QA(品質保証)スコアカードは、本格的なカスタマーサービス品質プログラムのバックボーンです。明確な基準がなければ、レビューは主観的になります。あるマネージャーは文法に焦点を当て、別のマネージャーは共感性を優先するかもしれません。その結果、フィードバックの一貫性がなく、エージェントは混乱し、サービス品質は実際には向上しません。
手短に言うと、明確に定義された基準は、品質保証を直感から体系的なプロセスに変えます。チームに「良い」とは何かについての共通言語を提供し、測定可能な改善のための基盤を構築します。
このガイドでは、Zendesk QAスコアカードの重要な評価カテゴリを分解し、スコアリングフレームワークを検討し、実際に優れたサポートを推進する基準を実装する方法を紹介します。また、eesel AIでの品質保証への取り組み方など、AIがどのように状況を変えているかについても見ていきます。
QAスコアカードとは何か、そして基準が重要な理由
QAスコアカードは、カスタマーサービスの品質を特定の測定可能なコンポーネントに分解する評価フレームワークです。会話をレビューするためのルーブリックと考えてください。「それは良いやり取りでしたか?」と尋ねる代わりに、「エージェントは問題を解決しましたか?口調は適切でしたか?彼らは手順に従いましたか?」と尋ねます。
これらの基準は、チームの標準に対するパフォーマンスを表す割合である内部品質スコア(IQS: Internal Quality Score)に反映されます。カスタマーサービス品質ベンチマークレポートによると、IQSの業界ベンチマークは88%です。しかし、ここに落とし穴があります。実際にIQSを追跡しているサポートチームは約3分の1にすぎず、ほとんどの運用は品質に関して手探りの状態になっています。
明確に定義された基準は、単に数値を生成するだけではありません。エージェントに期待されることを明確にします。マネージャーが具体的で実行可能なフィードバックを提供するのに役立ちます。そして、顧客満足度や維持率などのビジネス成果に日々のやり取りを結び付けます。ZendeskのQAプログラム構築ガイドでは、品質指標をビジネス成果に結び付けるための追加のフレームワークを提供しています。
結論は?QAが改善の真の推進力になるか、単なる管理タスクになるかは、基準によって決まります。
必須のZendesk QAスコアカードの基準
最も効果的なスコアカードは、サポート品質の7つのコアディメンションを評価します。含めるべき内容は次のとおりです。
ソリューションの品質(Solution quality)
エージェントは顧客の問題を正しく、完全に解決しましたか?これは、優れたサポートの基礎です。エージェントは友好的でプロフェッショナルである可能性がありますが、問題を解決しない場合、インタラクションはその主な目的を果たせません。
文法とスペル(Grammar and spelling)
エラーのないコミュニケーションは、すべてのチャネルで重要です。タイプミスや文法の間違いは、特に顧客が洗練された応答を期待するメールでは、信頼性を損ないます。ペースの速いチャットでも、基本的なエラーは不注意を示しています。
口調(Tone of voice)
コミュニケーションはプロフェッショナルで、ブランドと一致していましたか?トーン(口調)には、フォーマルレベル、言葉の選択、および全体的な態度が含まれます。金融サービス会社は正確さと抑制を優先するかもしれませんが、ライフスタイルブランドは暖かさと熱意を奨励するかもしれません。
共感性(Empathy)
エージェントは顧客の感情を理解していることを示しましたか?共感性とは、単に「理解しています」と言うことではありません。それは、不満を認め、懸念を検証し、支援することに心から関心を示すことです。このカテゴリは、顧客がインタラクションについてどのように感じるかに直接影響するため、多くの場合、大きな重みを持っています。
パーソナライゼーション(Personalization)
エージェントは顧客の名前を使用し、関連する履歴を参照しましたか?パーソナライゼーションは、顧客が単なるチケット番号ではないことを示します。過去のやり取りに言及したり、アカウントの詳細を参照したり、特定の状況に合わせてソリューションを調整したりすることが含まれる場合があります。
