
CSATダッシュボードが見せていない「5%問題」
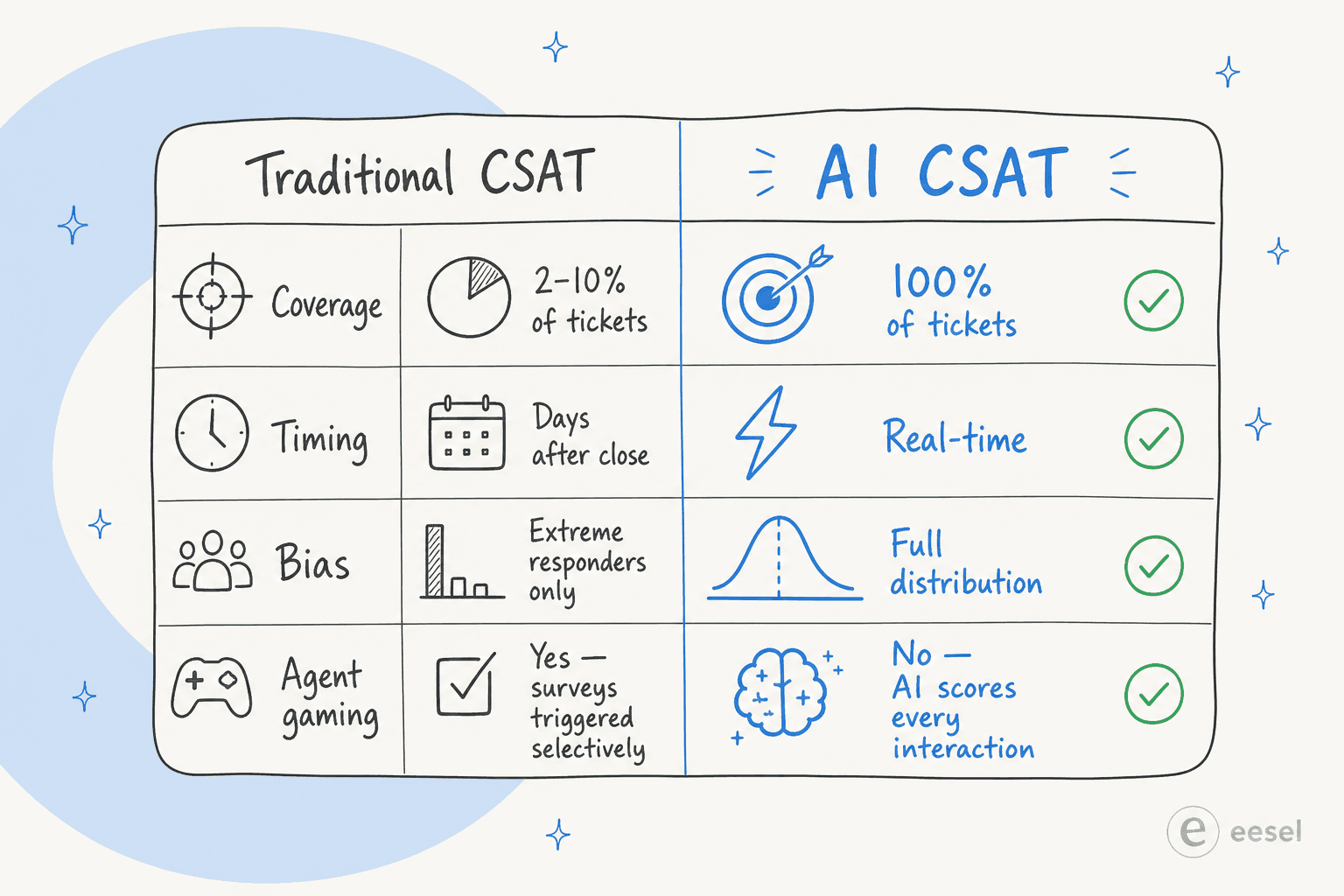
ほとんどのサポートCSATプログラムがどう機能しているか、正直に説明しましょう。エージェントがチケットを閉じると自動メールが送信され、実際に回答するのは顧客のうち2%から10%程度です。
それが、あなたのダッシュボードを支えるデータセットのすべてです。
回答する顧客は代表的なサンプルではありません。大満足の支持者は回答します。激怒した批判者も回答します。広大で満足している中間層、つまり質問に答えてもらい「まあ、悪くなかった」と思って先に進んだ人々は、ほとんど回答しません。だからあなたの82%というCSATは、実際には最も声の大きい顧客のスナップショットであり、必ずしも制御できない両極端に偏っているのです。
事態はさらに悪化します。Crestaの調査は、実務者がすでに知っていることを裏付けています。エージェントはしばしば、感情がポジティブだと判断した後に、選択的にアンケートを送ります。アンケートはサポート体験を測定しているのではなく、エージェントが尋ねても十分良いと感じたやり取りを測定しているのです。それは指標ではなく、編集されたハイライト集です。
「エージェントはしばしば自らの裁量でアンケートを送り、多くの場合は感情がポジティブだと判断した後にのみ送るため、最終的に現実を歪めてしまう。」 - Cresta、The CSAT Mirage
アンケート疲れがこの問題を悪化させます。回答率は量が増えるにつれて低下します。会話が終了したときに送られるCSATアンケートは、やり取りの感情的な質感を失います。顧客の記憶は薄れ、偶発的な気分の要因が評価を汚染します。そして、短いアンケートは深さを失い、長いアンケートは回答者を失うため、従来の形式の中ではきれいな解決策がありません。
