Claude Opus 4.7 : L'avènement du modèle d'ingénieur senior
Stevia Putri
Dernière modification April 20, 2026
La sortie surprise de Claude Opus 4.7 n'est pas juste une simple amélioration de benchmark. Alors que nous nous sommes habitués à ce que les modèles deviennent légèrement meilleurs en mathématiques ou en codage à chaque itération, cette mise à jour marque un changement distinct dans la manière dont ces systèmes se comportent. C'est le passage d'un assistant passif qui suit les ordres à un collaborateur qui réfléchit, planifie et, à l'occasion, exprime son désaccord.
Anthropic positionne Claude Opus 4.7 comme un modèle conçu pour le travail d'ingénierie de niveau senior, et les premiers retours de la communauté des développeurs suggèrent qu'ils ont atteint leur objectif. Il ne s'agit pas tant des scores bruts que de la « discipline épistémique » dont fait preuve le modèle : la capacité à savoir ce qu'il ignore et à vérifier son propre travail avant de vous le présenter.

Analysons pourquoi cette version est importante pour votre flux de travail et comment elle modifie le paysage des agents IA en 2026.
Le changement comportemental : Pourquoi Claude Opus 4.7 ressemble à un ingénieur senior
Le point le plus intéressant du lancement de Claude Opus 4.7 n'était pas les graphiques. C'étaient les témoignages d'entreprises comme Replit, Hex et Cognition. Elles décrivent un modèle façonné vers une nouvelle personnalité : celle d'un ingénieur senior plutôt que celle d'un assistant serviable.
Ce changement se manifeste par trois comportements clés :
- Planification et vérification : Au lieu de se lancer directement dans le code, le modèle planifie son approche et détecte ses propres erreurs logiques avant l'exécution.
- Volonté de contredire : Il apporte une perspective plus affirmée. Si vous proposez une architecture sous-optimale, Opus 4.7 est plus susceptible de vous contredire et de suggérer une meilleure alternative plutôt que de simplement être d'accord avec vous.
- Persévérance face à l'échec : Dans les boucles agentiques, il continue de s'exécuter malgré des échecs d'outils qui auraient stoppé net les modèles précédents.
Un PDG chez Replit a récemment partagé : « Personnellement, j'adore la façon dont il exprime son désaccord lors des discussions techniques pour m'aider à prendre de meilleures décisions. On a vraiment l'impression d'avoir un meilleur collègue. »
Chez eesel AI, nous considérons cela comme un moment charnière pour l'automatisation du contenu et du support. Lorsque vous embauchez un coéquipier IA pour gérer des recherches ou une rédaction complexe, vous ne voulez pas seulement un rédacteur rapide, vous voulez un coéquipier qui comprend les nuances de votre marque et qui peut corriger lui-même sa production.
Vision haute résolution : 3 fois plus de détails pour les tâches complexes
La vision a toujours été un goulot d'étranglement pour les agents IA chargés de naviguer dans des interfaces utilisateur complexes ou de lire des documents techniques denses. Claude Opus 4.7 élimine efficacement ce goulot d'étranglement grâce à un saut massif dans la prise en charge de la résolution.
Le modèle prend désormais en charge des images allant jusqu'à 2576 pixels sur le bord long (~3,75 mégapixels), ce qui représente plus de trois fois la fidélité des modèles Claude précédents. Pour les développeurs qui créent des agents « d'utilisation informatique », c'est la différence entre une capture d'écran floue et une carte parfaite au pixel près de l'interface.
Voici comment ce saut en matière de vision se traduit dans la pratique :
- Coordonnées pixel 1:1 : Les coordonnées du modèle correspondent désormais directement aux pixels réels. Cela signifie qu'il n'y a plus de calculs de facteur d'échelle ou de devinettes sur l'emplacement d'un bouton sur un écran haute résolution.
- Analyse de diagrammes techniques : Il peut lire des structures chimiques, des plans architecturaux et des diagrammes d'ingénierie complexes avec une précision beaucoup plus élevée.
- Extraction de données : Il peut transcrire des données à partir de tableaux de bord et de chiffres denses qui étaient auparavant illisibles.
Un CTO chez XBOW a noté : « Notre plus gros point de douleur avec Opus a effectivement disparu, et cela débloque son utilisation pour toute une classe de travail pour laquelle nous ne pouvions pas l'utiliser auparavant. »
Puissance de l'API : effort xhigh et budgets de tâches
Pour ceux qui développent sur la plateforme Claude, Opus 4.7 introduit de nouveaux contrôles qui vous permettent d'ajuster le compromis entre intelligence et coût.