プロセス遵守(Process adherence)
エージェントは内部手順とプロトコルに従いましたか?これには、適切なタグ付け、正しいエスカレーションパス、セキュリティ検証、およびコンプライアンス要件が含まれます。規制対象の業界では、このカテゴリは「クリティカル」としてマークされる可能性があり、ここで失敗するとレビュー全体が失敗します。
プロアクティブな支援(Proactive help)
エージェントはニーズを予測するために、基本を超えて行動しましたか?これは、潜在的なフォローアップの質問に対処したり、追加のリソースを提供したり、関連する問題がないか確認したりすることを意味する場合があります。それは、満足のいくサービスと卓越したサービスの違いです。
特定のカテゴリは、ビジネスの優先事項を反映する必要があります。SaaS企業は製品知識を重視するかもしれません。eコマースビジネスは、スピードと効率を優先するかもしれません。これらの7つから始めて、顧客にとって最も重要なことに基づいて調整してください。Bufferの品質プログラムやその他のZendeskのお客様は、これらの基準をさまざまな業界に合わせてカスタマイズするためのアプローチを共有しています。
適切なスコアリングスケールの選択
測定するものを定義したら、それをどのようにスコアリングするかを決定する必要があります。Zendesk QAは、それぞれ異なるトレードオフを持つ4つの評価スケールを提供しています。
| スケール(Scale) | オプション(Options) | 最適(Best For) |
|---|---|---|
| 二値(Binary) | 良い/悪い(Good/Bad) | スピードを必要とする大量のチーム(High-volume teams needing speed) |
| 3点(3-point) | 良い/満足/悪い(Good/Satisfactory/Bad) | ニュアンスと効率のバランス(Balance of nuance and efficiency) |
| 4点(4-point) | 良い/やや良い/やや悪い/悪い(Good/Slightly good/Slightly bad/Bad) | 決定的な評価を強制する(Forcing decisive assessments) |
| 5点(5-point) | 5-1スケール(5-1 scale) | コーチングのための詳細なフィードバック(Detailed feedback for coaching) |
**二値スケール(Binary scales)**が最も高速です。レビュアーは迅速な判断を下し、一貫したデータを得ることができます。欠点は?中間点がないことです。ほとんどが良いが、1つの問題があるインタラクションは、完全な失敗と同じスコアになります。ZendeskのQAドキュメントでは、各スケールタイプを設定する方法について説明しています。
**3点スケール(3-point scales)**は、その中間オプションを追加します。レビュアーの速度を低下させることなく、十分なニュアンスを提供するため、ほとんどのチームに適しています。
**4点スケール(4-point scales)**は、中立オプションを排除します。これにより、レビュアーはインタラクションが標準以上か標準以下かを判断する必要があり、調整に役立ちます。
**5点スケール(5-point scales)**は、最も詳細な情報を提供します。漸進的な改善を追跡したいコーチングに焦点を当てたプログラムに最適です。トレードオフはレビュー速度です。
スケール自体を超えて、カテゴリの**重み付け(weighting)**を検討してください。すべての基準が同じように重要ではありません。コンプライアンスが業界で交渉の余地がない場合は、より高い重みを与えます。顧客体験で差別化を図ろうとしている場合は、共感性とパーソナライゼーションをより重視します。Zendesk QAでは、各カテゴリに0から100までの重みを割り当てることができます。
チャネル固有の基準に関する考慮事項
同じコア基準がすべてのチャネルに適用されますが、それらを評価する方法は媒体によって異なります。