ここから導かれる示唆は重要です。顧客満足度スコアが動かないとき、問題はサポート体験ではないかもしれません。測定の問題かもしれないのです。
AI CSATとは実際に何なのか
予測CSATは、推論CSAT、モデルスコアリングCSAT、AI CSATとも呼ばれ、機械学習を使って、顧客がアンケートに回答するかどうかに関係なく、すべてのサポートのやり取りについて満足度スコアを生成します。
このモデルは、実際のアンケート回答と組み合わせた過去の会話データで訓練されます。一度キャリブレーションされると、人間が検証した評価に対して80〜90%の精度で満足度を予測します。一部の導入では95%の一致率に達します。
モデルが分析する対象は、3つのカテゴリーに分かれます。
言語・NLPシグナル:
- 会話全体にわたる感情の推移 - 不満が増大するか、解消するか?
- 具体的な言語マーカー:解約意図、繰り返されるフレーズ、エスカレーション要求(「マネージャーと話させてほしい」)
- 顧客の実際の質問に直接答えたか、それとも回避したか
- 最初のメッセージから最後のメッセージへのトーンの変化
行動・運用シグナル:
- エージェントの引き継ぎ回数 - 再割り当てのたびに満足度は測定可能なほど低下する
- 顧客の期待に対する応答速度と待ち時間
- 顧客が7日以内に再度サポートに連絡したか(強い解約シグナル)
- 顧客が解決のないまま会話を途中で放棄したか
解決品質シグナル:
- 問題は実際に解決されたのか、それとも単に解決済みとマークされただけか?
- 顧客がどこかの時点で問題を言い直したか(引き継ぎ時のコンテキスト喪失)?
- エージェントは解決策に飛びつく前に、顧客の状況を認識したか?
