
Seamos realistas: la IA está en todas partes en el mundo del desarrollo. La idea de conectarla a algo como Bitbucket para acelerar las cosas ya no es ciencia ficción. Es una forma real de hacer más, escribir mejor código y, quizás, incluso lanzar productos un poco más rápido. Pero intentar averiguar cómo hacerlo realmente puede parecer como navegar por un pantano de jerga de marketing.
Esta guía está aquí para acabar con todo ese ruido. Vamos a ver qué son las integraciones de OpenAI Codex con Bitbucket, qué puedes hacer realmente con ellas, las diferentes formas de configurarlas y los obstáculos con los que casi seguro te encontrarás.
Al final, tendrás una idea mucho más clara de cómo conectar estas herramientas de una manera que resuelva problemas reales para tu equipo de desarrollo.
¿Qué son las integraciones de OpenAI Codex con Bitbucket?
Antes de entrar en el "cómo", debemos estar en la misma página sobre el "qué". El espacio de la IA se mueve increíblemente rápido, así que aclaremos nuestras definiciones. Hará que todo lo demás encaje.
¿Qué es Bitbucket?
Probablemente ya lo conozcas, pero por si acaso: Bitbucket es la plataforma Git de Atlassian para alojar y colaborar en código. Es muy parecido a sus competidores, pero su superpoder es lo bien que encaja en la familia Atlassian, especialmente en Jira. Los equipos a menudo lo eligen por sus sólidos pipelines de CI/CD y su enfoque en características de nivel empresarial y seguridad.

¿Qué es OpenAI Codex? Una aclaración necesaria
Bien, aquí es donde las cosas se complican un poco. Si has estado siguiendo la IA durante un tiempo, recordarás el modelo original de OpenAI Codex. Fue la tecnología detrás de las primeras versiones de GitHub Copilot y en su momento parecía magia. Bueno, ese modelo específico fue retirado oficialmente en marzo de 2023.
Entonces, ¿qué significa eso para nosotros hoy?
-
OpenAI ahora usa el nombre "Codex" para un agente de ingeniería de software más nuevo y ambicioso que puede abordar proyectos de codificación completos.
-
Las capacidades del Codex original han sido completamente absorbidas y superadas por modelos de lenguaje grandes (LLM) más nuevos, como la serie GPT-4.
Así que, para el resto de esta guía, cuando decimos "integraciones de OpenAI Codex", en realidad estamos hablando de usar los modelos de lenguaje más recientes y avanzados de OpenAI para realizar tareas de codificación dentro de tu flujo de trabajo de Bitbucket.
¿Qué puedes hacer realmente con las integraciones de OpenAI Codex con Bitbucket?
El objetivo de configurar estas integraciones es deshacerse de las partes aburridas y repetitivas del día a día de un desarrollador. Cuando lo haces bien, conectar una IA a tu repositorio es como tener un desarrollador junior extra en tu equipo que trabaja 24/7 y nunca se cansa. Aquí hay algunas de las cosas más populares que la gente está haciendo:
-
Revisiones de código automatizadas: Imagina una IA que hace una primera revisión de cada pull request. Podría añadir comentarios automáticamente señalando errores de sintaxis, sugiriendo ajustes basados en la guía de estilo de tu equipo o marcando código que parece un poco sospechoso. Esto no significa que tus desarrolladores senior se queden sin trabajo; solo significa que no tienen que perder tiempo en las cosas pequeñas y pueden centrarse en la arquitectura general.
-
Resúmenes de pull requests generados por IA: Todos hemos pasado por eso, mirando una PR con una descripción que solo dice "corrección de error". Una IA puede leer los mensajes de los commits y los cambios en el código para redactar un resumen claro de lo que está sucediendo. Esto le ahorra unos minutos al desarrollador y les da a los revisores el contexto que necesitan para empezar de inmediato.
-
Preguntas y respuestas inteligentes sobre el código: Esto es algo muy importante. Permite a los desarrolladores hacer preguntas en lenguaje natural sobre el código y obtener respuestas inmediatas. Cosas como, "¿Qué cambió en la API de pagos en esta PR?" o "Muéstrame dónde está la lógica de autenticación de usuario". Es como tener un compañero de equipo con una memoria fotográfica perfecta de toda la base de código.
-
Documentación automatizada: Seamos sinceros, la documentación casi siempre está desactualizada. Una integración puede actualizar automáticamente tus READMEs, wikis internas o la documentación de la API cada vez que el código que describe cambia. Este es un paso gigantesco para resolver finalmente el problema de la documentación obsoleta.