**メールサポート(Email support)**は、徹底性と文法を重視します。顧客は、やり取りなしで完全な回答を期待します。基準には、「フォローアップの質問を予測した」または「包括的なソリューションを提供した」が含まれる場合があります。応答時間は品質ほど重要ではありません。
**チャットサポート(Chat support)**は、スピードとマルチタスクを優先します。エージェントは、多くの場合、3つまたは4つの会話を同時に処理します。基準には、応答時間のベンチマークと、複数のチャット間でコンテキストを維持する機能が含まれている必要があります。トーン(口調)はメールよりもカジュアルになる可能性があります。
**電話サポート(Phone support)**は、音声スキルと感情的な知性に焦点を当てています。レビュアーは、ペース、音量、積極的な傾聴、および感情的に負荷のかかった会話を管理する能力を評価します。電話エージェントは、書面チャネルエージェントとは異なるスキルが必要です。
クロスチャネルスコアカードを構築する場合は、どの基準が普遍的で、どの基準がチャネル固有の定義を必要とするかを特定します。文法はメールとチャットで重要ですが、電話には関係ありません。応答時間はチャットでは重要ですが、メールではそれほど重要ではありません。どこにでも適用される基準の一貫した標準を維持しながら、評価アプローチを適応させます。HiverのQAスコアカードに関する調査では、さまざまなサポートチャネルの基準を適応させるための追加のガイダンスを提供しています。
基準を整理するためのフレームワーク
生の基準リストは圧倒される可能性があります。フレームワークは、それらを一貫性のある構造に整理するのに役立ちます。QAスコアカードの設計では、2つのモデルが主流です。
**4Cフレームワーク(The 4C Framework)**は、基準を4つの柱に整理します。
- 明確に伝える(Communicate clearly): 明確さ、トーン(口調)、積極的な傾聴、文法
- つながりを構築する(Build connection): 共感性、パーソナライゼーション、エンゲージメント
- ルールに従う(Follow rules): スクリプト遵守、データ保護、コンプライアンス
- 正しく解決する(Solve correctly): 精度、解決品質、フォローアップ
このフレームワークは、顧客体験を優先するチームに適しています。ソフトスキルとハード要件のバランスを取ります。
**ピラーフレームワーク(The Pillar Framework)**は、より広い視野を持っています。
- 顧客体験(Customer experience): CSAT(顧客満足度)、NPS(ネットプロモータースコア)、センチメント指標
- コンプライアンス(Compliance): プロセス遵守、規制要件
- パフォーマンス(Performance): 最初の電話での解決、処理時間、効率
- 継続的な改善(Continuous improvement): フィードバックの統合、コーチングの成果
このモデルは、正式な品質管理システムを備えたチームに適しています。QAをより広範なビジネス指標に結び付けます。
チームの成熟度と目標に合ったフレームワークを選択してください。初期段階のチームは、4Cのシンプルさから恩恵を受けることがよくあります。確立された運用では、包括的なピラーアプローチを好むかもしれません。重要なのは、レビュアーが理解し、一貫して適用できる構造を持つことです。Zendeskのスコアカードテンプレートライブラリには、両方のフレームワークの実践例が含まれています。
Zendeskを使用したQAスコアカードの実装
基準を定義し、フレームワークを選択したら、Zendesk QAでスコアカードを構築する時が来ました。プロセスの仕組みは次のとおりです。
品質保証>設定>スコアカードに移動し、新しいスコアカードを作成します。カテゴリを追加し、それぞれに評価スケールを選択し、重みを割り当てます。多くの基準がある場合は、カテゴリをグループに整理できます。Zendeskのヘルプドキュメントには、スクリーンショット付きの詳細な設定手順が記載されています。

Zendesk QAには、AutoQAが有効になっている場合に自動的にスコアリングされるいくつかの**システムカテゴリ(system categories)**が含まれています。これらは、スペル、文法、トーン(口調)などの一般的な基準をカバーしています。これらを、ビジネス固有の要件に合わせてカスタムカテゴリで補完できます。