一部のプラットフォームは会話中にリアルタイムでスコアリングし、不満や解約意図が急上昇したときにスーパーバイザーへのアラートを表示して、エスカレーションの前に介入できるようにします。他のプラットフォームは終了後にバッチでスコアリングします。いずれにせよ、出力は5%のサンプルではなく、一つひとつのやり取りについての満足度推定値です。
スケールの違いを示す具体例があります。あるエンタープライズのヘルスケア企業は、AI QAツールを導入した後、サポート通話の5%のスコアリングから100%の通話スコアリングへと移行し、個別の通話レビューでは一度も明らかにならなかったパターンレベルのインサイトをすぐに可視化し始めました。サポートが一夜にして劇的に良くなったからではなく、ようやくそのすべてを見られるようになったからです。
完全な分析スタック:AIがCSAT以外に可視化する指標
CSATは見出しの数字です。CSATがなぜその値なのかを説明し、実際に何を変えるべきかを示す指標こそ、AIが自動的に可視化してくれるものです。
初回解決率:最も強力なCSATの予測因子
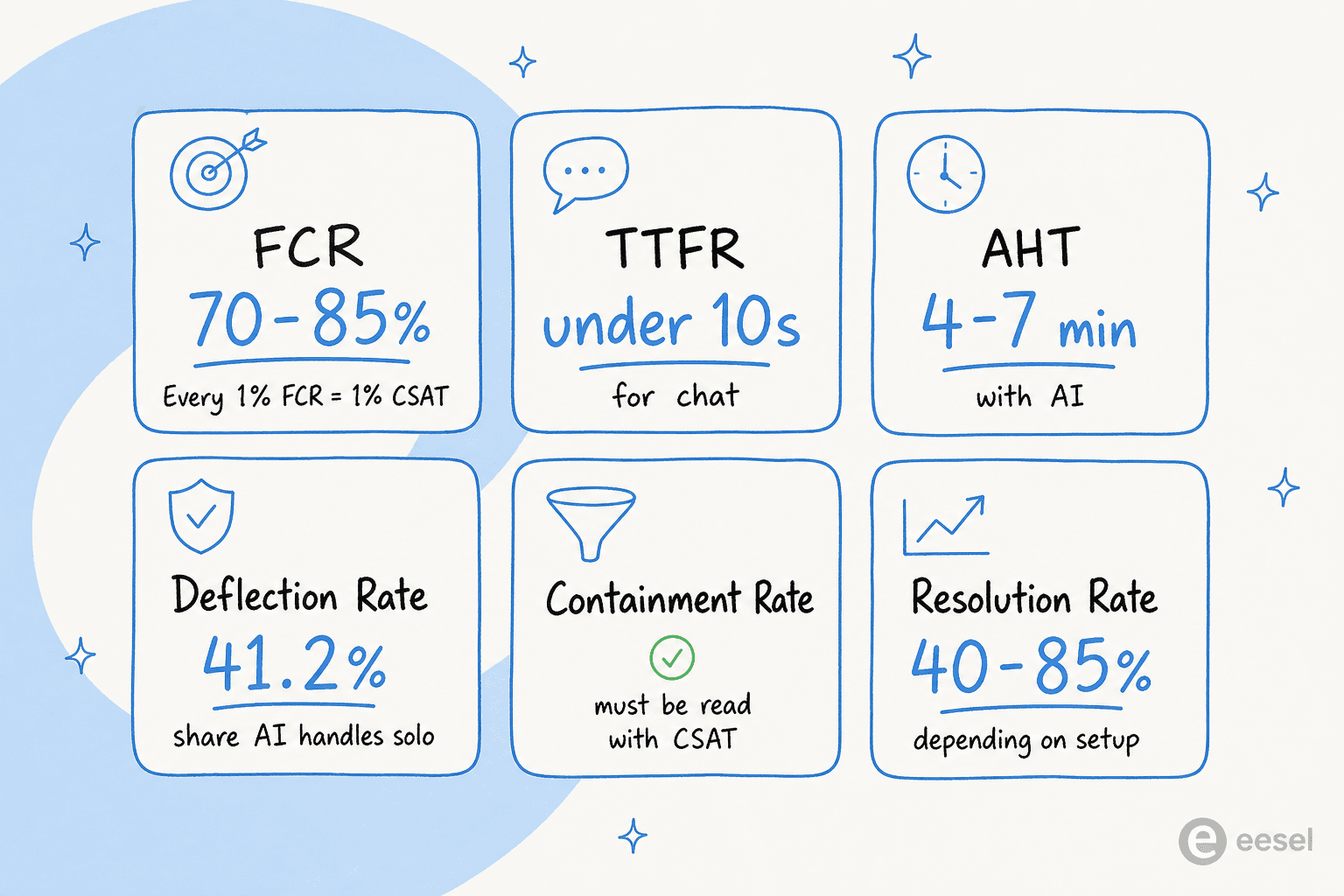
FCRは、フォローアップの連絡を必要とせず、顧客の問題が最初の試みで解決されたかどうかを測定します。CSATとの関係はほぼ線形です。FCRが1%改善するごとに、CSATはおよそ1%改善します。SQM Groupの調査は、業界や業種を超えてこれを一貫して裏付けています。
FCRの業界ベンチマークは、一般的なサポートで70〜79%、トップパフォーマーで85%に達します。AIは再問い合わせの根本原因を排除することでこの数字を動かします。24時間365日の対応は「営業時間中にかけ直そう」というループをなくし、一貫した知識に裏付けられた回答は「前回は違う答えだった」という問題をなくし、適切なチケットトリアージは最初から正しいチームにチケットが届くことを保証します。
AI導入前のFCRは通常60〜75%です。AI導入後のFCRは70〜85%で、チケットの複雑さと知識ベースの品質によってはさらに高くなる導入もあります。
初回応答までの時間
初回応答までの時間(TTFR)は、顧客が何らかの返答を得るまでにどれだけ待つかです。メールサポートの平均応答時間は12時間10分ですが、顧客はB2Bメールで4時間未満、ライブチャットで10秒未満を期待しています。5〜10秒であれば、ライブチャットのCSATは84.7%に達します。30秒を超えると、急激に低下します。
AIは自動化されたチャネルにおいて、このギャップを完全に排除します。初回応答は数秒で届きます。人間がレビューするキューについては、AIが支援するチケットトリアージとチケットの要約が、人間が返信する前のコンテキスト切り替えの時間を圧縮します。
平均処理時間
AHTは解決にかかる全体の時間をカバーします。通話やチャットの時間、保留時間、やり取り後の後処理です。一般的なサポートのベンチマークは、AI導入前で6〜10分、AIが支援するサポートでは通常4〜7分、完全にAIネイティブなチケット解決では3分未満です。
