Qu'est-ce que Sakana Fugu exactement ?
Sakana AI est un laboratoire frontier à Tokyo fondé en 2023 par trois anciens chercheurs de Google : le CEO David Ha, le CTO Llion Jones (l'un des huit co-auteurs du paper original "Attention Is All You Need" sur les Transformers) et le COO Ren Ito. En novembre 2025, il a levé $135M en Série B à une valorisation de $2,65 Mds, faisant de lui l'une des startups IA les plus valorisées du Japon.
Le nom a de l'importance. « Sakana » (魚) signifie poisson, clin d'œil au pari du laboratoire que l'avenir de l'IA ressemble moins à un grand cerveau unique qu'à un banc coordonné de petits spécialistes. Fugu (nommé d'après le poisson-globe) est cette thèse transformée en produit. Sakana le présente comme « One Model to Command Them All » : des performances de niveau frontier sans dépendre d'un seul fournisseur.
Voici la façon la plus claire de l'imaginer. Fugu est lui-même un modèle, mais au lieu de générer la réponse finale seul, il assemble dynamiquement une équipe à partir d'un ensemble d'autres modèles puissants et les coordonne. Tout l'appareil vous est présenté comme un seul modèle derrière une seule API. Si vous avez lu notre explication sur les agents IA versus chatbots, Fugu est l'idée de l'agent poussée à son extrême logique : les « outils » de l'agent sont d'autres modèles frontier.
