ヘルプデスクがダウンすると、1分1秒が重要になります。チームが顧客との会話を管理するためにZendeskに依存している場合、障害はサポート業務を一時停止させるだけではありません。それは、不満を抱えた顧客、手持ち無沙汰のエージェント、および潜在的な収益の損失という連鎖反応を引き起こします。
現実をお伝えしましょう。Zendeskは、UberからKhan Academyまで、10万社以上の企業にサービスを提供しています。そのインフラストラクチャに問題が発生すると、何百万もの顧客とのやり取りが宙に浮いた状態になります。そして、Zendeskの信頼性は一般的に堅牢ですが(堅牢なプラットフォームを構築しています)、障害は発生します。問題は、障害に直面するかどうかではなく、発生したときに備えているかどうかです。
このガイドでは、Zendesk SaaS(Software as a Service)の障害に対処するために知っておくべきことをすべて説明します。インフラストラクチャの仕組み、顧客に影響を与える前に問題を監視する方法、および主要なツールがダウンしている場合でもサポート業務を継続するための対応プレイブックの構築方法について説明します。
Zendeskのインフラストラクチャと障害パターンを理解する
Zendeskは、分散型の「ポッド(Pod)」アーキテクチャで実行されます。ポッドとは、顧客アカウントの異なるグループを処理する個別のデータセンタークラスターと考えてください。Zendeskにサインアップすると、アカウントは特定のポッド(Pod 18、Pod 25、Pod 29など)に割り当てられます。
このアーキテクチャは、障害の発生方法に影響を与えます。
- ポッド固有の問題は、その特定のポッドの顧客にのみ影響します。別のポッドの競合他社がまったく問題ないのに、チケットにアクセスできなくなる可能性があります。
- グローバルな問題は、すべてのポッドに同時に影響を与えます。これらはあまり一般的ではありませんが、より深刻です。
- サービス固有の障害は、プラットフォームの残りの部分がオンラインのままであっても、Webウィジェットまたはエージェントワークスペースのみを停止させる可能性があります。
Zendeskのサービス通知からの最近のインシデントデータを見ると、いくつかのパターンが現れています。過去数か月で、最も一般的な問題は、CDN(コンテンツデリバリーネットワーク)関連の5XXエラー(複数のサービスに影響)、エージェントワークスペースコンポーザーの問題(インターフェイスが公開返信ではなく内部メモにデフォルト設定される)、およびWebウィジェット機能の問題でした。
解決時間は大きく異なります。軽微なインシデントは通常1〜3時間以内に解決されます。中程度の問題には、4〜12時間かかる場合があります。長時間の障害はまれですが、数日間続く可能性があります(2025年12月のAPI使用状況ダッシュボードの問題は、ほぼ2週間続きました)。
重要なポイントは、影響を受けている障害がグローバルであると想定しないでください。ポッドのステータスを具体的に確認してください。また、グローバルな障害が発生した場合でも、すべてのZendesk機能がダウンしているとは限りません。プラットフォームは十分にモジュール化されているため、部分的な障害が一般的です。
Zendeskのステータスをプロアクティブに監視する方法
ZendeskがダウンしたときにZendeskからの情報だけに頼ると、利益相反が生じます。独立した検証ソースが必要です。
まず、公式のZendeskステータスページから始めます。特定のポッドのメールまたはSMSアラートを購読します。ステータスページでは、製品(Support、Chat、Voiceなど)ごとに状態が分類され、計画されたダウンタイムを中心に計画できるようにメンテナンススケジュールが含まれています。