知っておく価値のある一つのニュアンスがあります。AIを最初に導入したとき、AHTは当初増加します。AIが簡単なチケットを吸収し、人間には難しいチケットが残るからです。60〜90日のランプ期間を経て、エージェントが残った複雑なチケットについてもAIが生成したコンテキストとドラフト返信を受け取るようになるにつれ、AHTは低下します。AIが支援するサポートは、1時間あたりの問い合わせ処理数を13.8%向上させます。通話前と通話後の両方を組み合わせたAI導入は、成熟期には25〜50%のAHT削減を達成します。
デフレクション率
デフレクション率は、AIまたはセルフサービスによって完全に処理され、人間のエージェントに一切届かないサポートリクエストの割合を測定します。ベンダーの主張は70〜80%のデフレクションを見出しに掲げる傾向があります。独立したZendeskのベンチマークデータはより地に足が着いています。デフレクション率の中央値は41.2%、上位四分位は58.7%、下位四分位は22.4%です。Eコマースと通信は高めに偏り、B2B SaaSとフィンテックはチケットが難しいため低めに偏ります。
デフレクション率は解決あたりのコストにとって重要です。AIによる解決は平均で約0.62ドル、人間が処理するチケットは7.40ドルです。ただしCSATと並べて読むべきです。高いデフレクションとCSATの低下が同時に起きているなら、AIは問題を解決せずにチケットを閉じているということです。
封じ込め率
封じ込め率は、AIで始まり、人間にエスカレーションすることなく完結する会話の割合です。AI搭載サポートの目標範囲は70〜90%です。
落とし穴があります。封じ込め率単体では虚栄の指標です。困惑した顧客を諦めさせる形で回避するボットは、封じ込め率100%で壊滅的なCSATになります。封じ込め率は、解決品質とCSATと並べて読んで初めて意味を持ちます。封じ込め率が上昇しCSATも上昇しているなら、AIは問題を解決しています。封じ込め率が上昇しCSATが低下しているなら、AIは支援へのアクセスを妨げているのです。
解決率
解決率は、AIが正しく解決したチケットの割合です。単に閉じるのではなく、実際に解決したものです。現実的な出発点は、ほとんどの導入で40〜50%です。よく整理された知識ベースと調整されたエスカレーションルールを備えた高度なシステムは、70〜85%に達します。
これは、誠実なAIベンダーが筆頭に掲げる指標です。Zendesk上で運用されるギグエコノミー向けのドライバー分析プラットフォームGridwiseは、最初の月にeeselがティア1リクエストの73%を解決したと報告しており、その成果は7日間のトライアル内で確認できました。
「最初の月で、eeselは当社のティア1リクエストの73%を解決しています。私たちのチームは7日間のトライアル中に導入し、すぐに成果を達成しました。回答の修正や調整も簡単です。このプラットフォームには、チケットのタグ付け、割り当て、ステータス更新の自動化まで含まれています!」 - Kim Simpson、Gridwise(G2レビュー)