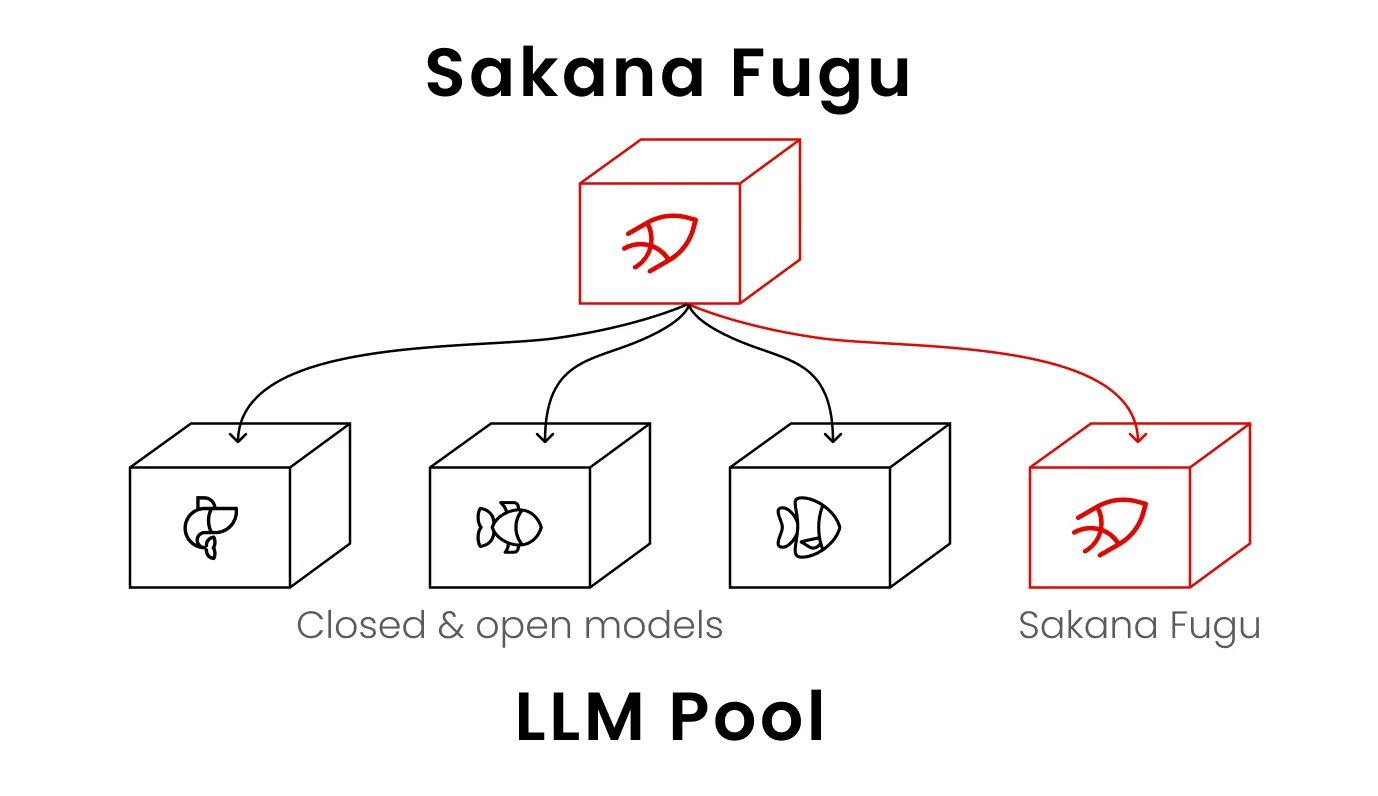
Un détail important que beaucoup ratent : Fable 5 et Mythos Preview ne sont pas dans l'ensemble de Fugu, car ils ne sont pas accessibles publiquement. Fugu orchestre uniquement les modèles qu'il peut réellement appeler. Donc quand Sakana dit que Fugu égale Fable 5, il affirme qu'une équipe coordonnée d'autres modèles publics peut rivaliser avec le frontier, ce qui est une affirmation plus intéressante qu'il n'y paraît.
Comment Fugu fonctionne vraiment sous le capot
C'est là que Fugu mérite la défense de « pas seulement un routeur ». Il repose sur deux papers ICLR 2026 sur l'orchestration de modèles apprise, et le mécanisme est plus élaboré que simplement choisir un modèle et transférer la requête.
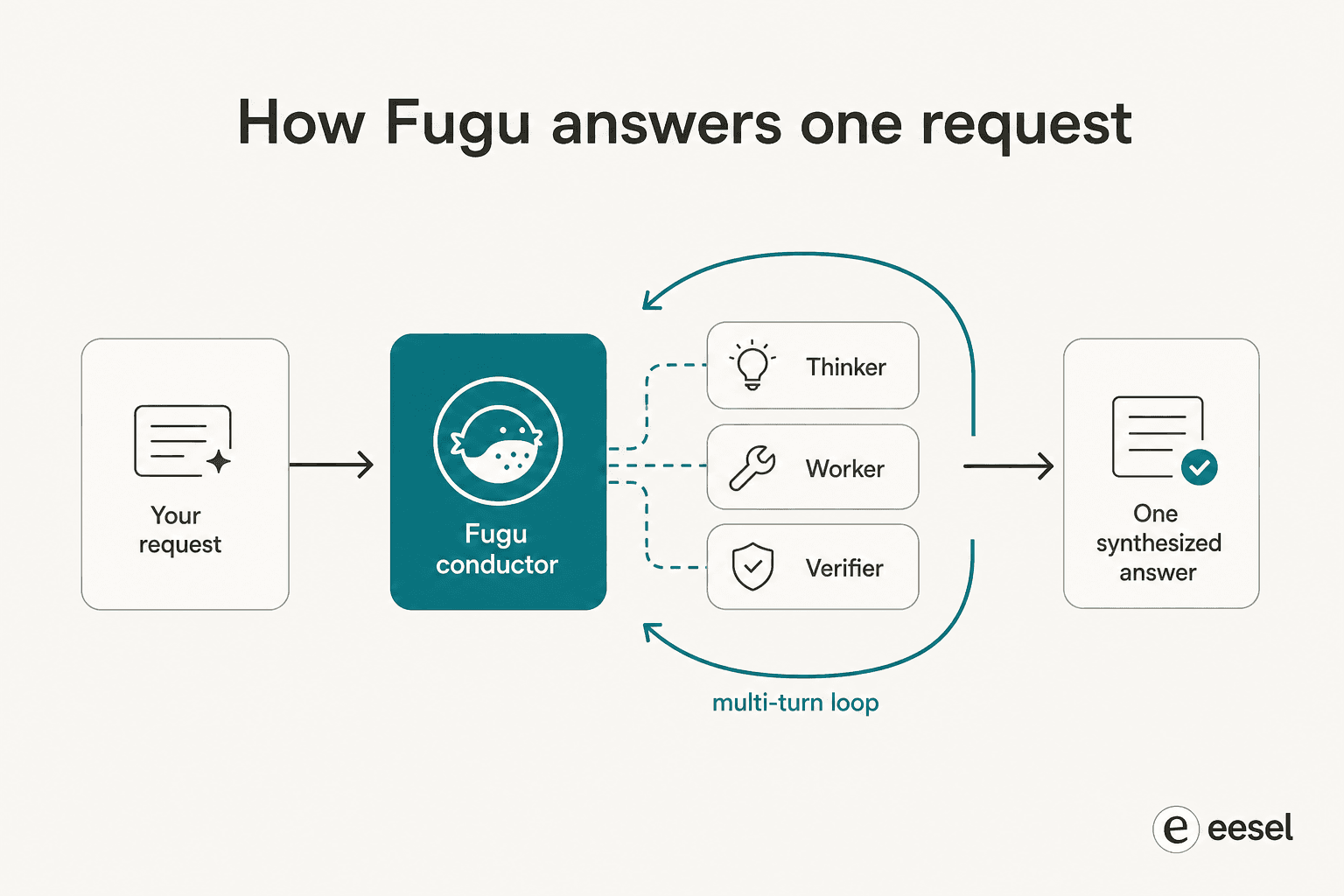
Le premier paper, TRINITY, utilise un coordinateur léger et évolutif qui orchestre plusieurs modèles sur plusieurs tours, attribuant à chacun un rôle de Thinker, Worker ou Verifier et re-déléguant à mesure que la tâche se déroule. Le second, le Conductor, est entraîné par apprentissage par renforcement pour découvrir des stratégies de coordination en langage naturel, apprenant essentiellement à écrire des prompts ciblés et à concevoir comment les modèles se parlent pour que l'ensemble surpasse n'importe quel membre individuel.