ただし、注意点があります。公式のステータスページは、ユーザーから報告された問題よりも遅れる場合があります。企業は問題を投稿する前に検証する傾向があるため、遅延が発生します。そこで、サードパーティの監視ツールが役立ちます。
Downdetectorは、クラウドソーシングされたユーザーレポートを集約します。ユーザーがZendeskにアクセスできない場合、ここで報告します。これにより、公式な承認の15〜30分前に問題が表面化することがよくあります。このサイトでは、問題の種類(アプリ、ログイン、ウェブサイト)ごとに分類されるため、他のユーザーが同じ症状を経験しているかどうかをすばやく確認できます。
StatusGatorは、異なるアプローチを取ります。ユーザーレポートと自動化されたAPIチェックに加えて、Zendeskの公式ステータスページを監視します。その障害マップは、問題の地理的な分布を示しています。彼らのデータによると、Zendeskは過去12か月で79件のインシデントを経験しており、Supportが最も影響を受けたコンポーネントです。
技術チームの場合は、ZendeskのAPIエンドポイントを直接監視することを検討してください。数分ごとの簡単なHTTPチェックにより、エージェントにカスケードする前に接続の問題を警告できます。Uptime.comなどのツールは、この自動監視を過去の応答時間データとともに提供します。
ベストプラクティスは何でしょうか?複数のソースを使用します。信頼できる更新については公式ステータスページを購読し、早期警告信号についてはDowndetectorを確認し、傾向分析と地理的影響評価についてはStatusGatorを使用します。
Zendeskの障害対応プレイブックを構築する
Zendeskがダウンすると、計画がない限り、混乱が続きます。その計画を構築するためのフレームワークを次に示します。
即時検証(最初の5分)
最悪の事態を想定しないでください。複数のソースをチェックして、これが広範囲にわたる障害なのか、ローカルの問題なのかを確認します。
- ポッドのZendeskステータスページを確認します
- ユーザーレポートについてDowndetectorを確認します
- ISP(インターネットサービスプロバイダ)を除外するために、別のネットワーク(モバイルホットスポット)からZendeskへのアクセスを試みます
- 別の場所にいる同僚にアクセスをテストするように依頼します
自分だけの場合は、ローカルでトラブルシューティングを行います。広範囲にわたる場合は、障害対応をアクティブにします。
内部コミュニケーション(5〜15分)
内部チャットプラットフォーム(Slack、Microsoft Teamsなど)を介してチームに警告します。コミュニケーションを所有する単一の「障害コーディネーター」を指定します。これにより、矛盾するメッセージが防止され、一貫した更新が保証されます。
内部アラートには、次のものを含める必要があります。
- Zendeskで障害が発生していることの確認
- 予想される影響(チケットを作成できない、過去のデータにアクセスできないなど)
- アクティブ化されている代替ワークフロー
- 次の更新のタイムライン(その更新が「まだ待機中です」であっても)
顧客コミュニケーション(15〜30分)
沈黙は悪いニュースよりも顧客をイライラさせます。プロアクティブなコミュニケーションは、状況を把握していることを示します。
次の場所に通知を投稿します。
- ステータスページ(ある場合)
- ウェブサイトのバナー
- ソーシャルメディアチャネル
- メール自動応答(該当する場合)
メッセージは正直でありながら安心できるものでなければなりません。「サポートプラットフォームで技術的な問題が発生しています。私たちのチームは状況を監視し、お客様を支援するための代替方法に取り組んでいます。緊急の問題については、[代替連絡方法]をご利用ください。」
エスカレーション手順
エスカレーションするタイミングのしきい値を定義します。
