
Le problème des 5 % que votre tableau de bord CSAT ne vous montre pas
Voici la version honnête du fonctionnement de la plupart des programmes CSAT de support : un agent clôture un ticket, un e-mail automatisé est envoyé, et entre 2 % et 10 % des clients répondent réellement.
C'est l'intégralité du jeu de données sur lequel votre tableau de bord est bâti.
Les clients qui répondent ne sont pas représentatifs. Les défenseurs enchantés répondent. Les détracteurs furieux répondent. La vaste majorité satisfaite du milieu, les personnes qui ont obtenu une réponse à leur question, se sont dit « bon, c'était correct » et sont passées à autre chose, ne répondent presque jamais. Donc votre CSAT de 82 % est en réalité un instantané de vos clients les plus bruyants, pondéré vers des extrêmes que vous ne pouvez pas toujours contrôler.
Et c'est pire encore. Une étude de Cresta documente ce que les praticiens savent déjà : les agents déclenchent souvent les sondages de manière sélective, après avoir déjà évalué que le sentiment est positif. Le sondage ne mesure pas l'expérience de support, il mesure les interactions au sujet desquelles l'agent s'est senti suffisamment à l'aise pour demander. Ce n'est pas une métrique ; c'est une compilation des meilleurs moments soigneusement sélectionnés.
« Les agents déclenchent souvent les sondages à leur propre discrétion, souvent seulement après avoir évalué que le sentiment est positif, ce qui finit par déformer la réalité. » - Cresta, The CSAT Mirage
La fatigue des sondages aggrave le problème. Les taux de réponse chutent à mesure que le volume augmente. Les sondages CSAT envoyés à la clôture d'une conversation perdent la texture émotionnelle de l'interaction : la mémoire du client s'estompe, et des facteurs d'humeur accessoires contaminent l'évaluation. Et parce que les sondages courts perdent en profondeur tandis que les sondages longs perdent des répondants, il n'existe aucune solution propre dans le format traditionnel.
L'implication est importante : lorsque votre score de satisfaction client ne bouge pas, le problème n'est peut-être pas l'expérience de support. C'est peut-être la mesure.
Ce qu'est réellement le CSAT IA
Le CSAT prédictif, aussi appelé CSAT inféré, CSAT noté par modèle ou CSAT IA, utilise l'apprentissage automatique pour générer un score de satisfaction pour chaque interaction de support, que le client réponde ou non à un sondage.
Le modèle est entraîné sur des données de conversation historiques associées à des réponses de sondage réelles. Une fois calibré, il prédit la satisfaction avec une précision de 80 à 90 % par rapport aux évaluations vérifiées par des humains. Certains déploiements atteignent un taux de correspondance de 95 %.
Ce que le modèle analyse se répartit en trois catégories :
Signaux linguistiques et NLP :
- Trajectoire du sentiment au fil de la conversation : la frustration augmente-t-elle ou se résorbe-t-elle ?
- Marqueurs linguistiques spécifiques : intention d'annulation, phrases répétées, demandes d'escalade (« passez-moi un responsable »)
- Si la véritable question du client a reçu une réponse directe ou une déflexion
- Changements de ton entre le message d'ouverture et de clôture
Signaux comportementaux et opérationnels :
- Nombre de transferts entre agents : chaque réattribution diminue la satisfaction de manière mesurable
- Vitesse de réponse et temps d'attente par rapport aux attentes du client
- Si le client a recontacté le support dans les 7 jours (un fort signal de churn)
- Si le client a abandonné en milieu de conversation sans résolution
Signaux de qualité de résolution :
- Le problème a-t-il réellement été clôturé, ou seulement marqué comme résolu ?
- Le client a-t-il reformulé le problème à un moment donné (perte de contexte lors d'un transfert) ?
- L'agent a-t-il reconnu la situation du client avant de passer aux solutions ?
Certaines plateformes notent en temps réel pendant la conversation, en faisant remonter des alertes aux superviseurs lorsque la frustration ou l'intention d'annulation s'intensifie, permettant une intervention avant l'escalade. D'autres notent par lots après la clôture. Dans les deux cas, la sortie est une estimation de satisfaction pour chaque interaction, pas un échantillon de 5 %.