Les deux expressions à retenir sont appris et multi-tour. Fugu ne suit pas un script conçu par des humains « demandez d'abord au modèle A, puis au modèle B ». Il a appris, par évolution et RL, à découvrir des patterns de collaboration non évidents, et il boucle, re-vérifiant et re-routant plutôt que de faire un seul passage. C'est pourquoi les premiers utilisateurs rapportent qu'il tourne pendant des heures sur une seule tâche : 123 expériences sur environ 14 heures pour un problème de recherche ML, ou près de quatre heures pour reproduire de manière autonome un paper. Cela ressemble beaucoup au type de boucle d'agent sur lequel nous nous obsédons lors de la construction d'automatisation du support, simplement orienté vers des modèles frontier plutôt que vers des outils.
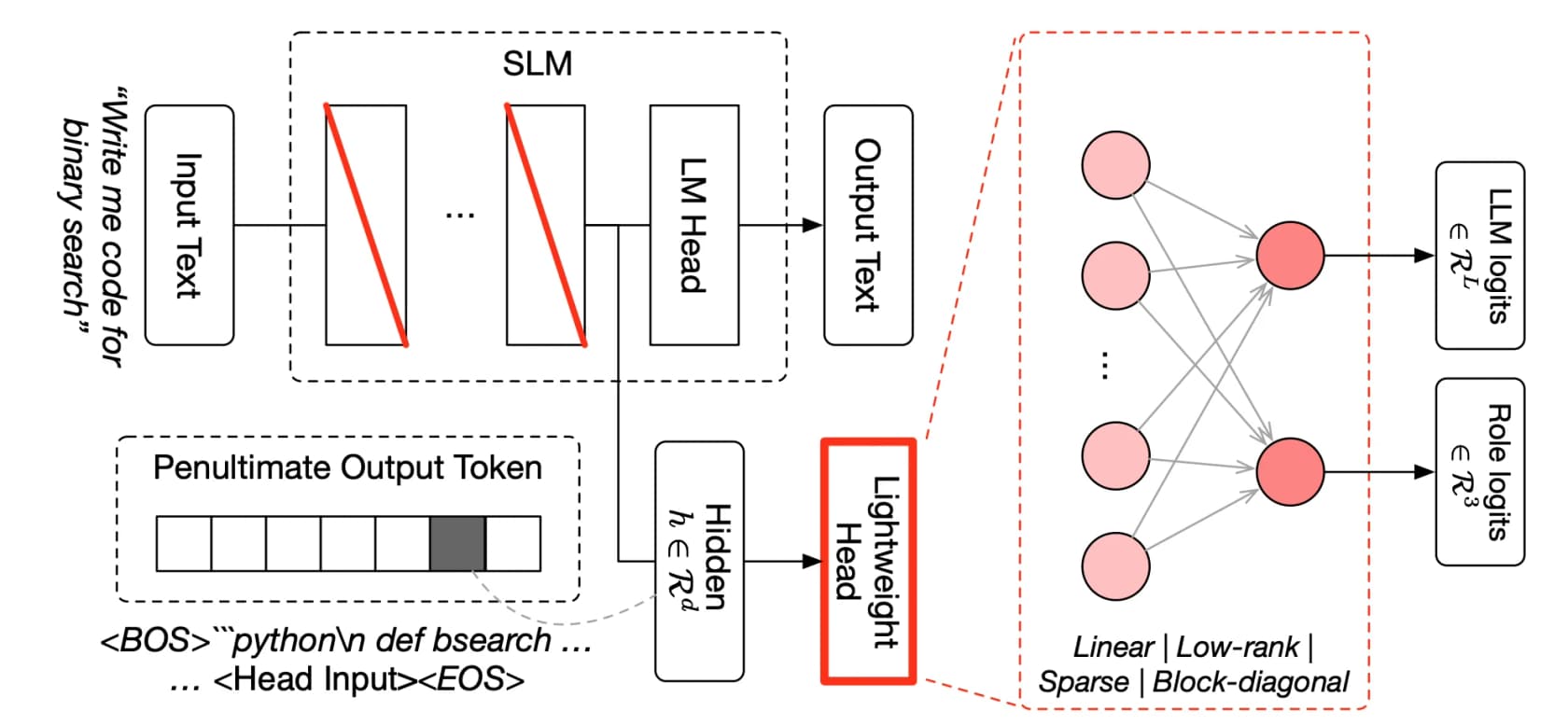
Un compromis à signaler maintenant : le routage est propriétaire et opaque par conception. Vous ne pouvez pas voir quel modèle sous-jacent a répondu à une requête donnée. Pour certaines équipes c'est acceptable ; pour quiconque a des exigences de conformité, cette structure de boîte noire devant une boîte noire est une vraie considération.
Fugu vs Fugu Ultra : lequel est lequel
Fugu se décline en deux modèles, tous deux accessibles via la même API compatible OpenAI pour que vous puissiez basculer entre eux sans toucher à votre intégration. La différence tient au nombre d'agents experts coordonnés, qui est le levier entre vitesse et qualité.