Métodos actuales para integrar OpenAI Codex con Bitbucket
Entonces, ¿cómo se conecta todo esto? Tienes algunas opciones, cada una con su propio equilibrio de facilidad, potencia y precio.
Funcionalidades de IA nativas de Atlassian
Atlassian está incorporando sus propias herramientas de IA, como Atlassian Intelligence y Rovo, directamente en Bitbucket. Son útiles para cosas simples, como generar una descripción de una PR con un solo clic.
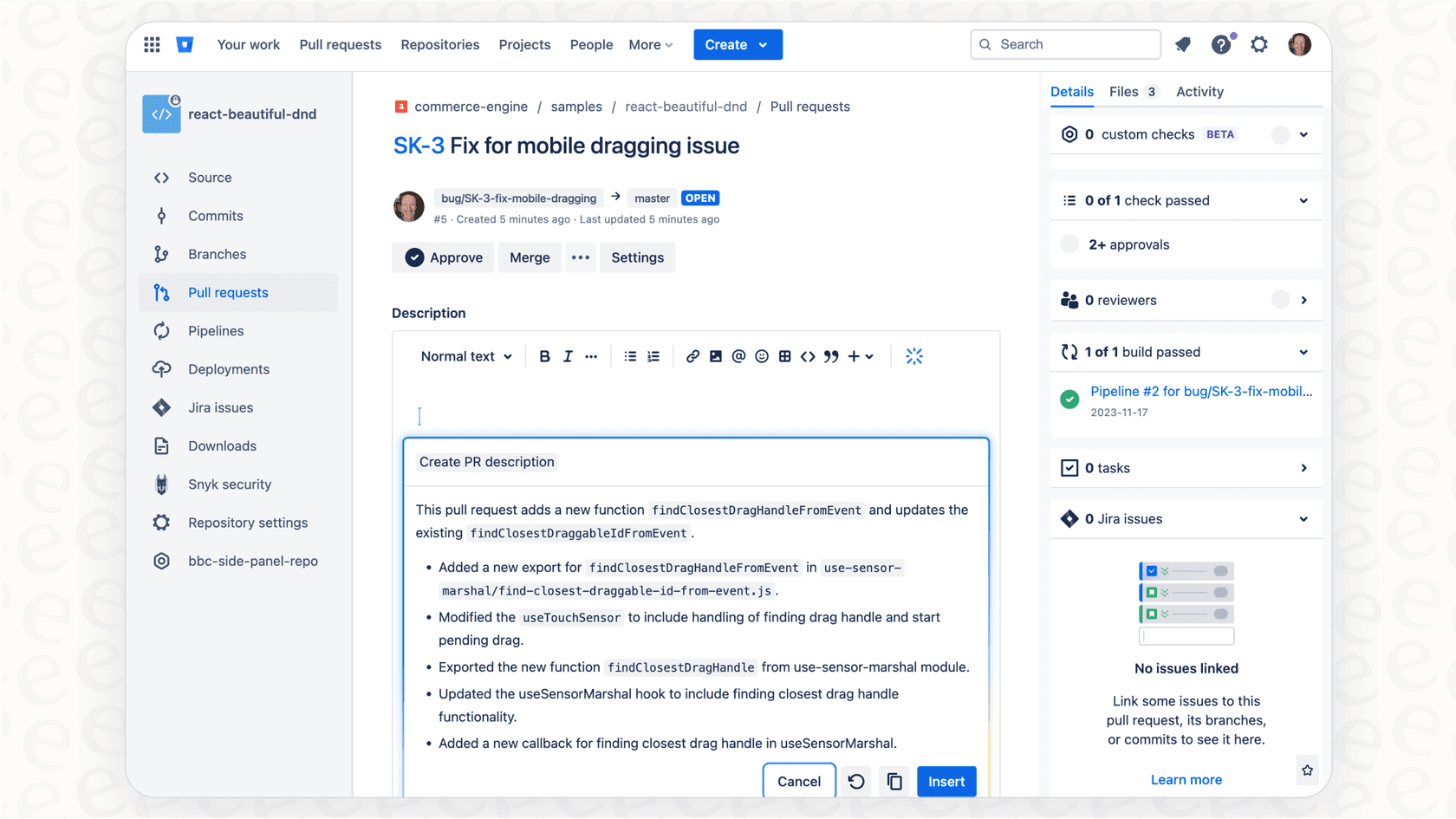
El problema es que estás jugando en el terreno de Atlassian. Estas herramientas son convenientes, pero no siempre tienen toda la potencia o flexibilidad de usar los modelos de OpenAI directamente. Si tienes en mente un flujo de trabajo específico y personalizado o necesitas hacer un análisis de código muy profundo, probablemente encontrarás que las funciones integradas son un poco limitadas.