Un exemple concret de la différence d'échelle : une grande entreprise de santé est passée de la notation de 5 % des appels de support à 100 % après avoir déployé des outils de contrôle qualité par IA, et a immédiatement commencé à faire émerger des analyses au niveau des tendances que les revues d'appels individuelles n'avaient jamais révélées. Non pas parce que le support s'est radicalement amélioré du jour au lendemain, mais parce qu'ils pouvaient enfin tout voir.
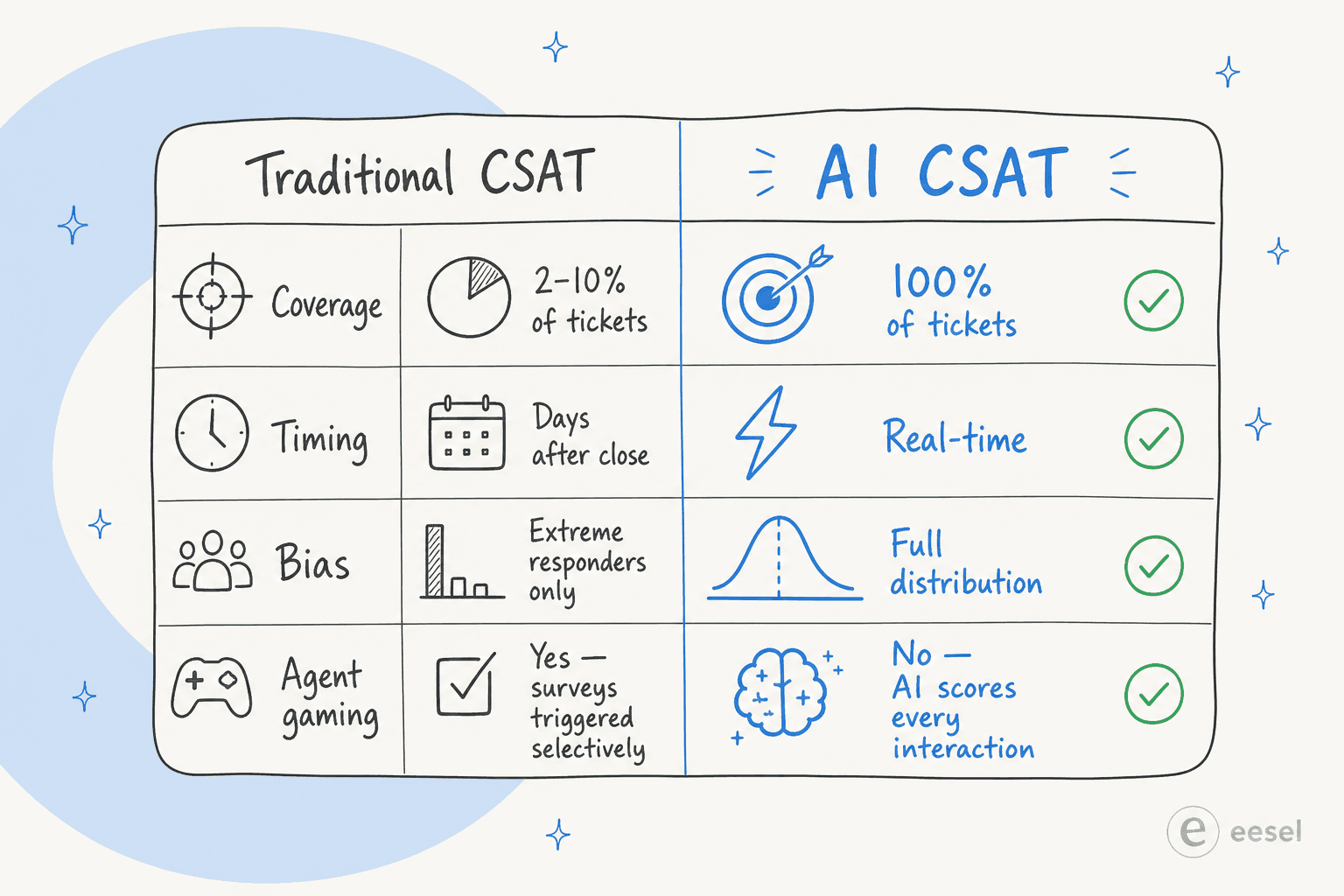
La pile d'analyses complète : les métriques que l'IA met en lumière au-delà du CSAT
Le CSAT est le chiffre vedette. Les métriques qui expliquent pourquoi le CSAT est ce qu'il est, et ce qu'il faut réellement changer, sont celles que l'IA rend visibles automatiquement.
