
Groqとは何か(なぜここでは料金の仕組みが違うのか)
Groqはモデルを作らず、他社のモデル(Llama、Qwen、Mistral、Whisper、OpenAIのオープンウェイトモデル)を独自のカスタムシリコン「Language Processing Unit(LPU)」上で実行します。2016年に元GoogleのTPUエンジニアたちによって設立され、2025年9月に69億ドルのバリュエーションで7億5,000万ドルを調達し、現在200万人以上の開発者にサービスを提供しています。マクラーレンF1チームはリアルタイムのレース解析にGroqを使用しており、「たいてい速い」では済まされないユースケースです。
料金モデルはシンプルです。トークン単位での課金で、アイドル時のインフラ費用なし、動的価格変動なし。Groqの公式声明によると、「他の推論プロバイダーは警告なしにコストを急騰させます。弾力的な価格設定の陰に隠れているところもあります。Groqの料金は線形で予測可能であり、隠れたコストやアイドルインフラの費用はありません。」

LPUがコスト計算を変える理由
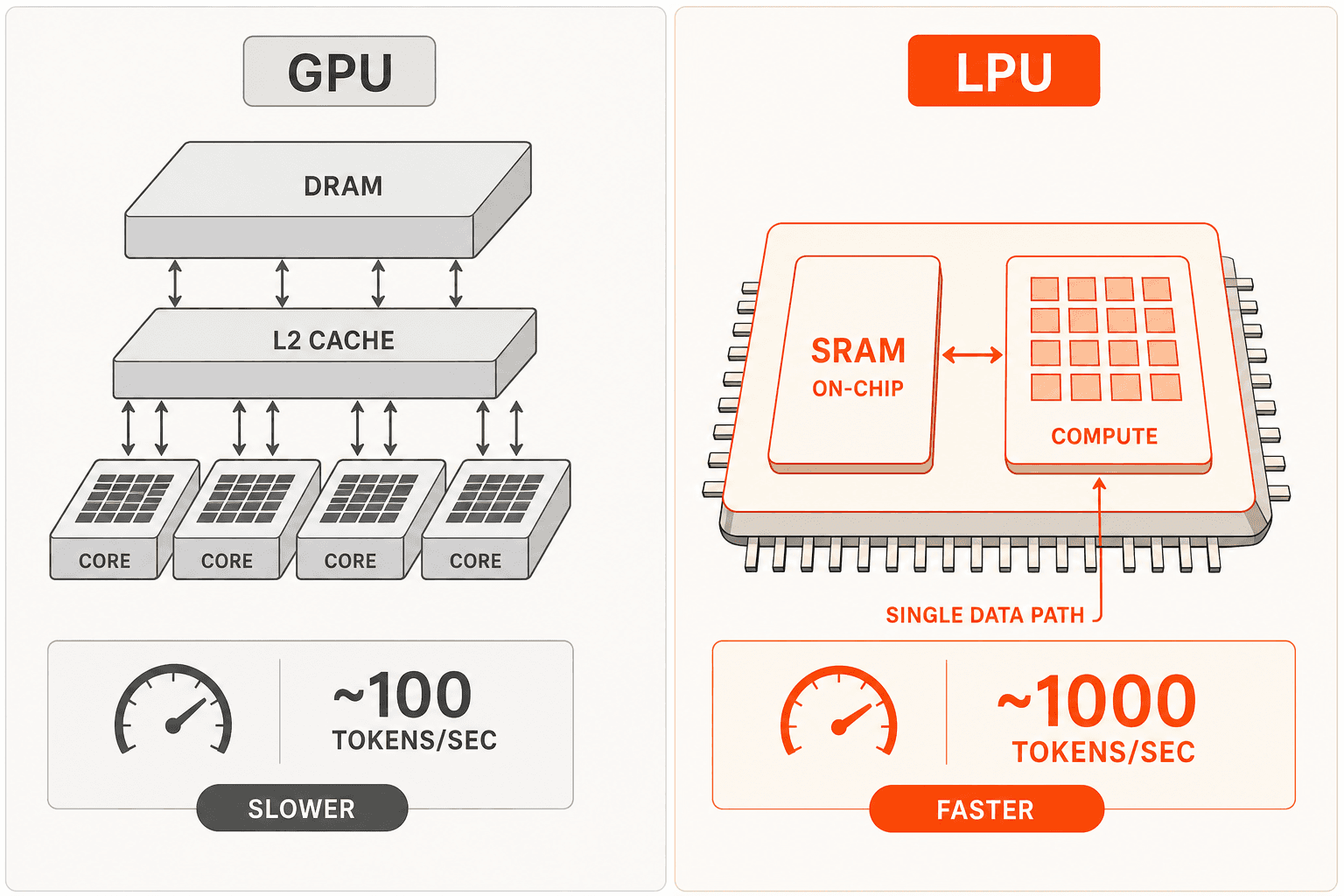
GPUはトレーニング向けに設計されています。大型の外部DRAM/HBMメモリ階層、動的スケジューリング、キャッシュコヒーレンシプロトコルが特徴です。これらは数千コアにわたる行列演算を並列化してトレーニングする際には優れた特性ですが、逐次的なレイヤー実行で算術強度が低くメモリフェッチがレイテンシを支配する推論とは相性が悪いです。
LPUアーキテクチャは異なるアプローチを取ります。オンチップSRAMがキャッシュではなく主要なウェイトストレージとして機能します。Groqの専用コンパイラは実行前に全ての演算を個々のクロックサイクルまで事前スケジューリングし、動的スケジューリングのオーバーヘッドを完全に排除します。RealScaleチップ間プロトコルにより、数百のLPUがテンソル並列処理のために単一コアとして動作できます。全ての演算が静的にスケジューリングされているため、Groqはテンソル並列処理の上にパイプライン並列処理を実行できます。つまりレイヤーNがまだ処理中にレイヤーN+1が処理を開始でき、これはGPUの動的スケジューリングでは確実に実現できないことです。
実際の結果として、GPT OSS 20Bが毎秒1,000トークン、Llama 3.1 8Bが560〜840 TPS、Llama 3.3 70Bが280〜394 TPSで動作します。一般的なGPUベースのクラウドAPIは同等モデルで50〜100 TPSです。同じハードウェアが毎秒より多くのリクエストを処理することで、固定コストがより多くのトークンに分散され、これが入力トークン100万件あたり$0.05が商業的に成立する仕組みです。

Groq無料ティア:実際に何が使えるか
無料ティアはクレジットカード不要で、月間トークン予算ではなくレート制限によって管理されます。無料プランで各モデルが提供する詳細は以下の通りです。
| モデル | RPM | TPM | 1日のリクエスト数 |
|---|---|---|---|
llama-3.1-8b-instant | 30 | 6,000 | 14,400 |
llama-3.3-70b-versatile | 30 | 12,000 | 1,000 |
meta-llama/llama-4-scout-17b-16e-instruct | 30 | 30,000 | 1,000 |