Plataformas de integración de terceros
Han surgido un montón de plataformas sin código y de bajo código para actuar como el pegamento entre diferentes aplicaciones, como Albato, Latenode y Autonoly. Son bastante buenas para crear flujos de trabajo simples del tipo "si pasa esto, haz aquello". Por ejemplo, podrías configurar fácilmente una regla: "Cuando se abra una nueva pull request en Bitbucket, envía el código a OpenAI y publica su resumen como un comentario".
graph TD A[New Pull Request in Bitbucket] --> B{Third-Party Platform}; B --> C[Send Code to OpenAI API]; C --> D{Generate Summary}; D --> E[Post Summary as Comment in Bitbucket];
La desventaja es que estas plataformas pueden ser caras, y sus activadores predefinidos a menudo no tienen suficiente contexto sobre tu repositorio para proporcionar información realmente profunda. una simple llamada a la API puede resumir un cambio en un archivo, pero no puede decirte por qué ese cambio va en contra de una decisión que tu equipo tomó hace seis meses.
Scripts personalizados con Bitbucket Pipelines
Esta es la opción más potente y que requiere remangarse. Puedes escribir un script (por ejemplo, en Python) que se ejecute como parte de un Bitbucket Pipeline cada vez que ocurra un evento como un "git push". El script puede entonces llamar a la API de OpenAI con las instrucciones que quieras y gestionar la respuesta.
La ventaja es el control total. Puedes ajustar tus prompts, construir lógicas complejas y crear un flujo de trabajo que se ajuste perfectamente a tu equipo. La desventaja obvia es que requiere el tiempo y el esfuerzo de un desarrollador para construirlo y mantenerlo. Es, con diferencia, la opción que más trabajo requiere, y estos scripts personalizados a veces pueden ser frágiles.
Los desafíos ocultos (y cómo resolverlos)
Lograr que dos APIs se comuniquen suele ser la parte fácil. La parte difícil, donde la mayoría de los equipos se atascan, es hacer que la integración sea genuinamente útil. Aquí están los problemas reales que encontrarás y cómo pensar en ellos.
La brecha de contexto: una IA sin conocimiento de la empresa
Este es, sin lugar a dudas, el mayor problema al que te enfrentarás. Una llamada estándar a la API de OpenAI no tiene ni idea de los estándares de codificación de tu empresa, las decisiones de arquitectura o el historial del proyecto. Da consejos genéricos que pueden ser técnicamente correctos pero totalmente equivocados para tu base de código específica. Podría sugerir usar una biblioteca que has prohibido o recomendar un patrón que al líder de tu equipo no le gusta en absoluto.
Aquí es donde necesitas más que una IA inteligente; necesitas una capa de inteligencia que entienda tu organización. Mientras que OpenAI proporciona la potencia, una plataforma como eesel AI aporta ese contexto crítico. Se conecta a todo el conocimiento de tu empresa, no solo al código. Estamos hablando de documentos de diseño en Confluence, historial de proyectos en Jira Service Management e incluso debates técnicos en Slack. Al unir todo esto, eesel AI te ayuda a construir un asistente que da respuestas que son realmente relevantes para cómo trabaja tu equipo.
El dolor de cabeza de la configuración: herramientas simples vs. necesidades complejas
A menudo te quedas atascado en una situación frustrante. Las herramientas sin código son sencillas para empezar, pero no son lo suficientemente flexibles para el trabajo de ingeniería real. Los scripts personalizados son potentes pero pueden convertirse en una enorme carga de mantenimiento. No hay un buen punto intermedio para construir flujos de trabajo de IA sofisticados sin necesitar un equipo para gestionarlos.
Aquí es donde el enfoque de "listo en minutos" de eesel AI resulta útil. Es una plataforma de autoservicio que tiene como objetivo darte el poder de una solución personalizada sin todos los quebraderos de cabeza de ingeniería. Con integraciones sencillas para tus herramientas existentes, puedes configurar potentes agentes de IA a través de un panel de control, lo que te proporciona tanto facilidad de uso como una personalización profunda.
El déficit de confianza: ¿cómo implementar la IA de forma segura?
Esta es la gran pregunta: ¿cómo puedes confiar en que una IA empiece a comentar las pull requests de tu equipo sin un montón de pruebas? Dejar una IA suelta en tu flujo de trabajo principal es un riesgo enorme. ¿Y si da consejos terribles, confunde a la gente o simplemente crea más ruido?