Résolution au premier contact : le plus fort prédicteur du CSAT
Le FCR mesure si le problème d'un client a été résolu à la première tentative, sans nécessiter de contact de suivi. La relation avec le CSAT est presque linéaire : chaque amélioration de 1 % du FCR génère environ 1 % d'amélioration du CSAT, l'étude du SQM Group le confirme de manière constante dans tous les secteurs et verticales.
Le benchmark sectoriel du FCR s'établit à 70-79 % pour le support général, les meilleurs performeurs atteignant 85 %. L'IA fait évoluer ce chiffre en éliminant les causes profondes des contacts répétés : la disponibilité 24h/24 et 7j/7 supprime la boucle du « je rappellerai pendant les heures ouvrées » ; des réponses cohérentes adossées à la connaissance éliminent le problème du « j'ai eu une réponse différente la dernière fois » ; un tri des tickets approprié garantit que la bonne équipe reçoit le ticket en premier.
Le FCR pré-IA tourne généralement autour de 60-75 %. Le FCR post-IA tourne autour de 70-85 %, certains déploiements allant plus haut selon la complexité des tickets et la qualité de la base de connaissances.
Temps de première réponse
Le temps de première réponse (TTFR) correspond à la durée pendant laquelle un client attend avant d'avoir un retour. Le temps de réponse moyen du support par e-mail est de 12 heures 10 minutes, mais les clients attendent moins de 4 heures pour un e-mail B2B et moins de 10 secondes pour le chat en direct. À 5-10 secondes, le CSAT du chat en direct atteint 84,7 %. Au-delà de 30 secondes, il chute fortement.
L'IA élimine complètement cet écart pour les canaux automatisés : la première réponse arrive en quelques secondes. Pour les files d'attente revues par des humains, le tri des tickets assisté par IA et la synthèse des tickets compressent le temps de bascule de contexte avant qu'un humain ne réponde.
Temps de traitement moyen
L'AHT couvre toute la fenêtre de résolution : temps de conversation ou de chat, temps d'attente et traitement post-interaction. Les benchmarks du support général tournent autour de 6-10 minutes en pré-IA ; le support assisté par IA atterrit généralement à 4-7 minutes ; la résolution de tickets entièrement native par IA tourne en dessous de 3 minutes.
Une nuance à connaître : l'AHT augmente initialement lors du premier déploiement de l'IA, car l'IA absorbe les tickets faciles et laisse aux humains les plus difficiles. Sur une montée en puissance de 60 à 90 jours, l'AHT baisse à mesure que les agents reçoivent du contexte généré par l'IA et des brouillons de réponses sur les tickets complexes restants. Le support assisté par IA améliore le débit de 13,8 % de requêtes traitées en plus par heure ; un déploiement IA combiné en début et en fin d'appel atteint une réduction de l'AHT de 25 à 50 % à maturité.
Taux de déflexion
Le taux de déflexion mesure la part des demandes de support traitées entièrement par l'IA ou le self-service qui n'atteignent jamais un agent humain. Les affirmations des fournisseurs ont tendance à mettre en avant 70-80 % de déflexion. Les données de benchmark indépendantes de Zendesk sont plus mesurées : le taux de déflexion médian est de 41,2 %, le quartile supérieur est de 58,7 % et le quartile inférieur de 22,4 %. L'e-commerce et les télécoms penchent vers le haut ; le SaaS B2B et la fintech penchent vers le bas car les tickets sont plus difficiles.
Le taux de déflexion compte pour le coût par résolution. Les résolutions par IA coûtent environ 0,62 $ en moyenne contre 7,40 $ pour les tickets traités par des humains. Mais lisez-le en parallèle du CSAT : une déflexion élevée avec un CSAT en baisse signifie que l'IA clôture des tickets sans les résoudre.
Taux de confinement
Le taux de confinement est la part des conversations qui démarrent avec l'IA et se terminent sans escalade vers un humain. La fourchette cible pour le support propulsé par IA est de 70-90 %.