AIは実際にどうやってCSATの数字を動かすのか
CSATをより正確に測定すること自体が、本質的にCSATを改善するわけではありません。CSATを改善するのは、AIがサポート体験そのものに対して行うことです。
より速い応答時間が最も直接的なレバーです。初回応答を10秒未満で待つ顧客は、30秒以上待つ顧客よりも体験を8〜14ポイント高く評価します。AIの初回応答は自動化されたチャネルでの待ち時間を排除し、AIのドラフト返信が残りについて人間の応答時間を圧縮します。
一貫した正確な回答は、FCRとCSATを同時に破壊する再問い合わせのサイクルを排除します。すべてのエージェントと、すべてのAIが、同じ知識ベースから情報を引き出し、同じエスカレーションルールを適用すれば、顧客は矛盾した情報を聞かなくなります。AIチケット分類とインテリジェントなトリアージは、チケットをより速く正しいチームに届け、満足度を低下させる「たらい回し」の体験を減らします。
スムーズなエスカレーション - 完全な会話履歴、顧客のコンテキスト、AIが生成した要約を引き継ぐ担当者に渡すAIチャットエスカレーション - は、ハイブリッドサポートで最も一般的なCSATキラー、すなわち新しい担当者に問題を再説明させられることを防ぎます。同じ解決品質であっても、スムーズな引き継ぎを受けた顧客は、冷たい転送を受けた顧客よりも人間とのやり取りを高く評価することが、調査で一貫して示されています。
スケールでのパターン検出は、従来のCSATでは提供できないインサイトレイヤーです。AIがやり取りの100%をスコアリングしていると、特定の製品カテゴリーが他のものの3倍の率で不満を生んでいること、エスカレーションの40%は100ドルを超える返金紛争の扱い方をAIが知らないために起きていること、あるいはどのエージェントがチケットをすばやく閉じる一方で最も多くの再オープンを生んでいるかが見えるようになります。これらはいずれも、5%のサンプルでは見えません。
「eesel AIは私たちのワークフローを合理化し、生産性を高め、より高いレベルのサービスの一貫性を保証します。」 - Melissa Ryan、Zendesk管理者、Discuss.io(Zendesk Marketplaceレビュー)

主要なヘルプデスクにおけるAI CSAT分析
Zendesk
Zendeskのネイティブ分析はZendesk Exploreにあり、CSATの測定とレポート、初回返信時間、チケット量、AIエージェントの解決率を可視化します。スケジュールレポートとメール配信を設定でき、ダッシュボード全体で計算指標を構築できます。Zendeskのパフォーマンス指標は、初回返信時間や解決済みチケット数を含め、すべてExploreを通じてネイティブに可視化されます。
Exploreが力不足な点:予測CSATを生成せず、エスカレーション品質を可視化せず、チケットタイプ別に分解した解決品質も表示しません。Zendesk AIエージェント分析はネイティブのZendesk AIについてこの一部をカバーしますが、サードパーティ統合がその全体像を大きく拡張します。自動解決を追跡するためのZendesk AIエージェント指標とエスカレーションルールが入力を提供し、eeselのダッシュボードがそれらを解決品質のスコアリングと組み合わせて単一のビューにまとめます。