| Fugu | Fugu Ultra | |
|---|---|---|
| Optimisé pour | Performance et latence équilibrées | Qualité de réponse maximale |
| Pool d'agents | Coordonne un ensemble ; vous pouvez exclure des modèles | Pool fixe plus profond ; pas d'exclusion |
| Idéal pour | Codage quotidien, revue de code, chatbots | Problèmes difficiles, à fort enjeu, multi-étapes |
| Compromis | Faible latence, solide par défaut | Meilleure qualité au détriment de la vitesse |
En clair : optez pour Fugu quand vous voulez un défaut réactif, et Fugu Ultra quand vous avez un problème épineux et que vous acceptez d'attendre pour une meilleure réponse. Les premiers utilisateurs mettent Ultra à contribution sur des compétitions Kaggle, des reproductions de papers, des analyses de cybersécurité et des investigations de brevets, ce qui indique que le point idéal visé est la profondeur, non le débit.
Les benchmarks : est-il vraiment à égalité avec Fable 5 ?
L'affirmation principale de Sakana est que les modèles Fugu « surpassent les modèles frontier publiquement accessibles et sont à égalité avec Fable 5 et Mythos Preview » sur des benchmarks d'ingénierie, scientifiques et de raisonnement. Les chiffres soutiennent bien l'affirmation la plus étroite.
