライト) | ユーザーあたり月額8ドル | チームコラボレーションとドキュメント | AI機能は限定的 |
Freshdesk(フレッシュデスク)、Gorgias(ゴルジアス)、またはIntercom(インターコム)を使用しているチームの場合、eesel AIは、既存のチケット履歴とヘルプセンターコンテンツから自動的に学習するネイティブ統合を提供します。

**構築対購入の決定:**無制限の予算と専任のAIチームを持つ大規模な企業でない限り、独自のナレッジベースAIをゼロから構築することは意味がありません。McKinsey(マッキンゼー)のAI実装に関する分析によると、ほとんどの企業は、カスタムAI開発に必要な時間とリソースを2〜3倍過小評価しています。既存のプラットフォームがすでにすぐに処理できるものに、12〜18か月と数十万ドルを費やすことになります。
ほとんどのチームがAI企業になりたくないため、eesel AIを構築しました。彼らはヘルプデスクを接続し、既存のデータでトレーニングし、より迅速に顧客を支援したいと考えています。私たちのアプローチでは、AIを複雑なワークフローで構成するツールではなく、採用して時間をかけてレベルアップするチームメイトのように扱います。
ステップ3:AIの接続とトレーニング
プラットフォームを選択したら、実際のトレーニングプロセスは簡単です。仕組みは次のとおりです。
**ナレッジソースを接続します。**ほとんどのプラットフォームでは、複数のソースから同時にインポートできます。ヘルプセンター、Googleドライブ、Confluence(コンフルエンス)、Notion(ノー ション)、PDF、およびその他のドキュメントリポジトリを接続します。過去のサポートチケットにアクセスできる場合は、それらも接続します。これにより、AIにチームが実際に顧客とどのようにコミュニケーションするかを教えます。
**トレーニングプロセスの仕組み。**最新のAIナレッジベースは、Retrieval-Augmented Generation(検索拡張生成)(RAG(ラグ))と呼ばれる手法を使用します。簡単なバージョンを次に示します。AIはすべてのコンテンツをインデックス化し、それを埋め込みと呼ばれる数学的表現に変換し、これらをベクトルデータベースに保存します。顧客が質問をすると、AIはこのデータベースを検索して最も関連性の高いコンテンツを見つけ、そのコンテンツを使用して応答を生成します。これが、AIがドキュメントに表示されない方法で言い換えられた質問に答えることができる理由です。キーワードだけでなく、意味を理解します。RAG(ラグ)とベクトルデータベースとハイブリッド検索アプローチの詳細をご覧ください。
**わかりやすい英語の指示を設定します。**複雑な決定木をプログラミングする代わりに、AIに自然言語でどのように動作させたいかを記述します。「常に丁寧で簡潔にしてください。」「誰かが価格について質問した場合は、価格ページへのリンクを含めてください。」「請求に関する紛争は財務チームにエスカレートしてください。」優れたプラットフォームを使用すると、これらの指示を調整し、結果をすぐに確認できます。
**ライブになる前にテストします。**サンプルクエリをAIで実行し、応答を確認します。チームのように聞こえますか?適切なソースから取得していますか?その知識に明らかなギャップはありますか?顧客に見られる前に、今すぐ修正してください。
eesel AIを使用すると、このプロセス全体に数週間ではなく、数分しかかかりません。ヘルプデスクを接続すると、過去のチケット、ヘルプセンターの記事、およびマクロから自動的に学習します。手動トレーニングは必要ありません。
