
What Devin Fusion actually is
Let me start with the thing itself, because "multi-model harness" is jargon that hides a simple idea.
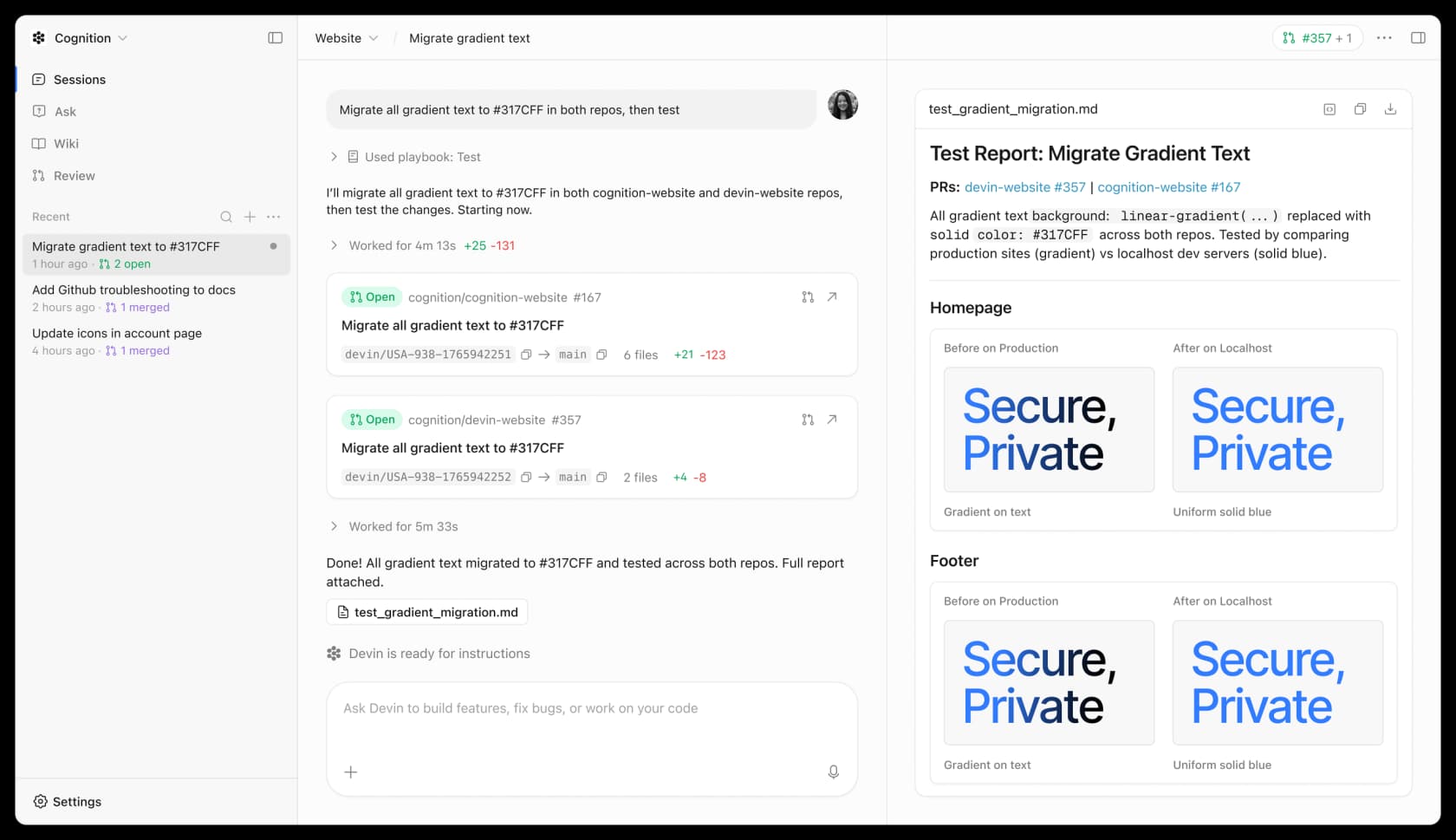
A harness is the scaffolding around a language model that turns it into an agent: the loop that reads your codebase, plans, calls tools, runs tests, and decides what to do next. Devin has always been Cognition's harness for autonomous software work. Fusion changes one thing about it: instead of running that loop on a single model, it runs it across two at once.