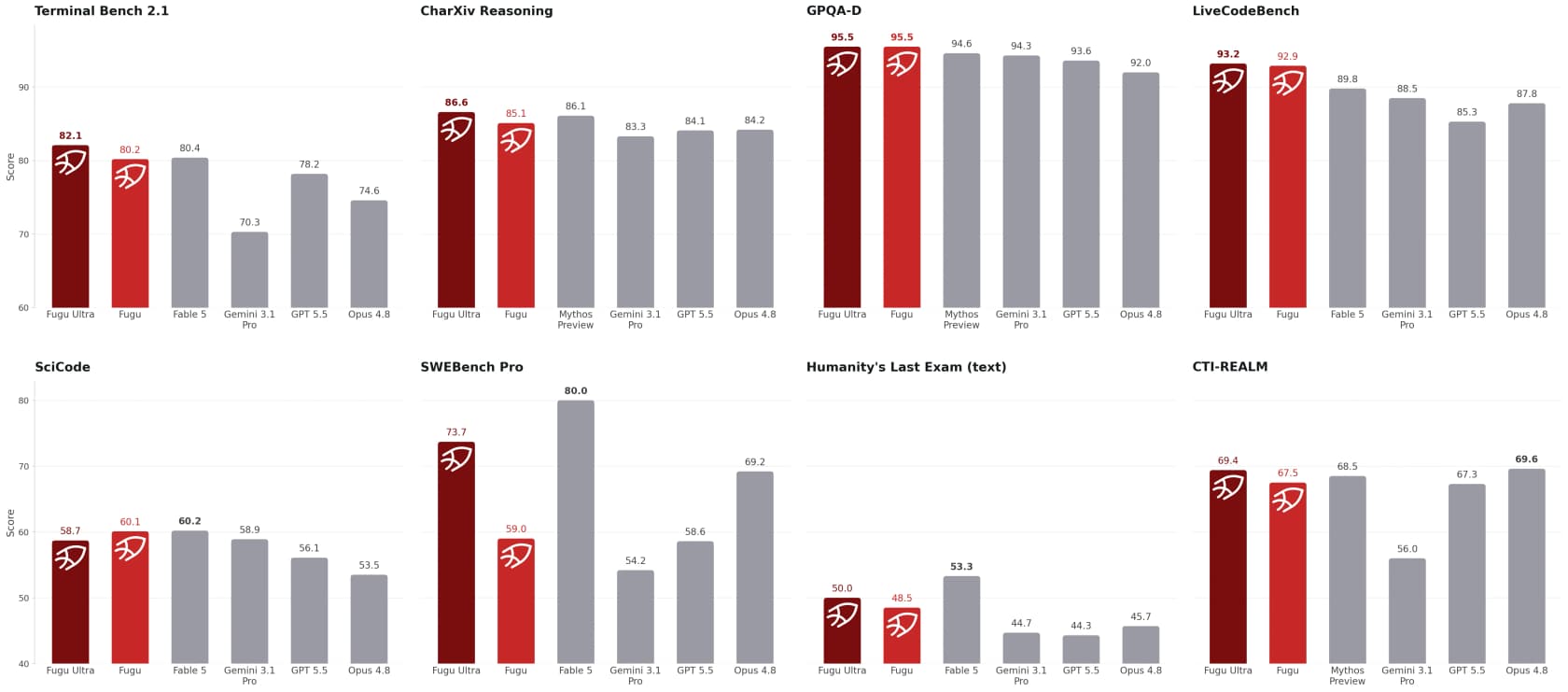
Quelques chiffres remarquables du tableau de Sakana : Fugu Ultra obtient 73,7 au SWE-Bench Pro (vs 69,2 pour Opus 4.8 et 58,6 pour GPT-5.5), 93,2 au LiveCodeBench et 95,5 au GPQA-Diamond, devant toutes les baselines publiques présentées. Les démos qualitatives sont encore plus impressionnantes : Fugu aurait battu trois modèles frontier et un moteur Stockfish de 2100 Elo aux échecs à l'aveugle, et dans un test de trading de séries temporelles a fait passer $10 000 à $11 943 sur une fenêtre de 50 semaines, un rendement moyen de +19,43% qui a battu les autres.