ステップ4:AIの動作とエスカレーションルールの構成
明確なエスカレーションルールがないAIナレッジベースは、発生を待っている負債です。AIが処理するものと、いつ人間に引き継ぐかを正確に定義する必要があります。
**AIが処理するものとエスカレートするものを定義します。**具体的にしてください。AIは、パスワードのリセット、注文ステータスの検索、および基本的なトラブルシューティングを処理できる可能性があります。法的措置を脅かす怒っている顧客、診断を必要とする複雑な技術的な問題、または手厚い対応が必要なVIPアカウントを処理すべきではありません。
**エスカレーショントリガーを設定します。**AIがその深さに達していないことを認識し、人間に転送するようにAIを構成します。一般的なトリガーには、顧客が明示的に人間を要求する、感情分析が不満を検出する、複雑さを示すキーワード(「訴訟」、「アカウントのキャンセル」、「エグゼクティブエスカレーション」)、またはAI自身の信頼度スコアがしきい値を下回るなどが含まれます。
**トーンとブランドボイスを構成します。**AIは、一般的なチャットボットではなく、チームの拡張のように聞こえるはずです。チームがカジュアルでフレンドリーな場合、AIもそうである必要があります。フォーマルで技術的な場合は、AIもそれに一致する必要があります。ほとんどのプラットフォームでは、プロンプトまたは過去の応答でトレーニングすることにより、トーンをカスタマイズできます。
**営業時間と可用性を設定します。**AIがいつ動作するかを決定します。一部のチームは、即時応答のためにAIを24時間年中無休で実行し、営業時間中に人間がエスカレーションを処理します。他のチームは、AIを営業時間外の対応に制限します。正解はありません。顧客とチームの能力によって異なります。
**エッジケースとフォールバック応答をテストします。**AIを壊そうとしてください。答えられないとわかっている質問をしてください。誰かが意味不明なことを入力したときに何が起こるかを確認してください。フォールバック応答が役立ち、常に人間の助けへの道を提供していることを確認してください。
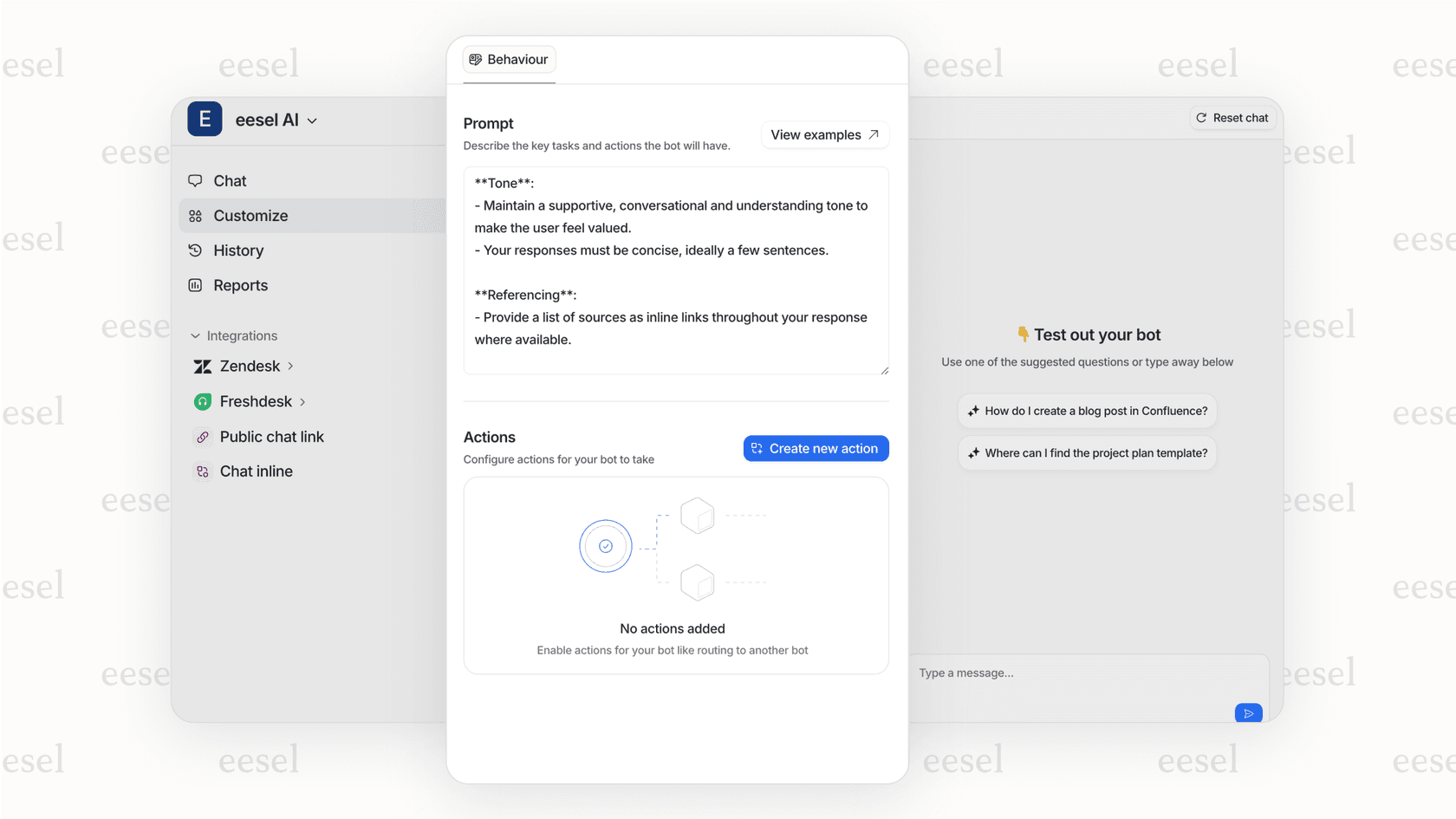
eesel AIでの私たちのアプローチの利点は、これらすべてをわかりやすい英語で定義することです。複雑なワークフロービルダーや決定木はありません。必要なことを記述するだけで、AIが指示に従います。
ステップ5:テスト、デプロイ、および反復
AIナレッジベースをライブにすることは、1回限りのイベントではありません。それは、信頼を構築し、範囲を拡大する段階的なプロセスです。
**過去のチケットでシミュレーションを実行します。**AIに実際の顧客に触れさせる前に、過去のデータでテストします。過去のチケットを数百件取得し、AIで実行し、その応答を人間のエージェントが実際に送信したものと比較します。パターンを探します。特定の種類の質問が一貫して欠落していますか?トーンは適切ですか?答えは正確ですか?
