Why "Devin Fusion pricing" doesn't exist (and what to price instead)
If you came here expecting a Fusion price tag, here's the reframe worth having up front. Devin Fusion is a harness, not a model and not a plan. Cognition announced it on June 29, 2026 and shipped it in preview inside Devin the same day. It runs behind the scenes on the plans you already pay for, deciding which model handles which part of a task.
So the thing to actually price is Devin itself, and then to understand how Fusion moves the usage meter underneath your plan. That's the split this post follows: the flat plan fees first, then the variable cost that Fusion is designed to shrink.

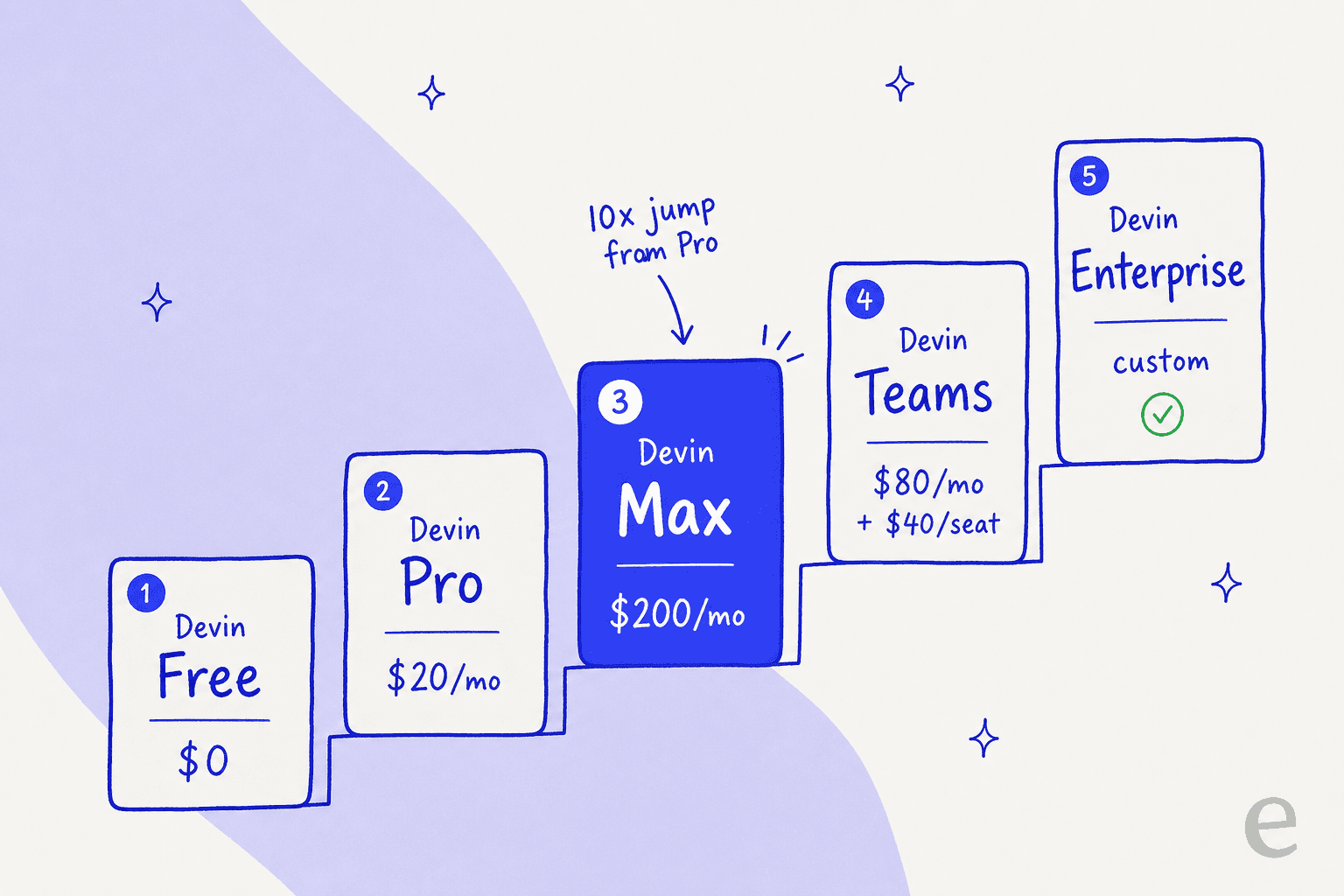
Devin pricing at a glance (2026)
Here's every current plan, pulled from devin.ai/pricing. Self-serve plans (everything except Enterprise) run on a token-based quota; Enterprise runs on ACUs.