La mayoría de las herramientas simplemente pasan por alto este problema, pero eesel AI lo convierte en una prioridad. Tiene un modo de simulación que te permite probar tu agente de IA en miles de tus PRs o tickets de soporte pasados en un entorno seguro y aislado. Puedes ver exactamente cómo se habría comportado, obtener pronósticos sobre su rendimiento y ajustarlo hasta que sea perfecto, todo antes de que interactúe con un solo desarrollador. Esto te permite implementar la IA con confianza, no solo con esperanza.
Pasando de una simple conexión a una inteligencia real
Conectar OpenAI a Bitbucket puede ser de gran ayuda para automatizar las tareas aburridas, mejorar la calidad del código y ayudar a tu equipo a moverse más rápido. Como hemos visto, tienes varias formas de hacerlo, desde funciones integradas hasta scripts totalmente personalizados.
Pero una gran integración es algo más que conectar dos APIs. La verdadera magia ocurre cuando puedes darle a la IA el contexto que necesita para entender el conocimiento único de tu equipo. Los mayores beneficios llegan cuando tienes un flujo de trabajo potente que sigue siendo fácil de gestionar y una forma de probarlo e implementarlo sin correr grandes riesgos.
Resolver estos desafíos en torno al contexto, la complejidad y el control es exactamente para lo que están diseñadas las plataformas de IA modernas, convirtiendo una simple llamada a la API en un sistema inteligente que realmente funciona para tu equipo.
Unifica tu conocimiento de ingeniería con eesel AI
¿Listo para construir un asistente de IA que realmente entienda a tu equipo? ¿Uno que pueda responder preguntas técnicas difíciles aprovechando el cerebro colectivo de tu equipo?
Conecta tus herramientas de desarrollo como Confluence, Jira Service Management y Slack con eesel AI. Dale a tu equipo una IA interna que proporcione respuestas instantáneas y precisas basadas en el propio conocimiento de tu empresa. Puedes tenerlo funcionando en minutos, no en meses.
Preguntas frecuentes
¿A qué se refieren exactamente hoy las integraciones de OpenAI Codex con Bitbucket, dado que el modelo Codex original fue retirado?
Hoy en día, cuando hablamos de integraciones de OpenAI Codex con Bitbucket, nos referimos a usar los modelos de lenguaje más recientes y capaces de OpenAI, como la serie GPT-4, para tareas relacionadas con la codificación dentro de tus flujos de trabajo de Bitbucket. Las capacidades del modelo Codex original han sido superadas y ahora están integradas en estos LLM más nuevos y potentes.
¿Cuáles son algunas aplicaciones prácticas de las integraciones de OpenAI Codex con Bitbucket para mejorar la eficiencia de un equipo de desarrollo?
Estas integraciones pueden aumentar significativamente la eficiencia a través de revisiones de código automatizadas que señalan problemas, resúmenes de pull requests generados por IA para una comprensión más rápida y preguntas y respuestas inteligentes sobre el código para obtener respuestas instantáneas sobre la base de código. También pueden automatizar las actualizaciones de la documentación, reduciendo el esfuerzo manual.
¿Cuáles son los principales métodos disponibles para configurar las integraciones de OpenAI Codex con Bitbucket?
Puedes integrarlas usando las funciones de IA nativas de Atlassian (como Atlassian Intelligence), aprovechar plataformas de integración de terceros para flujos de trabajo más simples o crear scripts personalizados que se ejecuten dentro de Bitbucket Pipelines para un control y flexibilidad máximos. Cada método ofrece diferentes niveles de facilidad y potencia.
¿Cómo pueden los equipos asegurarse de que pueden confiar en los resultados y desplegar de forma segura las integraciones de OpenAI Codex con Bitbucket?
Para generar confianza, los equipos deben utilizar modos de simulación que permitan probar agentes de IA con datos pasados en un entorno seguro y aislado. Esto te ayuda a observar el comportamiento, prever el rendimiento y perfeccionar la IA antes de que interactúe directamente con los flujos de trabajo de desarrollo en vivo, mitigando los riesgos.
¿Existen limitaciones específicas a considerar al usar herramientas más simples para las integraciones de OpenAI Codex con Bitbucket?
Las herramientas más simples y sin código pueden ser fáciles para empezar, pero a menudo carecen del contexto profundo sobre tu repositorio o de la flexibilidad para flujos de trabajo de ingeniería complejos. Sus activadores predefinidos pueden no proporcionar suficiente información matizada para una asistencia de IA verdaderamente perspicaz o personalizada.