**コパイロットモードから開始します。**ほとんどのチームは、AIが返信を下書きし、送信する前に人間のエージェントが確認することから始めます。これにより、顧客関係を危険にさらすことなく品質を確認できます。エージェントは、応答を編集、承認、または再生成できます。時間をかけて信頼を築き上げたら、特定のチケットタイプについてAIが応答を直接送信できるようにすることができます。AIエージェント支援アプローチの詳細をご覧ください。
**パフォーマンスメトリックを監視します。**重要なメトリックを追跡します。解決率(AIがエスカレーションなしで処理するクエリの割合は?)、精度(回答は正しいですか?)、顧客満足度(顧客はAIインタラクションをどのように評価しますか?)、および節約された時間(AI応答は人間よりもどれだけ速いですか?)。AI搭載のカスタマーサービスに関するForrester(フォレスター)の調査によると、これらの特定のKPI(重要業績評価指標)を追跡している企業は、体系的に測定していない企業よりも40%優れた結果が得られています。
**フィードバックを収集して改善します。**AIが答えられない顧客からの質問に注意してください。これらは埋めるべきコンテンツのギャップです。エージェントによって編集された応答に注目してください。これらはトレーニングの機会です。最高のAIナレッジベースは、実際の使用状況に基づいて継続的に改善されます。
**AIの範囲を徐々に拡大します。**AIがその能力を証明するにつれて、処理するものを拡大します。パスワードのリセットから始まり、注文の検索を追加し、すべての請求に関する質問を処理するかもしれません。「新入社員」から「トップパフォーマーエージェント」への道は、明確かつ管理されている必要があります。
AIサポート自動化に関する業界調査によると、AIナレッジベースを生きているシステムとして扱い、継続的に更新する企業は、チケットの削減を25〜40%持続的に実現しています。起動して無視する企業は、数か月以内に最初の改善が消えるのを見ています。
避けるべき一般的な間違い
何百ものチームがナレッジベースでAIをトレーニングするのを支援した後、私たちは同じ間違いを繰り返し見てきました。注意すべき点は次のとおりです。
-
**古くなったコンテンツまたは重複したコンテンツでトレーニングする。**AIは、与えるものと同じくらい優れています。古いドキュメントは間違った答えを生み出します。競合する情報を含む重複したコンテンツは、AIを混乱させます。
-
**テストフェーズをスキップする。**AIが動作することを確認するまで、顧客に話させないでください。シミュレーションを実行します。サンプル応答を確認します。明らかな失敗を非公開でキャッチします。
-