openai/gpt-oss-20b | 30 | 8,000 | 1,000 |
openai/gpt-oss-120b | 30 | 8,000 | 1,000 |
qwen/qwen3-32b | 60 | 6,000 | 1,000 |
groq/compound | 30 | 70,000 | 250 |
whisper-large-v3 | 20 | - | 2,000件の音声リクエスト |
whisper-large-v3-turbo | 20 | - | 2,000件の音声リクエスト |
(RPM=1分あたりリクエスト数、TPM=1分あたりトークン数。出典:Groqレート制限ドキュメント)
開発者が見落としがちな点が2つあります。まず、レート制限はAPIキー単位ではなく組織レベルで適用されます。5つのキーを作成しても150 RPMにはならず、アカウント全体で30 RPMのまま共有されます。次に、プロンプトキャッシングトークンはレート制限にカウントされないため、呼び出し間で繰り返される長いシステムプロンプトがある場合、これは大きなメリットになります。
1分あたりのTPM制限が実際のボトルネックになることが多く、1日のリクエスト上限よりも影響が大きいです。2,000トークンのプロンプト1回でLlama 8BのTPM予算の3分の1を消費します。
「Groq APIを使い続けていますが、無料ティアの制限にまだ引っかかっていないことに驚き続けています」 - @ctatedev、2024年5月
Whisperの無料ティアは特に魅力的な価値を提供します。Artificial Analysisが確認したように、GroqはWhisper Large v3の最低コストプロバイダーの一つです。無料プランでは1日2,000件の音声文字起こしリクエストが利用でき、リクエストあたり最小10秒でバッチ処理した場合、1時間あたり約2時間分の音声に相当します。OpenAIはWhisperアクセスに$0.36/時間を請求しますが、Groqの有料ティアは$0.04〜$0.111/時間なので、無料ティアは非常に太っ腹な出発点です。
「音声テキスト変換の無料APIは素晴らしく、非常に寛大です。強くお勧めします。」
Trustpilotのレビュアー

Groq有料API料金:全モデル
特に記載がない限り、価格はすべて100万トークン(入力/出力)あたりのUSD表示です。出典:Groq料金ページ。
テキスト/LLMモデル
| モデル | モデルID | 速度(TPS) | コンテキスト | 入力 $/1M | 出力 $/1M | ステータス |
|---|---|---|---|---|---|---|
| Llama 3.1 8B Instant | llama-3.1-8b-instant | 560〜840 | 128k | $0.05 | $0.08 | 本番 |
| GPT OSS 20B | openai/gpt-oss-20b | 1,000 | 128k | $0.075 | $0.30 | 本番 |
| Llama 4 Scout (17Bx16E) | meta-llama/llama-4-scout-17b-16e-instruct | 594〜750 | 128k | $0.11 | $0.34 | プレビュー |
| GPT OSS 120B | openai/gpt-oss-120b | 500 | 128k | $0.15 | $0.60 | 本番 |
| Qwen3 32B | qwen/qwen3-32b | 400〜662 | 131k | $0.29 | $0.59 | プレビュー |