| Plan | Price | Members | Concurrent sessions | What you get |
|---|---|---|---|---|
| Free | $0 | 1 | Up to 10 | Light quota, limited model choice, unlimited inline edits + Tab completions |
| Pro (popular) | $20/mo | 1 | Up to 10 | Frontier models (OpenAI, Claude, Gemini), free SWE-1.6, Devin Cloud agents, can buy extra usage at API prices |
| Max (new) | $200/mo | 1 | Unlimited | Everything in Pro, significantly higher quotas |
| Teams | $80/mo base + $40/mo per full dev seat | Unlimited | Unlimited | Everything in Pro, shared collaboration, admin dashboard + analytics, priority support |
| Enterprise | Contact sales | Unlimited | Unlimited | SAML/OIDC SSO, VPC deployment, enterprise admin controls, dedicated support; billed in ACUs |
A couple of things worth knowing that the table hides:
- Grandfathered prices exist. If you were already on Pro or Teams before the March 2026 change, you keep $15/mo Pro and $30/seat Teams indefinitely, per Cognition's migration FAQ. New signups pay the rates in the table.
- SSO moved to Enterprise. Single sign-on used to be a Teams add-on; it's now an Enterprise-only feature (existing Teams SSO holders are grandfathered).
The tiers climb steeply, which is the first thing to plan around. The jump from Pro to Max is 10x, and that gap is entirely about quota headroom, not new features.
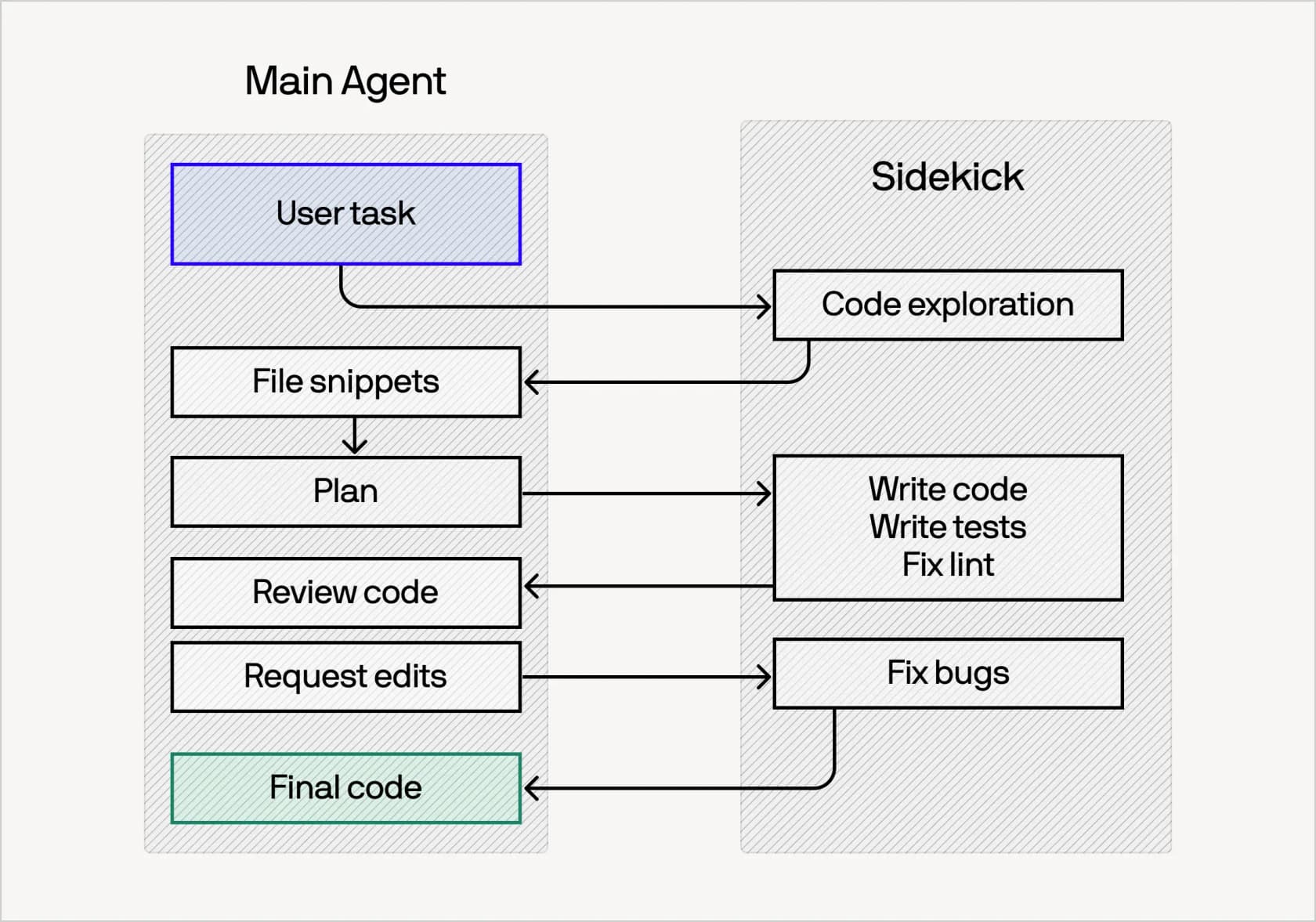
How Fusion changes the cost equation
Now the part that makes Fusion interesting for your bill. Cognition's whole argument is that most engineering orgs are, in their words, "lighting money on fire" by running the most expensive model on every task. Fusion's fix is a two-agent setup: a frontier main agent that plans, interprets ambiguity, and does the final review, plus a cheap sidekick that does the mechanical work (code exploration, broad edits, writing tests, fixing lint). The main agent delegates and monitors; the sidekick grinds.
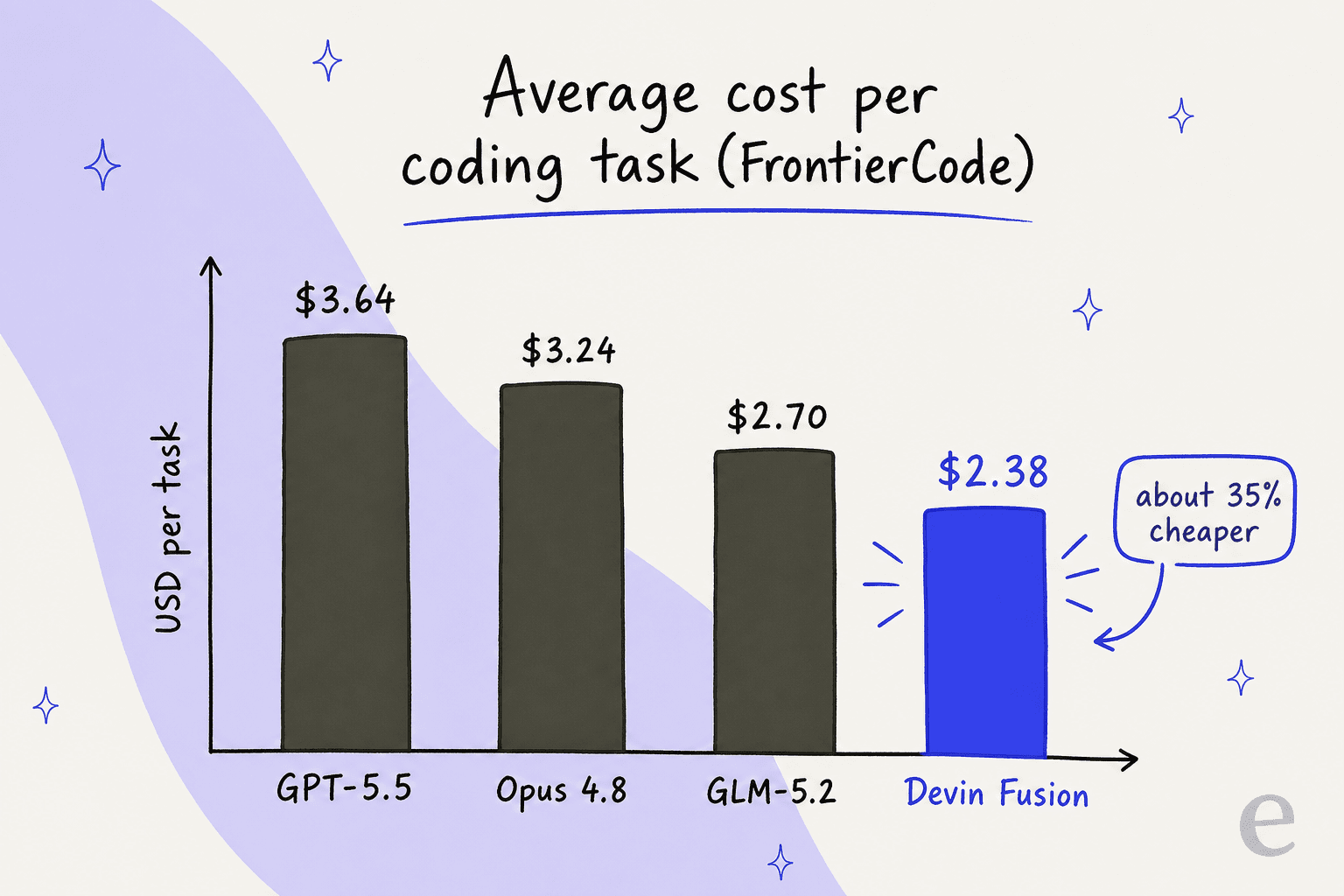
The payoff shows up as cost per task. On FrontierCode Extended, Cognition's own benchmark, here's what the money looks like next to the quality score:
| Config | Quality score | Avg cost per task |
|---|---|---|
| Fusion + Fable 5 | 57.6 | $3.00 |
| Fable 5 (medium) | 57.0 | $5.12 |
| Opus 4.8 (high) | 48.8 | $3.24 |
| Fusion | 47.9 | $2.38 |
| GPT-5.5 (high) | 44.8 | $3.64 |
| GLM-5.2 | 43.0 | $2.70 |
The live comparison to read is Fusion at $2.38/task against GPT-5.5 at $3.64 and Opus 4.8 at $3.24, at a quality score that sits right in the frontier pack. That's where the "35% cheaper" line comes from.
One caveat that matters for accuracy: the flashiest row, Fusion + Fable 5 at a 41% saving, isn't something you can buy right now. Access to Fable 5 was suspended on June 12, 2026 under a US government directive and, as of Cognition's post, hadn't been restored. So the 35% figure (without Fable 5) is the one grounded in a model you can actually run today.
The billable unit: quota, tokens, and ACUs
This is the section that trips people up, and it's the real answer to "what will Devin cost me?" There are two separate billing worlds, and which one you're in depends entirely on your plan.