**非現実的な期待を設定する。**AIはすべてを解決するわけではありません。ルーチンクエリを処理するため、人間のチームは複雑な問題に集中できます。サポートチーム全体を置き換えることを期待すると、がっかりするでしょう。
-
**明確なエスカレーションパスを提供しない。**AIが支援できない場合、顧客は次に何が起こるかを知る必要があります。エスカレーションを簡単かつ明確にします。支援を受けられない不満のある顧客は、元顧客になります。
-
**「設定して放置」として扱う。**製品は変更されます。ポリシーは変更されます。ナレッジベースもそれらに合わせて変更する必要があります。定期的なコンテンツ監査をスケジュールします。AIを使用してサポート記事を生成および更新する方法の詳細をご覧ください。
-
**指示を複雑にしすぎる。**厳格なルールと複雑なワークフローは維持が困難です。自然言語による指示は、記述、理解、および更新が容易です。
今すぐAIナレッジベースのトレーニングを開始する
ナレッジベースでAIをトレーニングすることは、体系的にアプローチすると簡単です。コンテンツを監査し、適切なプラットフォームを選択し、ソースを接続し、動作を構成し、徹底的にテストし、実際の使用状況に基づいて反復します。
その見返りは大きいです。応答時間の短縮、顧客満足度の向上、および反復的な作業から解放され、人間の判断が実際に必要な複雑な問題に集中できるサポートチームです。
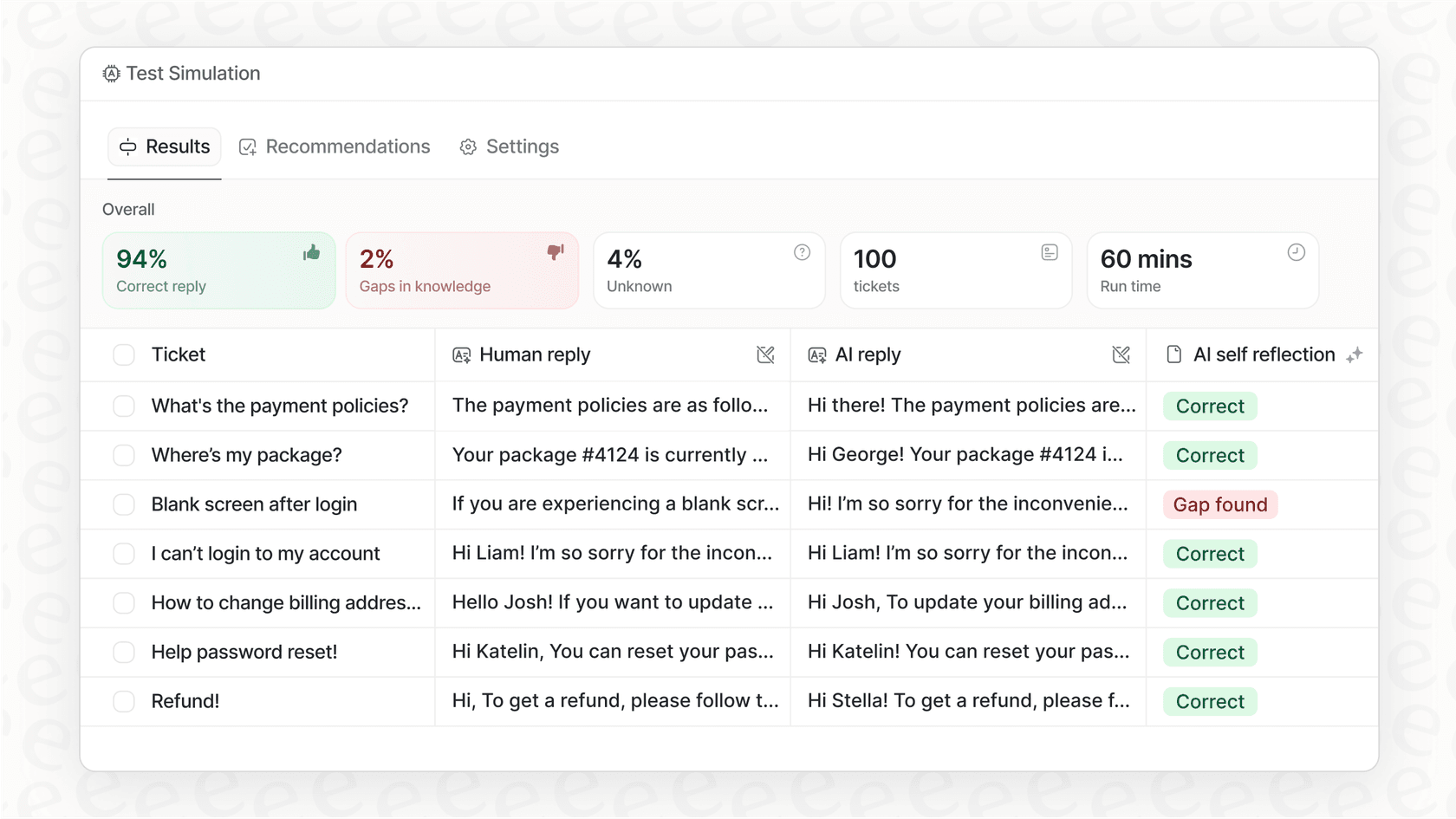
私たちは、このプロセスを可能な限り簡単にするためにeesel AIを構築しました。ヘルプデスクを接続すると、既存のデータから自動的に学習します。コパイロットモードから開始して品質を確認し、信頼が高まるにつれて完全な自律性にレベルアップします。わかりやすい英語の指示ですべてを制御します。コードも複雑なワークフローもありません。
私たちの顧客は、最大81%の自律的な解決率と、通常2か月未満の回収期間を実現しています。しかし、さらに重要なのは、一日中同じ記事からコピー&ペーストするのではなく、重要な仕事に集中できるサポートチームが見られることです。
eesel AIを7日間無料で試すか、デモを予約するして、ナレッジベースでAIをトレーニングすることがチームにとってどのように機能するかを確認してください。
よくある質問
Share this article

Article by
Stevia Putri
Stevia Putri is a marketing generalist at eesel AI, where she helps turn powerful AI tools into stories that resonate. She’s driven by curiosity, clarity, and the human side of technology.