Deux mises en garde honnêtes. Premièrement, ce sont des benchmarks rapportés par le fournisseur, et les modèles les plus puissants (Fable 5, Mythos) ont été exclus de la comparaison en tant que concurrents directs plutôt qu'être battus directement. Deuxièmement, les benchmarks mesurent la capacité de pointe sur les problèmes difficiles, pas si la chose est agréable à utiliser un mardi après-midi. Comme l'a dit un beta testeur, slopdetector, sur Hacker News :
« J'ai utilisé ceci pendant la bêta. Bat GPT-5.5 xhigh sur les tâches complexes. Comme c'est cher et difficile à subventionner, utilisez-le pour les problèmes les plus difficiles... les résultats que j'ai obtenus de fugu-ultra étaient impressionnants. » - slopdetector sur Hacker News
Ce que coûte Sakana Fugu (et le problème que personne ne mentionne)
Il y a deux façons de payer, et les deux incluent l'accès à Fugu et Fugu Ultra.
| Niveau d'abonnement | Prix | Quota d'usage | Pour |
|---|---|---|---|
| Standard | $20/mois | Base | Usage quotidien léger |
| Pro | $100/mois | 10× Standard | Sessions de travail concentrées |
| Max | $200/mois | 30× Standard | Charges de travail lourdes et longues |
(À noter : les cartes tarifaires de Sakana indiquent que Max est 30× Standard tandis qu'une réponse de FAQ dit 20×, donc confirmez le quota avant de vous engager.) Il existe aussi un plan de tokens à l'usage où Fugu Ultra est fixé à $5 d'entrée, $30 de sortie et $0,50 d'entrée mise en cache par million de tokens, passant à $10 / $45 / $1,00 une fois le contexte au-delà de 272K tokens. Et il y a une promo de lancement : abonnez-vous avant fin juillet 2026 pour un deuxième mois gratuit.
Maintenant le problème. Fugu est tarifé au plafond de l'ensemble qu'il achemine, donc le surcoût d'orchestration doit se justifier face à un paiement direct pour un modèle frontier. Plusieurs utilisateurs pratiques ont estimé qu'il ne le faisait pas. La version la plus tranchante est venue de cortesi sur Hacker News :
« Pour $200/mois vous avez moins de 3 heures d'utilisation par semaine, l'API est extrêmement lente, et la qualité de sortie dans mes tests n'est nulle part près de Fable. Ce n'est nulle part près d'être utilisable comme cheval de bataille quotidien. Très décevant. » - cortesi sur Hacker News