Cognition frames the problem bluntly in the Devin Fusion announcement: "Engineering teams are lighting money on fire. It's no longer sustainable to use the most expensive models on every task." Their analogy is the one that stuck with me: "You wouldn't drive a Lamborghini to the grocery store, so why should you take a model that can discover zero-day vulnerabilities and use it to round the corner of a button?"
The pitch, in their words: "The age of using one model for all of your work is coming to an end." Fusion is their answer, and it launched in preview inside Devin the same day it was announced. It arrives on the back of a big year for Cognition, which raised over $1B at a $26B valuation in May 2026 and folded Windsurf into the product line (the old Windsurf IDE is now "Devin Desktop").

The sidekick: how it works under the hood
The core mechanism is what Cognition calls the "sidekick" approach, and it's worth understanding because it's different from the naive model-routing most tools do.
Two fully capable agents run in parallel. A main agent on a frontier model (think Opus 4.8 or GPT-5.5) and a smaller, cheaper sidekick agent. Each keeps its own persistent, cached context. As the task moves along, the main agent decides what to delegate. Cognition's tuned pattern is that the main agent "should take minimal actions... By default it should delegate and monitor, while making the significant decisions: the plan, the interpretation of ambiguity, the final review." The sidekick does the grunt work: exploring the codebase, writing code, writing tests, fixing lint.
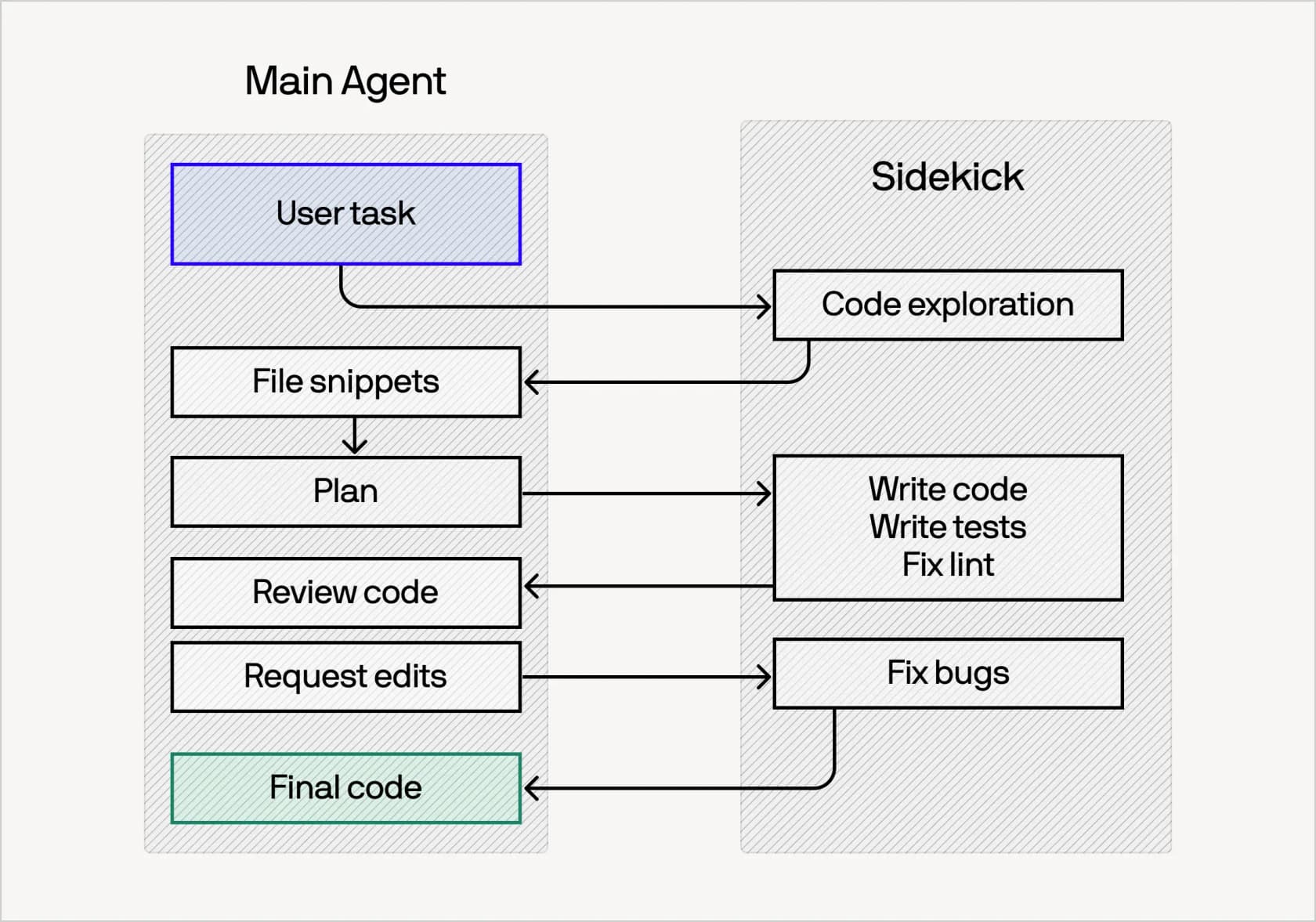