Le piège : le taux de confinement à lui seul est une métrique de vanité. Un bot qui pousse les clients déroutés à abandonner a un confinement de 100 % et un CSAT catastrophique. Le confinement ne signifie quelque chose que lorsqu'il est lu en parallèle de la qualité de résolution et du CSAT. Si le confinement augmente et le CSAT augmente, l'IA résout des problèmes. Si le confinement augmente et le CSAT baisse, l'IA bloque l'accès à l'aide.
Taux de résolution
Le taux de résolution est la part des tickets que l'IA résout correctement : pas seulement clôture, mais résout réellement. Un point de départ réaliste est de 40-50 % pour la plupart des déploiements ; les systèmes avancés dotés de bases de connaissances bien organisées et de règles d'escalade affinées atteignent 70-85 %.
C'est la métrique que les fournisseurs d'IA honnêtes mettent en avant. Gridwise, une plateforme d'analyse pour conducteurs de l'économie des petits boulots sur Zendesk, a rapporté qu'eesel résolvait 73 % de ses demandes de niveau 1 dès le premier mois, des résultats visibles dans un essai de 7 jours.
« Dès le premier mois, eesel résout 73 % de nos demandes de niveau 1. Notre équipe a mis en œuvre et obtenu des résultats rapidement pendant notre essai de 7 jours. Les réponses sont simples à corriger et à ajuster. La plateforme inclut même des automatisations pour l'étiquetage, l'attribution et les mises à jour de statut des tickets ! » - Kim Simpson, Gridwise (avis G2)
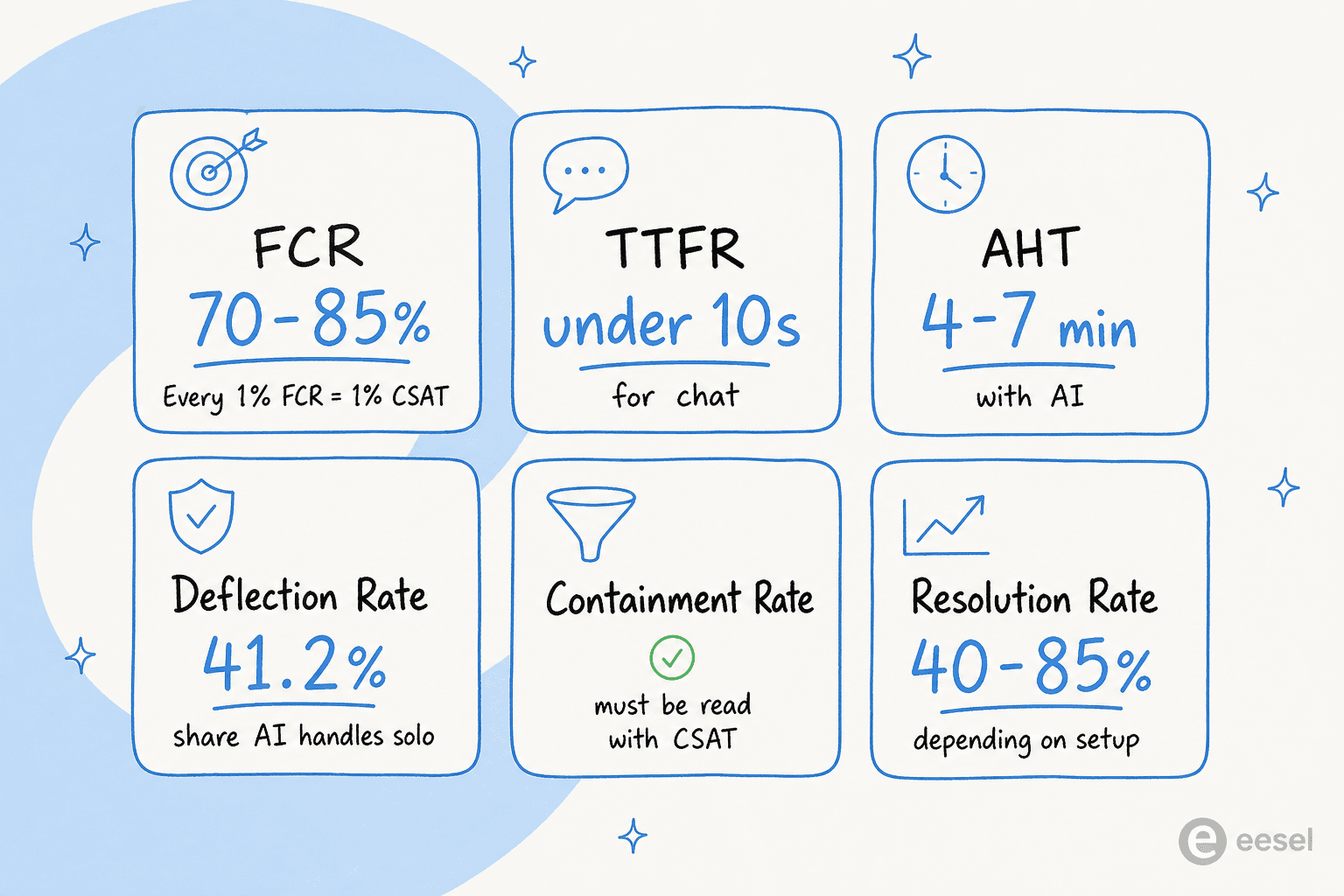
Comment l'IA fait réellement bouger le chiffre du CSAT
Mesurer le CSAT plus précisément ne l'améliore pas intrinsèquement. Ce qui améliore le CSAT, c'est ce que l'IA fait à l'expérience de support elle-même.
Un temps de réponse plus rapide est le levier le plus direct. Les clients qui attendent moins de 10 secondes une première réponse évaluent leur expérience 8 à 14 points plus haut que les clients qui attendent plus de 30 secondes. La première réponse par IA élimine le temps d'attente sur les canaux automatisés, et les brouillons de réponses par IA compressent le temps de réponse humain sur le reste.