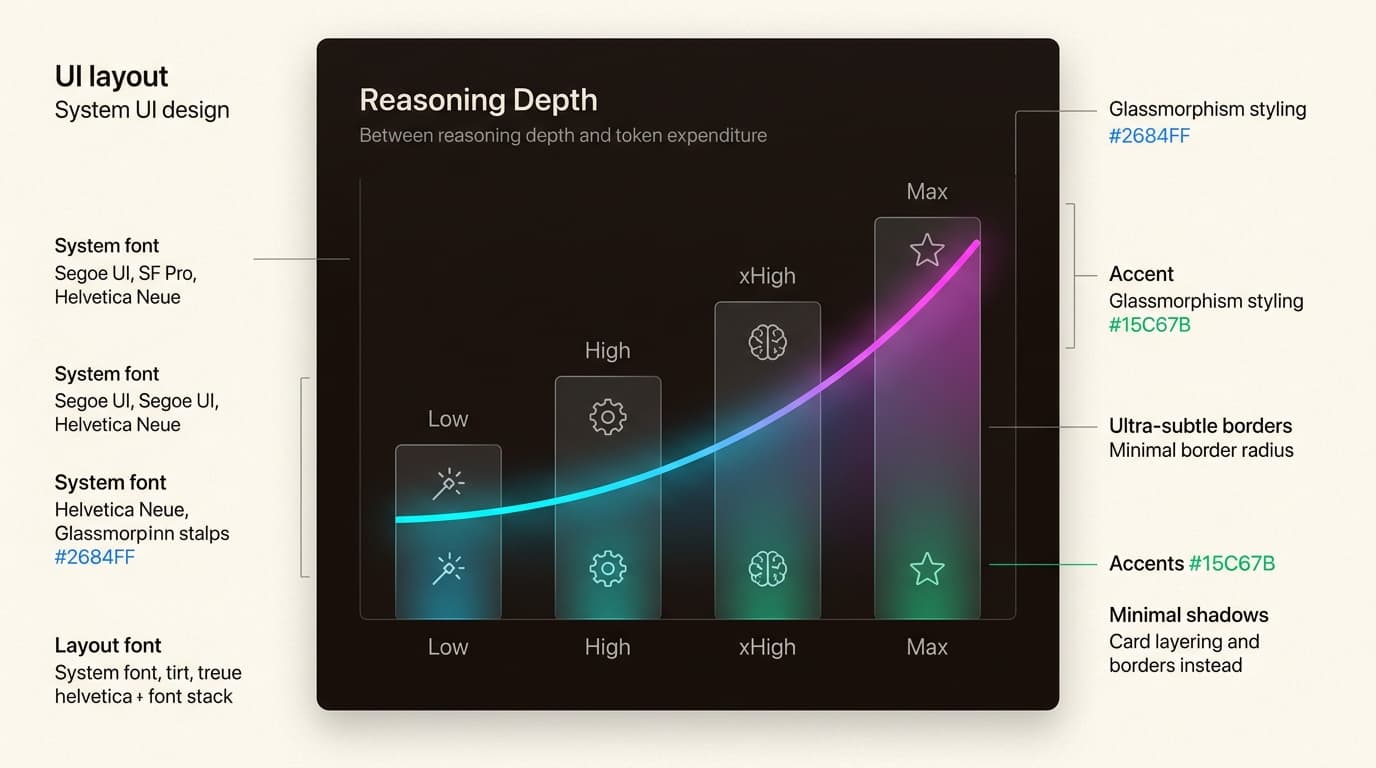
Le nouveau niveau d'effort xhigh
Le paramètre d'effort a été étendu avec un nouveau niveau xhigh (« extra élevé »). Il se situe entre high et max, offrant une capacité de raisonnement plus profonde qui est désormais la valeur par défaut pour Claude Code.
Commencez avec le niveau d'effort xhigh pour :
- Les tâches de refactorisation complexes
- La recherche de bugs profondément ancrés dans de grandes bases de code
- Les boucles agentiques à long terme où la qualité est primordiale
Budgets de tâches (bêta)
Anthropic introduit également les budgets de tâches en version bêta publique. Cela donne au modèle une allocation de jetons cible pour une boucle agentique complète. Contrairement à max_tokens, qui est un plafond strict dont le modèle n'a pas conscience, Claude peut voir un compte à rebours de son budget de tâche et l'utiliser pour prioriser le travail.