Freshdesk
FreshdeskのFreddy AIは、ネイティブのレポートモジュールを通じて基本的な分析を処理します。CSATスコア、チケット量、初回応答時間、解決時間がすべて利用可能です。Freshdesk Freddy AIの料金はCopilotおよびAutopilotのティアに連動し、上位プランほど分析の深さが増します。
制限はZendeskと同様です。Freddy Analyticsは何が起きたかを表示しますが、なぜ起きたかは表示しません。解決品質のスコアリングと予測CSATはネイティブには利用できません。高度なAIエージェントをFreshdeskに接続することが、より充実した分析への道です。eeselの解決追跡は、Freshdeskのネイティブデータを置き換えるのではなく、その上に重ねます。
Gorgias
Gorgiasの分析はEコマース指標に焦点を当てています。サポートに帰属する収益、やり取り後のアンケートからのCSAT、そして自動化率、すなわち人間の介入なしに処理されたチケットの割合です。Gorgias AI Agent 2.0はより多くの自動化チケット指標を追加しましたが、予測CSATスコアリングはネイティブのスイートには含まれていません。
完全な分析スタックを求めるEコマースヘルプデスクチームにとって、eeselの統合は、Gorgiasのネイティブレポートが可視化しない解決品質の追跡と、封じ込め率+CSATのビューをもたらします。
指標を一緒に読む:ほとんどのチームが陥る落とし穴
ここが、ほとんどのAIサポート導入が間違える場所です。一つの指標を最適化して、別の指標を壊してしまうのです。
高いデフレクション、低下するCSAT - AIはチケットを処理していますが、顧客を満足させていません。よくある原因には、知識のギャップ(自信たっぷりだが間違った回答)、エスカレーショントリガーの欠落(人間に届くべきチケットがAIに留まっている)、引き継ぎ時にコンテキストが失われるチャットボットのエスカレーションの失敗が含まれます。
改善するAHT、横ばいのFCR - AIはエージェントがより速く働くのを助けていますが、根本的なルーティングの問題のために、顧客は依然として再度連絡してきます。処理時間を数秒削るよりも、ルーティングと知識ベースの完全性を修正する方が重要です。
上昇する封じ込め率、不明なCSAT - 最も危険な組み合わせです。AIが会話を完結させているのに、顧客がエスカレーションせずに不満を抱えたまま離れていたら、シグナルが得られません。これこそAI CSATスコアリングがギャップを埋める場面です。そうでなければ「苦情がない、だから問題なかったはずだ」として記録されてしまう沈黙をカバーします。
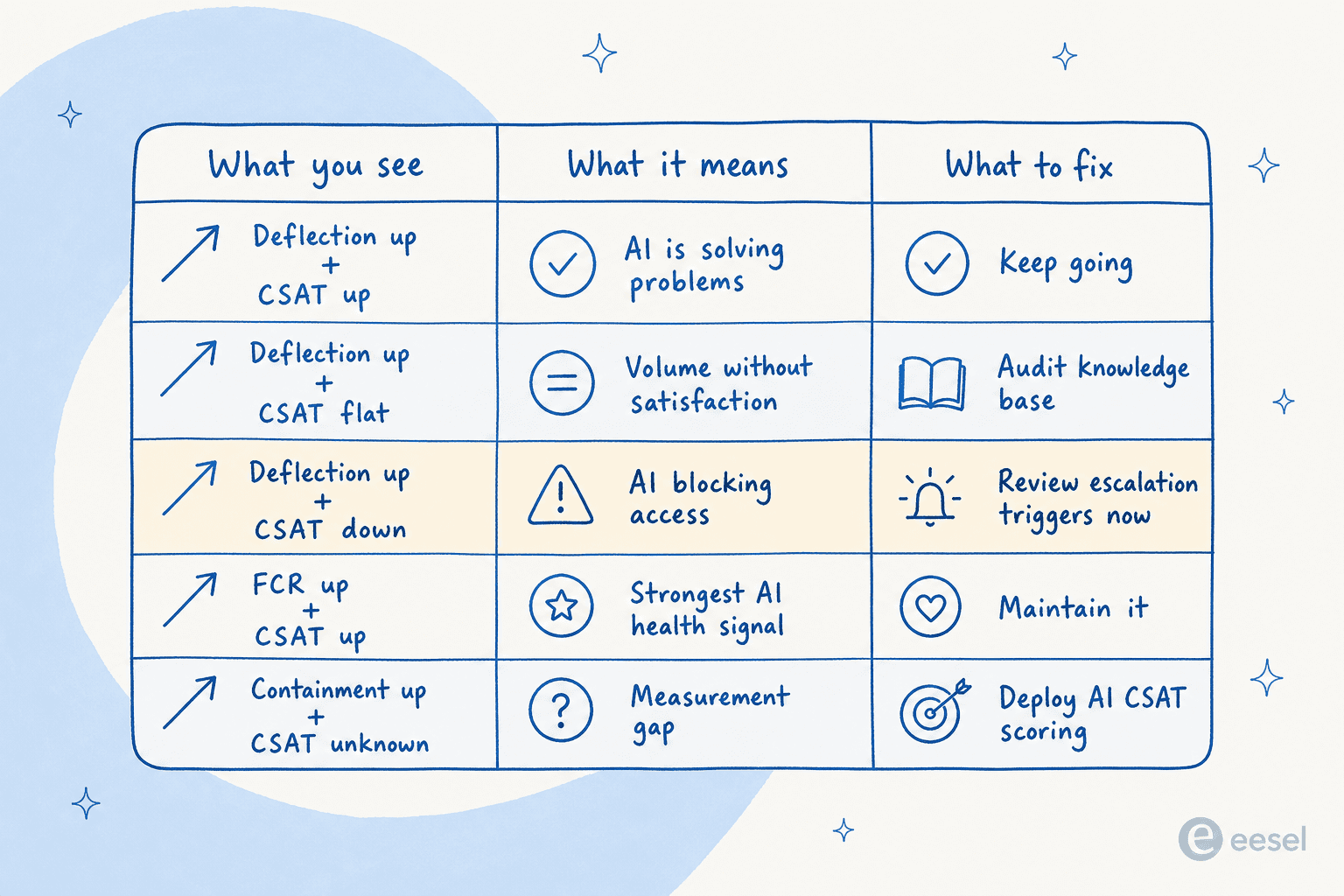
シグナルを一緒に読む方法は次のとおりです。
| 見えるもの | 意味すること | 修正すべきこと |