Des réponses cohérentes et précises éliminent le cycle des contacts répétés qui détruit simultanément le FCR et le CSAT. Lorsque chaque agent, et chaque IA, puise dans la même base de connaissances et applique les mêmes règles d'escalade, les clients cessent d'entendre des informations contradictoires. La classification des tickets par IA et le tri intelligent acheminent les tickets à la bonne équipe plus rapidement, réduisant l'expérience du « ballotté de service en service » qui plombe la satisfaction.
Les escalades à chaud, l'escalade de chat par IA qui transmet tout l'historique de la conversation, le contexte du client et un résumé généré par l'IA à l'humain qui prend le relais, préviennent le tueur de CSAT le plus courant dans le support hybride : être contraint de réexpliquer le problème à une nouvelle personne. Les études montrent systématiquement que les clients qui bénéficient d'un transfert à chaud évaluent l'interaction humaine plus haut que les clients qui ont subi un transfert à froid pour une qualité de résolution équivalente.
La détection de tendances à grande échelle est la couche d'analyse que le CSAT traditionnel ne peut pas fournir. Lorsque l'IA note 100 % des interactions, vous pouvez voir qu'une catégorie de produits spécifique génère de la frustration à un taux 3 fois supérieur aux autres, que 40 % des escalades surviennent parce que l'IA ne sait pas gérer les litiges de remboursement de plus de 100 $, ou quels agents clôturent les tickets rapidement mais génèrent le plus de réouvertures. Rien de tout cela n'est visible dans un échantillon de 5 %.
« eesel AI rationalise notre flux de travail, booste la productivité et garantit un niveau supérieur de cohérence du service. » - Melissa Ryan, administratrice Zendesk, Discuss.io (avis sur le Zendesk Marketplace)

Les analyses CSAT IA dans les principaux helpdesks
Zendesk
Les analyses natives de Zendesk résident dans Zendesk Explore, qui met en lumière la mesure et le reporting du CSAT, le temps de première réponse, le volume de tickets et les taux de résolution des agents IA. Vous pouvez configurer des rapports planifiés et un envoi par e-mail et construire des métriques calculées sur l'ensemble du tableau de bord. Les métriques de performance de Zendesk, y compris le temps de première réponse et les tickets résolus, remontent toutes nativement via Explore.