| Llama 3.3 70B Versatile | llama-3.3-70b-versatile | 280〜394 | 128k | $0.59 | $0.79 | 本番 |
| Kimi K2 Instruct | moonshotai/kimi-k2-instruct-0905 | - | - | $1.00(キャッシュ済み$0.50) | $3.00 | - |
| Llama Prompt Guard 2 22M | meta-llama/llama-prompt-guard-2-22m | - | 512 | $0.03 | $0.03 | プレビュー |
| Llama Prompt Guard 2 86M | meta-llama/llama-prompt-guard-2-86m | - | 512 | $0.04 | $0.04 | プレビュー |
いくつかのモデルについて補足します。GPT OSS 20BはGPT-4ではなくOpenAIのオープンウェイトモデルで、毎秒1,000トークン、入力$0.075/出力$0.30で動作します。これはプラットフォーム上で最速のモデルであると同時に、出力トークンあたりのコストも最安値クラスです。Llama 4 Scoutはビジョン入力(最大20 MBのファイル)に対応していますが、まだプレビュー段階のため本番環境への導入は推奨しません。Kimi K2はプロンプトキャッシングが料金表に明示的に組み込まれた唯一のモデルです。キャッシュ済み入力トークンが100万件あたり$0.50で、未キャッシュの$1.00より安くなります。
Prompt Guardモデル(100万トークンあたり$0.03〜$0.04)は、プロンプトインジェクションやジェイルブレイクの試みを検出するように設計された安全性分類器です。顧客向けAIを構築していて、メインモデルの前に軽量なフィルター層が必要な場合に役立ちます。
開発者プランのレート制限
無料から開発者プランへの移行は大幅に改善されます。
| モデル | 開発者TPM | 開発者RPM |
|---|---|---|
llama-3.1-8b-instant | 250,000 | 1,000 |
llama-3.3-70b-versatile | 300,000 | 1,000 |
openai/gpt-oss-20b | 250,000 | 1,000 |
openai/gpt-oss-120b | 250,000 | 1,000 |
meta-llama/llama-4-scout-17b-16e-instruct | 300,000 | 1,000 |
qwen/qwen3-32b | 300,000 | 1,000 |
whisper-large-v3-turbo | 400,000 ASH | 400 |
groq/compound | 200,000 | 200 |
(出典:console.groq.com/docs/models)
GroqとOpenAIおよび他プロバイダーとの料金比較
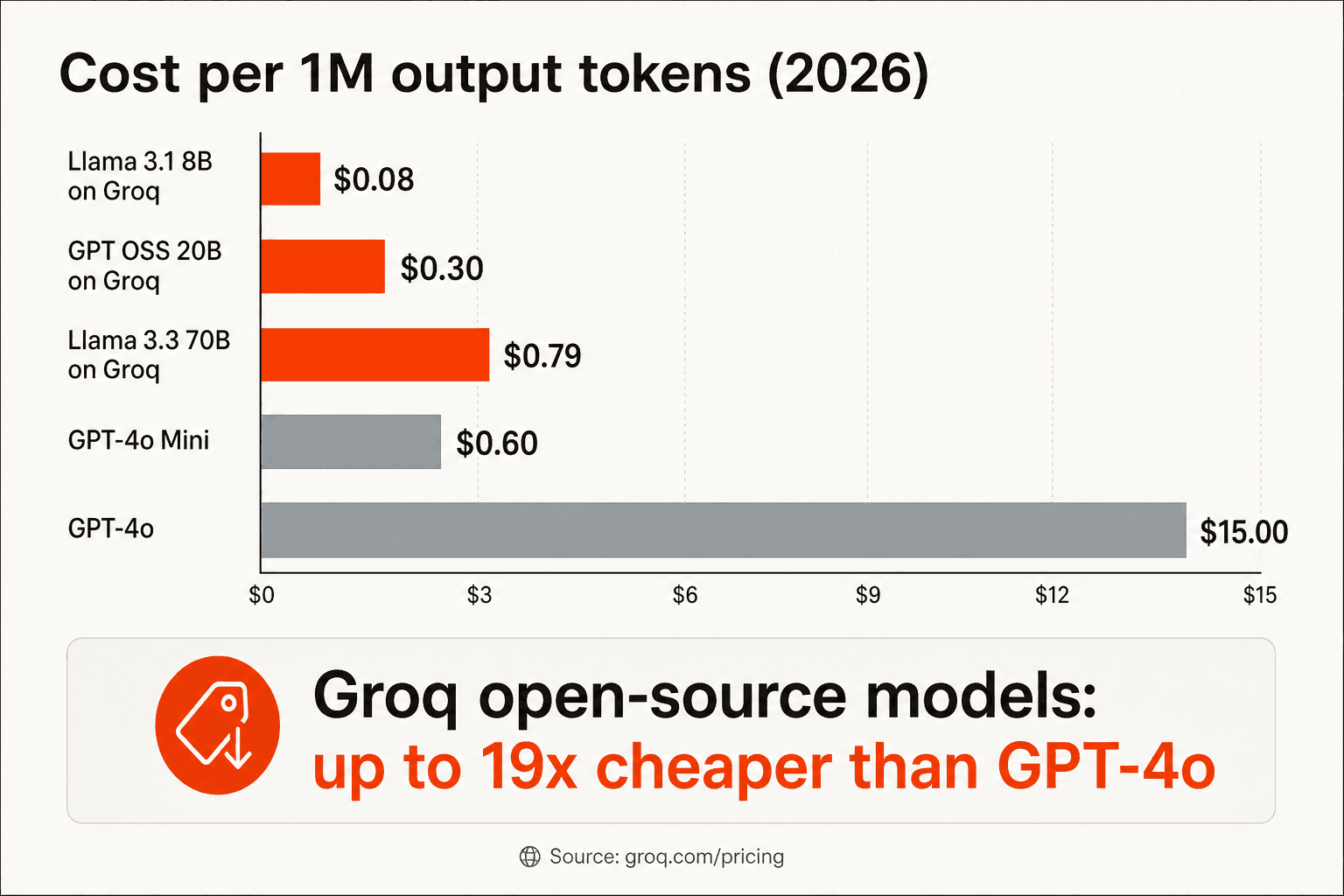
開発者コミュニティで最もよく引用される数字は「同等のオープンソースモデルに対してOpenAIより10〜20倍安い」というものです。これはおおむね正確ですが、同一のモデルを比較しているわけではないという注意が必要です。
「GroqでのLLM推論はGPT-4oのOpenAI料金と比べて約10倍安い。GroqはLlama 3-70B対GPT-4oで10〜20倍安いですが、モデルの性能はやや劣ります」 - Balazs Kocsis、Medium、2024年8月