|---|---|---|
| デフレクション上昇 + CSAT上昇 | AIが問題を解決している | 継続する。エスカレーションの閾値を調整する |
| デフレクション上昇 + CSAT横ばい | AIは量を処理しているが満足度は伴わない | 知識ベースを監査する。信頼度の閾値を調整する |
| デフレクション上昇 + CSAT低下 | AIが人間へのアクセスを妨げている | エスカレーショントリガーを直ちに見直す |
| FCR上昇 + CSAT上昇 | AIの健全性を示す最も強力なシグナル | 何が機能しているかを文書化し、維持する |
| AHT低下 + 再オープン増加 | エージェントが早すぎるタイミングでチケットを閉じている | クローズ基準を見直す |
| 封じ込め率上昇 + CSAT不明 | 測定のギャップ | AI CSATスコアリングを導入して埋める |
解決あたりのコスト比較は、このコンテキストの中でのみ意味を持ちます。チケットの60%を1解決あたり0.62ドルで回避するAIは、再連絡率が40%だと判明するまでは素晴らしく見えます。つまり、それらの「解決済み」チケットは、下流でより多くの人間による作業を生んでいるのです。
もう一つのよくある落とし穴は、AIと人間のカスタマーサポートを二者択一として読むことです。最も優れたカスタマーサービスAIプラットフォームは、量を処理し一貫したベースラインを維持するためにAIを使い、複雑で重大で感情的な負荷の高いチケットには人間を使います。そうしたチケットでは、人間とのやり取りが真に重要であるため、AIエージェントと人間のエージェントのコストの比較は崩れます。
AI CSATを実際に動かす3つのこと
1. 封じ込めよりもFCRを優先する。
FCRの改善が1%進むごとに、CSATは1%向上します。封じ込め率は入力であり、CSATは出力です。会話をボット内に留めるのではなく、最初の試みで正しい解決を最大化するように、ルーティングルール、知識ベース、エスカレーションの閾値を設定しましょう。ティア1サポートのデフレクションのためのAIは、回避されたチケットがそもそもAIで本当に解決可能だった場合にのみ、CSATの推進力として機能します。
2. エスカレーション率だけでなく、エスカレーション品質を監査する。
AIチャットエスカレーションは、ハイブリッド導入においてCSATが勝ち取られるか失われるかの分かれ目です。完全なコンテキストを伴うきれいなエスカレーションは、不満の残るAIとのやり取りの後でも顧客満足度を回復させます。コンテキストを失う冷たい転送は、不満を倍増させます。エスカレーション率とは別にエスカレーション品質を追跡することで、引き継ぎが機能しているかどうかがわかります。最も優れたAIエージェントアシストツールは、これを手動で計算するものではなく、ダッシュボード指標として可視化します。
3. 手動では決して監査しないチケットを見つけるためにAI CSATを使う。