- **15分:**代替ワークフローをアクティブ化します
- **1時間:**リーダーシップとカスタマーサクセスチームに通知します
- **4時間:**影響を受けた顧客にサービスクレジットまたは善意のジェスチャーを提供することを検討します
- **8時間以上:**専用の作戦室を備えた完全なインシデント対応モード
ドキュメンテーション
障害中はすべてを記録します。開始時間、症状、受信した顧客からの苦情、実行されたアクション、および解決時間をメモします。このデータは、事後分析や、冗長性投資のビジネスケースを構築するために役立ちます。
Zendeskの障害時にカスタマーサポートを維持する
主要なヘルプデスクがダウンしている場合は、代替手段が必要です。重要なのは、必要なときに備えて、これらの代替手段を事前に構成してテストしておくことです。
代替コミュニケーションチャネル
- **メール:**Zendeskを介してルーティングされないバックアップメールアドレス(support@company.com)を保持します。エージェントは、障害時にGmailまたはOutlookでこれを直接監視できます。
- **電話:**音声サポートがある場合は、Zendeskとは独立して動作できることを確認してください。多くの電話システムは、ヘルプデスクの統合が失敗した場合に、エージェントの直接回線に電話をルーティングできます。
- **ソーシャルメディア:**Twitter/XとFacebookは、一時的なサポートチャネルとして機能します。顧客は、通常のチャネルで連絡が取れない場合、最初にこれらを確認することがよくあります。
- 他のプラットフォームのチャットウィジェット:eesel AIのチャットボットを使用している場合、Zendeskがダウンしている場合でもウェブサイトで動作し続け、後でフォローアップするためにお問い合わせをキャプチャできます。
セルフサービスオプション
適切に管理されたナレッジベースは、発券システムがダウンしている場合でも、問い合わせのかなりの部分をそらすことができます。障害時にヘルプセンターの記事にアクセスできることを確認してください。状況を説明し、代替連絡方法を提供する簡単な「Zendesk障害FAQ」ページを作成することを検討してください。
AI搭載バックアップ
最新のAIサポートツールは、障害時に継続性を提供できます。ナレッジベースでトレーニングされたAIエージェントは、主要な発券システムが利用できない場合でも、一般的な質問に答えることができます。当社のAIエージェントは、複数のプラットフォームと同時に統合されるため、Zendeskがダウンした場合でも、代替チャネルを介して動作し続けることができます。
重要なのは、必要なときに備えてこれらのバックアップを設定することです。障害が発生しているときは、新しいツールを構成するのに適した時期ではありません。
サポートツールのダウンタイムの真のコストを計算する
障害は不便なだけではありません。費用がかかります。コストを理解することは、冗長性への投資を正当化するのに役立ちます。
障害の影響を計算するための簡単なフレームワークを次に示します。
直接コスト:
- エージェントのアイドル時間:(影響を受けるエージェントの数)×(1時間あたりのコスト)×(障害期間)
- 解決されなかったチケット:(1時間あたりの平均チケット数)×(障害時間)×(平均チケット価値)
- キャッチアップ作業の残業:(バックログチケット)×(解決までの時間)×(残業レート)
間接コスト:
- SLAペナルティ:契約の違反条項を確認してください
- 顧客の解約:(影響を受ける顧客)×(解約確率)×(顧客生涯価値)
- 評判の低下:定量化するのは難しいですが、特に障害が頻繁になる場合は現実的です
中規模チームの計算例:
- 50人のエージェントが1時間あたり40ドル= 1時間あたり2,000ドルの人件費
- 4時間の障害= 8,000ドルの直接人件費