最も公正な比較は、GroqとOpenAIのプロプライエタリモデルの比較ではなく、Together AIやFireworks AIなど同じモデルを運用している他のオープンソースホスティングプロバイダーとの比較です。そこでは、Awesome Agentsの8週間本番レビューによると、同等のモデルティアでGroqは20〜50%安く、p99が中央値の15%以内に収まる決定論的テールレイテンシを持ちます。これはテールレイテンシの急騰が一般的なGPUワークロードに対して大きな優位性です。
「さようならOpenAI API。今日、同じ基盤となるインテリジェンス(Llama-3またはそのオープンソース競合製品)を100万トークンあたり$0.20以下という底値に近い価格で入手できます。18ヶ月で99%の価格削減です。」 - Aparna Pradhan、GoPenAI、2025年12月
開発者コミュニティで定着した実践的な考え方(LinkedIn上のJolly Guptaが2025年9月にまとめ、114いいね)は次の通りです。速度重視かつコスト敏感なオープンソースワークロードにはGroqを使い、GPT-4oの機能やマルチモーダルの深みが必要な場合はOpenAIを使う。ほとんどの本番スタックは両方を使います。
GroqはArtificial Analysisの調査においても、OpenAI・Google・Anthropic・Microsoftと並んで開発者採用数上位5社の推論プロバイダーとして選ばれています。
音声料金:WhisperとTTS
音声テキスト変換
GroqはLPUハードウェア上でWhisper Large v3の両バリアントを実行し、リアルタイムの217〜228倍速で文字起こしを行います。1時間の音声が約15秒で処理されます。
| モデル | 速度係数 | 価格 | 最大ファイルサイズ |
|---|---|---|---|
whisper-large-v3 | リアルタイムの217倍 | $0.111 / 時間 | 100 MB |
whisper-large-v3-turbo | リアルタイムの228倍 | $0.04 / 時間 | - |
ほとんどのワークロードでは、$0.04/時間のTurboが明確な選択肢です。フルモデルより2.8倍安く高速で、ほとんどの音声では品質差はわずかです。音声は実際の長さにかかわらず、リクエストあたり最小10秒で課金されるため、短いクリップをまとめてバッチ処理する実装の手間をかける価値があります。
OpenAIはWhisperに$0.36/時間を請求しますが、Groqの$0.04/時間はTurboモデルで9倍安いです。Levels.ioが指摘したように、GroqのWhisper+TTSは2024年時点でも「非常に安価」でしたが、それ以来料金は安定しています。
テキスト音声合成(プレビュー)
Groqは最近、Canopy LabsのOrpheusモデルを通じてTTSをリリースしました。
| モデル | 価格 | 備考 |
|---|---|---|
canopylabs/orpheus-v1-english | $22.00 / 100万文字 | 英語、約100文字/秒 |
canopylabs/orpheus-arabic-saudi | $40.00 / 100万文字 | アラビア語(サウジ方言) |
これらはまだプレビュー段階です。LPUのスピード優位性はここでも明らかで、OrpheusはGroq上で毎秒100文字を生成し、ほぼリアルタイムの音声アプリケーションを実現します。