Why not just let the main model "ask" a cheaper model for help, the way earlier tools did? Because of cache misses. When a frontier agent queries a separate advisor model, it re-sends its whole context at full price every time, which gets expensive fast. Fusion sidesteps this: both agents keep their own cached contexts, so delegation doesn't trigger a costly re-send. Cognition even leaves an engineering teaser in the post, noting that "most cached inputs only have a 5-minute expiry" and inviting readers to think about how they engineered around it.
The second technique is dynamic mid-session routing. Picking a model at the start of a task is a gamble, because a single prompt rarely reveals how hard the work will actually get. So Fusion runs lightweight classifiers during execution that can escalate a struggling sidekick task back to the main agent, or swap models entirely. The neat trick: it switches models during context compaction, a step that would trigger a cache miss anyway, so the switch is effectively free. This is the same agentic reasoning loop idea that underpins modern agents, just applied to which model runs each turn.
The numbers: 35% cheaper, with an asterisk
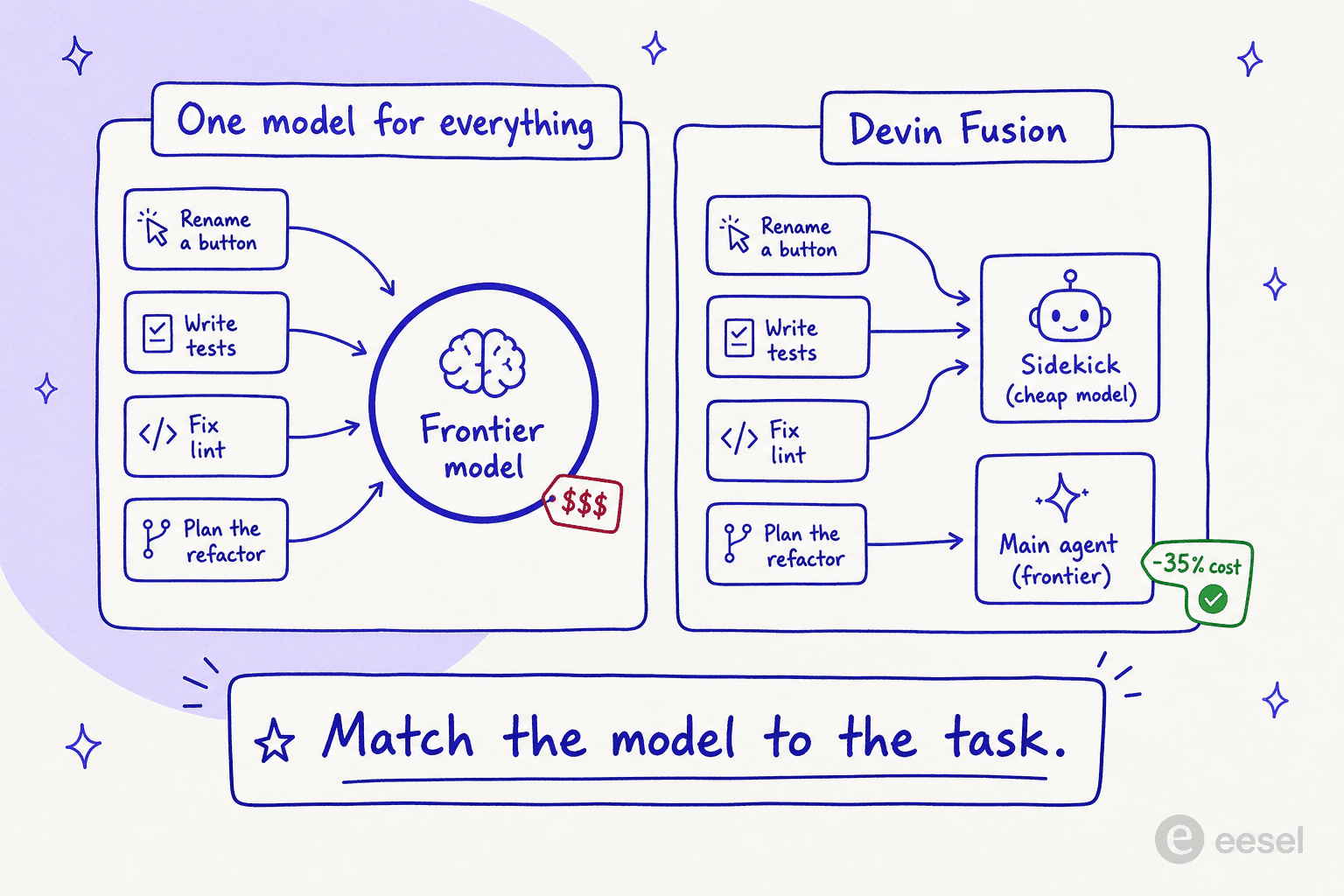
Cognition benchmarked Fusion on FrontierCode, a new code-quality benchmark it built with 20-plus open-source maintainers that measures whether code is actually mergeable, not just whether it passes a test. Here's the headline slice of results (FrontierCode Extended, score versus average cost per task):
| Configuration | Score | Avg cost/task |
|---|---|---|
| Fusion + Fable 5 | 57.6 | $3.00 |
| Fable 5 (medium) | 57.0 | $5.12 |
| Opus 4.8 (high) | 48.8 | $3.24 |
| Devin Fusion | 47.9 | $2.38 |
| GPT-5.5 (high) | 44.8 | $3.64 |