C'est l'expérience d'un testeur, pas un verdict, mais cela correspond à plusieurs autres rapportant que la limite de 5 heures s'épuise vite. Si vous avez déjà modélisé les coûts des agents IA face aux agents humains, la leçon est familière : le prix affiché et le coût réel par tâche utile sont des chiffres différents.
Voici une vérification rapide pour savoir si Fugu est le bon outil pour ce que vous faites :
La critique « juste OpenRouter avec des étapes supplémentaires » est-elle justifiée ?
La réaction la plus bruyante au lancement de Fugu, répétée indépendamment sur Hacker News, X et Reddit, était quelque chose comme « n'est-ce pas simplement OpenRouter ? » C'est un instinct légitime, donc prenons-le au sérieux.
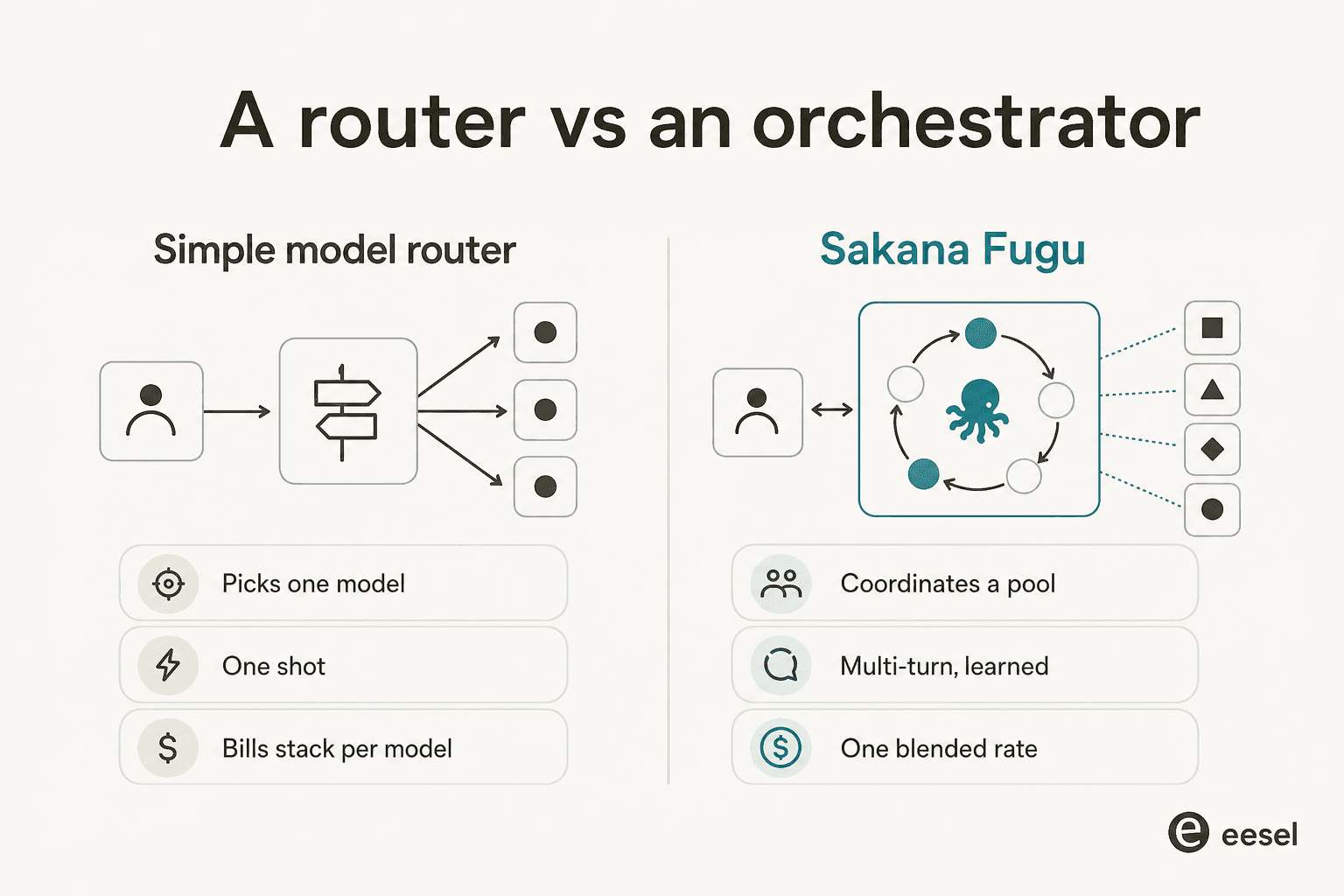
Un simple routeur choisit un modèle et transfère votre requête une fois. Fugu, au moins sur le papier, fait trois choses qu'un routeur ne fait pas : il exécute plusieurs tours, fait que les modèles vérifient mutuellement leur travail, et facture un seul tarif mixte basé sur le modèle supérieur impliqué plutôt que d'empiler la facture de chaque modèle. L'architecture est réelle, et « routeur avancé » sous-estime la boucle multi-tour et d'auto-vérification.
Mais les sceptiques portent un coup réel sur la valeur, pas l'architecture. Comme chenzhekl l'a demandé directement :
« Mais c'est au même prix que les modèles frontier. Pourquoi ne pas payer directement pour les modèles frontier ? » - chenzhekl sur Hacker News
C'est tout le débat en une ligne. L'architecture est plus qu'un routeur ; la question ouverte est de savoir si la coordination supplémentaire vous apporte suffisamment pour justifier de payer les prix frontier pour elle. Mon avis : sur vos problèmes les plus difficiles, vraisemblablement oui ; sur le travail quotidien, probablement non. C'est le même calcul qui apparaît dans les décisions entre agent IA et chatbot basé sur des règles, où plus de sophistication ne vaut que lorsque la tâche est vraiment difficile.