Compound AIシステム:ツール使用で追加コストが発生する場合
GroqCloudのCompoundシステム(groq/compoundとgroq/compound-mini)は、言語モデルに組み込みのウェブ検索とコード実行機能を追加するエージェントラッパーです。料金はモデルのトークンコストにツール使用料が加算されます。
| ツール | 価格 |
|---|---|
| 基本的なウェブ検索 | $5 / 1,000リクエスト |
| 高度なウェブ検索 | $8 / 1,000リクエスト |
| ウェブサイト訪問 | $1 / 1,000リクエスト |
| コード実行 | $0.18 / 時間 |
| ブラウザ自動化 | $0.08 / 時間 |
Compoundシステムは131kコンテキストで約450 TPSで動作します。ツール使用のオーケストレーションを自分で構築するのではなく、プラットフォームに委ねたいエージェントAIワークロードの現実的な出発点です。

知っておくべき2つの隠れた割引
Batch API:非同期ワークロードが50%オフ
Batch APIはジョブを非同期で実行することで、どのモデルでもコストを半額にします。JSONLファイル(最大50,000行、200 MB)を送信すると、24時間〜7日以内に処理が完了し、標準のトークン単価の50%を支払います。標準のレート制限には影響しません。
これが適切な選択肢となるのは、ドキュメント分類パイプライン、大量コンテンツ生成、夜間データエンリッチメント、大規模コンテンツモデレーションなど、レイテンシ許容度が高く大幅な割引が得られるワークロードです。Compoundシステムのツール使用は引き続き標準料金で課金されます。
プロンプトキャッシング:繰り返されるプレフィックスが50%オフ
プロンプトキャッシングは自動的に機能し、コード変更も追加料金も不要です。呼び出し間で同じプレフィックス(長いシステムプロンプト、参照ドキュメント)が繰り返されると、Groqは最大2時間キャッシュします。キャッシュヒットは通常の入力価格の50%になります。
プロンプトキャッシングをサポートするモデルとキャッシュ済み料金:
| モデル | 標準入力 | キャッシュ済み入力 |
|---|---|---|
openai/gpt-oss-20b | $0.075 / 1M | $0.0375 / 1M |
openai/gpt-oss-120b | $0.15 / 1M | $0.075 / 1M |
moonshotai/kimi-k2-instruct-0905 | $1.00 / 1M | $0.50 / 1M |
二重のメリットがあります。キャッシュ済みトークンはコストが半減するだけでなく、レート制限にもカウントされません。長いシステムプロンプトを持つワークロード(RAGパイプライン、ドキュメントQ&A、大規模な知識コンテキストを持つAIカスタマーサポートエージェント)では、レート制限ティアをアップグレードせずに実効スループットを大幅に拡張できます。
レート制限:上限に達したときの対処法
レート制限を超えると、GroqはHTTP 429を返し、retry-afterヘッダーに待機時間(秒数)が示されます。エラー本文は具体的です。
「モデル
openai/gpt-oss-20bのレート制限に達しました… サービスティア: on_demand … 制限 200,000 · 使用済み 199,336 · リクエスト 1,524 · 6分11.52秒後に再試行してください。」 - Standard Timeプロジェクト管理ツールドキュメント、2026年4月