| GLM-5.2 | 43.0 | $2.70 |
The story the table tells: Fusion (without Fable 5) scores 47.9 at $2.38 per task, roughly matching Opus 4.8's 48.8 while costing about a third less. Cognition rounds that to a 35% cost improvement "while maintaining performance matching the frontier."
Two honest caveats before you screenshot that chart. First, this is a vendor benchmark on a vendor-built eval, which is fine as a signal but not the same as independent testing. Second, the even better "41% cheaper" number requires Anthropic's Fable 5, and access to Fable 5 was suspended on June 12, 2026 under a US government directive. So those Fable 5 figures were measured before the cutoff and aren't reproducible right now. The live number is the 35% one.
Cognition also says Fusion "actually feels good in real use," and backs it with an internal stat: after turning it on, 88% of their merged pull requests were driven entirely by the automated Fusion router. That's a real signal, though it's Cognition dogfooding on Cognition's own codebase, which is about the friendliest possible test environment.
When delegating helps, and when it backfires
The most useful part of the announcement, to me, wasn't the headline number. It was Cognition publishing the tasks where the sidekick hurt.
On mechanical work, delegation is a clear win. Modernizing a JS file to ES6 came in 62% cheaper with the score holding steady. Ripping a deprecated tracing library out of a Go codebase ran 32% cheaper. But on a hard front-end feature where the judgment was the deliverable, delegating tanked the quality score from 54 to 27. Cognition's own summary: "When the judgment is the deliverable, delegating it backfires."