Là où Explore est en deçà : il ne génère pas de CSAT prédictif, ne met pas en lumière la qualité des escalades et n'affiche pas la qualité de résolution ventilée par type de ticket. Les analyses des agents IA de Zendesk couvrent une partie de cela pour l'IA native de Zendesk, mais les intégrations tierces étendent considérablement le tableau. Les métriques des agents IA de Zendesk pour suivre les résolutions automatisées et les règles d'escalade vous donnent les entrées ; le tableau de bord d'eesel les combine avec la notation de la qualité de résolution dans une vue unique.
Freshdesk
L'IA Freddy de Freshdesk gère les analyses de base via son module de rapports natif : scores CSAT, volume de tickets, temps de première réponse et temps de résolution sont tous disponibles. Le prix de l'IA Freddy de Freshdesk est lié aux niveaux Copilot et Autopilot, avec une profondeur d'analyse croissante aux niveaux de forfait supérieurs.
La limite est similaire à celle de Zendesk : Freddy Analytics montre ce qui s'est passé, pas pourquoi. La notation de la qualité de résolution et le CSAT prédictif ne sont pas disponibles nativement. Connecter un agent IA avancé à Freshdesk est la voie vers des analyses plus riches : le suivi de résolution d'eesel s'ajoute par-dessus les données natives de Freshdesk plutôt que de les remplacer.
Gorgias
Les analyses de Gorgias se concentrent sur les métriques e-commerce : revenus attribués au support, CSAT issu des sondages post-interaction et taux d'automatisation, la part des tickets traités sans intervention humaine. Gorgias AI Agent 2.0 a ajouté davantage de métriques de tickets automatisés, mais la notation prédictive du CSAT ne fait pas partie de la suite native.
Pour les équipes de helpdesk e-commerce qui souhaitent la pile d'analyses complète, l'intégration d'eesel apporte le suivi de la qualité de résolution et la vue taux de confinement plus CSAT que les rapports natifs de Gorgias ne fournissent pas.
Lire les métriques ensemble : le piège dans lequel tombent la plupart des équipes
Voici où la plupart des déploiements de support IA dérapent : ils optimisent une métrique et en cassent une autre.
Déflexion élevée, CSAT en baisse : l'IA traite les tickets mais ne satisfait pas les clients. Les causes courantes incluent les lacunes de connaissances (réponses sûres d'elles mais erronées), des déclencheurs d'escalade manquants (des tickets qui devraient atteindre des humains restent avec l'IA) ou des échecs d'escalade du chatbot où le contexte est perdu lors du transfert.