レスポンスヘッダーにはx-ratelimit-limit-requests、x-ratelimit-remaining-tokens、x-ratelimit-reset-requestsも含まれており、試行錯誤なしに正確な指数バックオフを実装するのに十分な情報が得られます。
重要な運用上の考慮事項として、レート制限は組織単位かつモデル単位で適用されます。同じGroqアカウントから複数のサービスやチームメンバーが実行している場合、同じ制限プールを共有します。本番環境と開発環境には別々の組織アカウントを使用するか、特定のワークロードに対するより高い制限についてはconsole.groq.com/settings/limitsからGroqに連絡してください。
エンタープライズ料金
公開されたエンタープライズ料金表はありません。以下にアクセスするには、groq.com/enterprise-accessからお問い合わせください。
- 特定のワークロードに対するより高いレート制限
- GroqRackオンプレミスデプロイメント
- LoRAファインチューニングモデル
- エンタープライズ専用モデル(Minimax M2.5、Qwen3-VL 32Bビジョン対応)
- リージョン別デプロイメントとデータレジデンシーオプション
- SOC 2、GDPR、HIPAAコンプライアンスドキュメント
稼働率について、Awesome Agentsの本番レビューは8週間で99.94%の稼働率を測定し、p99レイテンシは中央値の15%以内に収まっていました。LPUスケジューリングが決定論的であるため、GPUベースの競合より優れたテール動作を示します。エンタープライズSLA保証には正式な契約が必要です。
持続可能性についての疑問
ほとんどのGroq料金ガイドはこの点をスキップしています。私たちは省略しません。
2024年9月、Kyle CorbittがXに投稿し、Groq社員からトークンあたりコストが「請求額の1〜2桁高い」という発言を聞いたと報告しました。この投稿は27万1,000回閲覧されました。2024年初頭には、@swyxが計算し、この料金はバッチサイズ約512でのみ成立し(通常の推論では前例のない数値)、バッチサイズ64の通常の状況では100万トークンあたり約$1.84になることを明らかにしました。
反論として、Groqは7億5,000万ドルを調達しており、BlackRock・Samsung・Cisco・Disruptive AIから投資を受けているのは、ボリュームと新チップの論拠が信頼できるからです。同社の顧客事例では、GPTZeroが7倍高速化しながらコストを50%削減、ReBlink1ゲームあたり14倍コスト削減、Recall 10倍コスト削減が示されています。PeerSpotのマインドシェアデータでは、エンタープライズAIインフラ評価担当者の間で前年比わずかな低下(13.7%から9.8%)が見られます。これはNVIDIAとの契約の不確実性を反映している可能性があり、注視する価値があります。
私たちの見解として、現在の料金が構造的に持続可能なのか、次世代チップ投入前の意図的な「先行展開」戦略なのかは分かりません。分かっていることは、2025〜2026年を通じて料金が安定しており、7億5,000万ドルの調達資金が時間的余裕を生み出しているということです。価格性能比が理にかなっている用途で使い、切り替えられない単一プロバイダー依存にならないよう注意してください。