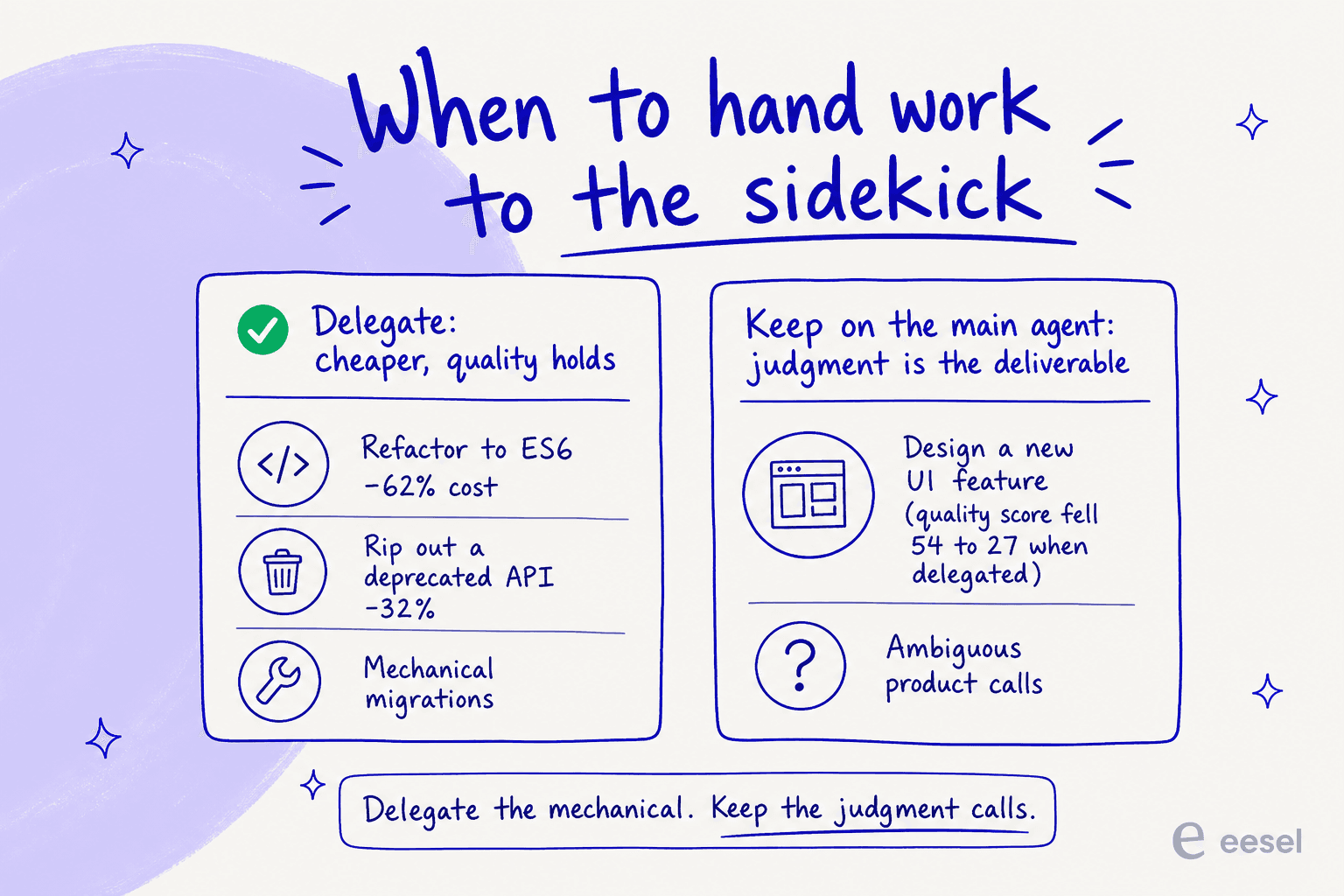
This is the honest, non-marketing version of the pitch, and it's the part worth internalizing. Fusion isn't magic that makes cheap models as smart as expensive ones. It's a system for spending expensive tokens only where they change the outcome. That distinction is exactly what separates a genuinely useful AI agent from an expensive demo.
What people are actually saying
Fusion is only a few days old, so the community reaction to Fusion specifically is thin and mostly positive launch commentary. On Reddit's r/AIDeveloperNews, the take was that "the architecture is actually pretty clever," and operators on X have been dissecting the sidekick design approvingly.
But you can't read Fusion reactions in a vacuum, because Devin carries a lot of baggage. The most durable criticism is the March 2024 independent test where Devin completed 3 of 20 tasks, which the internet branded a fake demo. Interestingly, in 2026 that line mostly shows up as a comeback story:
"In March 2024, independent testers said Devin completed 3 of 20 tasks. The internet called it a fake demo. Two years later, that product codes for the US Army."