AHT en amélioration, FCR stable : l'IA aide les agents à travailler plus vite, mais les problèmes de routage sous-jacents font que les clients recontactent quand même. Corriger le routage et l'exhaustivité de la base de connaissances compte davantage que de gratter quelques secondes sur le temps de traitement.
Confinement en hausse, CSAT inconnu : la combinaison la plus dangereuse. Si l'IA termine des conversations mais que le client est parti frustré sans escalader, vous n'avez aucun signal. C'est exactement là que la notation CSAT par IA comble le vide : elle couvre le silence qui s'enregistrerait autrement comme « pas de plainte, ça devait aller ».
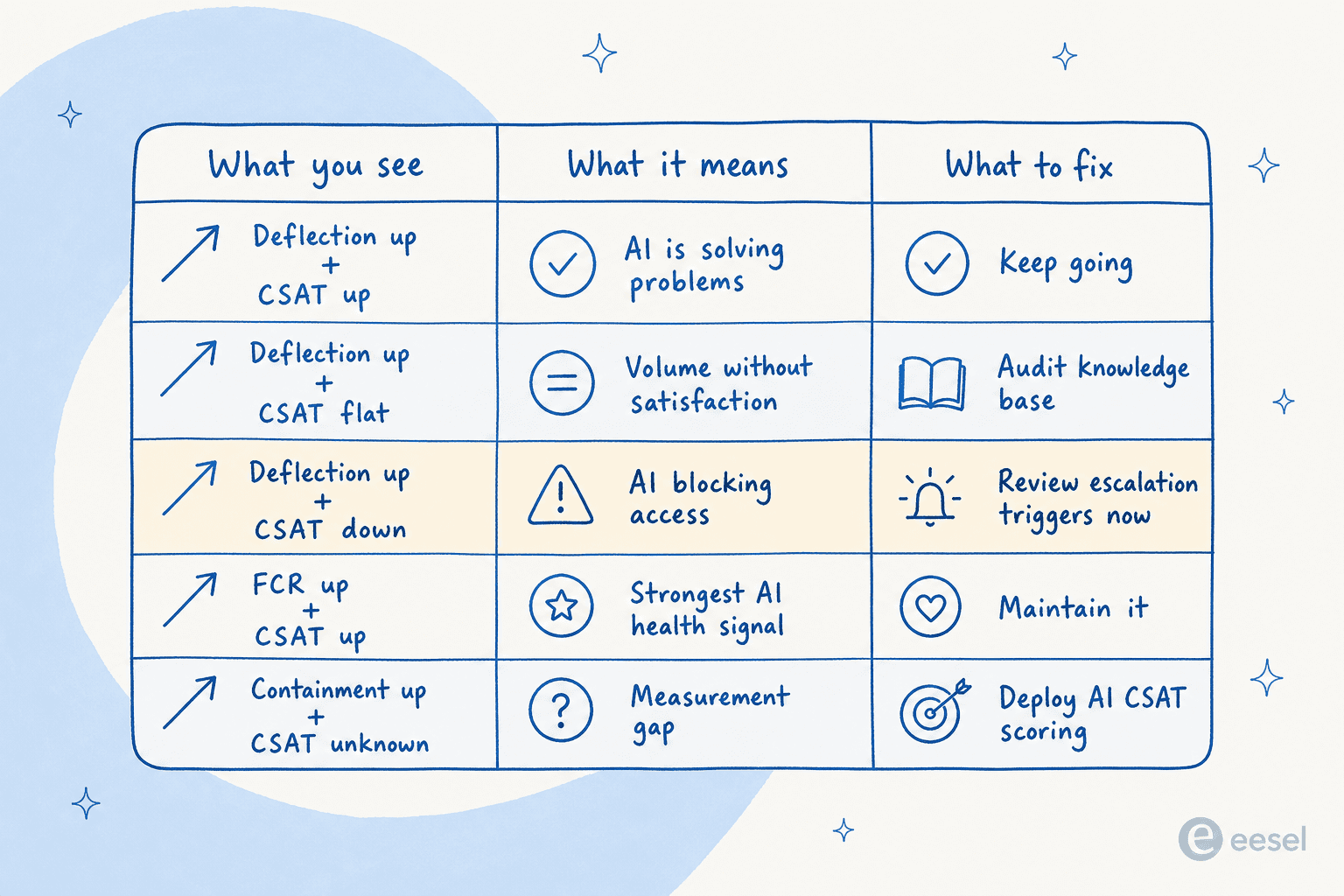
Voici comment lire les signaux ensemble :
| Ce que vous voyez | Ce que cela signifie | Ce qu'il faut corriger |
|---|---|---|
| Déflexion en hausse + CSAT en hausse | L'IA résout les problèmes | Continuez ; affinez les seuils d'escalade |
| Déflexion en hausse + CSAT stable | L'IA gère le volume, pas la satisfaction | Auditez la base de connaissances ; ajustez les seuils de confiance |
| Déflexion en hausse + CSAT en baisse | L'IA bloque l'accès aux humains | Revoyez immédiatement les déclencheurs d'escalade |
| FCR en hausse + CSAT en hausse | Le plus fort signal de bonne santé de l'IA | Documentez ce qui fonctionne ; maintenez-le |
| AHT en baisse + réouvertures en hausse | Les agents clôturent les tickets prématurément | Revoyez les critères de clôture |
| Confinement en hausse + CSAT inconnu | Lacune de mesure | Déployez la notation CSAT par IA pour la combler |
La comparaison du coût par résolution n'a de sens que dans ce contexte. Une IA qui défléchit 60 % des tickets à 0,62 $ par résolution paraît excellente jusqu'à ce que vous découvriez que le taux de recontact est de 40 %, ce qui signifie que ces tickets « résolus » génèrent davantage de travail traité par des humains en aval.
L'autre piège courant est de lire l'IA vs support client humain comme un choix binaire. Les meilleures plateformes d'IA pour le service client utilisent l'IA pour gérer le volume et maintenir des bases de référence cohérentes, et les humains pour les tickets complexes, à fort enjeu et émotionnellement chargés, là où la comparaison du coût d'un agent IA vs un agent humain s'effondre parce que l'interaction humaine compte véritablement.