Groqを使うべき人、そうでない人
Groqを使うべき場合:
- 毎秒280〜1,000トークンがユーザー体験を左右するリアルタイム音声やチャットインターフェースを構築している
- モデルスタックがLlama・Qwen・Whisper、またはOpenAIのオープンウェイトモデルで動作している
- 大規模での安価な文字起こしが必要 - Whisper Turboの$0.04/時間は打ち負かすのが難しい
- プロトタイピング中 - 無料ティアはクレジットカードなしでほとんどの開発ワークロードをカバーする
- 非同期バッチワークロードがある - 50%のBatch API割引が経済性を大きく変える
他を検討すべき場合:
- GPT-4o・Claude・Geminiが必要 - GroqCloudでは利用不可
- 堅牢なマルチモーダルサポートが必要 - Llama 4 Scoutはまだプレビュー段階
- 標準サポート条件のオンプレミスデプロイメントが必要 - GroqRackにはエンタープライズ交渉が必要
- ファインチューニングされたプロプライエタリモデルが必要 - LoRAファインチューニングにはエンタープライズアクセスが必要
より幅広い機能比較については、Groqレビューで製品全体を詳しく解説しています。プロバイダーの選定を続けている場合、Groq代替案では同じ価格性能比の観点からTogether AI・Fireworks・Cerebrasなどを比較しています。
eeselでAI搭載のカスタマーサポートを試す
カスタマーサポートやヘルプデスク自動化のためにGroqを評価している場合、eeselとの相性は抜群です。eeselは既存のツール(Zendesk・Freshdesk・Slack・メール)に直接自律型AIエージェントをデプロイし、複雑さに応じて適切なモデルにサポートチケットをルーティングします。単純で大量のクエリは高速・安価なモデルティアに(Groqのllama 8BとGPT OSS 20Bはまさにこのために設計されています)、複雑なエスカレーションはより高性能なモデルに転送します。
月間10万件以上のチケットを処理するチームが、単に回避するだけでなく実際に問題を解決するeeselエージェントを使っています。新しいインターフェースを覚える必要もなく、プロンプトエンジニアリングも不要です。新入社員をオンボーディングするように、エージェントに説明するだけで後は任せられます。

よくある質問
Groq APIは100万トークンあたりいくらかかりますか?
Groqに無料ティアはありますか?
GroqとOpenAIの料金はどう違いますか?
Groqの有料開発者ティアのレート制限はどのくらいですか?
Groqの料金は本番ワークロードに対してコストパフォーマンスが良いですか?

Article by
Rama Adi Nugraha
Rama is a software engineer at eesel AI with two years of experience writing about B2B SaaS, AI tools, and customer support technology. Based in Bali, Indonesia, he brings a developer's perspective to product comparisons — cutting through marketing copy to what the integrations and APIs actually do.