Self-serve plans (Free, Pro, Max, Teams): token-based quota. Since March 2026, these plans include a daily and weekly usage allowance measured in tokens, not credits. Cheaper models (like SWE-1.6 and open-source models) burn less; free models don't count against quota at all. When you exhaust the included quota, Pro/Max/Teams users can keep going by buying extra usage billed at the underlying model's API prices, while Free users just wait for the reset.
Enterprise: ACUs. Enterprise contracts are metered in Agent Compute Units, which Cognition defines as a measure of "agent effort" that "scales with the inference used and the model selected." How many ACUs you get, and what each one costs, is set per contract, and Cognition doesn't publish a per-ACU dollar figure anywhere I could find. It's "contact your account team."
That opacity is the single most repeated gripe about Devin's pricing. One user put it bluntly on Hacker News:
"ACU are entirely too opaque/confusing/complicated. The entire description of them is shrouded in mystery... what does 'the few ACUs required to keep the Devin VM running' mean?"
The practical read: the plan fee is the tip of the iceberg. What actually moves your bill is the variable layer underneath, extra-usage token charges on self-serve and ACUs on Enterprise. Fusion's job is to make that underwater part smaller by not wasting a frontier model on lint fixes.
What it actually costs: two worked examples
Abstract tiers don't help you budget, so here are two realistic scenarios.
Solo developer, moderate use. You take the Pro plan at $20/month. That covers frontier models, Devin Cloud agents, and free SWE-1.6, and Fusion routes across them automatically. If you stay inside the daily/weekly quota, $20 is your whole bill. Push hard on big frontier-heavy tasks and you'll spill into extra usage at API token prices, so a heavy month might land at $20 plus, say, $30-$60 of overage. Fusion is the thing keeping that overage number from being far worse.
Five-person team. On Teams you pay the $80 base plus $40 per full dev seat, so 5 seats is $80 + (5 × $40) = $280/month before any extra usage. That's the predictable floor; the variable layer sits on top when the team runs frontier-heavy sessions in parallel. Run the numbers for your own seat count below.
Is Devin Fusion worth the price?
The honest answer depends on what you're delegating. Fusion (and Devin generally) is at its best on large, mechanical, pattern-heavy work, the exact tasks where the sidekick can grind cheaply while the main agent supervises. Cognition says that internally, 88% of their merged PRs were driven entirely by the automated Fusion router, and the company is real: it raised over $1B at a $26B valuation in May 2026. When the fit is right, users are genuinely happy:
"IMO it's the best tool for AI generating features if you know what you're looking for, have patterns to follow, etc. I suspect the context they build about your project helps a ton."
Where the price stings is on judgment-heavy work and on runaway sessions. The same hands-on reviewers who like Devin also flag that it drifts, and drifting on a usage meter is expensive:
"Once the ACU consumption hits around 40 or 50, Devin really starts to lose the plot... I usually have to kill the session and start a completely fresh one."
So the value math is: Fusion legitimately lowers the cost of the good case, but it doesn't fix the bad case where an agent burns budget going off the rails. If you're evaluating it, weigh it against Cursor's pricing, Windsurf (now Devin Desktop), and OpenAI Codex alternatives, and read the wider sentiment in our Cognition AI reviews roundup before you pick a tier. For the full breakdown of how the tiers evolved, our Cognition AI pricing guide goes deeper on the ACU history.
Right-sizing AI cost, on the support side
The idea underneath Fusion, stop paying frontier prices for work a cheaper model can do, is exactly how we think about AI cost at eesel too, just for customer support instead of code. eesel runs AI agents on live support queues, and the reason we price on outcomes rather than per-seat is the same reason Fusion routes to a sidekick: you shouldn't pay a premium rate for the easy 60% of tickets a smaller model resolves fine.
Where it differs: with support, the risk isn't a runaway token bill, it's a confident-sounding bot giving a wrong answer to a real customer. That's why every eesel rollout is simulated against your historical tickets first, so you see the resolution rate and the cost before it ever touches a customer. If you're weighing AI spend the way this whole post has, our usage-based pricing is built on the same "don't overpay for the easy stuff" logic. Try eesel free.