Among people using it day to day, the gripes are consistent and they're the exact things Fusion doesn't obviously fix. Reliability is one:
"The promise was full autonomy, but the reality still involves a lot of babysitting. You give it a task, it goes off the rails, you correct it, it sort of gets back on track. Rinse and repeat."
Cost opacity is the other, and it's the loudest one. A detailed G2 review from a test-automation engineer captures the long-task drift well: "Once the ACU consumption hits around 40 or 50, Devin really starts to lose the plot. It begins ignoring the initial instructions... It feels like the model gets tired." The same reviewer still rated it highly for parallel work ("I can have five different sessions running in parallel"), which is the fair, two-sided read.
There's even a thread of pure brand skepticism worth hearing, because it's the counterweight to the hype:
"Devin? Now that's a name I've not heard in a long time... in this age of Claude Code and Codex, does anyone use Devin, or even know someone who does?"
My read: Fusion is a real engineering answer to the cost complaint, and Devin's review tooling genuinely gets praise. But cheaper tokens don't fix an agent that drifts off a long task, and that's still the thing seasoned users flag first.
Devin pricing, briefly
Fusion is rolling out inside Devin, so the pricing you'll actually hit is Devin's. Here's the current Devin pricing:
| Plan | Price | What you get |
|---|---|---|
| Free | $0 | Light quota, limited models, unlimited inline edits and tab completions |
| Pro | $20/mo | Frontier models (OpenAI, Claude, Gemini), cloud agents, free SWE-1.6, overage at API pricing |
| Max | $200/mo | Everything in Pro with much higher quotas |
| Teams | $80/mo + $40/seat | Unlimited members, centralized billing, admin dashboard, priority support |
| Enterprise | Custom | SSO, VPC deploy, dedicated support |
One nuance that trips people up: Devin used to bill self-serve plans in "ACUs" (Agent Compute Units), the opaque metering that generated most of the Hacker News complaints. As of March 2026, self-serve moved to a token-based quota model instead, and ACUs are now an enterprise-only meter that Cognition doesn't publish a public dollar rate for. If you're comparing costs, eesel's Cognition AI pricing guide breaks the history down, and it's worth reading before you assume a per-ACU number you saw online is still accurate.
What this means if you're not writing code
Here's the part I care about most, because Fusion's core idea reaches well past AI coding tools.
"The age of using one model for everything is coming to an end" isn't just a claim about Cursor versus Codex. It's true of every place agents do real work, including customer support. A password-reset FAQ and a nuanced billing dispute do not need the same model, and paying frontier prices for the easy 80% is exactly the "money on fire" problem Cognition is describing, just in a different queue.
The trap is that most support-AI vendors hide this from you. They meter raw model usage, or they charge per resolution and then quietly route everything to whatever's cheapest to protect their margin, which is the deflection-rate-as-vanity-metric game. The better model is the one Fusion gestures at: right-size the model to the task, and let the buyer pay for the outcome, not the tokens.
Where eesel fits
I work on eesel AI, and this is squarely the problem we build around, just for support and internal teams instead of pull requests. eesel is an AI teammate that plugs into your existing helpdesk, learns from your past tickets and help docs, and handles tier-1 work the same way Fusion handles mechanical coding: the routine stuff gets resolved automatically, and the genuinely hard, judgment-heavy tickets get escalated to a human with full context. Same principle as the sidekick, different queue.

Two things make the analogy hold. First, you can simulate on your historical tickets before going live, so you see the resolution rate and cost on your own data instead of trusting a vendor benchmark, which is exactly the independent test Fusion doesn't have yet. Gridwise saw 73% of tier-1 requests resolved in the first month doing this. Second, pricing is usage-based at about $0.40 per resolved ticket with no per-seat fees, so you're paying for the outcome, not for a big model idling on easy questions. You can try eesel free without a sales call.
Frequently Asked Questions
What is Devin Fusion?
How much does Devin cost?
Is Devin Fusion actually 35% cheaper?
What is the sidekick model in Devin Fusion?
Is Devin worth it compared to other AI coding agents?

Article by
Alicia Kirana Utomo
Kira is a writer at eesel AI with a Computer Science background and over a year of hands-on experience evaluating AI-powered customer service tools. She focuses on breaking down how helpdesk platforms and AI agents actually work so that support teams can make better buying decisions.









{kind=link}