- 失われたキャパシティ:200枚のチケットが25ドルの価値= 5,000ドル
- 合計直接的な影響:13,000ドル
これには、バックログをクリアするための残業、潜在的なSLAペナルティ、または顧客満足度の低下は含まれていません。すべての要素を考慮すると、1つの大規模な障害で20,000〜50,000ドルの費用がかかる可能性があります。
この計算により、バックアップシステムに対する考え方が変わります。4時間の障害で13,000ドル以上の費用がかかる場合、冗長性に月額500ドルを費やすのは安く見えます。
eesel AIで回復力のあるサポートスタックを構築する
ここで不快な真実をお伝えします。重要なビジネスオペレーションのために単一のSaaSプラットフォームに依存すると、単一障害点が発生します。そのプラットフォームで障害が発生すると、あなたは彼らの慈悲に委ねられます。
解決策は何でしょうか?すべての卵を1つのバスケットに入れないマルチプラットフォームアプローチです。
eesel AIでは、回復力を念頭に置いてプラットフォームを構築しました。当社のAIエージェントは、1つのヘルプデスクに存在するだけではありません。Zendesk、Freshdesk、Intercom、Gorgias、および100以上の他のツールと同時に統合されます。これは、次のことを意味します。
- Zendeskがダウンした場合、AIエージェントは代替チャネルを介して動作し続けることができます
- 複数のプラットフォームでAIを並行して実行し、冗長性を作成できます
- 顧客データと会話履歴は、単一のベンダーのエコシステムに閉じ込められません

私たちのアプローチは、従来のAIツールとは異なります。複雑なワークフローを構成する代わりに、新しいチームメンバーのようにeesel AIを採用します。既存のデータ(過去のチケット、ヘルプセンターの記事、マクロ)からビジネスを学習し、自律的な運用にレベルアップする前に監督から開始します。
チームがeesel AIで回復力を構築する方法を次に示します。
通常の運用中はAI Copilotから開始します。エージェントが確認するために返信を下書きし、トーンとポリシーを学習します。これは、エージェントが代替チャネルを介して送信する応答を下書きできるため、部分的な障害が発生した場合でも機能し続けます。
ルーチンのお問い合わせについてはAIエージェントに進みます。Zendeskがダウンしている場合、AIはウェブサイトのチャットウィジェット、メール、またはSlackを介して一般的な質問を処理し、主要なプラットフォームの問題を解決するための時間を稼ぐことができます。
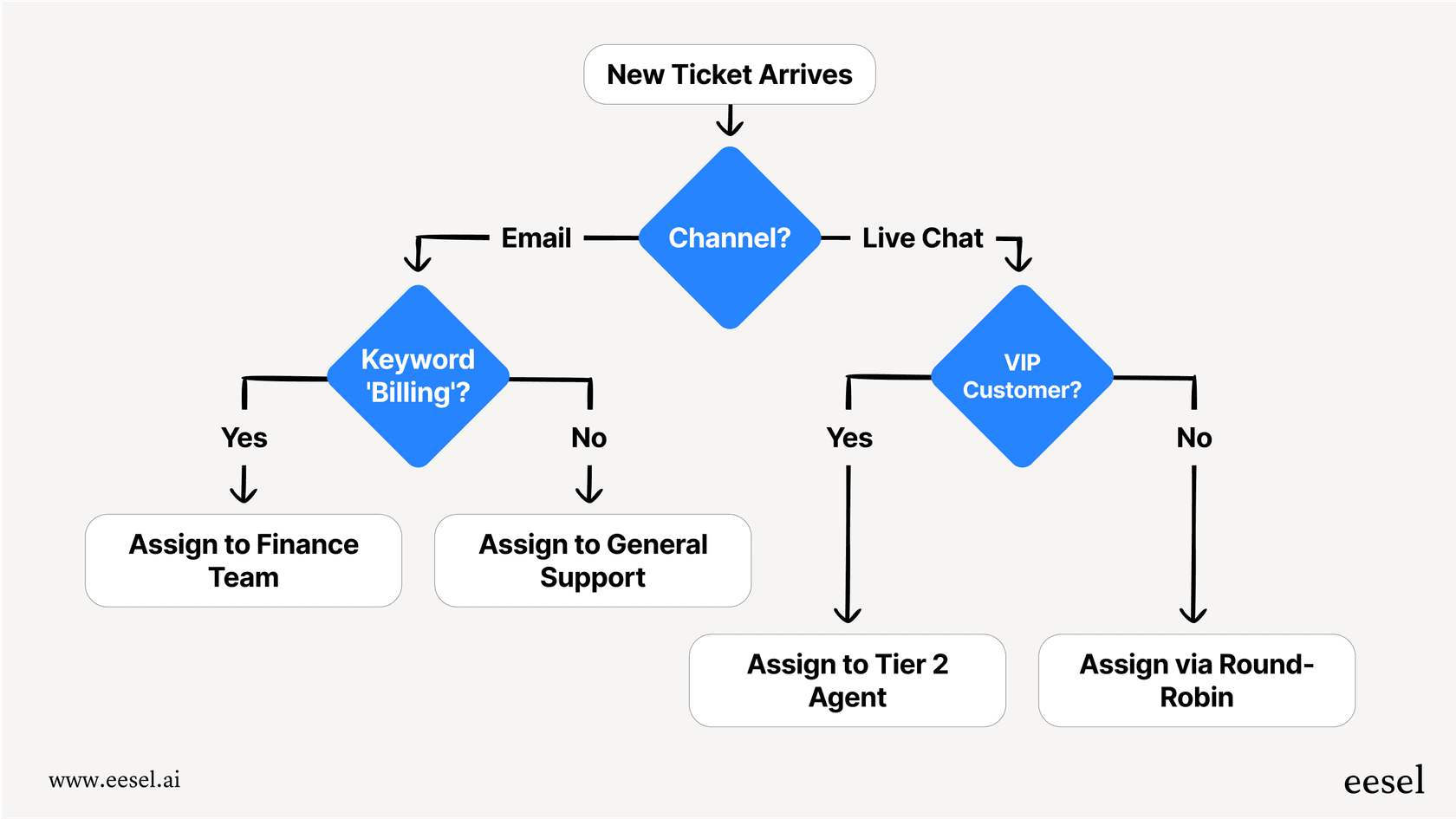
AIトリアージを使用して、チケットの衛生状態を自動化された状態に保ちます。サービスが低下している場合でも、チケットにタグを付け、ルーティングし、優先順位を付けることができるため、チームは完全なサービスが復元されたときに完全な混乱に直面することはありません。
AIサポートツールの回収期間は通常2か月未満です。通常の効率向上に加えて障害回復力を考慮に入れると、投資はさらに魅力的になります。
現在、カスタマーサポートを完全にZendeskに依存している場合は、次の障害時に顧客体験がどうなるかを検討してください。より回復力のあるサポートオペレーションの構築について話し合いましょう。
よくある質問
Share this article

Article by
Stevia Putri
Stevia Putri is a marketing generalist at eesel AI, where she helps turn powerful AI tools into stories that resonate. She’s driven by curiosity, clarity, and the human side of technology.