Ce que les gens pensent vraiment de Sakana Fugu
Le sentiment de la communauté, lu équitablement, est mixte à sceptique avec un vrai camp pro. Les partisans avancent l'argument le plus intéressant : que faire vérifier les modèles mutuellement est simplement la bonne parie. Comme l'a soutenu epsteingpt :
« Tout le monde comprend depuis des mois que faire vérifier mutuellement les modèles est la meilleure voie à suivre... Si (grand si) la mécanique d'utilisation fonctionne, c'est en fait une très bonne stratégie anti-grand-modèle. Ils seront incités par votre succès, pas à maximiser les tokens pour leurs investisseurs. » - epsteingpt sur Hacker News
Ce point sur l'alignement des incitations est pertinent, et c'est une vraie raison de soutenir un orchestrateur plutôt qu'un monolithe. Il y a aussi un fil de respect pour le parcours de recherche de Sakana. Comme l'a noté quanto, David Ha a emprunté une voie non conventionnelle vers la recherche en IA, et les travaux antérieurs du laboratoire (Evolutionary Model Merge, l'AI Scientist, Transformer²) sont constamment distinctifs.
Les sceptiques, pendant ce temps, ne sont pas réflexifs. Leurs objections se regroupent autour du coût, de la latence et du cadrage opaque de « un seul fournisseur remplaçant un autre seul fournisseur ». Et quelques notes du monde réel à connaître avant de s'inscrire : Fugu n'est pas encore disponible dans l'UE/EEE, et certains utilisateurs ont exprimé leur malaise face aux contrats militaires de Sakana. Si vous le pesez face aux meilleurs agents IA pour la production, ce ne sont pas des notes de bas de page.
Pourquoi un modèle qui orchestre des modèles est important pour le support
C'est la partie qui m'intéresse le plus, parce que c'est le travail que je fais vraiment. L'idée sous-jacente de Fugu — ne pariez pas votre flux de travail sur un seul modèle, coordinez-en plusieurs et faites-les se vérifier mutuellement — est exactement juste pour l'automatisation à fort enjeu comme le support client. Une mauvaise réponse d'un bot de support n'est pas un raté dans le classement, c'est un remboursement émis par erreur ou un client furieux.
Mais il y a un gouffre entre une API de modèle brut et opaque et quelque chose que vous pouvez mettre en toute sécurité devant des clients. Fugu vous donne l'orchestration ; il ne vous donne pas votre centre d'aide, vos tickets passés, la voix de votre marque, vos règles d'escalade, ni un moyen de tester la chose avant qu'elle passe en production. C'est la couche qui décide vraiment si l'IA pour le service client fonctionne, et c'est pourquoi je préférerais un agent IA dédié au service client plutôt que de câbler manuellement une API frontier. La question d'orchestration sur laquelle nous nous obsédons dans construire versus acheter est la même que celle à laquelle Fugu répond, simplement à une couche différente de la pile.
Essayez eesel
eesel prend la leçon sur laquelle Fugu est construit et l'applique là où elle doit réellement être fiable : votre file de support. Au lieu de vous remettre une API de modèle, c'est un agent IA qui se connecte au helpdesk que vous utilisez déjà (Zendesk, Freshdesk, Help Scout, Slack et plus) en quelques minutes, se forme sur vos tickets passés et votre centre d'aide, et répond avec la voix de votre marque, sans plomberie d'orchestration de modèles requise.

Le différenciateur qui compte le plus ici est la partie que Fugu ne peut pas vous donner : un mode simulation qui rejoue l'agent contre des milliers de vos tickets historiques avant qu'il ne touche jamais un client en direct, pour que vous voyiez le taux de résolution et les réponses exactes à l'avance plutôt que de les découvrir en production. La tarification est basée sur l'usage sans frais par siège, donc le coût évolue avec la valeur plutôt qu'avec les effectifs. Si vous voulez voir à quoi ressemble un service client IA quand l'orchestration est invisible et que les garde-fous sont intégrés, c'est gratuit à essayer.
Questions fréquentes
Qu'est-ce que Sakana Fugu en termes simples ?
En quoi Sakana Fugu diffère-t-il d'OpenRouter ?
Combien coûte Sakana Fugu ?
Sakana Fugu est-il meilleur que Claude ou GPT-5.5 ?
Pour quoi Sakana Fugu est-il le mieux adapté ?
Puis-je utiliser Sakana Fugu pour le support client ?
Sakana Fugu est-il disponible partout ?

Article by
Alicia Kirana Utomo
Kira is a writer at eesel AI with a Computer Science background and over a year of hands-on experience evaluating AI-powered customer service tools. She focuses on breaking down how helpdesk platforms and AI agents actually work so that support teams can make better buying decisions.