Si le budget devient faible, le modèle essaiera de terminer la tâche en douceur plutôt que de s'arrêter au milieu d'une phrase. C'est un outil pour limiter le travail à une allocation de jetons spécifique, bien que vous deviez expérimenter avec la limite minimale de 20 000 jetons pour trouver le point idéal pour votre cas d'utilisation.
Le paradoxe des prix : mêmes tarifs, nouveau tokenizer
Sur le papier, la tarification de Claude Opus 4.7 reste inchangée par rapport à Opus 4.6 : 5 $ par million de jetons d'entrée et 25 $ par million de jetons de sortie. Cependant, il existe une variable cachée que vous devez prévoir : le tokenizer mis à jour.
Le nouveau tokenizer améliore la façon dont le modèle traite le texte, mais cela signifie également que la même entrée peut correspondre à plus de jetons (environ 1,0x à 1,35x plus selon votre type de contenu). Cela entraîne effectivement une légère augmentation des coûts pour le même volume de texte brut.
Pour gérer cela, vous devriez vous appuyer sur :
- La mise en cache des invites (Prompt caching) : Économisez jusqu'à 90 % sur les coûts d'entrée pour un contexte répétitif.
- Le traitement par lots (Batch processing) : Obtenez 50 % d'économies pour les tâches qui ne sont pas sensibles au temps.
- L'ajustement de l'effort : Utilisez
highau lieu dexhighpour les tâches plus simples afin de garder l'utilisation des jetons sous contrôle.
Ceci est particulièrement pertinent lors de la comparaison de Claude avec d'autres modèles comme GPT-4 et Gemini. Bien que le prix par jeton puisse sembler identique, le coût « réel » par tâche dépend désormais davantage de la mesure dans laquelle le modèle « réfléchit » aux niveaux d'effort plus élevés.
Guide de migration : Passer de Claude Opus 4.6 à 4.7
La mise à niveau vers Claude Opus 4.7 est conçue pour être une mise à niveau directe, mais vous voudrez ajuster votre implémentation pour obtenir les meilleurs résultats.
| Changement | Recommandation |
|---|---|
| Marge de manœuvre | Augmentez votre limite max_tokens pour tenir compte du changement de tokenizer de 1,0x-1,35x. |
| Échafaudage | Supprimez les invites telles que « vérifie deux fois ton travail » ou « planifie soigneusement ». Opus 4.7 le fait nativement. |
| Effort | Passez à xhigh pour vos tâches de codage et agentiques les plus difficiles. |
| Budgets | Implémentez des budgets de tâches pour les agents autonomes afin d'éviter les boucles infinies. |
Si vous utilisez déjà des coéquipiers IA pour automatiser des flux de travail de codage complexes, vous constaterez probablement une amélioration immédiate de la fiabilité. Le modèle surmonte les échecs d'outils qui nécessitaient auparavant une intervention manuelle, rendant l'expérience de « coéquipier » beaucoup plus fluide.
Pour les professionnels de la sécurité, il existe également le nouveau programme de vérification cybernétique (Cyber Verification Program). Il permet aux utilisateurs vérifiés de contourner les protections cybernétiques en temps réel pour des recherches légitimes, telles que les tests d'intrusion et la recherche de vulnérabilités.
Conclusion
Claude Opus 4.7 est un aperçu de la direction que nous prenons : nous nous éloignons des chatbots pour nous diriger vers des coéquipiers autonomes. En optimisant le raisonnement soutenu et les comportements de « senior » comme le fait de contredire les mauvaises idées, Anthropic a construit un modèle à qui l'on peut confier davantage de responsabilités.
Que vous construisiez un tableau de bord, déboguiez une condition de concurrence ou automatisiez votre file d'attente de support, le changement de comportement compte bien plus que les benchmarks. Il est enfin temps d'arrêter de materner vos agents et de commencer à collaborer avec eux.
Questions fréquemment posées
Share this article

Article by
Stevia Putri
Stevia Putri is a marketing generalist at eesel AI, where she helps turn powerful AI tools into stories that resonate. She’s driven by curiosity, clarity, and the human side of technology.