**調整セッション(Calibration sessions)**は、一貫性を保つために不可欠です。複数のレビュアーに同じ会話を個別にスコアリングさせ、結果を比較します。矛盾について話し合い、解釈を調整します。ほとんどのチームは、月次または四半期ごとに調整を実行します。ZendeskのQA調整ガイドでは、チームとの効果的な調整セッションの実行方法について説明しています。
基準を定期的に見直してください。顧客の期待は変化します。製品は進化します。6か月前に重要だったことが、今は重要ではないかもしれません。スコアカードの四半期ごとのレビューをスケジュールし、学習内容に基づいて調整します。
AIを活用した評価によるQAのさらなる進化
サポートリーダーが懸念すべき統計を次に示します。平均して、顧客との会話のわずか2%しか手動でレビューされていません。つまり、インタラクションの98%が評価されていないことになります。品質、トレーニング、およびプロセス改善に関する意思決定を、ごくわずかなサンプルに基づいて行っています。
AIはこの方程式を変えます。サンプリングする代わりに、インタラクションの100%をレビューできます。ZendeskのAutoQAは、カテゴリ全体で会話を自動的にスコアリングし、外れ値をフラグ付けし、手動レビューでは見逃される傾向を特定します。
しかし、AIを活用したQAは、単にカバレッジ(範囲)だけではありません。それはタイムリーさについてです。従来のQAは、インタラクションの数日または数週間後に行われます。その時までに、コーチングの機会は過ぎ去っています。AIはほぼリアルタイムのフィードバックを提供できるため、マネージャーはコンテキストがまだ新鮮なうちに介入できます。McKinseyのカスタマーサービスにおけるAIに関する調査は、AI主導の品質改善が顧客満足度スコアに大きな影響を与える可能性があることを示しています。
eesel AIでは、これをさらに一歩進めています。当社のAIエージェントは、品質保証を個別のレビュープロセスではなく、サポートワークフローの統合された一部として扱います。AIは、既存のデータから標準を学習し、それらの標準に対してすべてのインタラクションを自動的に評価します。エージェントはすぐにフィードバックを受け取ります。マネージャーは、運用全体の品質トレンドを示すダッシュボードを取得します。そして、すべてが自動化されているため、人員を追加することなく完全なカバレッジ(範囲)を得ることができます。
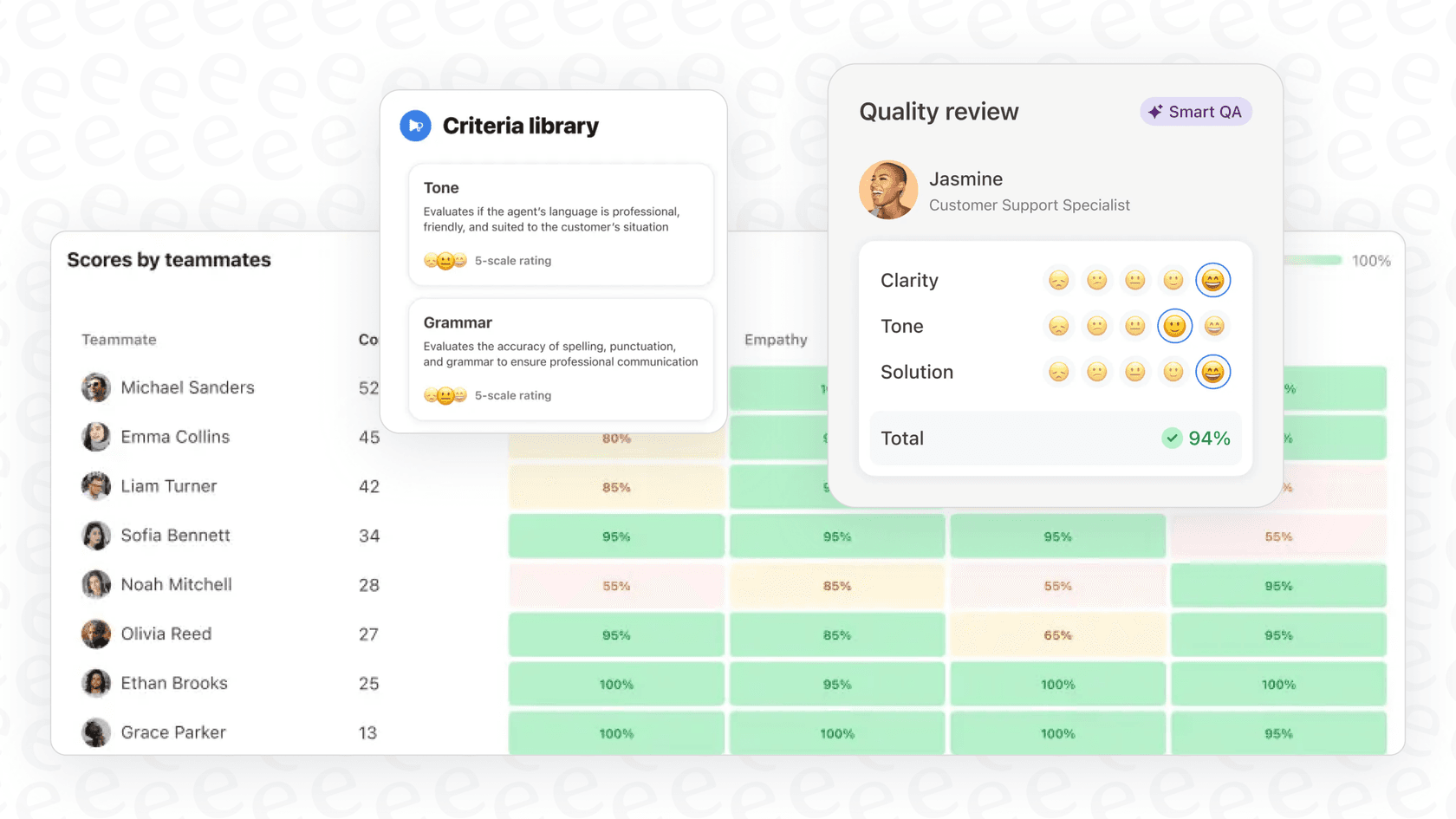
その結果、改善を測定するだけでなく、改善を推進する品質プログラムが実現します。
今すぐQAスコアカードの構築を開始しましょう
効果的なQAスコアカードの構築は、顧客とビジネスにとって何が重要かを理解することから始まります。これらの優先事項に基づいて基準を定義します。詳細と実用性のバランスを取るスコアリングスケールを選択します。すべてをチームが一貫して適用できるフレームワークに整理します。
シンプルに始めましょう。初日に20個のカテゴリは必要ありません。最も重要な5つまたは6つの基準を選択し、チームがそれらに慣れてから、拡張します。一貫して使用されるシンプルなスコアカードは、使用されていない複雑なスコアカードよりも優れています。
手動レビューを超えて、サポート品質を完全に可視化する準備ができている場合は、お手伝いできます。当社のAIを活用した品質保証は、すべてのインタラクションを自動的に評価し、効果的にコーチングし、継続的に改善するために必要なデータを提供します。また、eeselを無料で試して、既存のZendesk設定でどのように機能するかを確認することもできます。
よくある質問
Share this article

Article by
Stevia Putri
Stevia Putri is a marketing generalist at eesel AI, where she helps turn powerful AI tools into stories that resonate. She’s driven by curiosity, clarity, and the human side of technology.