AIがやり取りの100%をスコアリングすると、外れ値が自動的に浮かび上がります。平均の3倍の不満を生むチケットカテゴリー、自信たっぷりだが間違った回答を生む知識記事、一貫して再オープンにつながるエージェントのワークフローなどです。このスケールでのサポートチケット分析は、AIがスコアリングを行ってこそ実用的です。最も優れたAIカスタマーサポートチャットボットは、これをますます自動アラートとして可視化しています。あるカテゴリーのCSATが閾値を下回ると、それが解約問題になる前にシステムがフラグを立てるのです。
eeselを試す
eeselは、別途分析ツールを必要とせずに、チケットを解決し、分析を可視化し、解決品質を測定するカスタマーサービス向けのAIチームメイトです。組み込みのレポートダッシュボードは、Zendesk、Freshdesk、Gorgias、Slack、メール、Shopify、そして100以上のその他のチャネルを含む、接続されたすべてのチャネルにわたって、解決率、チケット品質、やり取りの量、アクティビティログを表示します。
セットアップは数か月ではなく数分で完了します。Global PayのChief Innovation OfficerであるAlex Capurroは、Confluence上でeeselのAI Copilotを導入した後、回答とオンボーディングで最大80%の時間削減を報告しました。Gridwiseは最初の月にティア1解決率73%を達成しました。InDebtedは、社内ITヘルプデスクで現在15%のチケットデフレクションを達成しており、目標は55%です。
分析は別個の製品ではありません。AIが働く中で生成するものそのものです。料金は使用量ベースで1チケットあたり0.40ドル、プラットフォーム手数料も席数ごとの課金もありません。これは100チケットで月40ドル、1,000チケットで月400ドルに相当し、月300ドル以上で25%の年間コミット割引が利用できます。

eeselを試す - 無料、50ドルの使用クレジット付き、クレジットカード不要、初日からすべての機能が利用可能。
よくある質問
AIはCSATとサポート分析を自動的に提供できますか?
2026年のカスタマーサポートにおける良いCSATスコアとは?
AIはCSAT以外にどんなサポート分析を追跡できますか?
ZendeskにおけるAIカスタマーサポートCSAT分析とは?
デフレクション率とCSATはどのように関係していますか?

Article by
Rama Adi Nugraha
Rama is a software engineer at eesel AI with two years of experience writing about B2B SaaS, AI tools, and customer support technology. Based in Bali, Indonesia, he brings a developer's perspective to product comparisons — cutting through marketing copy to what the integrations and APIs actually do.