Trois choses qui font réellement bouger le CSAT IA
1. Priorisez le FCR plutôt que le confinement.
Chaque amélioration de 1 % du FCR génère 1 % de CSAT. Le taux de confinement est une entrée ; le CSAT est la sortie. Réglez vos règles de routage, votre base de connaissances et vos seuils d'escalade pour maximiser les résolutions correctes à la première tentative, et non pour garder les conversations à l'intérieur du bot. L'IA pour la déflexion du support de niveau 1 ne fonctionne comme moteur de CSAT que lorsque les tickets défléchis étaient réellement solubles par l'IA au départ.
2. Auditez la qualité des escalades, pas seulement leur taux.
L'escalade de chat par IA est là où le CSAT se gagne ou se perd dans les déploiements hybrides. Une escalade propre avec tout le contexte récupère la satisfaction client même après une interaction IA frustrante. Un transfert à froid qui perd le contexte multiplie la frustration. Suivre la qualité des escalades séparément du taux d'escalade vous dit si vos transferts fonctionnent. Les meilleurs outils d'assistance aux agents par IA présentent cela comme une métrique de tableau de bord, et non comme quelque chose que vous calculez manuellement.
3. Utilisez le CSAT IA pour trouver les tickets que vous n'auditeriez jamais manuellement.
Lorsque l'IA note 100 % des interactions, les anomalies remontent automatiquement : la catégorie de tickets générant 3 fois la moyenne d'insatisfaction, l'article de la base de connaissances produisant des réponses sûres d'elles mais erronées, le flux de travail d'agent qui mène systématiquement à des réouvertures. L'analyse des tickets de support à cette échelle n'est praticable qu'avec l'IA qui assure la notation. Les meilleurs chatbots de support client par IA présentent de plus en plus cela sous forme d'alertes automatisées : lorsque le CSAT d'une catégorie passe sous un seuil, le système le signale avant que cela ne devienne un problème de churn.
Essayez eesel
eesel est un coéquipier IA pour le service client qui résout les tickets, met en lumière les analyses et mesure la qualité de résolution, sans nécessiter d'outil d'analyse distinct. Le tableau de bord de rapports intégré montre le taux de résolution, la qualité des tickets, le volume d'interactions et les journaux d'activité sur tous les canaux connectés : Zendesk, Freshdesk, Gorgias, Slack, e-mail, Shopify et plus de 100 autres.
La configuration prend quelques minutes plutôt que des mois. Alex Capurro, Chief Innovation Officer chez Global Pay, a rapporté jusqu'à 80 % de gain de temps sur les réponses et l'onboarding après avoir déployé le Copilot IA d'eesel par-dessus Confluence. Gridwise a atteint 73 % de résolution de niveau 1 dès le premier mois. InDebted est à 15 % de déflexion de tickets sur son helpdesk informatique interne avec un objectif de 55 %.
Les analyses ne sont pas un produit distinct : elles sont ce que l'IA génère au fil de son travail. La tarification est à l'usage à 0,40 $ par ticket, sans frais de plateforme ni facturation par siège. Cela revient à 40 $/mois pour 100 tickets ou 400 $/mois pour 1 000, avec des remises sur engagement annuel de 25 % disponibles à partir de 300 $/mois.

Essayez eesel gratuitement : 50 $ de crédit d'utilisation, sans carte bancaire, toutes les fonctionnalités débloquées dès le premier jour.
Questions fréquentes
L'IA peut-elle me fournir automatiquement le CSAT et des analyses de support ?
Qu'est-ce qu'un bon score CSAT pour le support client en 2026 ?
En quoi le CSAT IA diffère-t-il des sondages CSAT traditionnels ?
Quelles analyses de support l'IA peut-elle suivre au-delà du CSAT ?
Ajouter l'IA au support client améliore-t-il réellement le CSAT ?
Qu'est-ce que les analyses CSAT de support client par IA dans Zendesk ?

Article by
Rama Adi Nugraha
Rama is a software engineer at eesel AI with two years of experience writing about B2B SaaS, AI tools, and customer support technology. Based in Bali, Indonesia, he brings a developer's perspective to product comparisons — cutting through marketing copy to what the integrations and APIs actually do.








Comment le taux de déflexion et le CSAT sont-ils liés l'un à l'autre ?